Анализ robots.txt — Вебмастер. Справка
- Как проверить файл
- Как узнать, обойдет ли робот определенный URL
- Как отслеживать изменения файла
- Вопросы и ответы
Инструмент Анализ robots.txt помогает проверить, правильно ли составлен файл robots.txt или написать содержимое файла и после проверки скопировать его в robots.txt.
Также инструмент поможет отследить изменения в файле и скачать определенную версию.
- Как проверить файл
- Как узнать, обойдет ли робот определенный URL
- Как отслеживать изменения файла
- Вопросы и ответы
- Если сайт добавлен в Яндекс Вебмастер и права на его управление подтверждены
Содержимое файла появится на странице Инструменты → Анализ robots.txt после подтверждения прав на управление сайтом.
Если содержимое отображается на странице Анализ robots.txt, нажмите кнопку Проверить.
- Если сайт не добавлен в Яндекс Вебмастер
Перейдите на страницу Анализ robots.
 txt.
txt.В поле Проверяемый сайт укажите адрес вашего сайта. Например, https://example.com.
Нажмите значок . Содержимое robots.txt и результаты анализа отобразятся ниже.
 txt.
txt.В предназначенных для робота Яндекса (User-agent: Yandex или User-agent:*) разделах инструмент проверяет директивы, руководствуясь правилами использования robots.txt. Остальные разделы проверяются в соответствии со стандартом.
После проверки могут отобразиться:
Предупреждения. Они сообщают об отклонении от правил, которое инструмент может исправить самостоятельно. Также предупреждения указывают на потенциальную проблему, связанную с опечаткой или неточностью в написании правил.
Ошибки в файле. Это значит, что инструмент не может обработать строку, секцию или весь файл из-за серьезных ошибок в синтаксисе, допущенных при составлении директив.
Подробное описание см.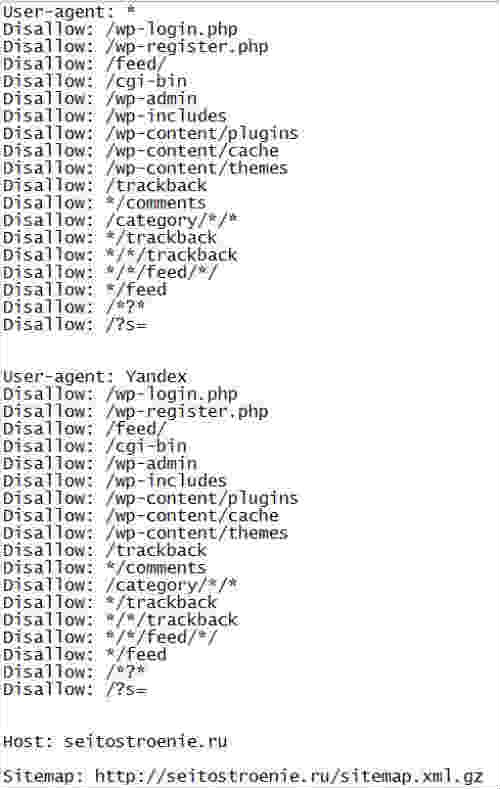 в разделе Справочник по ошибкам анализа robots.txt.
в разделе Справочник по ошибкам анализа robots.txt.
Когда ваш файл robots.txt загружен в Яндекс Вебмастер, на странице Анализ robots.txt отображается блок Разрешены ли URL?.
В поле Список URL укажите адрес страницы, которую хотите проверить. Можно указать полный URL или адрес относительно корневого каталога сайта. Например, https://example.com/page/ или /page/.
Нажмите кнопку Проверить.
Если URL разрешен для индексирования роботами Яндекса, напротив адреса появится значок , если запрещен — отобразится адрес, выделенный красным.
Примечание. Доступна история изменений за шесть месяцев. Максимальное количество сохраненных версий — 100.
Чтобы своевременно узнавать об изменениях файла robots.txt, настройте уведомления.
Яндекс Вебмастер регулярно проверяет обновления файла и сохраняет версии с учетом даты и времени изменения. Чтобы их посмотреть, перейдите на страницу Инструменты → Анализ robots.txt.
Список версий отображается, если одновременно выполнены следующие условия:
вы добавили сайт в Яндекс Вебмастер и подтвердили права на управление сайтом;
в Яндекс Вебмастере есть информация об изменениях robots.
 txt.
txt.
Вы можете:
- Просмотреть текущую и предыдущие версии файла
Выберите из списка Версия robots.txt версию файла. В поле ниже отобразится содержимое robots.txt, а также результаты анализа.
- Скачать выбранную версию файла
Выберите из списка Версия robots.txt версию файла.
Нажмите кнопку Скачать. Файл сохранится на вашем устройстве в формате TXT.
Ошибка «Этот URL не принадлежит вашему домену»
Скорее всего, в списке URL вы указали адрес одного из зеркал вашего сайта, например http://example.com вместо http://www.example.com. Формально это два различных URL. Проверяемые URL должны принадлежать сайту, для которого производится анализ robots.txt.
Укажите инструмент, в работе которого вы нашли ошибку, опишите ситуацию как можно подробнее, а при необходимости приложите скриншот, иллюстрирующий ситуацию.
Как создать файл Robots.txt: настройка, проверка, индексация
В SEO мелочей не бывает. Иногда на продвижение сайта может оказать влияние всего лишь один небольшой файл — Robots.txt. Если вы хотите, чтобы ваш сайт зашел в индекс, чтобы поисковые роботы обошли нужные вам страницы, нужно прописать для них рекомендации.
«Разве это возможно?», — спросите вы. Возможно. Для этого на вашем сайте должен быть файл robots.txt. Как правильно составить файл роботс, настроить и добавить на сайт – разбираемся в этой статье.
Сократите бюджет таргетированной и контекстной рекламы с click.ru
Click.ru вернёт до 15% от рекламных расходов.
- Перенесите рекламные кабинеты в click.ru.
- Чем больше вы тратите на рекламу, тем больший процент от расходов мы вернём.
- Это настоящие деньги. И click.ru выплатит их на карту, на электронные кошельки, или вы можете реинвестировать их в рекламу.
Сократить бюджет >> Реклама
Читайте также: Как проиндексировать сайт в Яндексе и Google
Что такое robots.txt и для чего нужен
Robots.txt – это обычный текстовый файл, который содержит в себе рекомендации для поисковых роботов: какие страницы нужно сканировать, а какие нет.
Важно: файл должен быть в кодировке UTF-8, иначе поисковые роботы могут его не воспринять.
Зайдет ли в индекс сайт, на котором не будет этого файла? Зайдет, но роботы могут «выхватить» те страницы, наличие которых в результатах поиска нежелательно: например, страницы входа, админпанель, личные страницы пользователей, сайты-зеркала и т.п. Все это считается «поисковым мусором»:
Если в результаты поиска попадёт личная информация, можете пострадать и вы, и сайт. Ещё один момент – без этого файла индексация сайта будет проходить дольше.
В файле Robots.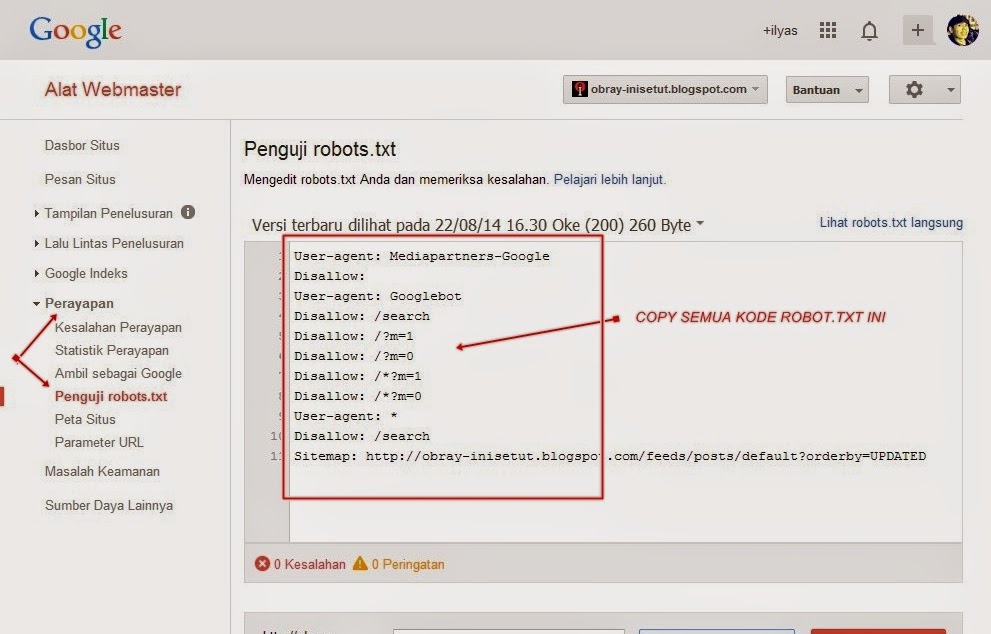 txt можно задать три типа команд для поисковых пауков:
txt можно задать три типа команд для поисковых пауков:
- сканирование запрещено;
- сканирование разрешено;
- сканирование разрешено частично.
Все это прописывается с помощью директив.
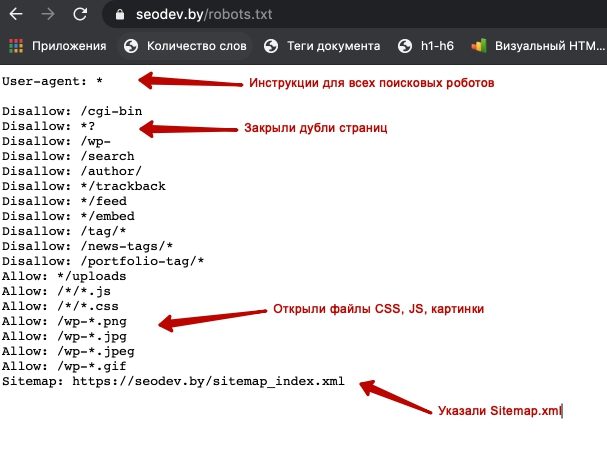
Как создать правильный файл Robots.txt для сайта
Файл Robots.txt можно создать просто в программе «Блокнот», которая по умолчанию есть на любом компьютере. Прописывание файла займет даже у новичка максимум полчаса времени (если знать команды).
Также можно использовать другие программы – Notepad, например. Есть и онлайн сервисы, которые могут сгенерировать файл автоматически. Например, такие как CY-PR.com или Mediasova.
Вам просто нужно указать адрес своего сайта, для каких поисковых систем нужно задать правила, главное зеркало (с www или без). Дальше сервис всё сделает сам.
Лично я предпочитаю старый «дедовский» способ – прописать файл вручную в блокноте. Есть ещё и «ленивый способ» — озадачить этим своего разработчика 🙂 Но даже в таком случае вы должны проверить, правильно ли там всё прописано. Поэтому давайте разберемся, как составить этот самый файл, и где он должен находиться.
Поэтому давайте разберемся, как составить этот самый файл, и где он должен находиться.
Это интересно: Как увеличить посещаемость сайта
Где должен находиться файл Robots
Готовый файл Robots.txt должен находиться в корневой папке сайта. Просто файл, без папки:
Хотите проверить, есть ли он на вашем сайте? Вбейте в адресную строку адрес: site.ru/robots.txt. Вам откроется вот такая страничка (если файл есть):
Файл состоит из нескольких блоков, отделённых отступом. В каждом блоке – рекомендации для поисковых роботов разных поисковых систем (плюс блок с общими правилами для всех), и отдельный блок со ссылками на карту сайта – Sitemap.
Внутри блока с правилами для одного поискового робота отступы делать не нужно.
Каждый блок начинается директивой User-agent.
После каждой директивы ставится знак «:» (двоеточие), пробел, после которого указывается значение (например, какую страницу закрыть от индексации).
Нужно указывать относительные адреса страниц, а не абсолютные. Относительные – это без «www.site.ru». Например, вам нужно запретить к индексации страницу www.site.ru/shop. Значит после двоеточия ставим пробел, слэш и «shop»:
Disallow: /shop.
Звездочка (*) обозначает любой набор символов.
Знак доллара ($) – конец строки.
Вы можете решить – зачем писать файл с нуля, если его можно открыть на любом сайте и просто скопировать себе?
Для каждого сайта нужно прописывать уникальные правила. Нужно учесть особенности CMS. Например, та же админпанель находится по адресу /wp-admin на движке WordPress, на другом адрес будет отличаться. То же самое с адресами отдельных страниц, с картой сайта и прочим.
Читайте также: Как найти и удалить дубли страниц на сайте
Настройка файла Robots.txt: индексация, главное зеркало, диррективы
Как вы уже видели на скриншоте, первой идет директива User-agent. Она указывает, для какого поискового робота будут идти правила ниже.
Она указывает, для какого поискового робота будут идти правила ниже.
User-agent: * — правила для всех поисковых роботов, то есть любой поисковой системы (Google, Yandex, Bing, Рамблер и т.п.).
User-agent: Googlebot – указывает на правила для поискового паука Google.
User-agent: Yandex – правила для поискового робота Яндекс.
Для какого поискового робота прописывать правила первым, нет никакой разницы. Но обычно сначала пишут рекомендации для всех роботов.
Рекомендации для каждого робота, как я уже писала, отделяются отступом.
Disallow: Запрет на индексацию
Чтобы запретить индексацию сайта в целом или отдельных страниц, используется директива Disallow.
Например, вы можете полностью закрыть сайт от индексации (если ресурс находится на доработке, и вы не хотите, чтобы он попал в выдачу в таком состоянии). Для этого нужно прописать следующее:
User-agent: *
Disallow: /
Таким образом всем поисковым роботам запрещено индексировать контент на сайте.
А вот так можно открыть сайт для индексации:
User-agent: *
Disallow:
Потому проверьте, стоит ли слеш после директивы Disallow, если хотите закрыть сайт. Если хотите потом его открыть – не забудьте снять правило (а такое часто случается).
Чтобы закрыть от индексации отдельные страницы, нужно указать их адрес. Я уже писала, как это делается:
User-agent: *
Disallow: /wp-admin
Таким образом на сайте закрыли от сторонних взглядов админпанель.
Что нужно закрывать от индексации в обязательном порядке:
- административную панель;
- личные страницы пользователей;
- корзины;
- результаты поиска по сайту;
- страницы входа, регистрации, авторизации.
Можно закрыть от индексации и отдельные типы файлов. Допустим, у вас на сайте есть некоторые .pdf-файлы, индексация которых нежелательна. А поисковые роботы очень легко сканируют залитые на сайт файлы. Закрыть их от индексации можно следующим образом:
User-agent: *
Disallow: /*.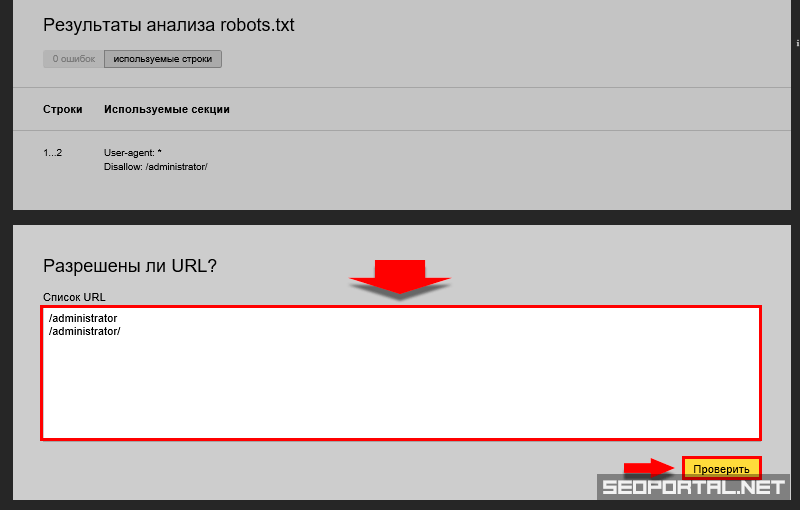 pdf$
pdf$
Как отрыть сайт для индексации
Даже при полностью закрытом от индексации сайте можно открыть роботам путь к определённым файлам или страницам. Допустим, вы переделываете сайт, но каталог с услугами остается нетронутым. Вы можете направить поисковых роботов туда, чтобы они продолжали индексировать раздел. Для этого используется директива Allow:
User-agent: *
Allow: /uslugi
Disallow: /
Главное зеркало сайта
До 20 марта 2018 года в файле robots.txt для поискового робота Яндекс нужно было указывать главное зеркало сайта через директиву Host. Сейчас этого делать не нужно – достаточно настроить постраничный 301-редирект.
Что такое главное зеркало? Это какой адрес вашего сайта является главным – с www или без. Если не настроить редирект, то оба сайта будут проиндексированы, то есть, будут дубли всех страниц.
Карта сайта: robots.txt sitemap
После того, как прописаны все директивы для роботов, необходимо указать путь к Sitemap. Карта сайта показывает роботам, что все URL, которые нужно проиндексировать, находятся по определённому адресу. Например:
Карта сайта показывает роботам, что все URL, которые нужно проиндексировать, находятся по определённому адресу. Например:
Sitemap: site.ru/sitemap.xml
Когда робот будет обходить сайт, он будет видеть, какие изменения вносились в этот файл. В итоге новые страницы будут индексироваться быстрее.
Читайте по теме: Как сделать карту сайта
Директива Clean-param
В 2009 году Яндекс ввел новую директиву – Clean-param. С ее помощью можно описать динамические параметры, которые не влияют на содержание страниц. Чаще всего данная директива используется на форумах. Тут возникает много мусора, например id сессии, параметры сортировки. Если прописать данную директиву, поисковый робот Яндекса не будет многократно загружать информацию, которая дублируется.
Прописать эту директиву можно в любом месте файла robots.txt.
Параметры, которые роботу не нужно учитывать, перечисляются в первой части значения через знак &:
Clean-param: sid&sort /forum/viewforum. php
php
Эта директива позволяет избежать дублей страниц с динамическими адресами (которые содержат знак вопроса).
Директива Crawl-delay
Эта директива придёт на помощь тем, у кого слабый сервер.
Приход поискового робота – это дополнительная нагрузка на сервер. Если у вас высокая посещаемость сайта, то ресурс может попросту не выдержать и «лечь». В итоге робот получит сообщение об ошибке 5хх. Если такая ситуация будет повторяться постоянно, сайт может быть признан поисковой системой нерабочим.
Представьте, что вы работаете, и параллельно вам приходится постоянно отвечать на звонки. Ваша продуктивность в таком случае падает.
Так же и с сервером.
Вернемся к директиве. Crawl-delay позволяет задать задержку сканирования страниц сайта с целью снизить нагрузку на сервер. Другими словами, вы задаете период, через который будут загружаться страницы сайта. Указывается данный параметр в секундах, целым числом:
Crawl-delay: 2
Комментарии в robots.
 txt
txtБывают случаи, когда вам нужно оставить в файле комментарий для других вебмастеров. Например, если ресурс передаётся в работу другой команде или если над сайтом работает целая команда.
В этом файле, как и во всех других, можно оставлять комментарии для других разработчиков.
Делается это просто – перед сообщением нужно поставить знак решетки: «#». Дальше вы можете писать свое примечание, робот не будет учитывать написанное:
User-agent: *
Disallow: /*. xls$
#закрыл прайсы от индексации
Как проверить файл robots.txt
После того, как файл написан, нужно узнать, правильно ли. Для этого вы можете использовать инструменты от Яндекс и Google.
Через Яндекс.Вебмастер robots.txt можно проверить на вкладке «Инструменты – Анализ robots.txt»:
На открывшейся странице указываем адрес проверяемого сайта, а в поле снизу вставляем содержимое своего файла. Затем нажимаем «Проверить». Сервис проверит ваш файл и укажет на возможные ошибки:
Также можно проверить файл robots. txt через Google Search Console, если у вас подтверждены права на сайт.
txt через Google Search Console, если у вас подтверждены права на сайт.
Для этого в панели инструментов выбираем «Сканирование – Инструмент проверки файла robots.txt».
На странице проверки вам тоже нужно будет скопировать и вставить содержимое файла, затем указать адрес сайта:
Потом нажимаете «Проверить» — и все. Система укажет ошибки или выдаст предупреждения.
Останется только внести необходимые правки.
Если в файле присутствуют какие-то ошибки, или появятся со временем (например, после какого-то очередного изменения), инструменты для вебмастеров будут присылать вам уведомления об этом. Извещение вы увидите сразу, как войдете в консоль.
Это интересно: 20 самых распространённых ошибок, которые убивают ваш сайт
Частые ошибки в заполнении файла robots.txt
Какие же ошибки чаще всего допускают вебмастера или владельцы ресурсов?
1. Файла вообще нет. Это встречается чаще всего, и выявляется при SEO-аудите ресурса.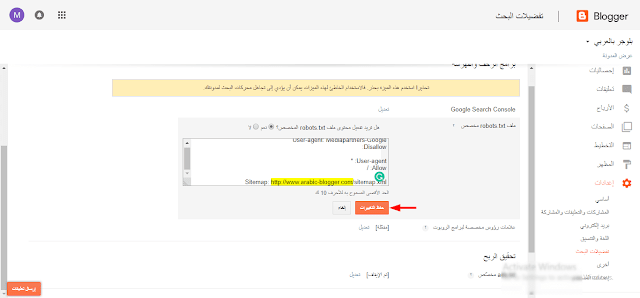 Как правило, на тот момент уже заметно, что сайт индексируется не так быстро, как хотелось бы, или в индекс попали мусорные страницы.
Как правило, на тот момент уже заметно, что сайт индексируется не так быстро, как хотелось бы, или в индекс попали мусорные страницы.
2. Перечисление нескольких папок или директорий в одной инструкции. То есть вот так:
Allow: /catalog /uslugi /shop
Называется «зачем писать больше…». В таком случае робот вообще не знает, что ему можно индексировать. Каждая инструкция должна иди с новой строки, запрет или разрешение на индексацию каждой папки или страницы – это отдельная рекомендация.
3. Разные регистры. Название файла должно быть с маленькой буквы и написано маленькими буквами – никакого капса. То же самое касается и инструкций: каждая с большой буквы, все остальное – маленькими. Если вы напишете капсом, это будет считаться уже совсем другой директивой.
4. Пустой User-agent. Нужно обязательно указать, для какой поисковой системы идет набор правил. Если для всех – ставим звездочку, но никак нельзя оставлять пустое место.
5. Забыли открыть ресурс для индексации после всех работ – просто не убрали слеш после Disallow.
6. Лишние звездочки, пробелы, другие знаки. Это просто невнимательность.
Регулярно заглядывайте в инструменты для вебмастеров и вовремя исправляйте возможные ошибки в своем файле robots.txt.
Удачного вам продвижения!
Как добавить файл robots.txt
Текстовый файл robots или файл robots.txt (часто ошибочно называемый файлом robot.txt) является обязательным для каждого веб-сайта. Добавление файла robots.txt в корневую папку вашего сайта — очень простой процесс, и наличие этого файла на самом деле является «знаком качества» для поисковых систем. Давайте посмотрим на параметры robots.txt, доступные для вашего сайта.
Что такое текстовый файл robots?
Файл robots.txt – это простой текстовый файл в формате ASCII, который сообщает поисковым системам, на какие сайты им нельзя заходить, что также известно как стандарт исключения роботов. Любые файлы или папки, перечисленные в этом документе, не будут просканированы и проиндексированы поисковыми роботами. Наличие robots.txt, даже пустого, показывает, что вы признаете, что поисковые системы разрешены на вашем сайте и что они могут иметь к нему свободный доступ. Мы рекомендуем добавить текстовый файл robots в ваш основной домен и все поддомены на вашем сайте.
Любые файлы или папки, перечисленные в этом документе, не будут просканированы и проиндексированы поисковыми роботами. Наличие robots.txt, даже пустого, показывает, что вы признаете, что поисковые системы разрешены на вашем сайте и что они могут иметь к нему свободный доступ. Мы рекомендуем добавить текстовый файл robots в ваш основной домен и все поддомены на вашем сайте.
Параметры форматирования robots.txt
Создание файла robots.txt — простой процесс. Выполните следующие простые шаги:
- Откройте Блокнот, Microsoft Word или любой текстовый редактор и сохраните файл как «роботы», все в нижнем регистре, обязательно выбрав .txt в качестве расширения типа файла (в Word выберите «Обычный текст»). .
- Затем добавьте в файл следующие две строки текста:
User-agent: *
«User-agent» — это другое слово для роботов или пауков поисковых систем. Звездочка (*) означает, что эта строка относится ко всем паукам. Здесь нет файлов или папок, перечисленных в строке «Запретить», что означает, что каждый каталог на вашем сайте может быть доступен. Это основной текстовый файл robots.
Это основной текстовый файл robots.
- Блокировка поисковых роботов на всем вашем сайте также является одной из опций robots.txt. Для этого добавьте в файл эти две строки:
User-agent: *
Disallow: /
- Если вы хотите заблокировать пауков из определенных областей вашего сайта, ваш robots.txt может выглядеть примерно так:
User-agent: *
Disallow: /database/
Disallow: /scripts/
Эти три строки сообщают всем роботам, что им не разрешен доступ к чему-либо в каталогах или подкаталогах базы данных и скриптов. Имейте в виду, что в строке Disallow можно использовать только один файл или папку. Вы можете добавить столько строк Disallow, сколько вам нужно.
- Не забудьте добавить XML-файл карты сайта, удобный для поисковых систем, в текстовый файл robots. Это гарантирует, что пауки смогут найти вашу карту сайта и легко проиндексировать все страницы вашего сайта. Используйте этот синтаксис:
Карта сайта: http://www.
- После завершения сохраните и загрузите файл robots.txt в корневой каталог вашего сайта. Например, если ваш домен www.mydomain.com, вы разместите файл по адресу www.mydomain.com/robots.txt.
- Когда файл будет на месте, проверьте файл robots.txt на наличие ошибок.
Search Guru может помочь реализовать этот и другие технические элементы SEO. Свяжитесь с нами сегодня чтобы начать!
Как правильно настроить файл robots.txt для своего сайта
Если у вас есть веб-сайт, вы, вероятно, слышали о файле robots.txt (или о «стандарте исключения роботов»). Есть у вас или нет, пришло время узнать об этом, потому что этот простой текстовый файл является важной частью вашего сайта. Это может показаться незначительным, но вы можете быть удивлены тем, насколько это важно.
Давайте посмотрим, что такое файл robots.txt, для чего он нужен и как его правильно настроить для вашего сайта.
Что такое файл robots.
 txt?
txt?Чтобы понять, как работает файл robots.txt, вам нужно немного узнать о поисковых системах. Короткая версия заключается в том, что они рассылают «краулеров», то есть программы, которые рыщут в Интернете в поисках информации. Затем они сохраняют часть этой информации, чтобы позже направить людей к ней.
Эти поисковые роботы, также известные как «боты» или «пауки», находят страницы на миллиардах веб-сайтов. Поисковые системы дают им указания, куда идти, но отдельные веб-сайты также могут общаться с ботами и сообщать им, какие страницы им следует просматривать.
В большинстве случаев они на самом деле делают обратное и говорят им, какие страницы им не следует просматривать. Такие вещи, как административные страницы, серверные порталы, страницы категорий и тегов и другие вещи, которые владельцы сайтов не хотят отображать в поисковых системах. Эти страницы по-прежнему видны пользователям и доступны всем, у кого есть на это разрешение (часто всем).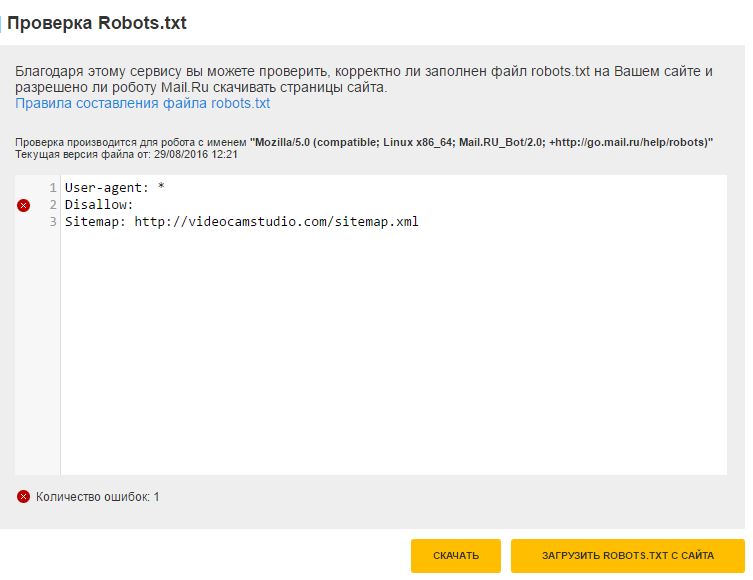
Но, говоря этим паукам не индексировать некоторые страницы, файл robots.txt делает всем одолжение. Если бы вы искали «MakeUseOf» в поисковой системе, хотели бы вы, чтобы наши административные страницы отображались высоко в рейтинге? Нет. Это никому не принесет пользы, поэтому мы просим поисковые системы не отображать их. Его также можно использовать, чтобы поисковые системы не проверяли страницы, которые могут не помочь им классифицировать ваш сайт в результатах поиска.
Короче говоря, файл robots.txt указывает поисковым роботам, что делать.
Могут ли сканеры игнорировать robots.txt?
Игнорируют ли сканеры файлы robots.txt? Да. На самом деле, многие сканеры и игнорируют его. Однако, как правило, эти сканеры не принадлежат авторитетным поисковым системам. Они исходят от спамеров, сборщиков электронной почты и других типов автоматических ботов, которые бродят по Интернету. Важно помнить об этом: 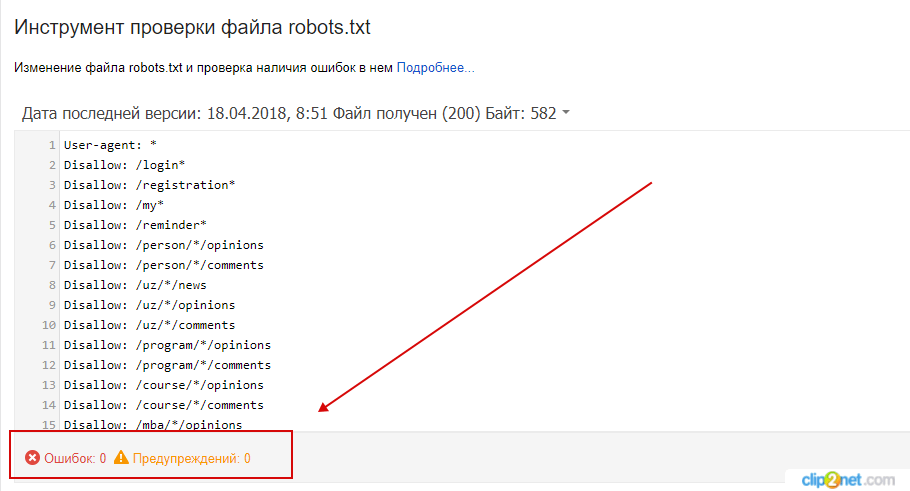 0084 . На самом деле, некоторые боты могут начать со страниц, на которые вы запретили им переходить.
0084 . На самом деле, некоторые боты могут начать со страниц, на которые вы запретили им переходить.
Однако поисковые системы будут действовать так, как указано в файле robots.txt, если он правильно отформатирован.
Как написать файл robots.txt
Стандартный файл исключения роботов состоит из нескольких частей. Я разобью их здесь по отдельности.
Декларация пользовательского агента
Прежде чем указывать боту, какие страницы ему не следует просматривать, необходимо указать, с каким ботом вы разговариваете. В большинстве случаев вы будете использовать простое объявление, означающее «все боты». Это выглядит так:
Указанный язык: разметка не существует.Генерация кода не удалась!!'
Звездочка означает «все боты». Однако вы можете указать страницы для определенных ботов. Для этого вам нужно знать имя бота, для которого вы разрабатываете рекомендации. Это может выглядеть так:
Указанный язык: разметка не существует. Генерация кода не удалась!!'
Генерация кода не удалась!!'
И так далее. Если вы обнаружите бота, который вообще не хочет сканировать ваш сайт, вы также можете указать это.
Чтобы найти имена пользовательских агентов, посетите useragentstring.com [Больше не доступно].
Запрет страниц
Это основная часть вашего файла исключения роботов. С помощью простого объявления вы говорите боту или группе ботов не сканировать определенные страницы. Синтаксис прост. Вот как вы можете запретить доступ ко всему в каталоге «admin» вашего сайта:
Указанный язык: разметка не существует.Генерация кода не удалась!!'
Эта строка не позволит ботам сканировать yoursite.com/admin, yoursite.com/admin/login, yoursite.com/admin/files/secret.html и все остальное, что попадает в каталог admin.
Чтобы запретить одну страницу, просто укажите ее в строке запрета:
Указанный язык: разметка не существует.Генерация кода не удалась!!'
Теперь страница «исключение» не будет прорисовываться, а все остальное в «общей» папке будет.
Чтобы включить несколько каталогов или страниц, просто перечислите их в следующих строках:
Указанный язык: разметка не существует.Генерация кода не удалась!!'
Эти четыре строки будут применяться к любому пользовательскому агенту, который вы указали в верхней части раздела.
Если вы хотите, чтобы боты не просматривали какие-либо страницы вашего сайта, используйте этот код:
.Указанный язык: разметка не существует.Генерация кода не удалась!!'
Установка разных стандартов для ботов
Как мы видели выше, вы можете указать определенные страницы для разных ботов. Объединив два предыдущих элемента, вот как это выглядит:
Указанный язык: разметка не существует.Генерация кода не удалась!!'
Разделы «admin» и «private» будут невидимы в Google и Bing, но Google увидит «секретный» каталог, а Bing — нет.
Вы можете указать общие правила для всех ботов с помощью пользовательского агента звездочки, а затем также дать конкретные инструкции ботам в последующих разделах.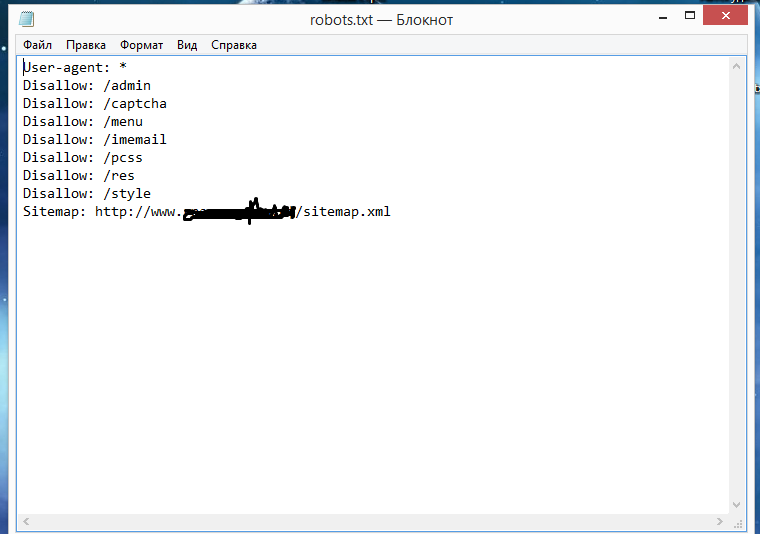
Собираем все вместе
Обладая вышеуказанными знаниями, вы можете написать полный файл robots.txt. Просто запустите свой любимый текстовый редактор (мы фанаты Sublime) и начните сообщать ботам, что они не приветствуются в определенных частях вашего сайта.
Если вы хотите увидеть пример файла robots.txt, просто перейдите на любой сайт и добавьте «/robots.txt» в конец. Вот часть файла robots.txt Giant Bicycles:
.Как видите, есть довольно много страниц, которые они не хотят показывать в поисковых системах. Они также включили несколько вещей, о которых мы еще не говорили. Давайте посмотрим, что еще вы можете сделать в своем файле исключения роботов.
Поиск вашей карты сайта
Если ваш файл robots.txt сообщает ботам, где , а не , ваша карта сайта делает обратное и помогает им найти то, что они ищут. И хотя поисковые системы, вероятно, уже знают, где находится ваша карта сайта, не помешает сообщить им об этом еще раз.
Объявление местоположения карты сайта простое:
Указанный язык: разметка не существует. Генерация кода не удалась!!'
Генерация кода не удалась!!'
Вот и все.
В нашем собственном файле robots.txt это выглядит так:
Указанный язык: разметка не существует'Генерация кода не удалась!!'
Вот и все.
Установка задержки сканирования
Директива задержки сканирования сообщает определенным поисковым системам, как часто они могут индексировать страницу на вашем сайте. Он измеряется в секундах, хотя некоторые поисковые системы интерпретируют его несколько иначе. Некоторые считают, что задержка сканирования в 5 – это указание им ждать пять секунд после каждого сканирования, чтобы начать следующее. Другие интерпретируют это как указание сканировать только одну страницу каждые пять секунд.
Почему вы говорите краулеру не ползать как можно больше? Для сохранения пропускной способности. Если ваш сервер не справляется с трафиком, вы можете установить задержку сканирования. В общем, большинству людей не нужно беспокоиться об этом. Однако крупные сайты с высокой посещаемостью могут захотеть немного поэкспериментировать.
Однако крупные сайты с высокой посещаемостью могут захотеть немного поэкспериментировать.
Вот как можно установить задержку сканирования в восемь секунд:
Указанный язык: разметка не существует.Генерация кода не удалась!!'
Вот и все. Не все поисковые системы будут подчиняться вашей директиве. Но спросить не помешает. Как и в случае с запрещенными страницами, вы можете установить разные задержки сканирования для определенных поисковых систем.
Загрузка файла robots.txt
После того, как вы настроите все инструкции в своем файле, вы можете загрузить его на свой сайт. Убедитесь, что это обычный текстовый файл с именем robots.txt. Затем загрузите его на свой сайт, чтобы его можно было найти по адресу yoursite.com/robots.txt.
Если вы используете систему управления контентом, такую как WordPress, вам, вероятно, потребуется сделать это особым образом. Поскольку в каждой системе управления контентом он разный, вам необходимо обратиться к документации по вашей системе.