Атрибут lang | htmlbook.ru
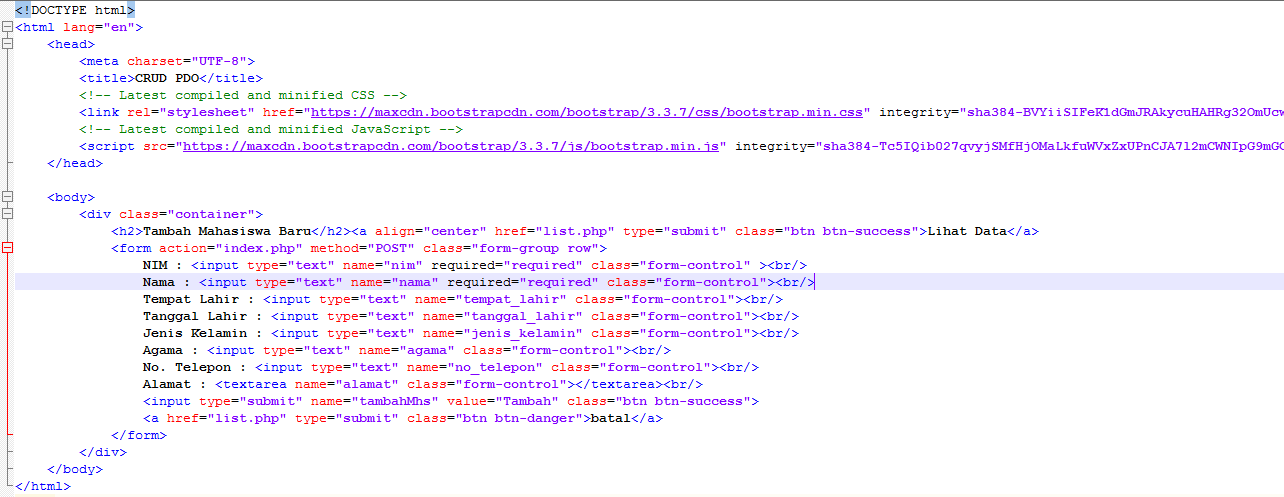
| Internet Explorer | Chrome | Opera | Safari | Firefox | Android | iOS |
| 6.0+ | 1.0+ | 3.5+ | 1.0+ | 1.0+ | 1.0+ | 1.0+ |
Описание
Текст документа может быть набран как на одном языке, так и содержать вставки на других языках, которые могут различаться по своим правилам оформления текста. Например, для русского, немецкого и английского языка характерны разные кавычки, в которые берется цитата. Чтобы указать язык, на котором написан текст внутри текущего элемента и применяется атрибут lang. Браузер использует его значение для правильного отображения некоторых символов.
Синтаксис
lang="код языка"Значения
См. коды языков
Значение по умолчанию
Нет.
Применяется к тегам
<a>, <abbr>, <acronym>, <address>, <applet>, <area>, <b>, <basefont>, <bdo><bgsound>, <big>, <blockquote>, <body>, <br>, <button>, <caption>, <center>, <cite>, <code>, <col>, <colgroup>, <dd>, <del>, <dfn>, <dir>, <div>, <dl>, <dt>, <em>, <embed>, <fieldset>, <font>, <form>, <frame>, <h2>, <h3>, <h4>, <h5>, <h5>, <h6>, <hr>, <i>, <iframe>, <img>, <input>, <ins>, <isindex>, <kbd>, <label>, <legend>, <li>, <link>, <map>, <marquee>, <menu>, <nobr>, <object>, <ol>, <option>, <p>, <plaintext>, <pre>, <q>, <s>, <samp>, <select>, <small>, <span>, <strike>, <strong>, <sub>, <sup>, <table>, <tbody>, <td>, <textarea>, <tfoot>, <th>, <thead>, <tr>, <tt>, <u>, <ul>, <var>, <wbr>, <xmp>
Пример
HTML5IECrOpSaFx
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>Атрибут lang</title> <style> p { font-size: 130%; /* Размер текста */ } q:lang(de) { quotes: "\201E" "\201C"; /* Вид кавычек для немецкого языка */ } q:lang(en) { quotes: "\201C" "\201D"; /* Вид кавычек для английского языка */ } q:lang(fr), q:lang(ru) { /* Вид кавычек для русского и французского языка */ quotes: "\00AB" "\00BB"; } </style> </head> <body> <p>Цитата на французском языке: <q lang="fr">Ce que femme veut, Dieu le veut</q>.</p> <p>Цитата на немецком: <q lang="de">Der Mensch, versuche die Gotter nicht</q>.</p> <p>Цитата на английском: <q lang="en">То be or not to be</q>.</p> </body> </html>
Результат данного примера показан на рис. 1. Для отображения типовых кавычек в примере используется стилевое свойство quotes, а само переключение языка и соответствующего вида кавычек происходит через атрибут lang, добавляемый к тегу <q>.
Рис. 1. Вид кавычек для разных языков
Коды языков | htmlbook.ru
Код языка применяется для атрибутов, задающих язык, на котором написан весь документ или отдельные его блоки. В HTML язык обычно задается через атрибут lang.
В табл. 1 приведены некоторые распространенные языки и их коды, которые используются в качестве значений.
| Язык | Код |
|---|---|
| Абхазский | ab |
| Азербайджанский | az |
| Аймарский | ay |
| Албанский | sq |
| Английский | en |
| Американский английский | en-us |
| Арабский | ar |
| Армянский | hy |
| Ассамский | as |
| Африкаанс | af |
| Башкирский | ba |
| Белорусский | be |
| Бенгальский | bn |
| Болгарский | bg |
| Бретонский | br |
| Валлийский | cy |
| Венгерский | hu |
| Вьетнамский | vi |
| Галисийский | gl |
| Голландский | nl |
| Греческий | el |
| Грузинский | ka |
| Гуарани | gn |
| Датский | da |
| Зулу | zu |
| Иврит | iw |
| Идиш | ji |
| Индонезийский | in |
| Интерлингва (искусственный язык) | ia |
| Ирландский | ga |
| Исландский | is |
| Испанский | es |
| Итальянский | it |
| Казахский | kk |
| Камбоджийский | km |
| Каталанский | ca |
| Кашмирский | ks |
| Кечуа | qu |
| Киргизский | ky |
| Китайский | zh |
| Корейский | ko |
| Корсиканский | co |
| Курдский | ku |
| Лаосский | lo |
| Латвийский, латышский | lv |
| Латынь | la |
| Литовский | lt |
| Малагасийский | mg |
| Малайский | ms |
| Мальтийский | mt |
| Маори | mi |
| Македонский | mk |
| Молдавский | mo |
| Монгольский | mn |
| Науру | na |
| Немецкий | de |
| Непальский | ne |
| Норвежский | no |
| Пенджаби | pa |
| Персидский | fa |
| Польский | pl |
| Португальский | pt |
| Пуштунский | ps |
| Ретороманский | rm |
| Румынский | ro |
| Русский | ru |
| Самоанский | sm |
| Санскрит | sa |
| Сербский | sr |
| Словацкий | sk |
| Словенский | sl |
| Сомали | so |
| Суахили | sw |
| Суданский | su |
| Тагальский | tl |
| Таджикский | tg |
| Тайский | th |
| Тамильский | ta |
| Татарский | tt |
| Тибетский | bo |
| Тонга | to |
| Турецкий | tr |
| Туркменский | tk |
| Узбекский | uz |
| Украинский | uk |
| Урду | ur |
| Фиджи | fj |
| Финский | fi |
| Французский | fr |
| Фризский | fy |
| Хауса | ha |
| Хинди | hi |
| Хорватский | hr |
| Чешский | cs |
| Шведский | sv |
| Эсперанто (искусственный язык) | eo |
| Эстонский | et |
| Яванский | jw |
| Японский | ja |
Не выкладывайте свой код напрямую в комментариях, он отображается некорректно.
lang — HTML | MDN
Глобальный атрибут lang помогает определить язык элемента: язык, на котором написаны нередактируемые элементы, или язык, на котором пользователем должны быть написаны редактируемые элементы. Атрибут содержит единственный “языковой тег” (
The source for this interactive example is stored in a GitHub repository. If you’d like to contribute to the interactive examples project, please clone https://github.com/mdn/interactive-examples and send us a pull request.
The source for this interactive example is stored in a GitHub repository. If you’d like to contribute to the interactive examples project, please clone https://github.com/mdn/interactive-examples and send us a pull request.
Если значение атрибута — пустая строка (lang=""), язык устанавливается, как неизвестный. Если тег языка недействителен согласно BCP47, он устанавливается, как недействительный.
Подробный синтаксис BCP47 достаточно подробен, чтобы отмечать специфичные языковые диалекты, но в большинстве случаев его использование намного проще.
Языковой тег состоит из языковых вложенных тегов, разделённых дефисом, где каждый вложенный тег указывает на определённое свойство языка. 3 наиболее распространённых вложенных тега:
- Языковой подтег
- Обязателен. Двух-или-трёх-символьный код, определяющий базовый язык, обычно записываемый в нижнем регистре. К примеру, код английского языка является
bdz. - Подтег скрипта
- Необязателен. Данный подтег определяет систему записи, и всегда состоящий из 4 символов с первой заглавной буквой. К примеру, французский язык Брайля — это
fr-Brai, аja-Kana— это японский язык, написанный с использованием алфавита Катакана (Katakana). Если язык написан типичным способом, например, английский с латинским алфавитом, нет необходимости использовать данный подтег.
Если язык написан типичным способом, например, английский с латинским алфавитом, нет необходимости использовать данный подтег. - Подтег региона
- Необязателен. Данный подтег определяет диалект основного языка из определённого места и состоит из двух букв в ALLCAPS, соответствующих коду страны, или трёх цифр, соответствующих региону, который не относится к стране. К примеру,
es-ES— это испанский язык, на котором разговаривают в Испании, аes-013означает испанский язык, на котором разговаривают в Центральной Америке. “Международный испанский” было бы простоes.
Подтег скрипта предшествует подтегу региона, если присутствуют оба тега — ru-Cyrl-BY — это русский язык, написанный кириллицей, на котором разговаривают в Беларуси.
Чтобы найти правильный подтег кода языка, используйте the Language Subtag Lookup.
Даже если указан атрибут lang, то он может не учитываться, поскольку атрибут xml:lang имеет приоритет над lang.
Для псевдокласса CSS :lang, два недопустимых названия языка будут разными, если их имена различны. Хотя, :lang(es) соответствует обоим lang="es-ES" и lang="es-419", но :lang(xyzzy) не соответствует lang="xyzzy-Zorp!".
HTML head lang ru en коды языка
Коды языка ISO
Атрибут HTML lang может использоваться для объявления языка веб-страницы или части веб-страницы. Это предназначено для оказания помощи поисковых систем и браузеров.
В соответствии с рекомендацией W3C необходимо объявить основной язык для каждой веб-страницы с атрибутом lang внутри тега <html>, например:
<html lang=»en»>
…
</html>
Для русского языка
<html lang=»ru»>
…
</html>
В XHTML язык объявляется внутри тега <html> следующим образом:
<html xmlns=»http://www.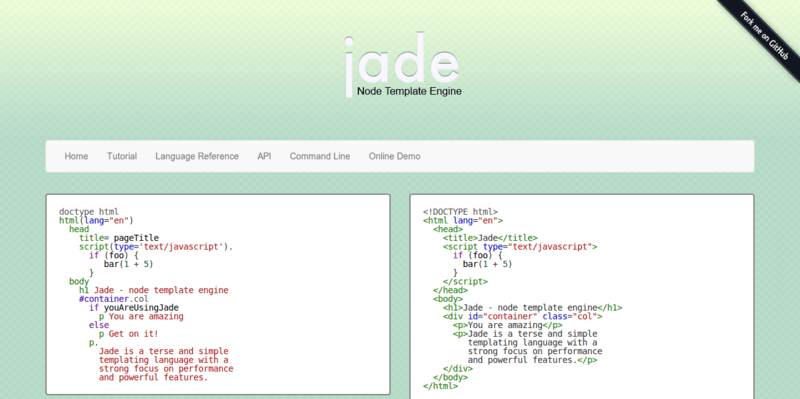 w3.org/1999/xhtml» lang=»en» xml:lang=»en»>
w3.org/1999/xhtml» lang=»en» xml:lang=»en»>
…
</html>
ISO 639-1 Коды языков
ISO 639-1 Определяет аббревиатуры для языков.
В HTML и XHTML их можно использовать в атрибутах lang и XML: lang.
Смотрите также: Следующая ссылка на коды стран.
| Язык | ISO Код |
|---|---|
| Абхазии | ab |
| Afar | aa |
| Afrikaans | af |
| Akan | ak |
| Albanian | sq |
| Amharic | am |
| Arabic | ar |
| Aragonese | an |
| Armenian | hy |
| Assamese | as |
| Avaric | av |
| Avestan | ae |
| Aymara | ay |
| Azerbaijani | az |
| Bambara | bm |
| Bashkir | ba |
| Basque | eu |
| Belarusian | be |
| Bengali (Bangla) | bn |
| Bihari | bh |
| Bislama | bi |
| Bosnian | bs |
| Breton | br |
| Bulgarian | bg |
| Burmese | my |
| Catalan | ca |
| Chamorro | ch |
| Chechen | ce |
| Chichewa, Chewa, Nyanja | ny |
| Chinese | zh |
| Chinese (Simplified) | zh-Hans |
| Chinese (Traditional) | zh-Hant |
| Chuvash | cv |
| Cornish | kw |
| Corsican | co |
| Cree | cr |
| Croatian | hr |
| Czech | cs |
| Danish | da |
| Divehi, Dhivehi, Maldivian | dv |
| Dutch | nl |
| Dzongkha | dz |
| English | en |
| Esperanto | eo |
| Estonian | et |
| Ewe | ee |
| Faroese | fo |
| Fijian | fj |
| Finnish | fi |
| French | fr |
| Fula, Fulah, Pulaar, Pular | ff |
| Galician | gl |
| Gaelic (Scottish) | gd |
| Gaelic (Manx) | gv |
| Georgian | ka |
| German | de |
| Greek | el |
| Greenlandic | kl |
| Guarani | gn |
| Gujarati | gu |
| Haitian Creole | ht |
| Hausa | ha |
| Hebrew | he |
| Herero | hz |
| Hindi | hi |
| Hiri Motu | ho |
| Hungarian | hu |
| Icelandic | is |
| Ido | io |
| Igbo | ig |
| Indonesian | id, in |
| Interlingua | ia |
| Interlingue | ie |
| Inuktitut | iu |
| Inupiak | ik |
| Irish | ga |
| Italian | it |
| Japanese | ja |
| Javanese | jv |
| Kalaallisut, Greenlandic | kl |
| Kannada | kn |
| Kanuri | kr |
| Kashmiri | ks |
| Kazakh | kk |
| Khmer | km |
| Kikuyu | ki |
| Kinyarwanda (Rwanda) | rw |
| Kirundi | rn |
| Kyrgyz | ky |
| Komi | kv |
| Kongo | kg |
| Korean | ko |
| Kurdish | ku |
| Kwanyama | kj |
| Lao | lo |
| Latin | la |
| Latvian (Lettish) | lv |
| Limburgish ( Limburger) | li |
| Lingala | ln |
| Lithuanian | lt |
| Luga-Katanga | lu |
| Luganda, Ganda | lg |
| Luxembourgish | lb |
| Manx | gv |
| Macedonian | mk |
| Malagasy | mg |
| Malay | ms |
| Malayalam | ml |
| Maltese | mt |
| Maori | mi |
| Marathi | mr |
| Marshallese | mh |
| Moldavian | mo |
| Mongolian | mn |
| Nauru | na |
| Navajo | nv |
| Ndonga | ng |
| Northern Ndebele | nd |
| Nepali | ne |
| Norwegian | no |
| Norwegian bokmål | nb |
| Norwegian nynorsk | nn |
| Nuosu | ii |
| Occitan | oc |
| Ojibwe | oj |
| Old Church Slavonic, Old Bulgarian | cu |
| Oriya | or |
| Oromo (Afaan Oromo) | om |
| Ossetian | os |
| Pāli | pi |
| Pashto, Pushto | ps |
| Persian (Farsi) | fa |
| Polish | pl |
| Portuguese | pt |
| Punjabi (Eastern) | pa |
| Quechua | qu |
| Romansh | rm |
| Romanian | ro |
| Russian | Русский | ru |
| Sami | se |
| Samoan | sm |
| Sango | sg |
| Sanskrit | sa |
| Serbian | sr |
| Serbo-Croatian | sh |
| Sesotho | st |
| Setswana | tn |
| Shona | sn |
| Sichuan Yi | ii |
| Sindhi | sd |
| Sinhalese | si |
| Siswati | ss |
| Slovak | sk |
| Slovenian | sl |
| Somali | so |
| Southern Ndebele | nr |
| Spanish | es |
| Sundanese | su |
| Swahili (Kiswahili) | sw |
| Swati | ss |
| Swedish | sv |
| Tagalog | tl |
| Tahitian | ty |
| Tajik | tg |
| Tamil | ta |
| Tatar | tt |
| Telugu | te |
| Thai | th |
| Tibetan | bo |
| Tigrinya | ti |
| Tonga | to |
| Tsonga | ts |
| Turkish | tr |
| Turkmen | tk |
| Twi | tw |
| Uyghur | ug |
| Ukrainian | uk |
| Urdu | ur |
| Uzbek | uz |
| Venda | ve |
| Vietnamese | vi |
| Volapük | vo |
| Wallon | wa |
| Welsh | cy |
| Wolof | wo |
| Western Frisian | fy |
| Xhosa | xh |
| Yiddish | yi, ji |
| Yoruba | yo |
| Zhuang, Chuang | za |
| Zulu | zu |
Атрибут lang и значение для SEO
CULTURE SPEC. CULTURE ENGLISH NAME
CULTURE ENGLISH NAME
—————————————————————
Invariant Language (Invariant Country)
af af-ZA Afrikaans
af-ZA af-ZA Afrikaans (South Africa)
ar ar-SA Arabic
ar-AE ar-AE Arabic (U.A.E.)
ar-BH ar-BH Arabic (Bahrain)
ar-DZ ar-DZ Arabic (Algeria)
ar-EG ar-EG Arabic (Egypt)
ar-IQ ar-IQ Arabic (Iraq)
ar-JO ar-JO Arabic (Jordan)
ar-KW ar-KW Arabic (Kuwait)
ar-LB ar-LB Arabic (Lebanon)
ar-LY ar-LY Arabic (Libya)
ar-MA ar-MA Arabic (Morocco)
ar-OM ar-OM Arabic (Oman)
ar-QA ar-QA Arabic (Qatar)
ar-SA ar-SA Arabic (Saudi Arabia)
ar-SY ar-SY Arabic (Syria)
ar-TN ar-TN Arabic (Tunisia)
ar-YE ar-YE Arabic (Yemen)
az az-Latn-AZ Azeri
az-Cyrl-AZ az-Cyrl-AZ Azeri (Cyrillic, Azerbaijan)
az-Latn-AZ az-Latn-AZ Azeri (Latin, Azerbaijan)
be be-BY Belarusian
be-BY be-BY Belarusian (Belarus)
bg bg-BG Bulgarian
bg-BG bg-BG Bulgarian (Bulgaria)
bs-Latn-BA bs-Latn-BA Bosnian (Bosnia and Herzegovina)
ca ca-ES Catalan
ca-ES ca-ES Catalan (Catalan)
cs cs-CZ Czech
cs-CZ cs-CZ Czech (Czech Republic)
cy-GB cy-GB Welsh (United Kingdom)
da da-DK Danish
da-DK da-DK Danish (Denmark)
de de-DE German
de-AT de-AT German (Austria)
de-DE de-DE German (Germany)
de-CH de-CH German (Switzerland)
de-LI de-LI German (Liechtenstein)
de-LU de-LU German (Luxembourg)
dv dv-MV Divehi
dv-MV dv-MV Divehi (Maldives)
el el-GR Greek
el-GR el-GR Greek (Greece)
en en-US English
en-029 en-029 English (Caribbean)
en-AU en-AU English (Australia)
en-BZ en-BZ English (Belize)
en-CA en-CA English (Canada)
en-GB en-GB English (United Kingdom)
en-IE en-IE English (Ireland)
en-JM en-JM English (Jamaica)
en-NZ en-NZ English (New Zealand)
en-PH en-PH English (Republic of the Philippines)
en-TT en-TT English (Trinidad and Tobago)
en-US en-US English (United States)
en-ZA en-ZA English (South Africa)
en-ZW en-ZW English (Zimbabwe)
es es-ES Spanish
es-AR es-AR Spanish (Argentina)
es-BO es-BO Spanish (Bolivia)
es-CL es-CL Spanish (Chile)
es-CO es-CO Spanish (Colombia)
es-CR es-CR Spanish (Costa Rica)
es-DO es-DO Spanish (Dominican Republic)
es-EC es-EC Spanish (Ecuador)
es-ES es-ES Spanish (Spain)
es-GT es-GT Spanish (Guatemala)
es-HN es-HN Spanish (Honduras)
es-MX es-MX Spanish (Mexico)
es-NI es-NI Spanish (Nicaragua)
es-PA es-PA Spanish (Panama)
es-PE es-PE Spanish (Peru)
es-PR es-PR Spanish (Puerto Rico)
es-PY es-PY Spanish (Paraguay)
es-SV es-SV Spanish (El Salvador)
es-UY es-UY Spanish (Uruguay)
es-VE es-VE Spanish (Venezuela)
et et-EE Estonian
et-EE et-EE Estonian (Estonia)
eu eu-ES Basque
eu-ES eu-ES Basque (Basque)
fa fa-IR Persian
fa-IR fa-IR Persian (Iran)
fi fi-FI Finnish
fi-FI fi-FI Finnish (Finland)
fo fo-FO Faroese
fo-FO fo-FO Faroese (Faroe Islands)
fr fr-FR French
fr-BE fr-BE French (Belgium)
fr-CA fr-CA French (Canada)
fr-FR fr-FR French (France)
fr-CH fr-CH French (Switzerland)
fr-LU fr-LU French (Luxembourg)
fr-MC fr-MC French (Principality of Monaco)
gl gl-ES Galician
gl-ES gl-ES Galician (Galician)
gu gu-IN Gujarati
gu-IN gu-IN Gujarati (India)
he he-IL Hebrew
he-IL he-IL Hebrew (Israel)
hi hi-IN Hindi
hi-IN hi-IN Hindi (India)
hr hr-HR Croatian
hr-BA hr-BA Croatian (Bosnia and Herzegovina)
hr-HR hr-HR Croatian (Croatia)
hu hu-HU Hungarian
hu-HU hu-HU Hungarian (Hungary)
hy hy-AM Armenian
hy-AM hy-AM Armenian (Armenia)
id id-ID Indonesian
id-ID id-ID Indonesian (Indonesia)
is is-IS Icelandic
is-IS is-IS Icelandic (Iceland)
it it-IT Italian
it-CH it-CH Italian (Switzerland)
it-IT it-IT Italian (Italy)
ja ja-JP Japanese
ja-JP ja-JP Japanese (Japan)
ka ka-GE Georgian
ka-GE ka-GE Georgian (Georgia)
kk kk-KZ Kazakh
kk-KZ kk-KZ Kazakh (Kazakhstan)
kn kn-IN Kannada
kn-IN kn-IN Kannada (India)
ko ko-KR Korean
kok kok-IN Konkani
kok-IN kok-IN Konkani (India)
ko-KR ko-KR Korean (Korea)
ky ky-KG Kyrgyz
ky-KG ky-KG Kyrgyz (Kyrgyzstan)
lt lt-LT Lithuanian
lt-LT lt-LT Lithuanian (Lithuania)
lv lv-LV Latvian
lv-LV lv-LV Latvian (Latvia)
mi-NZ mi-NZ Maori (New Zealand)
mk mk-MK Macedonian
mk-MK mk-MK Macedonian (Former Yugoslav Republic of Macedonia)
mn mn-MN Mongolian
mn-MN mn-MN Mongolian (Cyrillic, Mongolia)
mr mr-IN Marathi
mr-IN mr-IN Marathi (India)
ms ms-MY Malay
ms-BN ms-BN Malay (Brunei Darussalam)
ms-MY ms-MY Malay (Malaysia)
mt-MT mt-MT Maltese (Malta)
nb-NO nb-NO Norwegian, Bokmal (Norway)
nl nl-NL Dutch
nl-BE nl-BE Dutch (Belgium)
nl-NL nl-NL Dutch (Netherlands)
nn-NO nn-NO Norwegian, Nynorsk (Norway)
no nb-NO Norwegian
ns-ZA ns-ZA Northern Sotho (South Africa)
pa pa-IN Punjabi
pa-IN pa-IN Punjabi (India)
pl pl-PL Polish
pl-PL pl-PL Polish (Poland)
pt pt-BR Portuguese
pt-BR pt-BR Portuguese (Brazil)
pt-PT pt-PT Portuguese (Portugal)
quz-BO quz-BO Quechua (Bolivia)
quz-EC quz-EC Quechua (Ecuador)
quz-PE quz-PE Quechua (Peru)
ro ro-RO Romanian
ro-RO ro-RO Romanian (Romania)
ru ru-RU Russian
ru-RU ru-RU Russian (Russia)
sa sa-IN Sanskrit
sa-IN sa-IN Sanskrit (India)
se-FI se-FI Sami (Northern) (Finland)
se-NO se-NO Sami (Northern) (Norway)
se-SE se-SE Sami (Northern) (Sweden)
sk sk-SK Slovak
sk-SK sk-SK Slovak (Slovakia)
sl sl-SI Slovenian
sl-SI sl-SI Slovenian (Slovenia)
sma-NO sma-NO Sami (Southern) (Norway)
sma-SE sma-SE Sami (Southern) (Sweden)
smj-NO smj-NO Sami (Lule) (Norway)
smj-SE smj-SE Sami (Lule) (Sweden)
smn-FI smn-FI Sami (Inari) (Finland)
sms-FI sms-FI Sami (Skolt) (Finland)
sq sq-AL Albanian
sq-AL sq-AL Albanian (Albania)
sr sr-Latn-CS Serbian
sr-Cyrl-BA sr-Cyrl-BA Serbian (Cyrillic) (Bosnia and Herzegovina)
sr-Cyrl-CS sr-Cyrl-CS Serbian (Cyrillic, Serbia)
sr-Latn-BA sr-Latn-BA Serbian (Latin) (Bosnia and Herzegovina)
sr-Latn-CS sr-Latn-CS Serbian (Latin, Serbia)
sv sv-SE Swedish
sv-FI sv-FI Swedish (Finland)
sv-SE sv-SE Swedish (Sweden)
sw sw-KE Kiswahili
sw-KE sw-KE Kiswahili (Kenya)
syr syr-SY Syriac
syr-SY syr-SY Syriac (Syria)
ta ta-IN Tamil
ta-IN ta-IN Tamil (India)
te te-IN Telugu
te-IN te-IN Telugu (India)
th th-TH Thai
th-TH th-TH Thai (Thailand)
tn-ZA tn-ZA Tswana (South Africa)
tr tr-TR Turkish
tr-TR tr-TR Turkish (Turkey)
tt tt-RU Tatar
tt-RU tt-RU Tatar (Russia)
uk uk-UA Ukrainian
uk-UA uk-UA Ukrainian (Ukraine)
ur ur-PK Urdu
ur-PK ur-PK Urdu (Islamic Republic of Pakistan)
uz uz-Latn-UZ Uzbek
uz-Cyrl-UZ uz-Cyrl-UZ Uzbek (Cyrillic, Uzbekistan)
uz-Latn-UZ uz-Latn-UZ Uzbek (Latin, Uzbekistan)
vi vi-VN Vietnamese
vi-VN vi-VN Vietnamese (Vietnam)
xh-ZA xh-ZA Xhosa (South Africa)
zh-CN zh-CN Chinese (People’s Republic of China)
zh-HK zh-HK Chinese (Hong Kong S. A.R.)
A.R.)
zh-CHS (none) Chinese (Simplified)
zh-CHT (none) Chinese (Traditional)
zh-MO zh-MO Chinese (Macao S.A.R.)
zh-SG zh-SG Chinese (Singapore)
zh-TW zh-TW Chinese (Taiwan)
zu-ZA zu-ZA Zulu (South Africa)
Информация о языке и направлении текста
Информация о языке и направлении текстаВ этом разделе обсуждаются два важных вопроса, которые влияют на интернационализацию HTML: спецификация языка (атрибут lang) и направление (атрибут dir) текста в документе.
Определение атрибута- lang = language-code [CI]
- Этот атрибут определяет базовый язык значений атрибутов элементов и содержимого текста. По умолчанию значение этого атрибута неизвестно.
Информация о языке, определённая атрибутом lang, может быть использована Пользовательским Агентом (ПА) для управления представлением различными
путями.
Вот некоторые ситуации, где предоставленная автором информация о языке может быть полезной:
- содействие поисковым машинам;
- содействие речевым синтезаторам;
- помощь ПА в выборе вариантов глифов для высококачественной печати;
- помощь ПА в выборе вариантов кавычек;
- помощь ПА в принятии решений о дефисах, лигатурах и пробелах;
- помощь программам проверки правописания.
Атрибут lang определяет язык содержимого элемента и значений атрибутов. Относится ли это к соответствующему атрибуту, зависит от синтаксиса и семантики атрибута и выполняемой операции.
Цель атрибута lang — создать ПА условия для более понятного представления содержимого на базе принятой для данного языка культурной практики. Это не означает, что ПА должны отображать нетипичные для конкретного языка символы менее осмысленным способом. ПА обязаны действовать наилучшим образом
для отображения всех символов независимо от значений атрибута lang.
Например, если символы греческого алфавита появляются в окружении английского текста:
<P><Q lang="en">Her super-powers were the result of γ-radiation,</Q> he explained.</P>
ПА должен
(1) попытаться представить английское содержимое соответствующим образом (например, при обработке знаков кавычек) и
(2) обязан попытаться представить символ γ наилучшим образом, несмотря на то, что этот символ не является английской буквой.
См. дополнительную информацию в разделе неотображаемые символы.
8.1.1 Коды языка
Значением атрибута lang является код языка, идентифицирующий язык, используемый людьми для разговора, письма и других видов общения. Компьютерные языки исключены из кодов языка.
[RFC1766] определяет и разъясняет коды языка, которые должны использоваться в документах HTML.
Если говорить кратко, коды языка состоят из первичного кода и, возможно пустых, серий субкодов:
language-code = primary-code ( "-" subcode )*
Вот примеры кодов некоторых языков:
- «en»: английский,
- «en-US»: американский английский,
- «en-cockney»: Cockney-версия английского,
- «i-navajo»: навахо,
- «x-klingon»: тег «x» обозначает экспериментальный тег языка.
Двухсимвольные первичные коды зарезервированы для аббревиатур [ISO639].
Двухсимвольные коды включают fr (французский), de (немецкий), it (итальянский), nl (фламандский), el (греческий), es (испанский), pt (португальский),
ar (арабский), he (еврейский), ru (русский), zh (китайский), ja (японский), hi (хинди), ur (урду) и sa (санскрит).
Любые двухбуквенный субкод понимается как код страны в [ISO3166].
8.1.2 Наследование кодов языка
Элемент наследует информацию кода языка в следующем порядке (приоритет от высшего к низшему):
В этом примере основной язык документа — французский («fr»). Один параграф объявлен как испанский («es»), после которого возвращается основной язык (французский). Следующий параграф содержит фразу на внедрённом японском («ja»), после чего возвращается основной язык (французский).
Следующий параграф содержит фразу на внедрённом японском («ja»), после чего возвращается основной язык (французский).
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> <HTML lang="fr"> <HEAD> <TITLE>Un document multilingue</TITLE> </HEAD> <BODY> ...интерпретируется как французский... <P lang="es">...интерпретируется как испанский... <P>...снова интерпретируется как французский... <P>...французский текст прерывается японским... <EM lang="ja">что-нибудь на японском</EM>здесь снова продолжается французский... </BODY> </HTML>Примечание. Если ячейка занимает область из нескольких ячеек (span), то она может наследовать значение lang не из своего предка, а из первой ячейки в span . См. детали в разделе наследование выравнивания.
8.1.3 Интерпретация кодов языка
В контексте HTML код языка должен интерпретироваться ПА как иерархия понятий, а не отдельное понятие. Когда ПА уточняет отображение, используя информацию о языке (путём сравнения кодов языка таблиц стилей и значений атрибута lang), он всегда должен находить точное совпадение, но должен также учитывать совпадение основных кодов. Таким образом, если значение атрибута lang «en-US» установлено для элемента HTML, ПА должен сначала отдать предпочтение информации, совпадающей с «en-US», а уже затем — с более общим значением «en».
Примечание. Иерархии кодов языка не гарантируют, что все языки с обычным префиксом будут свободно пониматься, но они (иерархии) позволяют пользователю запрашивать эту сообщность, если для пользователя это является верным.
Определение атрибута
- dir = LTR | RTL [CI]
- Определяет направление движения изначально нейтрального текста (т.
 е. текста, который не имеет унаследованного направления, как определено в [UNICODE]), из содержимого элемента и значений атрибута. Устанавливает также направление
в таблицах.
е. текста, который не имеет унаследованного направления, как определено в [UNICODE]), из содержимого элемента и значений атрибута. Устанавливает также направление
в таблицах.
Возможные значения:- LTR: слева-направо, текст или таблица;
- RTL: справа-налево: текст или таблица.
В дополнение к спецификации языка документа с помощью атрибута lang, авторам может понадобиться определить базовое направление (слева-направо или справа-налево) части текста документа, структуры таблицы и т.д. Это устанавливается в атрибуте dir.
Спецификация [UNICODE] назначает направление символам и определяет (сложный) алгоритм для определения соответствующего направления текста. Если документ не содержит отображаемых справа-налево символов, то от соответствующего ПА не требуется применять двунаправленный алгоритм [UNICODE]. Если документ содержит отображаемые справа-налево символы и если ПА отображает эти символы, ПА обязан использовать двунаправленный алгоритм.
Хотя Unicode специфицирует символы с направлением текста, HTML предлагает высокоуровневые конструкции разметки, которые делают то же самое: атрибут dir (не путайте с элементом DIR) и элемент BDO. Таким образом, для отображения еврейских кавычек более интуитивно понятно будет записать:
<Q lang="he" dir="rtl">...еврейские кавычки...</Q>
чем то же самое в мнемониках Unicode:
‫״...еврейские кавычки...״‬
ПА не должны использовать атрибут lang для определения направления текста.
Атрибут dir наследуется и может быть переопределён. См. детали в разделе информация о наследовании направления текста.
8.2.1 Двунаправленный алгоритм. Введение.
Следующий пример иллюстрирует ожидаемое поведение двунаправленного алгоритма. Он включает английский, скрипт слева-направо, и еврейский языки, скрипт справа-налево:
english2 HEBREW2 english4 HEBREW4 english5 HEBREW6
Символы в этом примере (и во всех подобных) хранятся на компьютере таким образом: первый символ в файле — «e», второй — «n» и последний — «6».
Предположим, преобладающий язык документа, содержащего этот параграф, английский. Это означает, что базовое направление — слева-направо. Корректное представление этого:
english2 2WERBEH english4 4WERBEH english5 6WERBEH
<------ <------ <------
H H H
------------------------------------------------->
EЛинии обозначают структуру предложения: английский — основной, а еврейский — внедрён. Достичь корректного представления можно без дополнительной разметки, поскольку еврейские фрагменты корректно повёрнуты ПА с применением двунаправленного алгоритма.
Если наоборот, преобладающий язык документа — еврейский, то базовое направление — справа-налево. Тогда корректное представление:
6WERBEH english5 4WERBEH english4 2WERBEH english2
-------> -------> ------->
E E E
<-------------------------------------------------
HВ этом случае, всё предложение представлено как текст справа-налево, и внедрённая последовательность символов на английском соответствующим образом повёрнута с помощью двунаправленного алгоритма.
8.2.2 Наследование информации о направлении текста
Двунаправленный алгоритм Unicode требует наличия базового направления для текстовых блоков. Чтобы определить базовое направление элементов на уровне блока, установите атрибут dir в элементе. Значение атрибута dir по умолчанию — «ltr» (left-to-right/слева-направо).
Если атрибут dir установлен для элементов уровня блока, он действует на период существования самого элемента и всех вложенных элементов уровня блока. Установка атрибута dir во вложенном элементе переопределяет наследованное значение.
Чтобы установить базовое направление текста для всего документа, установите атрибут dir элемента HTML.
Например:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> <HTML dir="RTL"> <HEAD> <TITLE>...заглавие справа-налево...</TITLE> </HEAD> ...текст справа-налево... <P dir="ltr">...текст слева-направо...</P> <P>...снова текст справа-налево...</P> </HTML>
В то же время, инлайн-элементы не наследуют атрибут dir. Это значит, что инлайн-элемент без атрибута dir не открывает дополнительный уровень в установке двунаправленного алгоритма. (Элемент рассматривается здесь как уровня инлайн или блока на основе его представления по умолчанию. Обратите внимание, что элементы INS и DEL могут быть уровня блока или инлайн в зависимости от контекста.)
8.2.3 Установка направления внедрённого текста
Двунаправленный алгоритм [UNICODE] автоматически поворачивает внедрённые последовательности символов в соответствии с их унаследованным направлением (как показано в предыдущих примерах). Однако в целом только один уровень внедрения может быть просчитан. Чтобы установить дополнительные уровни внедрённых изменений направления, придётся использовать атрибут dir в инлайн-элементах.
Рассмотрим тот же текст, что и ранее:
english2 HEBREW2 english4 HEBREW4 english5 HEBREW6
Предположим, преобладающим языком документа, содержащего этот параграф, является английский. С другой стороны, это предложение на английском содержит раздел на еврейском от HEBREW2 до HEBREW4, и раздел на еврейском содержит в себе английский (english4). Нужное представление предложения таково:
english2 4WERBEH english4 2WERBEH english5 6WERBEH
------->
E
<-----------------------
H
------------------------------------------------->
EЧтобы выполнить два изменения направления, мы должны предоставить дополнительную информацию путём явного разграничения. В этом примере мы используем элемент SPAN и атрибут dir для
разметки текста:
В этом примере мы используем элемент SPAN и атрибут dir для
разметки текста:
english2 <SPAN dir="RTL">HEBREW2 english4 HEBREW4</SPAN> english5 HEBREW6
Авторы могут также использовать специальные символы Unicode для выполнения множественных внедрённых изменений направления текста. Для получения внедрения «слева-направо», окружите внедряемый текст символами LEFT-TO-RIGHT EMBEDDING («LRE», 16-ричная 202A) и POP DIRECTIONAL FORMATTING («PDF», 16-ричная 202C). Для получения внедрения «справа-налево», окружите внедряемый текст символами RIGHT-TO-LEFT EMBEDDING («RTE», 16-ричная l 202B) и PDF.
Использование разметки направления HTML с символами Unicode. Авторы и разработчики авторских программных продуктов должны знать, что конфликты могут увеличиться, если атрибут dir в инлайн-элементах (включая BDO) соседствует с символами форматирования [UNICODE]. Лучше использовать то или другое. Метод разметки даёт больше гарантии структурной целостности документа и облегчает решение некоторых проблем при редактировании двунаправленного текста HTML в простом текстовом редакторе, но некоторые программы могут быть более адаптированы к использованию символов [UNICODE]. Если используются оба метода, нужно быть очень внимательным, устанавливая вложенную разметку и внедрённые изменения направления, иначе результаты отображения могут быть непредсказуемыми.
8.2.4 Переопределение двунаправленного алгоритма: элемент
BDOНачальный тег: необходим, Конечный тег: необходим
Определение атрибута
- dir = LTR | RTL [CI]
- Этот обязательный атрибут определяет базовое направление текста в содержимом элемента. Это направление переопределяет унаследованное направление символов, как указано в [UNICODE]. Возможные значения:
- LTR: Left-to-right/слева-направо;
- RTL: Right-to-left/справа-налево.
Атрибут, определённый в другом месте
Двунаправленного алгоритма и атрибута dir обычно достаточно для обслуживания внедрённых изменений направления. Однако, в некоторых ситуациях двунаправленный алгоритм может быть причиной некорректного представления. Элемент BDO позволяет авторам отключить двунаправленный алгоритм в определённом фрагменте текста.
Рассмотрим документ, содержащий текст:
english2 HEBREW2 english4 HEBREW4 english5 HEBREW6
и представим, что этот текст уже выведен в таком визуальном порядке. Причиной этого может быть то, что стандарт MIME ([RFC2045], [RFC1556]) отдаёт
преимущество визуальному расположению, т.e. что последовательности текста «справа-налево» вставляются справа-налево в потоке байтов.
В email этот пример может быть сформатирован с включением символов новой строки:
english2 2WERBEH english4 4WERBEH english5 6WERBEH
Это конфликтует с двунаправленным алгоритмом [UNICODE], поскольку этот алгоритм повернёт 2WERBEH, 4WERBEH и 6WERBEH вторично, отображая еврейские слова слева-направо вместо справа-налево.
Решением в данном случае будет переопределение двунаправленного алгоритма помещением отрывка Email в элемент PRE (для сохранения символов новой строки) и каждой строки в элемент BDO, атрибут dir которого установлен в LTR:
<PRE> <BDO dir="LTR">english2 2WERBEH english4</BDO> <BDO dir="LTR">4WERBEH english5 6WERBEH</BDO> </PRE>
Это говорит двунаправленному алгоритму «Оставь меня слева-направо!» и должно создать желаемое представление:
english2 2WERBEH english4 4WERBEH english5 6WERBEH
Элемент BDO должен использоваться в конструкциях, где нужен полный контроль за порядком расположения (напр., несколько многоязычных частей). Наличие атрибута dir для
этого элемента обязательно.
Авторы могут также использовать специальные символы Unicode для переопределения двунаправленного алгоритма. — LEFT-TO-RIGHT OVERRIDE (202D) или RIGHT-TO-LEFT OVERRIDE (202E). Символ POP DIRECTIONAL FORMATTING (202C) заключает любое переопределение двунаправленного алгоритма.
Примечание. Напоминаем, что может увеличиться количество конфликтов, если атрибут dir в инлайн-элементах (включая BDO) соседствует с символами форматирования [UNICODE].
Двунаправленность и кодировка символов. В соответствии с [RFC1555] и [RFC1556], существуют несколько специальных соглашений об использовании значений параметра «charset» для обозначения двунаправленного представления в MIME mail, в особенности для различения визуального, подразумеваемого, и явного указания направления. Значение параметра «ISO-8859-8» (для еврейского языка) обозначает визуальное кодирование, «ISO-8859-8-i» обозначает подразумеваемую двунаправленность и «ISO-8859-8-e» обозначает явную двунаправленность.
Поскольку HTML использует двунаправленный алгоритм Unicode, соответствующие документы, кодированные с использованием ISO 8859-8, должны быть помечены как «ISO-8859-8-i». Явный контроль направления также возможен в HTML, но он не может быть выражен в ISO 8859-8, так что «ISO-8859-8-e» не должен использоваться.
Значение «ISO-8859-8» подразумевает, что документ сформатирован визуально, с потерей некоторой разметки (такой как TABLE с правым выравниванием и запретом переноса слов), чтобы обеспечить верное отображение в
более старых ПА, не обрабатывающих двунаправленность. Такие документы не соответствуют настоящей спецификации. При необходимости они могут быть оформлены в соответствии с настоящей спецификацией (и одновременно будут корректно отображаться в более старых ПА) путём добавления разметки BDO там, где это необходимо. В противоположность уже сказанному в [RFC1555] и [RFC1556],
ISO-8859-6 (арабский язык) визуально не упорядочивается.
8.2.5 Символьные мнемоники для указания направления и управление сращиванием
Поскольку иногда возникают двусмысленные ситуации при установке направления определённых символов (напр., знаки препинания), спецификация [UNICODE] содержит символы для соответствующего разрешения таких ситуаций. Также Unicode включает некоторые символы управления поведением сращивания там, где это необходимо (напр., некоторые ситуации с арабскими буквами). HTML 4 включает символьные ссылки-мнемоники для таких символов.
Следующий отрывок ОТД представляет некоторые мнемоники направления:
<!ENTITY zwnj CDATA "‌"--=zero width non-joiner--> <!ENTITY zwj CDATA "‍"--=zero width joiner--> <!ENTITY lrm CDATA "‎"--=left-to-right mark--> <!ENTITY rlm CDATA "‏"--=right-to-left mark-->
Мнемоника zwnj используется для блокировки сращивания в контексте, когда сращивание есть, но нежелательно.
Мнемоника zwj действует наоборот: она форсирует сращивание, когда его не должно быть, но оно необходимо. Например, арабская буква «HEH» используется как сокращение
от «Hijri», названия исламской календарной системы. Поскольку изолированно форма «HEH» похожа на цифру пять, как принято в арабском письме (на базе индийской нумерации), для предотвращения конфликтов «HEH» с конечной цифрой пять в обозначении года используется начальная форма «HEH». В то же время, отсутствует
контекст (т.е. сращивание букв), к которому «HEH» можно присоединить. Символ zwj обеспечивает такой контекст.
Также в персидских текстах встречаются случаи, когда буквы, которые обычно могут сращиваться с последующими, в курсивном соединении не делают этого. Символ zwnj используется для блокировки сращивания в таких случаях.
Другие символы, lrm и rlm, используются для форсирования направленных или нейтрально направленных символов. Например, если знак двойной кавычки вставляется между арабскими (справа-налево) и латинскими (слева-направо) буквами, направление знака кавычки на определено (закавычивает
ли она арабский или латинский текст?). Символы lrm и rlm имеют свойство направления, но не имеют свойств ширины и разрыва слов/строки. См. детали в [UNICODE].
Например, если знак двойной кавычки вставляется между арабскими (справа-налево) и латинскими (слева-направо) буквами, направление знака кавычки на определено (закавычивает
ли она арабский или латинский текст?). Символы lrm и rlm имеют свойство направления, но не имеют свойств ширины и разрыва слов/строки. См. детали в [UNICODE].
«Зеркальные» глифы символов. Вообще двунаправленный алгоритм не отражает «зеркально» глифы символов, а оставляет их без воздействия. исключение составляют символы, такие как скобки (см. [UNICODE], таблица 4-7). В тех случаях, когда зеркальное отражение необходимо, например, для египетских иероглифов или греческих Bustrophedon, или для достижения специальных дизайнерских эффектов, этим можно управлять с помощью стилей.
8.2.6 Действие таблиц стилей на двунаправленность
В целом, использование таблиц стилей для изменения визуального представления элементов с уровня блока на инлайн и наоборот является более прямым путём. Однако, поскольку двунаправленный алгоритм основывается на различении уровней блок/инлайн, необходимо особое внимание при обеспечении трансформации.
Если инлайн-элемент, не имеющий атрибута dir, трансформируется в элемент уровня блока с помощью таблицы стилей, он наследует атрибут dir от ближайшего родительского блок-элемента для определения базового направления блока.
Если блок-элемент, не имеющий атрибута dir, трансформируется в стиль инлайн-элемента с помощью таблицы стилей, результат представления должен быть эквивалентным, в плане двунаправленного форматирования, форматированию, получаемому путём явного добавления атрибута dir (с установкой наследуемого значения) к трансформируемому элементу.
Код языка HTML — Веб учебники
Обновляется!!! Справочник JavaScript
Коды языка ISO
Атрибут lang может использоваться для объявления языка веб страницы или части веб страницы. Предназначено для оказания помощи поисковых систем и браузеров.
Предназначено для оказания помощи поисковых систем и браузеров.
Согласно рекомендации W3C, вы должны объявить основной язык для каждой веб страницы с атрибутом lang внутри тега <html>, как это:
<html lang=»en»>
…
</html>
В XHTML язык объявляется внутри тега <html> следующим образом:
<html xmlns=»http://www.w3.org/1999/xhtml» lang=»en» xml:lang=»en»>
…
</html>
Коды языков ISO 639-1
ISO 639-1 определяет сокращения для языков.
В HTML и XHTML их можно использовать в атрибутах lang и xml:lang.
См. также коды: следующий справочник для стран.
| Язык | Код ISO |
|---|---|
| Абхазский | ab |
| Афарский | aa |
| Африкаанс | af |
| Акан | ak |
| Албанский | sq |
| Амхарский | am |
| Арабский | ar |
| Арагонский | an |
| Армянский | hy |
| Ассамский | as |
| Avaric | av |
| Авестийский | ae |
| Аймара | ay |
| Азербайджанский | az |
| Бамбара | bm |
| Башкирский | ba |
| Баскский | eu |
| Белорусский | be |
| Бенгальский (Bangla) | bn |
| Бихарийский | bh |
| Бисламанский | bi |
| Боснийский | bs |
| Бретонский | br |
| Болгарский | bg |
| Бирманский | my |
| Каталонский | ca |
| Chamorro | ch |
| Чеченский | ce |
| Чичев, Чева, Ньянджа | ny |
| Китайский | zh |
| Китайский (Упрощенный) | zh-Hans |
| Китайский (Традиционный) | zh-Hant |
| Чувашский | cv |
| Корнуоллский | kw |
| Корсиканский | co |
| Кри | cr |
| Хорватский | hr |
| Чешский | cs |
| Датский | da |
| Мальдивский, Дивехи, Дхивехи | dv |
| Голландский | nl |
| Дзонг-КЭ | dz |
| Английский | en |
| эсперантский | eo |
| Эстонский | et |
| Ewe | ee |
| Фарерский | fo |
| Фиджийский | fj |
| Финский | fi |
| Французский | fr |
| Fula, Fulah, Pulaar, Pular | ff |
| Галицийский | gl |
| Гэльский (Шотландский) | gd |
| Гэльский (Мэнский) | gv |
| Грузинский | ka |
| Немецкий | de |
| Греческий | el |
| Гренландский | kl |
| Гуарани | gn |
| Гуджара́тский | gu |
| Гаитянский Креольский | ht |
| Хауса | ha |
| Еврейский | he |
| Гереро | hz |
| Индийский | hi |
| Хиримоту | ho |
| Венгерский | hu |
| Исландский | is |
| Ибо | io |
| Игбо | ig |
| Индонезийский | id, in |
| Интерлингва | ia |
| Interlingue | ie |
| Инуктитут | iu |
| Inupiak | ik |
| Ирландский | ga |
| Итальянский | it |
| Японский | ja |
| Яванский | jv |
| Калааллисут, Ггренландский | kl |
| Каннада | kn |
| Канури | kr |
| Кашмирский | ks |
| Казахский | kk |
| Кхмерский | km |
| Кикуйю | ki |
| Киньяруанда (Руанда) | rw |
| Кирунди | rn |
| Киргизский | ky |
| Коми | kv |
| Kongo | kg |
| Корейский | ko |
| Курдский | ku |
| Kwanyama | kj |
| Лаоский | lo |
| Латинский | la |
| Латвийский (Латышский) | lv |
| Лимбургский (Лимбургер) | li |
| Английский | ln |
| Литовский | lt |
| Луга-Катанга | lu |
| Luganda, Ganda | lg |
| Люксембургский | lb |
| Мэнский | gv |
| Македонский | mk |
| Малагасийский | mg |
| Малайский | ms |
| Малайялама | ml |
| Мальтийский | mt |
| Маорийский | mi |
| Маратхи | mr |
| Маршалльский | mh |
| Молдаванский | mo |
| Монгольский | mn |
| Науру | na |
| Навахо | nv |
| Ndonga | ng |
| Северная Ндебеле | nd |
| Непальский | ne |
| Norwegian | no |
| Norwegian bokmål | nb |
| Norwegian nynorsk | nn |
| Nuosu | ii |
| Occitan | oc |
| Ojibwe | oj |
| Old Church Slavonic, Old Bulgarian | cu |
| Oriya | or |
| Oromo (Afaan Oromo) | om |
| Ossetian | os |
| Pāli | pi |
| Pashto, Pushto | ps |
| Persian (Farsi) | fa |
| Polish | pl |
| Portuguese | pt |
| Punjabi (Eastern) | pa |
| Quechua | qu |
| Romansh | rm |
| Romanian | ro |
| Русский | ru |
| Sami | se |
| Samoan | sm |
| Sango | sg |
| Sanskrit | sa |
| Serbian | sr |
| Serbo-Croatian | sh |
| Sesotho | st |
| Setswana | tn |
| Shona | sn |
| Sichuan Yi | ii |
| Sindhi | sd |
| Sinhalese | si |
| Siswati | ss |
| Slovak | sk |
| Slovenian | sl |
| Somali | so |
| Southern Ndebele | nr |
| Spanish | es |
| Sundanese | su |
| Swahili (Kiswahili) | sw |
| Swati | ss |
| Swedish | sv |
| Tagalog | tl |
| Tahitian | ty |
| Tajik | tg |
| Tamil | ta |
| Tatar | tt |
| Telugu | te |
| Thai | th |
| Tibetan | bo |
| Tigrinya | ti |
| Tonga | to |
| Tsonga | ts |
| Turkish | tr |
| Turkmen | tk |
| Twi | tw |
| Uyghur | ug |
| Ukrainian | uk |
| Urdu | ur |
| Uzbek | uz |
| Venda | ve |
| Vietnamese | vi |
| Volapük | vo |
| Wallon | wa |
| Welsh | cy |
| Wolof | wo |
| Western Frisian | fy |
| Xhosa | xh |
| Yiddish | yi, ji |
| Yoruba | yo |
| Zhuang, Chuang | za |
| Zulu | zu |
HTML Код языка ISO Ссылка
Коды языков ISO
Вы всегда должны включать атрибут lang внутри тег, чтобы объявить язык
Страница в Интернете. Это предназначено для помощи поисковым системам и браузерам:
Это предназначено для помощи поисковым системам и браузерам:
…
В XHTML язык объявляется внутри тега следующим образом:
…
Коды языков ISO 639-1
ISO 639-1 определяет сокращения для языков:
См. Также: Справочник кодов стран.
| Язык | Код ISO |
|---|---|
| Абхазский | ab |
| Афар | а.о. |
| Африкаанс | af |
| Акан | ак |
| албанский | кв. |
| Амхарский | утра |
| Арабский | ar |
| Арагонский | и |
| Армянский | hy |
| Ассамский | как |
| Avaric | в среднем |
| авестийский | ae |
| Аймара | ай |
| Азербайджанский | az |
| Бамбара | bm |
| Башкирский | ba |
| Баск | eu |
| Белорусский | быть |
| бенгальский (бангла) | млрд |
| Бихари | bh |
| Бислама | bi |
| Боснийский | BS |
| Бретонский | br |
| Болгарский | bg |
| бирманский | мой |
| Каталонский | ок. |
| Чаморро | шасси |
| чеченский | CE |
| Chichewa, Chewa, Nyanja | ny |
| китайский | ж |
| Китайский (упрощенный) | Ж-Ханс |
| Китайский (традиционный) | ж-Хант |
| Чувашский | cv |
| Корнуолл | кВт |
| Корсиканский | co |
| Кри | кр |
| Хорватский | часов |
| Чешский | cs |
| датский | da |
| Дивехи, Дивехи, Мальдивские острова | дв |
| Голландский | нл |
| Дзонгка | dz |
| Английский | и |
| эсперанто | eo |
| Эстонский | и |
| Эве | ee |
| Фарерские острова | fo |
| Фиджийцы | fj |
| финский | fi |
| Французский | пт |
| Fula, Fulah, Pulaar, Pular | ff |
| Галицкий | gl |
| гэльский (шотландский) | gd |
| гэльский (мэнский) | gv |
| Грузинская | ка |
| Немецкий | de |
| Греческий | el |
| Гренландский | кл |
| гуарани | gn |
| Гуджарати | гу |
| Гаитянский креольский | ht |
| Хауса | га |
| Еврейский | он |
| Гереро | Гц |
| Хинди | привет |
| Хири Моту | хо |
| Венгерский | hu |
| Исландский | это |
| Идо | io |
| Игбо | иг |
| Индонезийский | id, в |
| Интерлингва | ia |
| Интерлингв | т. е. е. |
| Инуктитут | ме |
| Инупяк | ik |
| Ирландский | га |
| Итальянский | это |
| Японский | и |
| яванский | СП |
| Калааллисут, Гренландия | кл |
| каннада | кун |
| Канури | крон |
| Кашмири | кс |
| казахский | кк |
| кхмерский | км |
| Кикую | ки |
| Киньяруанда (Руанда) | рв |
| Кирунди | рн |
| Кыргызская | лет назад |
| Коми | кв |
| Конго | кг |
| Корейский | ko |
| курдский | ку |
| Кваньяма | кДж |
| Лаос | lo |
| Латиница | la |
| латышский (латышский) | лев |
| лимбургский (лимбургский) | ли |
| Лингала | пер. |
| Литовский | л. |
| Луга-Катанга | lu |
| Луганда, Ганда | LG |
| люксембургский | фунтов |
| Мэн | gv |
| Македонский | мк |
| малагасийский | мг |
| Малайский | мс |
| Малаялам | мл |
| Мальтийский | тонн |
| маори | миль |
| маратхи | г-н |
| Маршалловы острова | мч |
| Молдавский | мес.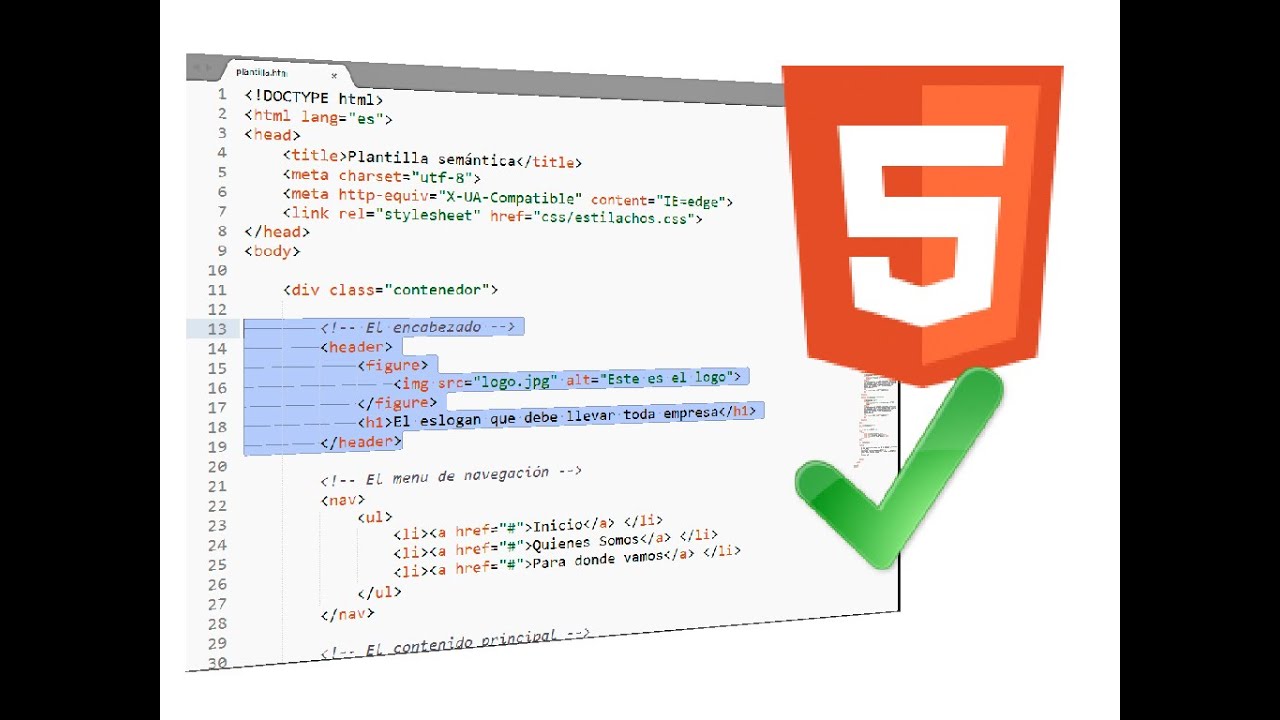 |
| Монгольский | мин |
| Науру | на |
| Навахо | nv |
| Ндонга | нг |
| Северный Ндебеле | nd |
| Непальский | ne |
| Норвежский | нет |
| Норвежский бокмол | nb |
| норвежский нюнорск | нн |
| Nuosu | II |
| Окситанский | oc |
| Оджибве | oj |
| Старославянский, Староболгарский | у.е. |
| Ория | или |
| Оромо (Афаан Оромо) | ом |
| Осетинский | os |
| Пали | пи |
| пушту, пушту | пс |
| Персидский (фарси) | fa |
| Польский | пл |
| Португальский | пт |
| пенджаби (восточный) | па |
| Quechua | qu |
| Романский | п.м. |
| Румынский | ro |
| Русский | ru |
| саами | se |
| Самоа | см |
| Санго | SG |
| санскрит | sa |
| сербский | sr |
| сербохорватский | ш |
| Сесото | ул |
| Сетсвана | тн |
| Шона | sn |
| Сычуань Йи | II |
| Синдхи | SD |
| Сингальский | si |
| Сисвати | сс |
| Словацкий | sk |
| словенский | sl |
| Сомали | так |
| Южный Ндебеле | № |
| Испанский | es |
| Суданский | su |
| Суахили (кисуахили) | sw |
| Свати | сс |
| Шведский | sv |
| Тагальский | TL |
| Таитянский | ty |
| Таджикский | тг |
| тамильский | ta |
| Татарский | тт |
| телугу | te |
| Тайский | чт |
| Тибетский | bo |
| Тигриня | ti |
| Тонга | Спо |
| Цонга | ts |
| Турецкий | тр |
| туркменский | тк |
| Twi | tw |
| Уйгурский | мкг |
| Украинский | uk |
| Урду | ур |
| Узбекский | uz |
| Венда | ве |
| Вьетнамский | vi |
| Volapük | во |
| Валлон | wa |
| Валлийский | cy |
| Волоф | wo |
| Западно-Фризская | fy |
| Xhosa | xh |
| Идиш | йи, дзи |
| Йоруба | года |
| Чжуан, Чжуан | за |
| Зулус | zu |
Объявление языка в HTML
Указание метаданных о языке аудитории
Если вы хотите создать метаданные, описывающие язык целевой аудитории страницы, а не язык определенного диапазона текста, сделайте это, заставив сервер отправить
информация в заголовке HTTP Content-Language . Если ваша целевая аудитория говорит на нескольких языках, заголовок HTTP позволяет использовать список языков, разделенных запятыми.
Если ваша целевая аудитория говорит на нескольких языках, заголовок HTTP позволяет использовать список языков, разделенных запятыми.
Вот пример HTTP-заголовка, объявляющего, что ресурс представляет собой смесь английского, хинди и панджаби:
Content-Language: en, hi, pa
Обратите внимание, что этот подход не эффективен, если доступ к вашей странице осуществляется с жесткого диска, диска или другого местоположения, не относящегося к серверу. В настоящее время не существует широко признанного способа использования такого рода метаданных на странице.
В прошлом многие люди использовали meta элемент с атрибутом http-Equiv , установленным на Content-Language . Из-за давних недоразумений и несовместимых реализаций этого элемента спецификация HTML5 сделала его несоответствующим в HTML, поэтому вам больше не следует его использовать.
Для обратной совместимости HTML5 описывает алгоритм, с помощью которого при определенных условиях можно определить язык содержимого по умолчанию из мета-информации HTTP или Content-Language .Однако это только резервный механизм для случаев, когда в теге html не использовался атрибут языка. Если вы использовали атрибут языка в теге html , как всегда, такие резервные варианты не имеют значения.
Для получения информации о Content-Language в HTTP и мета-элементах см. HTTP и мета для информации о языке .
Разные вещи, не относящиеся к делу
На всякий случай и для полноты, возможно, стоит упомянуть еще несколько моментов, которые не имеют отношения к и имеют отношение к этому обсуждению.
Во-первых, невозможно объявить язык текста с помощью CSS.
Во-вторых, DOCTYPE , который должен запускать любой файл HTML, может содержать то, что некоторым людям кажется декларацией языка. DOCTYPE в приведенном ниже примере содержит текст EN, что означает «английский». Это, однако, указывает на язык схемы , связанной с этим документом — это не имеет ничего общего с языком самого документа.
В-третьих, иногда люди предполагают, что информацию о естественном языке можно вывести из кодировки символов. Однако кодировка символов не позволяет однозначно идентифицировать естественный язык: здесь должно быть взаимно однозначное сопоставление между кодировкой и языком, чтобы этот вывод работал, а его нет.Например, единственная кодировка символов может использоваться для многих языков, например. Latin 1 (ISO-8859-1) может кодировать как французский, так и английский, а также множество других языков. Кроме того, кодировка символов может различаться для одного языка, например, арабский может использовать такие кодировки, как «Windows-1256», «ISO-8859-6» или «UTF-8».
Однако все эти примеры кодирования в настоящее время являются спорными, поскольку весь контент должен быть написан в UTF-8, который охватывает все языки, кроме самых редких, в единой кодировке символов.
В некоторых сценариях, таких как арабский и иврит, отображаемый текст читается преимущественно справа налево, хотя в этом потоке числа и текст из других сценариев отображаются слева направо. Разметка, такая как атрибут dir , необходима для установки общего контекста с письмом справа налево, а в некоторых случаях разметка необходима для правильного отображения двунаправленного текста, но это невозможно сделать с помощью языковой разметки.
То же самое и с направлением текста.![]() Как и в случае с кодировками и языком, не всегда существует взаимно однозначное соответствие между языком и сценарием и, следовательно, направленность.Например, азербайджанский может быть написан с использованием сценариев с письмом справа налево (арабский) и слева направо (латиница или кириллица), и код языка
Как и в случае с кодировками и языком, не всегда существует взаимно однозначное соответствие между языком и сценарием и, следовательно, направленность.Например, азербайджанский может быть написан с использованием сценариев с письмом справа налево (арабский) и слева направо (латиница или кириллица), и код языка az может быть актуален для любого из них. Кроме того, разметка направления текста, используемая со встроенным текстом, применяет к тексту диапазон различных значений, тогда как язык — это простой переключатель, который не соответствует требуемым задачам.
Зачем нужен атрибут языка?
Целевая аудитория: HTML-кодеры (с использованием редакторов или сценариев), разработчики сценариев (PHP, JSP и т. Д.)), и всем, кто задается вопросом, почему им следует использовать языковые атрибуты в HTML.
Почему я должен использовать атрибут языка на веб-страницах?
Атрибут lang (или иногда xml: lang ) определяет естественный язык содержимого веб-страницы. Атрибут в теге html устанавливает язык для всего текста на странице. Если часть страницы использует текст на другом языке, вы можете добавить атрибут языка с другим значением к элементу, который окружает это содержимое.Для получения информации об использовании языковых атрибутов см. Объявление языка в HTML .
Определение языка вашего контента позволяет автоматически делать ряд вещей, от изменения внешнего вида и поведения страницы до извлечения информации и изменения способа работы приложения. Некоторые языковые приложения работают на уровне документа в целом, некоторые работают с соответствующим образом помеченными фрагментами документа.
Лучше всего добавить информацию о языке к вашему контенту сейчас, чтобы иметь возможность воспользоваться преимуществами при появлении новых разработок.Это просто сделать при создании контента, но потом сложнее модифицировать.
Мы перечисляем здесь несколько способов использования языковой информации на данный момент, однако по мере развития спецификаций и браузеров в будущем могут появиться многочисленные дополнительные приложения для языковой информации.
Стили страниц
Атрибуты языка позволяют вам изменять стиль вашего контента в зависимости от языка. Дополнительные сведения о том, как это сделать, см. В разделе Стили с использованием атрибута lang .
Например, шрифты или межстрочный интервал может потребоваться изменить на приспособлены к разным алфавитам, кавычки, созданные по стилю, могут быть разными в зависимости от языка, возможно, потребуется выразить акцент на языке зависимые пути и др.
В следующем примере показано, как можно установить определенный шрифт для встроенного арабского текста на странице.
body { Семейство шрифтов : "Palatino Linotype",
«Книжная Антиква», Палатино, с засечками; } : lang (ar) { Семейство шрифтов : "Традиционный арабский",
«Аль-Баян», с засечками; }
Еще один пример языкового поведения — расстановка переносов.Правила расстановки переносов очень зависят от языка. Описание свойства дефисов в CSS (которое на момент написания только начинает восприниматься браузерами) гласит: «Для правильной автоматической расстановки переносов требуется ресурс расстановки переносов, соответствующий языку разбиваемого текста. UA — это поэтому требуется только автоматически переносить текст, для которого автор объявил язык (например, через HTML lang или XML xml: lang ) и для которого имеется соответствующий ресурс для расстановки переносов.«
Другие типографские функции и особенности макета, на которые влияет язык, включают перенос строк, выравнивание и преобразование регистра, и многое другое появляется по мере разработки спецификаций.
Выбор шрифта
Пользовательские агенты могут (и используют) информацию о языке для выбора подходящих для языка шрифтов, что улучшает общее впечатление пользователя от страницы.
Например, на странице, закодированной в Unicode, текст на упрощенном китайском, традиционном китайском, Японский и корейский языки могут использовать один и тот же код для идеографического символа, но носители эти языки ожидают, что используемые глифы будут различаться в мелких деталях от языка к языку.В отсутствие явного стиля, примененного автором контента, некоторые браузеры автоматически назначьте соответствующие шрифты в соответствии с языком контента. На рисунке ниже показано влияние на текст ничего не меняя, кроме значения атрибута языка в браузере, таком как Firefox или Internet Explorer.
Поиск
Хотя автоматическое определение языка обычно используется основными поисковыми системами для определения языка ресурсов, внутренняя разметка страницы может использоваться для улучшения качества результатов поиска на основе языковых предпочтений пользователя.
Проверка орфографии и грамматики
Инструменты разработки могут адаптировать проверку орфографии и грамматики в зависимости от языка содержимого или игнорировать содержимое, которое не на языке средства проверки орфографии. Это может значительно повысить эффективность проверки орфографии.
Браузеры также недавно начали позволять пользователям проверять орфографию текста, который они вводят в формы или элементы с установленным атрибутом contenteditable . Браузер, который принимает во внимание информацию о языке контента, может обеспечить более эффективное взаимодействие с пользователем.
Перевод
Инструменты переводамогут использовать языковые атрибуты для распознавания страниц или разделов текста на определенном языке и автоматически настраивать рабочий процесс или защищать текст от изменений переводчиком в инструментах перевода.
Нетекстовые считыватели
Информация о языке помогает синтезаторам речи и переводчикам Брайля получать полезные результаты. Эти приложениям необходимо знать, могут ли они производить вывод из текста или, возможно, им нужно переключиться в другой языковой режим.
Языковые теги рекомендованы W3C Web Accessibility Guidelines, которые в некоторых странах применяются в соответствии с государственной политикой, например. Великобритания — Закон о дискриминации инвалидов (Великобритания).
Парсеры и скрипты
Пометка контента с помощью языковой информации также позволяет обрабатывать данные на конкретном языке.
Например, скрипт или таблицу стилей XSLT можно использовать для различных действий, в том числе:
- извлечь текст для конкретного языка со страницы
- искать и выбирать информацию со страниц на определенном языке
- изменить порядок содержимого в соответствии с заданным языком (порядок сортировки сильно зависит от языка)
- применить стиль, зависящий от языка и региональных параметров, например соответствующая подстановка или выделение кавычек во время преобразования в другой формат, например XSL-FO.
Имейте в виду, что при создании информации вы не всегда знаете, как люди захотят обрабатывать вашу информацию позже.
Полезность языковых тегов возросла за последние годы по мере развития технологий, и по мере нашего продвижения она будет расти. Во многих случаях эти приложения могут быть не такими важными для вас при первой разработке контента, но со временем их ценность может расти. Однако мы в настоящее время столкнулся с круговой проблемой.Люди, которые не видят приложений языковой информации, не предоставляют информацию о языке своего содержание. Приложения, связанные с языком, развертываются медленно, пока эта информация не будет широко применена к контенту. Этот цикл можно разорвать авторы контента, само собой разумеющееся, объявляют информацию о языке. Чем больше контента помечено и правильно размечено, тем более полезными и широко распространенными станут такие приложения. Добавление языковой информации обычно легко сделать и не влечет за собой штрафных санкций.
Доступность в Пенсильвании | Языковые теги в HTML
Сводка
- По возможности используйте кодировку Unicode.
- Используйте тег LANG, чтобы отмечать слова или отрывки текста на другом языке. Это работает только для основных языков .
- Рассмотрите возможность дополнения языковых изменений текстовой индикацией (визуальной или скрытой), чтобы указать, когда идет слово или отрывок на иностранном языке.
О языковых тегах
Тег LANG (т.е. атрибут lang = "" ) предназначен для сигналов программ чтения с экрана для переключения на другой язык. По этой и другим причинам в WCAG 2.0 требуется пометка веб-текста как написанного на определенном языке.
Руководство 3.1.1 WCAG 2.0 — «Стандартный человеческий язык каждой веб-страницы может быть определен программно».
Еще более важным является использование языковых тегов, чтобы сигнализировать о переключении языков.
WCAG 2.0 Рекомендация 3.1.2 — «Человеческий язык каждого отрывка или фразы в содержании может быть определен программно, за исключением имен собственных, технических терминов, слов неопределенного языка, а также слов или фраз, которые стали частью местного языка. окружающий текст. «
Объявление языка страницы
Атрибут LANG предназначен для сообщения программ чтения с экрана о необходимости переключения на другой язык. Официальная рекомендация W3C — объявить основной язык для каждой веб-страницы с помощью <...lang => в теге . Коды — это коды языков ISO-639, некоторые из которых перечислены ниже на этой странице.
ПРИМЕЧАНИЕ: Вы также должны указать кодировку в
в дополнение к языку. Язык и его сценарий независимы.
Объявление американской английской страницы (штат Пенсильвания)
lang = "en-US" > ...
Объявление британского английского Страница
lang = "en-GB" > ...
Программы чтения с экрана, поддерживающие этот тег, могут переключаться на британский акцент.
Объявление французской страницы
lang = "fr" > ...
Программы чтения с экрана, поддерживающие этот тег, могут переключаться на французский акцент.
Переключение языков
Если вы переключаете языки на одной странице, вы можете встроить LANG атрибут
в другие теги, такие как P, TD, SPAN, DIV и
другие теги.Например
Тестовый текст с тегами языка
Это предложение по умолчанию — американский английский.
Это предложение будет читаться с британским акцентом.
Esta frase es en español. (испанский)
Cette фраза est en français. (французский)
Mae’r frawddeg hon yng Nghymraeg. (валлийский — не поддерживается)
Посмотреть код
Это предложение на английском языке. lang = "en-GB" > Это предложение будет читаться с британским акцентом lang = "es" > Esta frase es en espa & ntilde; ol . lang = "fr" > Cette фраза est en fran & ccedil; ais lang = "cy" > Mae'r frawddeg hon yng Nghymraeg.
Общие языковые коды
Две буквы vs.Три буквы
Первый набор языковых кодов (ISO-639) был двухбуквенным, но не охватывал все языки. В результате были созданы наборы трехбуквенных кодов (ISO-639-2 / ISO-639-3) для охвата большего количества языков.
Для любого языка стандарты указывают на использовать двухбуквенный код, если он существует . Используйте трехбуквенный код, только если другой код недоступен. Полный список кодов языков, включая исходные коды ISO-639 и более поздние варианты, см. В таблицах кодов ISO 639.
Западноевропейские языки
Эти коды поддерживаются многими программами чтения с экрана, включая JAWS.
Не западноевропейские языки
| Язык | Код | Варианты |
|---|---|---|
| Арабский | ar | См. Информацию на арабском языке |
| китайский | ж |
|
| Еврейский | он | Без основных вариантов |
| Хинди | привет | Без основных вариантов |
| Японский | и | Без основных вариантов |
| Корейский | ko | Без основных вариантов |
| Суахили | sw | Без основных вариантов |
Древние языки
| Язык | Код | Варианты |
|---|---|---|
| Древнегреческий | grc | |
| Латиница | la | Без основных вариантов |
| Староанглийский | углов | Без основных вариантов |
| Среднеанглийский | enm | Без основных вариантов |
Дополнительные сигналы неанглийского содержания
Помимо использования тега LANG , вы также можете включить указание в текст, чтобы пользователи старых программ чтения с экрана могли вручную выбирать языки.Это можно сделать, указав начало / конец отрывка в тексте (желательно в тегах h2, h3 или как часть набора ссылок) или в теге alt невидимой графики.
Правописание названия языка в тексте
Переводы Всеобщей декларации прав человека ООН
Испанский | Французский… (Меню предоставляет быстрый
список неанглийских отрывков). По-прежнему рекомендуется использовать тег LANG.
Статья 1 на испанском языке (По буквам)
Artículo 1
Todos los seres humanos nacen libres e iguales en dignidad y derechos y, dotados como están de razón y conciencia, deben comportarse fraternalmente los unos con los otros.
Французский Артикул 1
Article premier
Tous les êtres humains naissent libres et égaux en dignité et en droits. Ils sont doués de raison et de socience et doivent agir les uns envers les autres dans un esprit de fraternité.
с невидимой графикой
Более старый метод заключался в добавлении невидимой графики и использовании текста ALT для обозначения перехода на другой язык. По-прежнему рекомендуется использовать тег LANG.
Посмотреть код Начало страницы В HTML объявление языка — это атрибут, который указывает язык содержимого страницы.Выглядит это так: При определении содержимого тега Для английского языка тег будет выглядеть так: А тег для французского будет такой: Этот атрибут HTML используется различными программами, включая поисковые системы, чтобы помочь выяснить, на каком языке написана страница.Это полезно при попытке подобрать нужный контент для нужного пользователя. Атрибут HTML lang не оказывает большого влияния на SEO, когда дело касается Google. Google прямо заявил, что игнорирует теги в пользу тегов hreflang для многоязычных сайтов. Джон Мюллер из Google говорит об этом на видеовстрече для веб-мастеров: Итак, если это так, можете ли вы полностью игнорировать объявление языка? Не совсем так. В то время как Google не смотрит на языковые теги, Bing это делает. Фактически, Bing не использует тег hreflang при сопоставлении языка пользователя с содержимым страницы. Он использует так называемый метатег content-language в Вы можете проверить, что ваш язык был правильно объявлен , запустив бесплатный обзор WooRank. Тег content-language — это метатег в Тег выглядит так: В атрибуте При установке языка используйте двухбуквенный языковой код ISO 639, как если бы вы использовали языковой тег HTML. После языка должен быть указан код страны ISO 3166. Например: В то время как Bing также рассмотрит тег Даже несмотря на то, что использование HTML-атрибута объявления языка не повысит рейтинг вашего сайта, по-прежнему рекомендуется включать его для удобства использования и доступности.Вот наиболее частые ошибки, которые допускаются при использовании атрибута объявления языка. При объявлении языка необходимо использовать коды языков ISO 639-1. Одна из самых распространенных ошибок — неправильное использование этих кодов. Вероятно, самая распространенная ошибка — использовать И затем, конечно, есть ваши общие опечатки, например, использование чего-то вроде При необходимости вы можете добавить код страны в атрибут HTML lang, например, при различении американского и британского английского или французского и канадского французского. Чтобы сделать это правильно, просто добавьте страну после языка, используя тире, например: Указывает язык страницы на американском английском (так что ничего из этих надоедливых лишних «u»). Самая распространенная ошибка при добавлении кодов страны, как и в случае с кодом языка, — использование неправильного кода.Допустимые коды стран используют стандарт ISO 3166-1. Другая распространенная ошибка, которую делают люди при добавлении кода страны, — это ставить страну на первое место, например: Помните, язык всегда должен стоять перед кодом страны. RFC 3066 дает подробную информацию о допустимых значениях (выделение и ссылки добавлены): Все двухбуквенные подтэги интерпретируются как коды стран ISO 3166 alpha-2.
из [ISO 3166] , или впоследствии присвоенный техническим обслуживанием ISO 3166
агентство или руководящие органы по стандартизации, обозначающие область, в которую
этот языковой вариант относится. Я интерпретирую это как означающий, что любой допустимый (согласно ISO 3166) двухбуквенный код действителен как вложенный тег. В RFC говорится: Теги со вторыми подтэгами от 3 до 8 букв могут быть зарегистрированы с
IANA в соответствии с правилами, изложенными в главе 5 этого документа. Между прочим, это похоже на опечатку, поскольку глава 3, похоже, имеет отношение к процессу регистрации, а не к главе 5. Быстрый поиск в реестре IANA показывает очень длинный список всех доступных языковых вложенных тегов.Вот один пример из списка (который будет использоваться как Тип: вариант Подтег: scouse Описание: Scouse Добавлен: 18.09.2006 Префикс: en Комментарии: Английский ливерпудский диалект, известный как «Scouse» Доступно всевозможных субтегов, вложенных тегов; быстрый свиток уже показал Полезность некоторых из этих (я бы сказал, подавляющего большинства из них) тегов, когда дело доходит до документов, предназначенных для отображения в браузере, ограничена.В спецификации W3C Internationalization просто указано: Браузеры и другие приложения могут использовать информацию о языке
контента, чтобы предоставить пользователям наиболее подходящую информацию, или
представлять информацию пользователям наиболее подходящим способом. Чем больше
контент помечен и помечен правильно, более полезный и распространенный
такие приложения станут. Я изо всех сил пытаюсь найти подробную информацию о том, как браузеры ведут себя при встрече с тегами разных языков, но они, скорее всего, принесут некоторую пользу тем пользователям, которые используют программу чтения с экрана, которая может использовать тег для определения языка / диалекта / акцент, в котором излагается содержание. ![]()
![]() alt = "Начать испанский" >
alt = "Начать испанский" > Атрибут языка HTML / Справочник по языку ISO / Названия культур · GitHub
CULTURE SPEC.КУЛЬТУРА АНГЛИЙСКОЕ НАЗВАНИЕ ————————————————- ————- Неизменяемый язык (неизменяемая страна) af af-ZA Африкаанс af-ZA af-ZA Африкаанс (Южная Африка) ar ar-SA арабский ar-AE ar-AE Арабский (U.A.E.) ar-BH ar-BH Арабский (Бахрейн) ar-DZ ar-DZ Арабский (Алжир) ar-EG ar-EG Арабский (Египет) ar-IQ ar-IQ Арабский (Ирак) ar-JO ar-JO Арабский (Иордания) ar-KW ar-KW Арабский (Кувейт) ar-LB ar-LB Арабский (Ливан) ar-LY ar-LY Арабский (Ливия) ar-MA ar-MA Арабский (Марокко) ар-ОМ ар-ОМ Арабский (Оман) ar-QA ar-QA Арабский (Катар) ar-SA ar-SA Арабский (Саудовская Аравия) ar-SY ar-SY Арабский (Сирия) ar-TN ar-TN Арабский (Тунис) ar-YE ar-YE Арабский (Йемен) az az-Latn-AZ Азербайджанский az-Cyrl-AZ az-Cyrl-AZ Азери (кириллица, Азербайджан) az-Latn-AZ az-Latn-AZ Азери (латиница, Азербайджан) be be-BY Белорусский be-BY be-BY Белорусский (Беларусь) bg bg-BG Болгарка bg-BG bg-BG Болгарский (Болгария) bs-Latn-BA bs-Latn-BA Боснийский (Босния и Герцеговина) ca ca-ES Каталонский ca-ES ca-ES Каталонский (каталонский) cs cs-CZ Чешский cs-CZ cs-CZ Чехия (Чехия) cy-GB cy-GB Валлийский (Великобритания) da da-DK датский da-DK da-DK Датский (Дания) de-DE Немецкий de-AT de-AT Немецкий (Австрия) de-DE de-DE Немецкий (Германия) de-CH de-CH Немецкий (Швейцария) de-LI de-LI German (Лихтенштейн) de-LU de-LU Немецкий (Люксембург) дв дв-МВ Дивехи дв-МВ дв-МВ Дивехи (Мальдивы) el el-GR Греческий el-GR el-GR Греческий (Греция) en en-US Английский en-029 en-029 Английский (Карибский бассейн) en-AU en-AU Английский (Австралия) en-BZ en-BZ Английский (Белиз) en-CA en-CA Английский (Канада) en-GB en-GB Английский (Великобритания) en-IE en-IE Английский (Ирландия) en-JM en-JM Английский (Ямайка) en-NZ en-NZ Английский (Новая Зеландия) en-PH en-PH Английский (Республика Филиппины) en-TT en-TT Английский (Тринидад и Тобаго) en-US en-US Английский (США) en-ZA en-ZA Английский (Южная Африка) en-ZW en-ZW Английский (Зимбабве) es es-ES Испанский es-AR es-AR Испанский (Аргентина) es-BO es-BO Испанский (Боливия) es-CL es-CL Испанский (Чили) es-CO es-CO Испанский (Колумбия) es-CR es-CR Испанский (Коста-Рика) es-DO es-DO Испанский (Доминиканская Республика) es-EC es-EC Испанский (Эквадор) es-ES es-ES Испанский (Испания) es-GT es-GT Испанский (Гватемала) es-HN es-HN Испанский (Гондурас) es-MX es-MX Испанский (Мексика) es-NI es-NI Испанский (Никарагуа) es-PA es-PA Испанский (Панама) es-PE es-PE Испанский (Перу) es-PR es-PR Испанский (Пуэрто-Рико) es-PY es-PY Испанский (Парагвай) es-SV es-SV Испанский (Сальвадор) es-UY es-UY Испанский (Уругвай) es-VE es-VE Испанский (Венесуэла) et et-EE Эстонский et-EE et-EE Эстонский (Эстония) eu eu-ES Basque eu-ES eu-ES Basque (Баскский) fa fa-IR Персидский fa-IR fa-IR Персидский (Иран) fi fi-FI Финский fi-FI fi-FI Финский (Финляндия) fo fo-FO Фарерские острова fo-FO fo-FO Фарерские острова (Фарерские острова) fr fr-FR французский fr-BE fr-BE Французский (Бельгия) fr-CA fr-CA Французский (Канада) fr-FR fr-FR Французский (Франция) fr-CH fr-CH Французский (Швейцария) fr-LU fr-LU Французский (Люксембург) fr-MC fr-MC Французский (Княжество Монако) gl gl-ES Галицкий gl-ES gl-ES Галицкий (Галисийский) гу гу-IN Гуджарати гу-ИН гу-ИН Гуджарати (Индия) he he-IL Еврейский he-IL he-IL Еврейский (Израиль) привет привет-IN хинди hi-IN hi-IN Хинди (Индия) hr hr-HR Хорватский hr-BA hr-BA Хорватский (Босния и Герцеговина) hr-HR hr-HR Хорватский (Хорватия) hu hu-HU Венгерский hu-HU hu-HU Венгерский (Венгрия) hy hy-AM Армянский hy-AM hy-AM Армения (Армения) id id-ID Индонезийский id-ID id-ID Индонезийский (Индонезия) is-IS исландский is-IS is-IS Исландский (Исландия) it it-it итальянский it-CH it-CH Итальянский (Швейцария) it-IT it-IT итальянский (Италия) ja ja-JP Японский ja-JP ja-JP Японский (Япония) ка ка-GE Грузинская ka-GE ka-GE Грузия (Грузия) кк кк-KZ казахстан kk-KZ kk-KZ Казахстан (Казахстан) kn kn-IN каннада кн-IN кн-IN Каннада (Индия) ko ko-KR Корейский кок кок-ИН Конкани кок-ИН кок-ИН Конкани (Индия) ko-KR ko-KR Корейский (Корея) тыс. Кы-кг Кыргызстан кы-КГ кы-КГ Кыргызстан (Кыргызстан) lt lt-LT Литовский lt-LT lt-LT Литовский (Литва) lv lv-LV Латвийский lv-LV lv-LV Латвийский (Латвия) миль-NZ mi-NZ Маори (Новая Зеландия) мк мк-мк македонский mk-MK mk-MK Македонский (бывшая югославская Республика Македония) млн мин-мин Монгольский mn-MN mn-MN Монгольский (кириллица, Монголия) MR MR-IN Маратхи MR-IN MR-IN Marathi (Индия) мс ms-малайский ms-BN ms-BN Малайский (Бруней-Даруссалам) ms-MY ms-MY Малайский (Малайзия) mt-MT mt-MT Мальтийский (Мальта) nb-NO nb-NO Норвежский, Бокмал (Норвегия) nl nl-NL Голландский nl-BE nl-BE Голландский (Бельгия) nl-NL nl-NL Голландский (Нидерланды) nn-NO nn-NO Норвежский, Нюнорск (Норвегия) no nb-NO норвежский ns-ZA ns-ZA Северный Сото (ЮАР) pa pa-IN панджаби pa-IN pa-IN Пенджаби (Индия) pl pl-PL Польский pl-PL pl-PL Польский (Польша) pt pt-BR Португальский pt-BR pt-BR Португальский (Бразилия) pt-PT pt-PT Португальский (Португалия) quz-BO quz-BO Quechua (Боливия) quz-EC quz-EC Quechua (Эквадор) quz-PE quz-PE Quechua (Перу) ro ro-RO Румынский ro-RO ro-RO Румынский (Румыния) ru ru-RU Русский ru-RU ru-RU Россия (Россия) sa sa-IN Санскрит sa-IN sa-IN Санскрит (Индия) se-FI se-FI Sami (Северный) (Финляндия) se-NO se-NO Сами (Северный) (Норвегия) se-SE se-SE Саамский (Северный) (Швеция) sk sk-SK Словацкий sk-SK sk-SK Словацкий (Словакия) sl sl-SI словенский sl-SI sl-SI словенский (Словения) sma-NO sma-NO Сами (Южный) (Норвегия) sma-SE sma-SE Сами (Южный) (Швеция) smj-NO smj-NO Сами (Луле) (Норвегия) smj-SE smj-SE Сами (Луле) (Швеция) smn-FI smn-FI Sami (Inari) (Финляндия) sms-FI sms-FI Sami (Skolt) (Финляндия) кв. Кв. Албанский sq-AL sq-AL Албанский (Албания) sr sr-Latn-CS сербский sr-Cyrl-BA sr-Cyrl-BA Сербский (кириллица) (Босния и Герцеговина) sr-Cyrl-CS sr-Cyrl-CS Сербский (кириллица, Сербия) sr-Latn-BA sr-Latn-BA Сербский (латиница) (Босния и Герцеговина) sr-Latn-CS sr-Latn-CS Сербский (латиница, Сербия) sv sv-SE шведский sv-FI sv-FI шведский (Финляндия) sv-SE sv-SE Шведский (Швеция) SW SW-KE кисуахили sw-KE sw-KE Kiswahili (Кения) syr syr-SY Сирийский syr-SY syr-SY Сирийский (Сирия) ta ta-IN тамильский ta-IN ta-IN тамильский (Индия) te te-IN телугу te-IN te-IN телугу (Индия) -й тайский th-TH th-TH Тайский (Таиланд) tn-ZA tn-ZA Tswana (ЮАР) tr tr-TR Турецкий tr-TR tr-TR Турецкий (Турция) tt tt-RU Татарский tt-RU tt-RU Татарский (Россия) uk uk-UA Украинский uk-UA uk-UA Украинский (Украина) ур ур-ПК урду ур-ПК ур-ПК урду (Исламская Республика Пакистан) uz uz-Latn-UZ Узбекский uz-Cyrl-UZ uz-Cyrl-UZ Узбекский (кириллица, Узбекистан) uz-Latn-UZ uz-Latn-UZ Узбекский (латиница, Узбекистан) vi vi-VN Вьетнамский vi-VN vi-VN Вьетнамский (Вьетнам) xh-ZA xh-ZA Xhosa (ЮАР) zh-CN zh-CN Китайский (Китайская Народная Республика) zh-HK zh-HK Китайский (Гонконг S.A.R.) zh-CHS (нет) Китайский (упрощенный) zh-CHT (нет) Китайский (традиционный) zh-MO zh-MO китайский (Macao S.A.R.) zh-SG zh-SG Китайский (Сингапур) zh-TW zh-TW Китайский (Тайвань) zu-ZA zu-ZA Zulu (Южная Африка) Передовой опыт декларации языка HTML
Что такое атрибут языка?
...
lang используйте коды языков ISO 639-1.
...
...
Имеет ли значение языковой атрибут в SEO?
документа. Что такое метатег «content-language»?
HTML-документа, в котором указываются язык и страна, для которых содержание страницы наиболее актуально.
содержимого вы определяете язык и страну. Итак, для американского английского это будет выглядеть так:
, но отдает приоритет тегу . Ошибки объявления общего языка
Используется неправильный код языка
eng для английского языка вместо en . Вот некоторые другие распространенные ошибки: ch для китайского языка вместо zh sp для испанского вместо es будет для бенгальского вместо млрд ft для французского языка вместо fr . Ошибки с кодами стран
В чем разница между и?
en-scouse ): fr-1694acad (французский язык 17 века).