Как создать файл Robots.txt: настройка, проверка, индексация
- Новости
- Интернет-маркетинг
- PPC
- Блог Google Adwords
- Обновления Google Adwords
- Блог Яндекс Директ
- Обновления Яндекс Директ
- SEO
- SEO кейсы
- SMM
- IGTV
- TikTok
- YouTube
- Блог о ВКонтакте
- Обновление ВК
- Блог про Facebook
- Обновления Facebook
- Блог про Twitter
- Блог про Инстаграм
- Обновления в Instagram
- Блог про Одноклассники
- Обновления в Одноклассниках
- Таргетированная реклама
- Яндекс.Дзен
- Ещё
- Брендинг
- Веб-аналитика
- Блог Google Analytics
- Блог про Гугл Вебмастер
- Обновления в Гугл Вебмастер
- Блог про Яндекс Вебмастер
- Обновления Яндекс Вебмастер
- Блог Яндекс Метрики
- Обновления Яндекс Метрики
- Дизайн
- Контент-маркетинг
- Мессенджеры
- Продажи
- WordPress
- Услуги
- SEO & MARKETING
- Продвижение на рынке B2B
- Блоги
- Спецпроекты
- Click.ru
- PromoPult
- ukit
- Реклама
- ⚡ Сервисы
Поиск
IM- Новости
- Интернет-маркетинг
- Как написать статью-инструкцию или пошаговое руководство
7 советов для маркетологов, задумавшихся об удаленной работе
10 лучших конструкторов форм обратной связи для сайта
Структура сайта: разработка структуры в виде схемы, типы и примеры
Геймификация: что это такое, для чего нужно и как использовать
- Как написать статью-инструкцию или пошаговое руководство
7 советов для маркетологов, задумавшихся об удаленной работе
10 лучших конструкторов форм обратной связи для сайта
Структура сайта: разработка структуры в виде схемы, типы и примеры
Геймификация: что это такое, для чего нужно и как использовать
- PPC
- ВсеБлог Google AdwordsОбновления Google AdwordsБлог Яндекс ДиректОбновления Яндекс Директ
Как сгенерировать объявления для контекста из YML-файла
Анализ рекламы конкурентов в Яндекс.Директ: объявления, ключевые слова, бюджет
Рекламодатели Яндекса смогут разместить рекламу в TikTok
Новый подборщик ключевых слов, комбинатор ключевых фраз в Яндекс.Директ
- ВсеБлог Google AdwordsОбновления Google AdwordsБлог Яндекс ДиректОбновления Яндекс Директ
Как сгенерировать объявления для контекста из YML-файла
Анализ рекламы конкурентов в Яндекс.Директ: объявления, ключевые слова, бюджет
Рекламодатели Яндекса смогут разместить рекламу в TikTok
Новый подборщик ключевых слов, комбинатор ключевых фраз в Яндекс.Директ
- SEO
- ВсеSEO кейсы
В Яндекс.Справочнике появился геовизор, позволяющий посмотреть действия пользователей
Google вывел отчёт по скорости загрузки сайта в Search Console
Как веб-разработчику зарабатывать на рекламе сайтов клиентов (и не тратить на…
BERT – новый поисковый алгоритм Google
- ВсеSEO кейсы
В Яндекс.Справочнике появился геовизор, позволяющий посмотреть действия пользователей
Google вывел отчёт по скорости загрузки сайта в Search Console
Как веб-разработчику зарабатывать на рекламе сайтов клиентов (и не тратить на…
BERT – новый поисковый алгоритм Google
- SMM
internet-marketings.ru
Как создать файл robots.txt для сайта
Здравствуйте, уважаемые читатели. Не так давно я написал статью о создании карты сайта. Карта сайта, значительно упрощает индексацию вашего блога. Карта сайта должна быть в обязательном порядке у каждого сайта и блога. Но также на каждом сайте и блоге должен быть файл robots.txt. Файл robots.txt содержит свод инструкций для поисковых роботов. Можно сказать, — правила поведения поисковых роботов на вашем блоге. А также в данном файле содержится путь к карте сайта вашего блога. И, по сути, при правильно составленном файле robots.txt поисковый робот не тратит драгоценное время на поиск карты сайта и индексацию не нужных файлов.
Что же из себя представляет файл robots.txt?
robots.txt – это текстовый файл, может быть создан в обычном «блокноте», расположенный в корне вашего блога, содержащий инструкции для поисковых роботов.
Эти инструкции ограничивают поисковых роботов от беспорядочной индексации всех файлов вашего бога, и нацеливают на индексацию именно тех страниц, которым следует попасть в поисковую выдачу.
С помощью данного файла, вы можете запретить индексацию файлов движка WordPress. Или, скажем, секретного раздела вашего блога. Вы можете указать путь к карте Вашего блога и главное зеркало вашего блога. Здесь я имею ввиду, ваше доменное имя с www и без www.
Индексация сайта с robots.txt и без
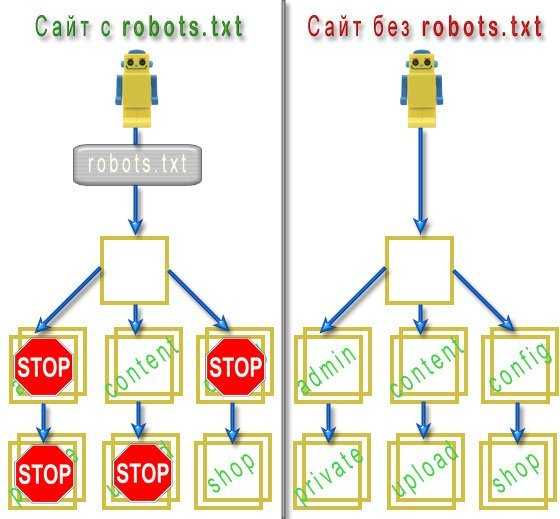
Работа robots.txt
Данный скриншот, наглядно показывает, как файл robots.txt запрещает индексацию определённых папок на сайте. Без файла, роботу доступно всё на вашем сайте.
Основные директивы файла robots.txt
Для того чтобы разобраться с инструкциями, которые содержит файл robots.txt нужно разобраться с основными командами (директивы).
User-agent – данная команда обозначает доступ роботам к вашему сайту. Используя эту директиву можно создать инструкции индивидуально под каждого робота.
Пример:
User-agent: Yandex – правила для робота Яндекс
User-agent: * — правила для всех роботов
Disallow и Allow – директивы запрета и разрешения. С помощью директивы Disallow запрещается индексация а с помощью Allow разрешается.
Пример запрета:
User-agent: *
Disallow: / — запрет ко всему сайта.
User-agent: Yandex
Disallow: /admin – запрет роботу Яндекса к страницам лежащим в папке admin.
Пример разрешения:
User-agent: *
Allow: /photo
Disallow: / — запрет ко всему сайту, кроме страниц находящихся в папке photo.
Примечание! директива Disallow: без параметра разрешает всё, а директива Allow: без параметра запрещает всё. И директивы Allow без Disallow не должно быть.
Sitemap – указывает путь к карте сайта в формате xml.
Пример:
Sitemap: https://1zaicev.ru/sitemap.xml.gz
Sitemap: https://1zaicev.ru/sitemap.xml
Host – директива определяет главное зеркало Вашего блога. Считается, что данная директива прописывается только для роботов Яндекса. Данную директиву следует указывать в самом конце файла robots.txt.
Пример:
User-agent: Yandex
Disallow: /wp-includes
Host: 1zaicev.ru
Примечание! адрес главного зеркала указывается без указания протокола передачи гипертекста (http://).
Как создать robots.txt
Теперь, когда мы познакомились с основными командами файла robots.txt можно приступать к созданию нашего файла. Для того чтобы создать свой файл robots.txt с вашими индивидуальными настройками, вам необходимо знать структуру вашего блога.
Мы рассмотрим создание стандартного (универсального) файла robots.txt для блога на WordPress. Вы всегда сможете дополнить его своими настройками.
Итак, приступаем. Нам понадобится обычный «блокнот», который есть в каждой операционной системе Windows. Или TextEdit в MacOS.
Открываем новый документ и вставляем в него вот эти команды:
User-agent: * Disallow: Sitemap: https://1zaicev.ru/sitemap.xml.gz Sitemap: https://1zaicev.ru/sitemap.xml User-agent: Yandex Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /xmlrpc.php Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-content/languages Disallow: /category/*/* Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: /tag/ Disallow: /feed/ Disallow: */*/feed/*/ Disallow: */feed Disallow: */*/feed Disallow: /?feed= Disallow: /*?* Disallow: /?s= Host: 1zaicev.ru
Не забудьте заменить параметры директив Sitemap и Host на свои.
Важно! при написании команд, допускается лишь один пробел. Между директивой и параметром. Ни в коем случае не делайте пробелов после параметра или просто где попало.
Пример: Disallow:<пробел>/feed/<Enter>
Данный пример файла robots.txt универсален и подходит под любой блог на WordPress с ЧПУ адресами url. О том что такое ЧПУ читайте здесь. Если же Вы не настраивали ЧПУ, рекомендую из предложенного файла удалить Disallow: /*?* Disallow: /?s=
Теперь нужно сохранить файл с именем robots.txt.
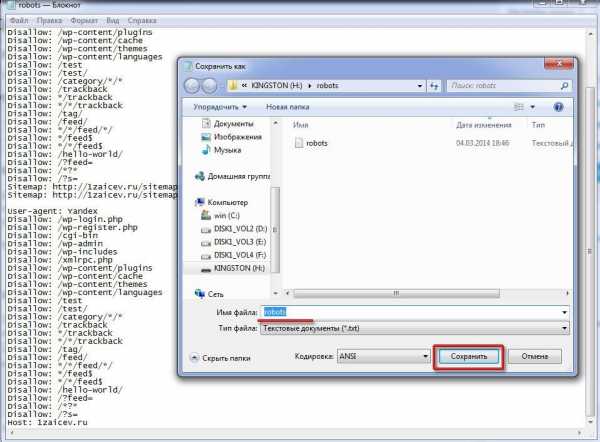
Сохранение robots.txt
Загрузка файла robots.txt на сервер
Лучшим способом для такого рода манипуляций является FTP соединение. О том как настроить FTP соединение для TotolCommander читайте здесь. Или же Вы можете использовать файловый менеджер на Вашем хостинге.
Я воспользуюсь FTP соединением на TotolCommander.
Сеть > Соединится с FTP сервером.
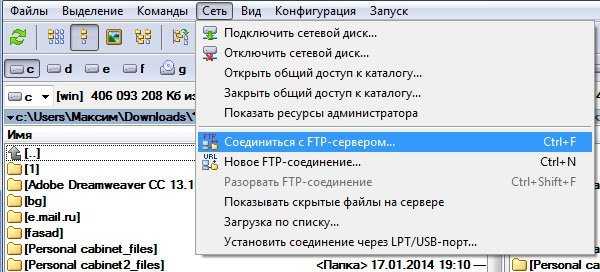
FTP-соединение
Выбрать нужное соединение и нажимаем кнопку «Соединиться».
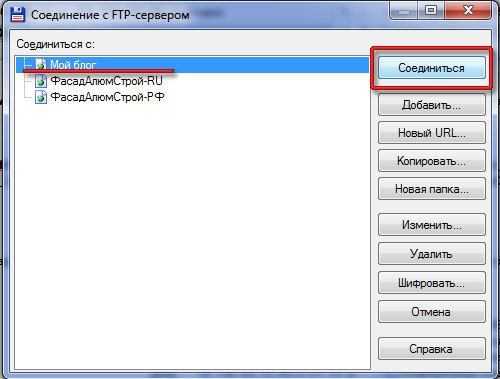
Выбор FTP-соединения
Открываем корень блога и копируем наш файл robots.txt, нажав клавишу F5.
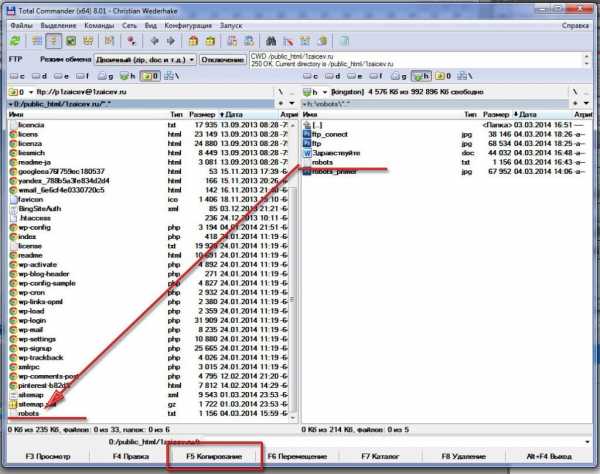
Копирование robots.txt на сервер
Вот теперь Ваш файл robots.txt будет исполнять надлежащие ему функции. Но я всё же рекомендую провести анализ robots.txt, чтобы удостоверится в отсутствии ошибок.
Анализ robots.txt
Для этого Вам потребуется войти в кабинет вебмастера Яндекс или Google. Рассмотрим примере Яндекс. Здесь можно провести анализ даже не подтверждая прав на сайт. Вам достаточно иметь почтовый ящик на Яндекс.
Открываем кабинет Яндекс.вебмастер.
Яндекс.вебмастер
На главной странице кабинета вебмастер, открываем ссылку «Проверить robots.txt».
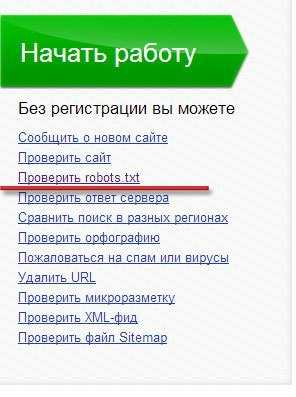
Проверка robots.txt
Для анализа потребуется ввести url адрес вашего блога и нажать кнопку «Загрузить robots.txt с сайта». Как только файл будет загружен нажимаем кнопку «Проверить».
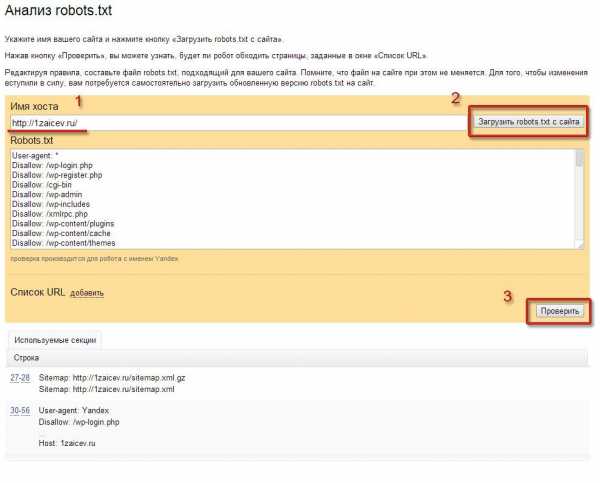
Анализ robots.txt
Отсутствие предупреждающих записей, свидетельствует о правильности создания файла robots.txt.
Теперь следует проверить ссылки Ваших материалов, дабы убедится, что Вы не запретили индексацию чего то нужного.
Для этого нажимаем на ссылку «Список URL добавить». Вводим ссылки Ваших материалов. И нажимаем кнопку «Проверить»
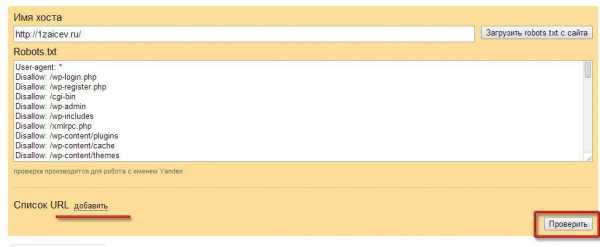
Добавление url
Ниже будет представлен результат. Где ясно и понятно какие материалы разрешены для показа поисковым роботам, а какие запрещены.
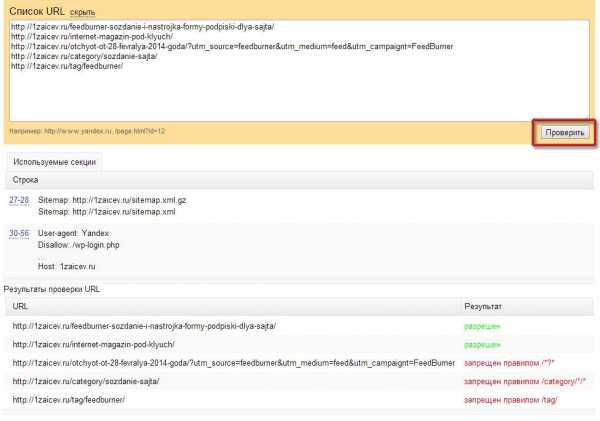
Результат анализа файла robots.txt
Здесь же вы можете вносить изменения в robots.txt и экспериментировать до получения нужного вам результата. Но помните, файл расположенный на вашем блоге при этом не меняется. Для этого вам потребуется полученный здесь результат скопировать в блокнот, сохранить как robots.txt и скопировать на Вас блог.
Кстати, если вам интересно как выглядит файл robots.txt на чьём-то блоге, вы может с лёгкостью его посмотреть. Для этого к адресу сайта нужно просто добавить /robots.txt
Пример:
https://1zaicev.ru/robots.txt
Вот теперь ваш robots.txt готов. И помните не откладывайте в долгий ящик создание файла robots.txt, от этого будет зависеть индексация вашего блога.
Если же вы хотите создать правильный robots.txt и при этом быть уверенным, что в индекс поисковых систем попадут только нужные страницы, то это можно сделать и автоматически с помощью плагина Clearfy.
На этом у меня всё. Всем желаю успехов. Если будут вопросы или дополнения пишите в комментариях.
До скорой встречи.
С уважением, Максим Зайцев.
1zaicev.ru
Правильный файл robots.txt для сайта
Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом. Примеры:
При указании путей директив Allow и Disallow можно использовать спецсимволы * и $, задавая, таким образом, определенные регулярные выражения.
Спецсимвол * означает любую (в том числе пустую) последовательность символов.
Спецсимвол $ означает конец строки, символ перед ним последний.
Директива Sitemap
Если вы используете описание структуры сайта с помощью файла Sitemap, укажите путь к файлу в качестве параметра директивы sitemap (если файлов несколько, укажите все). Пример:
User-agent: Yandex Allow: / sitemap: https://example.com/site_structure/my_sitemaps1.xml sitemap: https://example.com/site_structure/my_sitemaps2.xml
Директива является межсекционной, поэтому будет использоваться роботом вне зависимости от места в файле robots.txt, где она указана.
Робот запомнит путь к файлу, обработает данные и будет использовать результаты при последующем формировании сессий загрузки.
Директива Crawl-delay
Директива работает только с роботом Яндекса.
Если сервер сильно нагружен и не успевает отрабатывать запросы робота, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Перед тем, как изменить скорость обхода сайта, выясните к каким именно страницам робот обращается чаще.
- Проанализируйте логи сервера. Обратитесь к сотруднику, ответственному за сайт, или к хостинг-провайдеру.
- Посмотрите список URL на странице Индексирование → Статистика обхода в Яндекс.Вебмастере (установите переключатель в положение Все страницы).
Если вы обнаружите, что робот обращается к служебным страницам, запретите их индексирование в файле robots.txt с помощью директивы Disallow. Это поможет снизить количество лишних обращений робота.
Директива Clean-param
Директива работает только с роботом Яндекса.
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы:
www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex
Disallow:
Clean-param: ref /some_dir/get_book.plробот Яндекса сведет все адреса страницы к одному:
www.example.com/some_dir/get_book.pl?book_id=123Если на сайте доступна такая страница, именно она будет участвовать в результатах поиска.
Синтаксис директивы
Clean-param: p0[&p1&p2&..&pn] [path]В первом поле через символ & перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых нужно применить правило.
Примечание. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
Префикс может содержать регулярное выражение в формате, аналогичном файлу robots.txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. При этом символ * трактуется так же, как в файле robots.txt: в конец префикса всегда неявно дописывается символ *. Например:
Clean-param: s /forum/showthread.phpозначает, что параметр s будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php. Второе поле указывать необязательно, в этом случае правило будет применяться для всех страниц сайта.
Регистр учитывается. Действует ограничение на длину правила — 500 символов. Например:
Clean-param: abc /forum/showthread.php
Clean-param: sid&sort /forum/*.php
Clean-param: someTrash&otherTrashДиректива HOST
На данный момент Яндекс прекратил поддержку данной директивы.
Правильный robots.txt: настройка
Содержимое файла robots.txt отличается в зависимости от типа сайта (интернет-магазин, блог), используемой CMS, особенностей структуры и ряда других факторов. Поэтому заниматься созданием данного файла для коммерческого сайта, особенно если речь идет о сложном проекте, должен SEO-специалист с достаточным опытом работы.
Неподготовленный человек, скорее всего, не сможет принять правильного решения относительно того, какую часть содержимого лучше закрыть от индексации, а какой позволить появляться в поисковой выдаче.
Правильный Robots.txt пример для WordPress
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads Sitemap: http://site.ru/sitemap.xml # адрес карты сайтаUser-agent: GoogleBot # правила для Google (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # от индексирования, а удалять параметры меток, # Google такие правила не поддерживает Clean-Param: openstat # аналогично
Robots.txt пример для Joomla
User-agent: *Disallow: /administrator/Disallow: /cache/Disallow: /includes/Disallow: /installation/Disallow: /language/Disallow: /libraries/Disallow: /media/Disallow: /modules/Disallow: /plugins/Disallow: /templates/Disallow: /tmp/Disallow: /xmlrpc/Sitemap: http://путь к вашей карте XML формата
Robots.txt пример для Bitrix
User-agent: *Disallow: /*index.php$Disallow: /bitrix/Disallow: /auth/Disallow: /personal/Disallow: /upload/Disallow: /search/Disallow: /*/search/Disallow: /*/slide_show/Disallow: /*/gallery/*order=*Disallow: /*?print=Disallow: /*&print=Disallow: /*register=Disallow: /*forgot_password=Disallow: /*change_password=Disallow: /*login=Disallow: /*logout=Disallow: /*auth=Disallow: /*?action=Disallow: /*action=ADD_TO_COMPARE_LISTDisallow: /*action=DELETE_FROM_COMPARE_LISTDisallow: /*action=ADD2BASKETDisallow: /*action=BUYDisallow: /*bitrix_*=Disallow: /*backurl=*Disallow: /*BACKURL=*Disallow: /*back_url=*Disallow: /*BACK_URL=*Disallow: /*back_url_admin=*Disallow: /*print_course=YDisallow: /*COURSE_ID=Disallow: /*?COURSE_ID=Disallow: /*?PAGENDisallow: /*PAGEN_1=Disallow: /*PAGEN_2=Disallow: /*PAGEN_3=Disallow: /*PAGEN_4=Disallow: /*PAGEN_5=Disallow: /*PAGEN_6=Disallow: /*PAGEN_7=Disallow: /*PAGE_NAME=user_postDisallow: /*PAGE_NAME=detail_slide_showDisallow: /*PAGE_NAME=searchDisallow: /*PAGE_NAME=user_postDisallow: /*PAGE_NAME=detail_slide_showDisallow: /*SHOWALLDisallow: /*show_all=Sitemap: http://путь к вашей карте XML формата
Robots.txt пример для MODx
User-agent: *Disallow: /assets/cache/Disallow: /assets/docs/Disallow: /assets/export/Disallow: /assets/import/Disallow: /assets/modules/Disallow: /assets/plugins/Disallow: /assets/snippets/Disallow: /install/Disallow: /manager/Sitemap: http://site.ru/sitemap.xml
Robots.txt пример для Drupal
User-agent: *Disallow: /database/Disallow: /includes/Disallow: /misc/Disallow: /modules/Disallow: /sites/Disallow: /themes/Disallow: /scripts/Disallow: /updates/Disallow: /profiles/Disallow: /profileDisallow: /profile/*Disallow: /xmlrpc.phpDisallow: /cron.phpDisallow: /update.phpDisallow: /install.phpDisallow: /index.phpDisallow: /admin/Disallow: /comment/reply/Disallow: /contact/Disallow: /logout/Disallow: /search/Disallow: /user/register/Disallow: /user/password/Disallow: *register*Disallow: *login*Disallow: /top-rated-Disallow: /messages/Disallow: /book/export/Disallow: /user2userpoints/Disallow: /myuserpoints/Disallow: /tagadelic/Disallow: /referral/Disallow: /aggregator/Disallow: /files/pin/Disallow: /your-votesDisallow: /comments/recentDisallow: /*/edit/Disallow: /*/delete/Disallow: /*/export/html/Disallow: /taxonomy/term/*/0$Disallow: /*/edit$Disallow: /*/outline$Disallow: /*/revisions$Disallow: /*/contact$Disallow: /*downloadpipeDisallow: /node$Disallow: /node/*/track$Disallow: /*&Disallow: /*%Disallow: /*?page=0Disallow: /*sectionDisallow: /*orderDisallow: /*?sort*Disallow: /*&sort*Disallow: /*votesupdownDisallow: /*calendarDisallow: /*index.phpAllow: /*?page=Disallow: /*?Sitemap: http://путь к вашей карте XML формата
ВНИМАНИЕ!
CMS постоянно обновляются. Возможно, понадобиться закрыть от индексации другие страницы. В зависимости от цели, запрет на индексацию может сниматься или, наоборот, добавляться.
Проверить robots.txt
У каждого поисковика свои требования к оформлению файла robots.txt.
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка robotx.txt для поискового робота Яндекса
Сделать это можно при помощи специального инструмента от Яндекс — Яндекс.Вебмастер, еще и двумя вариантами.
Вариант 1:
Справа вверху выпадающий список — выберите Анализ robots.txt или по ссылке http://webmaster.yandex.ru/robots.xml
Вариант 2:
Этот вариант подразумевает, что ваш сайт добавлен в Яндекс Вебмастер и в корне сайта уже есть robots.txt.
Слева выберите Инструменты — Анализ robots.txt
Не стоит забывать о том, что все изменения, которые вы вносите в файл robots.txt, будут доступны не сразу, а спустя лишь некоторое время.
Проверка robotx.txt для поискового робота Google
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
- В Google Search Console выберите ваш сайт, перейдите к инструменту проверки и просмотрите содержание файла
robots.txt. Синтаксические и логические ошибки в нем будут выделены, а их количество – указано под окном редактирования. - Внизу на странице интерфейса укажите нужный URL в соответствующем окне.
- В раскрывающемся меню справа выберите робота.
- Нажмите кнопку ПРОВЕРИТЬ.
- Отобразится статус ДОСТУПЕН или НЕДОСТУПЕН. В первом случае роботы Google могут переходить по указанному вами адресу, а во втором – нет.
- При необходимости внесите изменения в меню и выполните проверку заново. Внимание! Эти исправления не будут автоматически внесены в файл robots.txt на вашем сайте.
- Скопируйте измененное содержание и добавьте его в файл robots.txt на вашем веб-сервере.

Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Генераторы robots.txt
- Сервис от SEOlib.ru.С помощью данного инструмента можно быстро получить и проверить ограничения в файле Robots.txt.
- Генератор от pr-cy.ru.В результате работы генератора Robots.txt вы получите текст, который необходимо сохранить в файл под названием Robots.txt и загрузить в корневой каталог вашего сайта.
webmaster-seo.ru
Robots.txt для Яндекса и Google
Правильная настройка файла robots.txt позволит исключить возможные проблемы, возникающие при индексации.
В частности, у владельца сайта имеется возможность ограничить индексирование служебных и личных разделов ресурса. Как создать файл и настроить его под разные поисковые системы, а также популярные CMS — поговорим в этой публикации.
Для чего нужен файл robots.txt
Как не трудно догадаться, этот файл содержит инструкции, предназначенные для поисковых ботов. Размещается он обязательно в корневой директории, благодаря чему индексацию страницы боты начнут именно с чтения условий, изложенных в robots.txt.
Таким образом, файл указывает поисковым роботам, какие директории сайта разрешены для индексирования, и какие этому процессу не подлежат.
Учитывая, что на процесс ранжирования наличие файла не влияет, много сайтов не содержат robots.txt. Но это не совсем верный путь. Рассмотрим преимущества robots.txt, которые он дает ресурсу.
Можно запретить индексирование ресурса целиком или частично, ограничить круг поисковых роботов, которые будут иметь право на проведение индексирования. Можно вовсе оградить ресурс от этого процесса (например, при создании или реконструкции сайта).
 Кроме того, файл роботс ограничивает доступ на ресурс всевозможных спам-роботов, цель которых — сканирование сайта на наличие электронных адресов, которые потом будут использоваться для рассылки спама. Не будем останавливаться на том, к чему это может привести — и так понятно.
Кроме того, файл роботс ограничивает доступ на ресурс всевозможных спам-роботов, цель которых — сканирование сайта на наличие электронных адресов, которые потом будут использоваться для рассылки спама. Не будем останавливаться на том, к чему это может привести — и так понятно.
От индексирования можно скрыть разделы сайта, предназначенные не для поисковых машин, а для определенного круга пользователей, разделы, содержащие приватную и прочую подобную информацию.
Как создать правильный robots.txt
Правильный robots легко написать вручную, не прибегая к помощи различных конструкторов. Процесс сводится к прописыванию нужных директив в обычном файле блокнота, который потом нужно сохранить под названием «robots» и закачать в корневую директорию собственного ресурса. Для одного сайта нужен один такой файл. В нем можно прописать инструкции для поисковых ботов всех нужных поисковых систем. То есть, делать отдельный файл под каждый поисковик не понадобится.
Что нужно прописывать в файле? Обязательно употребление двух директив: User-agent и Disallow. Первая определяет, какому боту адресовано данное послание, вторая показывает, какую страницу или директорию ресурса запрещено индексировать.
Чтобы задать одинаковые правила для всех ботов, можно в директиве User-agent вместо названия прописать символ «звездочку».
Файл robots.txt в таком случае будет выглядеть таким образом:
 Как можно догадаться, /file.html — это название конкретного файла, индексация которого запрещена, а /papka/ — название директории. В таком случае индексация не будет распространяться на все файлы, содержащиеся в ней.
Как можно догадаться, /file.html — это название конкретного файла, индексация которого запрещена, а /papka/ — название директории. В таком случае индексация не будет распространяться на все файлы, содержащиеся в ней.
Если нужно снять ограничения и разрешить индексацию всех страниц, файл будет выглядеть так:
 Особенности настройки robots.txt для Яндекс и Google
Особенности настройки robots.txt для Яндекс и Google
Файл robots.txt для Яндекса должен содержать обязательную директиву host. Это позволит избежать проблем с индексированием зеркала ресурса или иных дублей его страниц.
 Host — директива, которую понимают только боты Яндекса. Поэтому при создании файла robots.txt одновременно для Яндекса, Гугла и других поисковых систем, следует разделить директивы.
Host — директива, которую понимают только боты Яндекса. Поэтому при создании файла robots.txt одновременно для Яндекса, Гугла и других поисковых систем, следует разделить директивы.
 Создание файла robots.txt для Google ничем не отличается от описанной выше технологии. В директиве User-agent нужно прописать название бота поисковика: Googlebot, Googlebot-Image (для ограничения индексаций изображений),Googlebot-Mobile (для версий сайтов, рассчитанных на мобильные приложения) и т.п.
Создание файла robots.txt для Google ничем не отличается от описанной выше технологии. В директиве User-agent нужно прописать название бота поисковика: Googlebot, Googlebot-Image (для ограничения индексаций изображений),Googlebot-Mobile (для версий сайтов, рассчитанных на мобильные приложения) и т.п.
Желательно указать в файле путь к карте сайта — (директива sitemap). Благодаря этому робот будет быстрее ориентироваться на страницах ресурса, что значительно ускорит процесс индексации.
Кстати, разработчики Гугл неоднократно напоминали веб-мастерам, что файл robots.txt не должен превышать по размерам 500 Кб. Это непременно приведет к ошибкам при индексации. Если создавать файл вручную, то «достичь» такого размера, конечно, нереально. Но вот некоторые CMS, автоматически формирующие содержание robots.txt, могут значительно его «утяжелить».
Простое создание файла для любого поисковика
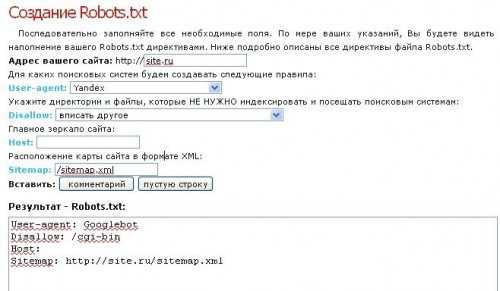
Если страшно наделать ошибок при написании файла (или просто лень этим заниматься), можно поручить создание нужных директив конструктору. Он прост, как дважды два, но небольшое объяснение по работе с ним все же приведем.
В первом поле прописывается адрес ресурса. Только после этого пользователю представится возможность выбрать поисковую систему, для которой устанавливаются данные правила (можно последовательно выбрать несколько поисковиков). Далее нужно указать папки и файлы, доступ к которым будет запрещен, прописать адрес зеркала сайта, указать расположение карты ресурса.
По мере заполнения полей в нижнем поле будут прописываться нужные директории. Все, что нужно в итоге — скопировать их в txt-файл и присвоить ему название robots.

Как проверить эффективность файла robots.txt
Для того, чтобы проанализировать действие файла в Яндексе, следует перейти на соответствующую страницу в разделе Яндекс.Вебмастер. В диалоговом окне следует указать имя сайта и нажать кнопку «загрузить».
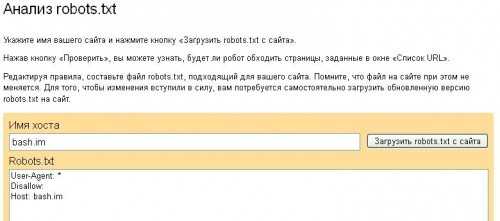

Система проанализирует файл robots.txt и укажет, будет ли поисковый робот обходить страницы, запрещенные к индексации. Если возникли проблемы, директивы можно отредактировать и проверить прямо в диалоговом окне, после чего скопировать отредактированный текст и вставить в свой файл robots.txt в корневом каталоге.
Аналогичную услугу предоставляет сервис «Инструменты для веб-мастеров» от поисковика Google

Создание robots.txt для WordPress , Joomla и Ucoz
Различные CMS, получившие широкую популярность на наших просторах, предлагают пользователям свои версии файлов robots.txt (или же не имеют их вовсе). Зачастую эти файлы либо чересчур универсальны и не учитывают особенностей ресурса пользователя, либо имеют ряд существенных недостатков.
Можно пытаться внести изменения в них вручную (что при недостатке знаний не очень-то эффективно), а можно воспользоваться опытом более профессиональных коллег. Как говорится, все уже сделано до нас. Например, robots.txt для WordPress может выглядеть таким образом:

 Строку www.site.ru, само собой, следует заменить на адрес сайта пользователя.
Строку www.site.ru, само собой, следует заменить на адрес сайта пользователя.
Файл robots.txt для Ucoz предоставляется автоматически. Он имеет оптимальные настройки, но единственный его недостаток — система создаст его спустя примерно месяц после создания ресурса. Если неохота ждать, можно написать файл самостоятельно. Выглядеть он будет так:

 Joomla! позволяет нескольким URL ссылаться на одну и ту же страницу, создавая для поисковых систем эффект дублирования контента. Избежать этого поможет установка robots.txt для Joomla такого содержания:
Joomla! позволяет нескольким URL ссылаться на одну и ту же страницу, создавая для поисковых систем эффект дублирования контента. Избежать этого поможет установка robots.txt для Joomla такого содержания:


В последних двух строчках, как несложно догадаться, нужно прописать данные собственного ресурса.


wildo.ru
Как сделать robots.txt для WordPress.Создаем правильный robots.txt для сайта на WordPress
Приветствую, друзья! В этом уроке мы поговорим о создании файла robots.txt, который показывает роботам поисковых систем, какие разделы Вашего сайта нужно посещать, а какие нет.
Фактически, с помощью этого служебного файла можно указать, какие разделы будут индексироваться в поисковых системах, а какие нет.
Создание файла robots.txt
1. Создайте обычный текстовый файл с названием robots в формате .txt.
2. Добавьте в него следующую информацию :
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= Host: site.com Sitemap: http://site.com/sitemap.xml
3. Замените в в текстовом файле строчку site.com на адрес Вашего сайта.
4. Сохраните изменения и загрузите файл robots.txt (с помощью FTP) в корневую папку Вашего сайта.
5. Готово.
Для просмотра и скачки примера, нажмите кнопку ниже и сохраните файл (Ctrl + S на клавиатуре).
Скачать пример файла robots.txtРазбираемся в файле robots.txt (директивы)
Давайте теперь более детально разберем, что именно и зачем мы добавили в файл robots.txt.
User-agent — директива, которая используется для указания названия поискового робота. С помощью этой директивы можно запретить или разрешить поисковым роботам посещать Ваш сайт. Примеры:
Запрещаем роботу Яндекса просматривать папку с кэшем:
User-agent: Yandex Disallow: /wp-content/cache
Разрешаем роботу Bing просматривать папку themes (с темами сайта):
User-agent: bingbot Allow: /wp-content/themes
Allow и Disallow — разрешающая и запрещающая директива. Примеры:
Разрешим боту Яндекса просматривать папку wp-admin:
User-agent: Yandex Allow: /wp-admin
Запретим всем ботам просматривать папку wp-content:
User-agent: * Disallow: /wp-content
В нашем robots.txt мы не используем директиву Allow, так как всё, что не запрещено боту с помощью Disallow — по умолчанию будет разрешено.
Host — директива, с помощью которой нужно указать главное зеркало сайта, которое и будет индексироваться роботом.
Sitemap — используя эту директиву, нужно указать путь к карте сайта. Напомню, что карта сайта является очень важным инструментом при продвижении сайта! Обязательно указывайте её в этой директиве!
Если остались какие-то вопросы — задавайте их в комментарий. Если же информации в этом уроке для Вас оказалось недостаточно, рекомендую почитать подробнее о всех директивах и способах их использования перейдя по этой ссылке.
Приветствую, друзья! В этом уроке мы поговорим о создании файла robots.txt, который показывает роботам поисковых систем, какие разделы Вашего сайта нужно посещать, а какие нет. Фактически, с помощью этого служебного файла можно указать, какие разделы будут индексироваться в поисковых системах, а какие нет. Создание файла robots.txt 1. Создайте обычный текстовый файл с названием robots в формате .txt. 2. Добавьте в него следующую информацию : User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes…
Создание и настройка robots.txt
Рейтинг: 4.49 ( 31 голосов ) 100wp-lessons.com
что это такое, для чего нужен, как его создать, чем грозит отсутствие этого файла
Тематический трафик – альтернативный подход в продвижении бизнеса

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Robots.txt — это текстовый файл, содержащий сведения для поисковых роботов, которые помогают проиндексировать страницы портала.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
Представьте, что вы отправились за сокровищами на остров. У вас есть карта. Там указан маршрут: “Подойти к большому пню. От него сделать 10 шагов на восток, затем дойти до обрыва. Повернуть вправо, найти пещеру”.
Это — указания. Следуя им, вы идете по маршруту и находите клад. Примерно также работает и поисковой бот, когда начинает индексировать сайт или страницу. Он находит файл robots.txt. В нем считывает, какие страницы нужно проиндексировать, а какие — нет. И, следуя этим командам, он обходит портал и добавляет его страницы в индекс.
Для чего нужен robots.txt
Роботы поисковых систем начинают ходить по сайтам и индексировать страницы после того, как сайт загружен на хостинг и прописаны dns. Они делают свою работу вне зависимости от того, есть у вас какие-то технические файлы или нет. Роботс указывает поисковикам, что при обходе веб-сайта нужно учитывать параметры, которые в нем находится.
Отсутствие файла robots.txt может привести к проблемам со скоростью обхода сайта и присутствия мусора в индексе. Некорректная настройка файла чревата исключением из индекса важных частей ресурса и присутствием в выдаче ненужных страниц.
Все это, как результат, ведет к проблемам с продвижением.
Рассмотрим подробнее, какие инструкции содержатся в этом файле, как они влияют на поведение бота у вас на сайте.
Как сделать robots.txt
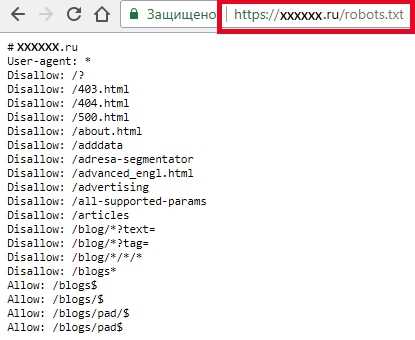
Для начала проверьте, есть ли у вас этот файл.
Введите в адресной строке браузера адрес сайта и через слэш имя файла, например, https://www.xxxxx.ru/robots.txt
Если файл присутствует, то на экране появится список его параметров.
Если файла нет:
- Файл создается в обычном текстом редакторе типо блокнота или Notepad++.
- Нужно задать имя robots, расширение .txt. Внести данные с учетом принятых стандартов оформления.
- Можно проверить на предмет ошибок с помощью сервисов типа вебмастера Яндекса.Там нужно выбрать пункт «Анализ robots.txt» в разделе «Инструменты» и следовать подсказкам.
- Когда файл готов, залейте его в корневой каталог сайта.
Правила настройки
У поисковиков не один робот. Некоторые боты индексируют только текстовый контент, некоторые — только графический. Да и у самих поисковых систем схема работы краулеров может быть разной. При составлении файла это нужно учитывать.
Некоторые из них могут игнорировать часть правил, например, GoogleBot не реагирует на информацию о том, какое зеркало сайта считать главным. Но в целом, они воспринимают и руководствуются файлом.
Синтаксис файла
Параметры документа: имя робота (бота) «User-agent», директивы: разрешающая «Allow» и запрещающая «Disallow».
Сейчас есть две ключевых поисковых системы: Яндекс и Google, соответственно, важно при составлении сайта учитывать требования обеих.
Формат создания записей выглядит следующим образом, обратите внимание на обязательные пробелы и пустые строки.
Директива User-agent
Робот ищет записи, которые начинаются с User-agent, там должны содержаться указания на название поискового робота. Если оно не указано, считается, что доступ ботов неограничен.
Директивы Disallow и Allow
Если нужно запретить индексацию в robots.txt, используют Disallow. С ее помощью ограничивают доступ бота к сайту или некоторым разделам.
Если роботс.тхт не содержит ни одной запрещающей директивы «Disallow», считается, что разрешена индексация всего сайта. Обычно запреты прописываются после каждого бота отдельно.
Вся информация, которая указана после значка #, является комментариями и не считывается машиной.
Allow применяют, чтобы разрешить доступ.
Символ звездочка служит указанием на то, что относится ко всем: User-agent: *.
Такой вариант, наоборот, означает полный запрет индексации для всех.
Запрет на просмотр всего содержимого определенной папки-каталога
Для блокировки одного файла нужно указать его абсолютный путь
Директивы Sitemap, Host
В файл, как правило, добавляют ссылку на «Sitemap» (карту сайта), чтобы облегчить боту ее поиск.
Для Яндекса в директиве Host принято указывать, какое зеркало вы хотите назначить главным. А Гугл, как мы помним, его игнорирует. Если зеркал нет, просто зафиксируйте, как считаете корректным писать имя вашего веб-сайта с www или без.
Директива Clean-param
Ее можно применять, если URL страниц веб-сайта содержат изменяемые параметры, не влияющие на их содержимое (это могут быть id пользователей, рефереров).
Например, в адресе страниц «ref» определяет источник трафика, т.е. указывает на то, откуда на сайт пришел посетитель. Для всех пользователей страница будет одинаковая.
Роботу можно указать на это, и он не будет загружать повторяющуюся информацию. Это снизит загруженность сервера.
Директива Crawl-delay
С помощью нее можно определить, с какой частотой бот будет загружать страницы для анализа. Эта команда применяется, когда сервер перегружен и указывает, что процесс обхода нужно ускорить.
Ошибки robots.txt
- Файл не находится в корневом каталоге. Глубже робот его искать не будет и не учтет.
- Буквы в названии должны быть маленькие латинские.
Ошибка в названии, иногда упускают букву S на конце и пишут robot. - Нельзя использовать кириллические символы в файле robots.txt. Если нужно указать домен на русском языке, используйте формат в специальной кодировке Punycode.
- Это метод преобразования доменных имен в последовательность ASCII-символов. Для этого можно воспользоваться специальными конвертерами.
Выглядит такая кодировка следующим образом:
сайт.рф = xn--80aswg.xn--p1ai
Дополнительную информацию, что закрывать в robots txt и по настройкам в соответствии с требованиями поисковиков Гугл и Яндекс можно найти в справочных документах. Для различных cms также могут быть свои особенности, это следует учесть.
semantica.in
Создать robots.txt онлайн
Чтобы активировать PRO версию программы достаточно только нажать и поделиться страницей через социальные сети выше.
Robots.txt является обыкновенным текстовым файлом, располагающимся в корне вашего сайта, просмотреть и отредактировать его можно используя любой текстовый редактор. В данном файлике записаны инструкции, которыми должны руководствоваться поисковые машины (роботы). Собственно, отсюда и пошло название этого документа. Инструкции эти указывают поисковику, что подлежит индексированию, а что трогать не нужно. Наверное, каждый вебмастер хотел бы, чтобы созданный им сайт как можно быстрее был проиндексирован поисковой системой, причем чтобы этот процесс прошел правильно и без ошибок. Поэтому, нужно понимать, что без грамотно составленного файла robots.txt это маловероятно, следовательно, нужно позаботиться о его создании. Конечно же вы можете самостоятельно написать данный файл, к тому же примеров в сети очень много. Но, намного правильнее и быстрее будет воспользоваться нашим инструментом создания robots.txt – это самый эффективный способ. Все что от Вас требуется это заполнить форму на нашем сайте и все. В результате вы получите уже готовый текст, который нужно просто вставить в документ и сохранить в корне вашего сайта под именем Robots.txt. При этом у вас есть возможность полностью запретить индексирование своего сайта, хотя вряд ли это кому-то понадобится. Здесь вам нужно будет указать местонахождение карты вашего сайта, а если у вас ее нету, то можно просто не заполнять данное поле. Далее вы можете выбрать поисковые системы, которым дадите право проводить индексирование страниц вашего ресурса. Рекомендуется выбирать все, это даст наиболее положительный эффект в плане посещаемости сайта. В перечне присутствуют все основные поисковые машины. Далее вам предлагается указать те страницы, которые вы бы не хотели видеть в индексе поисковиков. На этом все, ваш файлик готов, можете выкладывать его к себе на сайт.Есть ли какие-то отличия Robots.txt для Яндекса в сравнении с файлами для других роботов?
На самом деле каждая поисковая машина использует разные методы индексирования, и вообще работают они по-разному. Каждый поисковик имеет свои методики ранжирования, присвоения сайтам определенного места в своем списке. Однако, практически все они одинаково индексируют и понимают файл Robots.txt. Практика свидетельствует, что один файл Robots.txt подходит абсолютно ко всем поисковым системам и с ним не возникает никаких проблем.Есть ли возможность проверить существующий файл Robots.txt?
Если вы сами писали данный файл, или использовали другой генератор, и сомневаетесь в его работоспособности, то можете проверить его с помощью специального сервиса на нашем сайте. Если в ходе такой проверки обнаружатся те или иные проблемы, то вы с легкостью сможете сгенерировать новый файлик воспользовавшись нашим инструментом. Специалисты всегда рекомендуют проверять самодельные файлы Robots.txt с помощью уже проверенных генераторов, чтобы избежать возможных проблем в будущем.sitespy.ru