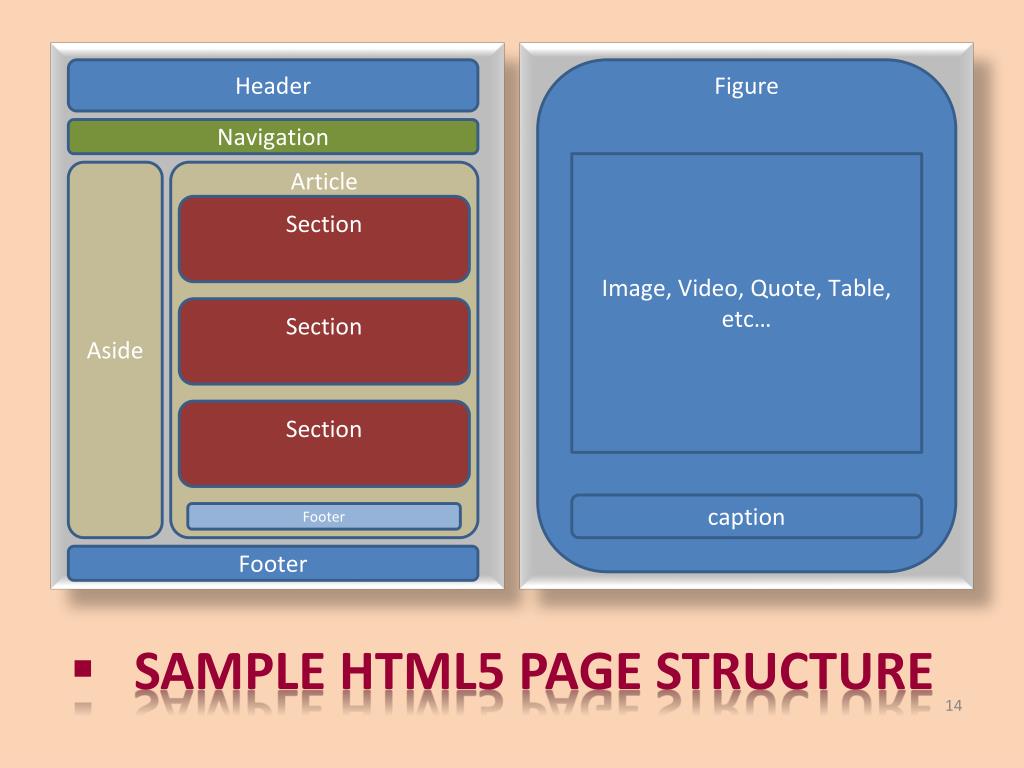
Тег header. Классы, селекторы и свойства в CSS
Начало урока. Разбор файла index.html
В index.html по сравнению с предыдущим уроком изменилось немного. Я только добавил после <body> следующий код:
<header> </header>
Верхнюю часть сайта, называемую «шапка», помещают в специальный тег <header></header>.
На вашем сайте в <header></header> будет вся красная верхушка, как на imdiz.ru/store/:
Цвет фона для header я задал свойством background в style.css. Если Вы еще не открыли файл style.css в SublimeText, то откройте.
Сейчас у Вас в SublimeText открыто 2 файла: index.html и style.css. Для удобства сделайте следующее: вверху SublimeText нажмите View, в выпавшем окне наведите на Layout, и выберите там Columns: 2. Ваш редактор разделится на 2 колонки и файлы можно разместить в разных колонках. Так вы будете видеть сразу оба файла. Смотрите видео:
Разбор файла style.css
Разберем файл style.css и заодно познакомимся с CSS.
Сперва пропустим верхнюю часть кода и перейдем к участку:
.header{
background: #cb2d41;
height: 100px;
}Говоря по-русски, благодаря этому коду браузер будет искать в index.html тег с классом header и задаст этому тегу цвет фона #cb2d41 и высоту 100px.
А теперь по-подробнее.
Этот код задает стили для <header>, который находится в index.html. Здесь задан цвет фона (background) и высота (height).
Посмотрите на картинку ниже, на ней изображена структура стилей в CSS:
То есть структура следующая. Сперва пишется селектор, в нашем случае это класс .header. Именно по селектору браузер определяет, для какого тега в index.html нужно применить CSS-свойства. В фигурных скобках прописываются нужные CSS-стили для этого селектора: свойство и значение этого свойства.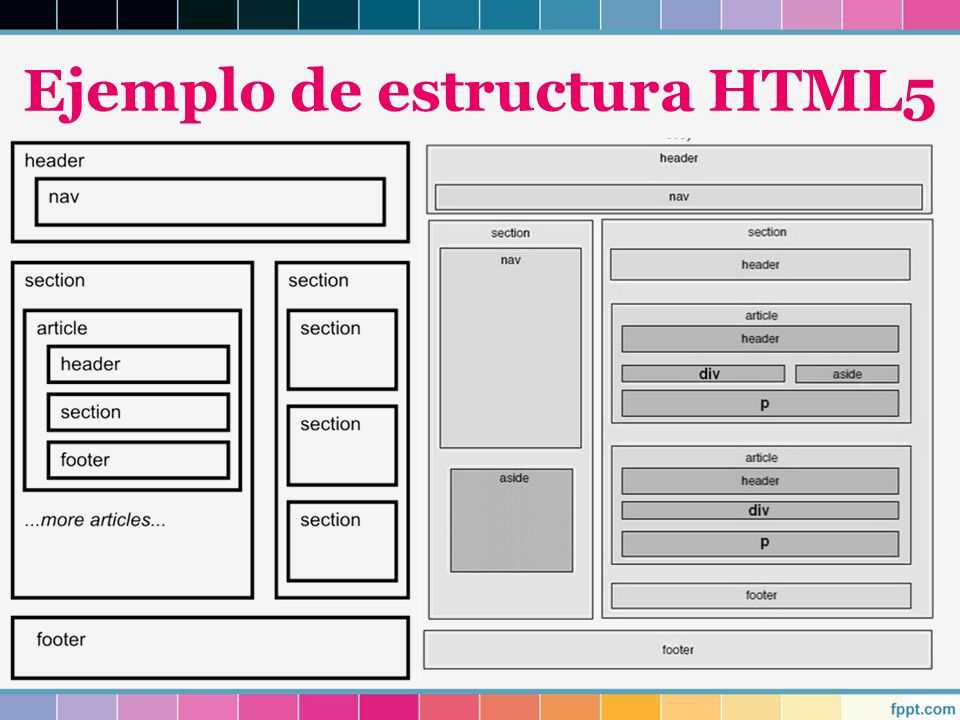
#cb2d41 — такой формат задания цвета называется HEX. Это наиболее частый формат в верстке сайтов. Цвет можно задать просто английским словом, например, background: red. Но чаще (а точнее, практически всегда) применяется именно формат HEX.
В index.html я задал тегу header класс «header». И в style.css задал стили для этого класса — .header. В CSS точка перед названием селектора означает, что это селектора класса.
В профессиональной верстке использовать селектор класса это почти стандарт, и нужно всегда стараться использовать именно селектор класса.
Кстати, название класса может быть абсолютно любым, хоть abcdef, но все-таки удобнее называть классы по смыслу элемента. У нас таким элементом является тег <header>, и здесь можно не выдумывать велосипед и назвать класс тоже header.
В нашем коде для .header помимо background задана еще и высота height: 100px;.
Переопределение стилей браузера. Инструменты разработчика в браузере
Теперь в Вашем style.css вернитесь к участку кода:
html, body{
margin: 0;
}Селекторы можно прописывать через запятую. В данном случае CSS-стили в фигурных скобках будут применены и для тега html, и для тега body.
Этот код равнозначен следующему:
html{
margin: 0;
}
body{
margin: 0;
}И еще обратите внимание, что здесь используется селектор тега, а не класса. Точка перед именем селектора не стоит.
А теперь о том, для чего нужен этот участок кода. Если Вы удалите этот участок кода и сохраните style.css, то увидите в браузере, что шапка не на всю ширину браузера (слева, справа, а также сверху, будут белые полоски). Это потому, что в каждом браузере уже прописаны некоторые стили для всех HTML-тегов. Это стили браузера по умолчанию. В нашем случае белые полосы будут из-за того, что для тега <body></body> в браузере указаны отступы (в CSS для этого используется свойство margin). Чтобы это увидеть вызовите в браузере средства разработчика. Для этого, если у вас Google Chrome или Yandex Browser, просто нажмите на клавиатуре F12.
Это потому, что в каждом браузере уже прописаны некоторые стили для всех HTML-тегов. Это стили браузера по умолчанию. В нашем случае белые полосы будут из-за того, что для тега <body></body> в браузере указаны отступы (в CSS для этого используется свойство margin). Чтобы это увидеть вызовите в браузере средства разработчика. Для этого, если у вас Google Chrome или Yandex Browser, просто нажмите на клавиатуре F12.
С инструментами разработчика удобнее работать, когда окно открыто внизу. Для того, чтобы его перенести вниз, нажмите справа на 3 точки, и в открывшемся окошке выберите нужное расположение. Смотрите видео:
В средствах разработчика видна структура HTML, а справа CSS-стили выделенного HTML-тега. Если Вы нажмете на <body>, то справа в CSS увидите, что помимо наших стилей у body есть еще другие стили, и в них margin: 8px;.
Комментарии в HTML
Помните в начале урока написано, что новые участки кода находятся между <!— New —><!— End —>. Сами <!— New —> и <!— End —> никак не отобразятся в браузере. С помощью <!— —> осуществляется комментирование в HTML. Всё, что Вы поместите внутрь данной конструкции не отобразится в браузере, оно будет закомментировано. С помощью комментариев можно помещать какие-то подсказки для себя. Также, комментировать можно некоторые участки кода, чтобы временно их скрыть, при этом не придется их удалять.
Подытожу этот урок тем, что в CSS не так уж много свойств и их значений. На практике все CSS-свойства быстро запоминаются. Все CSS-свойства являются английскими словами, например, height переводится «высота». И это тоже очень хорошо для запоминания CSS-свойств.
Конец урока. В данном уроке вы узнали:
background — CSS-свойство для задания фона HTML-элемента
height — свойство для задания высоты
margin — внешние отступы
<header></header> — тег для «шапки» сайта.
Блок не отображается на сайте, если он пустой или ему не задана высота.
Стандартные стили браузера нужно переопределять.
В Google Chrome и Yandex Browser есть инструменты разработчика, которые вызываются клавишей F12.
Стили в CSS задаются через селекторы. В качестве селектора нужно стараться выбирать класс HTML-элемента.
Элемент — CSS-LIVE
Ричард Кларк, вторник, 16 июня 2009
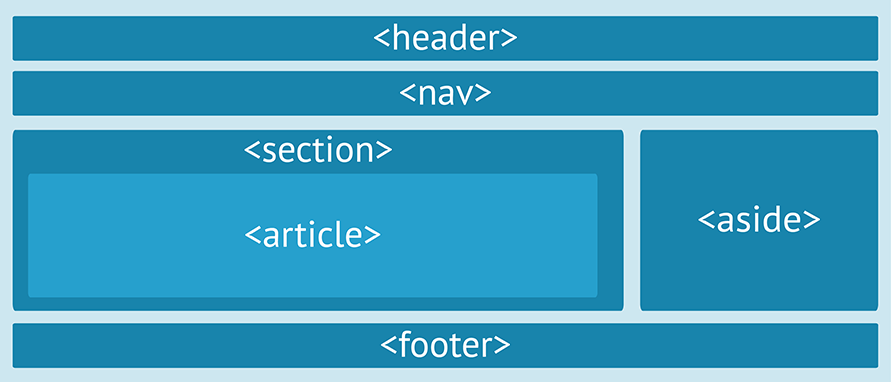
В последнее время наблюдается повышенный интерес к HTML 5 и его внедрению в работу web-профессионалов. В HTML 5 спецификации мы видим, что была добавлена масса новых тегов, среди которых и элемент <header>, о котором мы поговорим в этой статье. Мы расскажем про то, когда его использовать и когда не использовать, что он должен содержать и что не должен. Готовы? Тогда начнем.
Итак, вы привыкли видеть
<div>
на большинстве посещаемых вами сайтов. Теперь, с появлением HTML 5 это больше не требуется и мы можем обогатить семантическое содержимое новым элементом <header>.
Что представляет собой этот элемент?
Спецификация дает следующее определение элемента <header>
группа элементов вводного или навигационного значения. Как правило, элемент header содержит заголовок секции (элемент h2–h6 или группу элементов hgroup), но может также иметь и другое наполнение, например, содержание, форму поиска или соответствующие логотипы.
Где можно использовать элемент <header>
<header> <h2>Самый важный заголовок на этой странице</h2> <p>С какой-либо дополнительной информацией</p> </header>
Здесь важным моментом является то, что вы не ограничиваетесь использованием только одного элемента <header> на сайте. Их может быть несколько, и каждый из них будет хедером соответствующей секции документа.
<header>
<h2>The most important heading on this page</h2>
<p>With some supplementary information</p>
</header>
<article>
<header>
<h2>Title of this article</h2>
<p>By Richard Clark</p>
</header>
<p>...Lorem Ipsum dolor set amet...</p>
</article>
Также заметьте, что использование двух <h2> в рамках этого кусочка кода вполне применимо в HTML 5 (и HTML 4), но может вызвать проблемы с доступностью. Поэтому, мы советуем быть предельно внимательными, если у вас имеется большое количество статей на странице. Более детально этот вопрос будет рассмотрен в другой статье.
Что необходимо включать в элемент <header>
Теперь мы знаем, что существует возможность иметь несколько хедеров на странице. А что насчет обязательных компонентов, которые должен содержать этот элемент для его корректной работы?
Вкратце, типичный <header> содержит как минимум (количество не ограничивается) один заглавный тег (<h2> – <h6>). Вы также можете использовать элемент <hgroup>, но об этом мы поговорим в другой статье (прочитать больше про hgroup в спецификации). Элемент может иметь и другое наполнение, как, например, содержание, логотипы или форму поиска. Согласно последним изменениям в спецификации, отныне можно включать в хедер элемент <nav>.
Вы также можете использовать элемент <hgroup>, но об этом мы поговорим в другой статье (прочитать больше про hgroup в спецификации). Элемент может иметь и другое наполнение, как, например, содержание, логотипы или форму поиска. Согласно последним изменениям в спецификации, отныне можно включать в хедер элемент <nav>.
Оформление хедера
Еще один момент, о котором я бы хотел поговорить: в большинстве браузеров для того, чтобы <header> выполнял роль блочного элемента вам будет необходимо четко обозначить его как блок в ваших CSS, например, так:
header { display:block;}
Фактически, вам нужно будет делать это для большинства блочных элементов в HTML 5. Как только это свойство станет заданным в браузерах по умолчанию, мы вам сообщим и вы сможете сберечь драгоценные байты ваших CSS. Тем временем, постарайтесь быть в курсе того, что было и что не было внедрено в браузерные движки на этом ресурсе.
Заключение
Таким образом, элемент <header> предоставляет нам дополнительные возможности семантического содержания для описания верхней части секции.
Оригинал статьи и автор
P.S. Это тоже может быть интересно:
- HTML5, Семантика
Тег HTML 5
Тег HTML
Заголовки могут содержать заголовки, подзаголовки, информацию о версии, средства навигации и т. д.
Тег , или другой элемент
См. также тег .
Тег появился в HTML 5.
Демо
Атрибуты
Теги HTML могут содержать один или несколько атрибутов. Атрибуты добавляются к тегу, чтобы предоставить браузеру больше информации о том, как тег должен выглядеть или вести себя. Атрибуты состоят из имени и значения, разделенных знаком равенства (=), при этом значение заключено в двойные кавычки. Вот пример: style="color:black;" .
Существует 3 типа атрибутов, которые вы можете добавить к своим HTML-тегам: специфичные для элемента, глобальные атрибуты и атрибуты содержимого обработчика событий.
Ниже перечислены атрибуты, которые можно добавить к этому тегу.
Специфичные для элемента атрибуты
В следующей таблице показаны атрибуты, характерные для этого тега/элемента.
| Атрибут | Описание |
|---|---|
| Нет |
Глобальные атрибуты
Следующие атрибуты являются стандартными для всех тегов HTML 5 (хотя атрибут tabindex не применяется к диалога элемента).
-
ключ доступа -
автокапитализация -
класс -
редактируемый контент -
данные-* -
каталог -
перетаскиваемый -
скрытый -
идентификатор -
режим ввода -
это -
ИД товара -
элементпроп -
Артикул -
предметная область -
тип изделия -
язык -
часть -
слот -
проверка правописания -
стиль -
tabindex -
Название -
перевод
Полное объяснение этих атрибутов см. в разделе Глобальные атрибуты HTML 5.
в разделе Глобальные атрибуты HTML 5.
Атрибуты содержимого обработчика событий
Атрибуты содержимого обработчика событий позволяют вам вызывать сценарий из вашего HTML. Скрипт вызывается, когда происходит определенное «событие». Каждый атрибут содержимого обработчика событий имеет дело с другим событием.
-
прерывание -
onauxclick -
размытие -
при отмене -
онканплей -
oncanplaythrough -
при смене -
по клику -
при закрытии -
в контекстном меню -
онкопия -
при обмене -
врезной -
ondblclick -
ондраг -
ондрагенд -
ондрагентер -
ондрагзит -
на накладке -
ондраговер -
ондрагстарт -
-
ondurationchange -
при опорожнении -
одноконцевой -
при ошибке -
онфокус -
данные формы -
на входе -
недействительный -
нажатие клавиши -
нажатие клавиши -
onkeyup -
onlanguagechange -
под нагрузкой -
загруженные данные -
загруженные метаданные -
запуск при загрузке -
-
ввод с помощью мыши -
для мышей -
onmousemove -
onmouseout -
при наведении мыши -
-
на пасте -
при паузе -
в игре -
в игре -
в процессе -
при изменении скорости -
при сбросе -
изменение размера -
при прокрутке -
нарушение политики безопасности -
поиск -
поиск -
по выбору -
onslotchange -
установлен -
при отправке -
приостановить -
своевременное обновление -
нагрудник -
при изменении объема -
в ожидании -
на колесе
Полный список обработчиков событий см. в разделе Атрибуты содержимого обработчиков событий HTML 5.
в разделе Атрибуты содержимого обработчиков событий HTML 5.
спецификаций мета-тегов роботов | Центр поиска Google | Документация
В этом документе подробно описывается, как можно использовать настройки уровня страницы и текста для настройки того, как Google
представляет ваш контент в результатах поиска. Вы можете задать настройки на уровне страницы, включив
Мета-тег на страницах HTML или в заголовке HTTP. Вы можете задать настройки уровня текста с помощью атрибут data-nosnippet для элементов HTML на странице.
Имейте в виду, что эти настройки можно прочитать и использовать только в том случае, если сканерам разрешено получить доступ к страницам, которые включают эти настройки.
К поисковой системе применяется правило .
гусеницы. Чтобы заблокировать поисковые роботы, такие как
Чтобы заблокировать поисковые роботы, такие как AdsBot-Google , вам может потребоваться добавить правила, ориентированные на конкретный
поисковый робот (например, ).
Использование тега robots
meta Метатег robots позволяет вам использовать детальный, специфичный для страницы подход к управлению тем, как
отдельная страница должна быть проиндексирована и показана пользователям в результатах поиска Google. Поместите
роботы метатег в разделе данной страницы, например
этот:
<заголовок> (…) <тело> (…)
Если вы используете CMS, например Wix, WordPress или Blogger , возможно, вы не сможете редактировать
ваш HTML напрямую, или вы можете предпочесть этого не делать.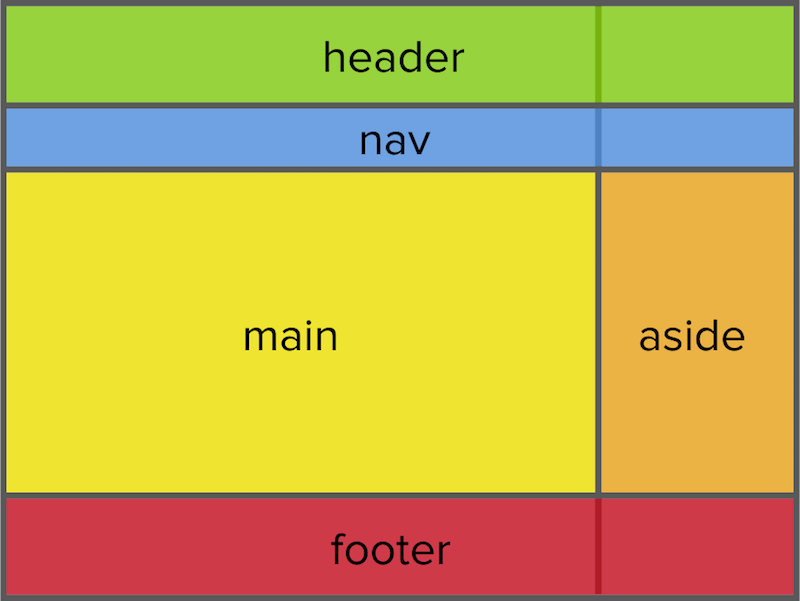 Вместо этого ваша CMS может иметь поисковую систему.
страница настроек или какой-либо другой механизм, сообщающий поисковым системам о
Вместо этого ваша CMS может иметь поисковую систему.
страница настроек или какой-либо другой механизм, сообщающий поисковым системам о метатегов .
Если вы хотите добавить на свой веб-сайт метатег , выполните поиск инструкций.
об изменении вашей страницы на вашей CMS (например,
найдите «wix добавить метатеги»).
В этом примере мета-тег robots указывает поисковым системам не показывать страницу в
результаты поиска. Значение атрибута name ( robots )
указывает, что правило применяется ко всем сканерам. К
обратиться к конкретному сканеру, замените роботов стоимость имя атрибут с именем искателя, которым вы являетесь
адресация. Определенные сканеры также известны как пользовательские агенты (сканер использует свой пользовательский агент для
запросить страницу.) Стандартный поисковый робот Google имеет имя пользовательского агента
Определенные сканеры также известны как пользовательские агенты (сканер использует свой пользовательский агент для
запросить страницу.) Стандартный поисковый робот Google имеет имя пользовательского агента Гуглбот . Чтобы предотвратить индексацию вашей страницы только Google,
обновите тег следующим образом:
Этот тег теперь предписывает Google не показывать эту страницу в результатах поиска. Оба имя и содержимое атрибуты
не чувствительны к регистру.
Поисковые системы могут иметь разные сканеры для разных целей. См.
полный список поисковых роботов Google.
Например, чтобы показать страницу в результатах веб-поиска Google, но не в Новостях Google, используйте
следующий метатег :
Чтобы указать несколько сканеров по отдельности, используйте несколько robots мета теги:
Чтобы заблокировать индексирование ресурсов, отличных от HTML, таких как файлы PDF, видеофайлы или файлы изображений,
вместо этого используйте заголовок ответа X-Robots-Tag .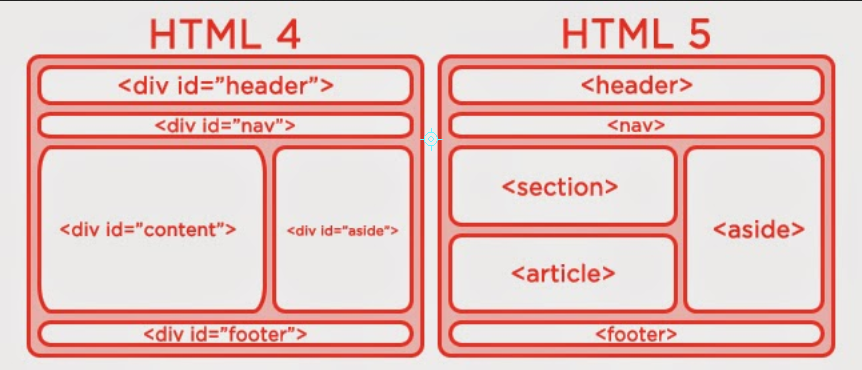
Использование
X-Robots-Tag HTTP-заголовка X-Robots-Tag можно использовать как элемент HTTP-заголовка
ответ для заданного URL. Любое правило, которое можно использовать в robots 9Метатег 0443 также может быть
указан как X-Robots-Tag . Вот пример HTTP
ответ с X-Robots-Tag , указывающим поисковым роботам не индексировать
страница:
HTTP/1.1 200 ОК Дата: вторник, 25 мая 2010 г., 21:42:43 по Гринвичу (…) X-Robots-Tag: noindex (…)
Несколько заголовков X-Robots-Tag могут быть объединены в HTTP-заголовке.
ответ, или вы можете указать список правил, разделенных запятыми. Вот пример
Ответ заголовка HTTP, который имеет без архива X-Robots-Tag в сочетании с unavailable_after X-Robots-Tag .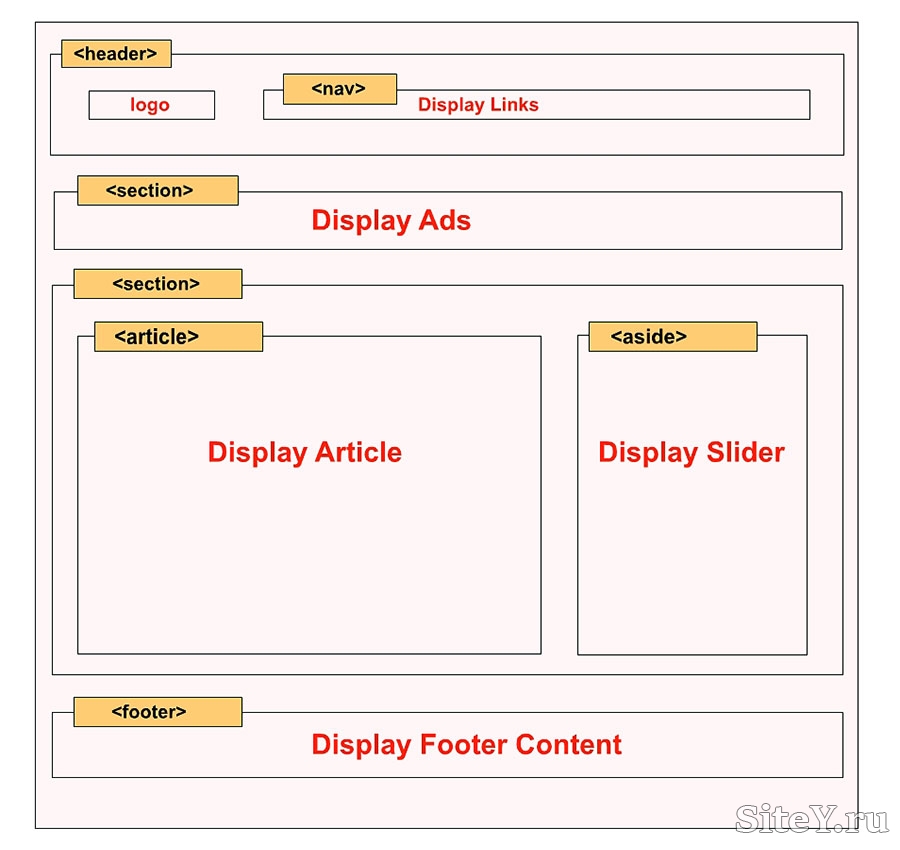
HTTP/1.1 200 ОК Дата: вторник, 25 мая 2010 г., 21:42:43 по Гринвичу (…) X-Robots-Тэг: нет в архиве X-Robots-Tag: unavailable_after: 25 июня 2010 г. 15:00:00 PST (…)
X-Robots-Tag может дополнительно указывать пользовательский агент перед
правила. Например, следующий набор X-Robots-Tag HTTP
заголовки могут использоваться для условного разрешения показа страницы в результатах поиска для разных
поисковые системы:
HTTP/1.1 200 ОК Дата: вторник, 25 мая 2010 г., 21:42:43 по Гринвичу (…) X-Robots-Tag: googlebot: nofollow X-Robots-Tag: otherbot: noindex, nofollow (…)
Правила, заданные без пользовательского агента, действительны для всех сканеров. Заголовок HTTP,
имя пользовательского агента, а указанные значения не чувствительны к регистру.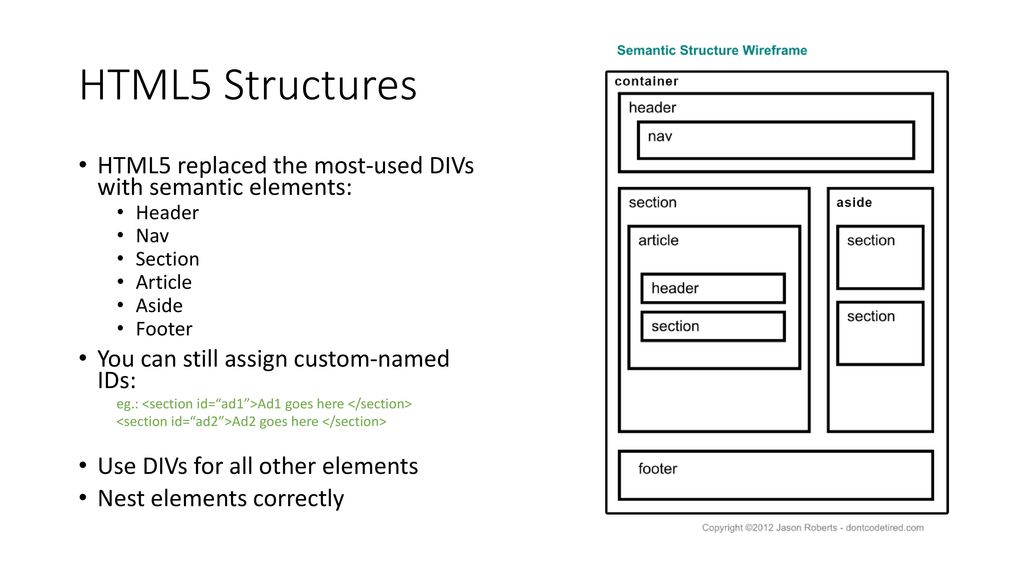
Конфликтующие правила роботов: В случае конфликтующих роботов
правил, применяется более строгое правило. Например, если на странице есть оба max-snippet:50 и nosnippet правила, будет применяться правило nosnippet .
Действительные правила индексации и обслуживания
Следующие правила, также доступные в
машиночитаемый формат, может использоваться для
управлять индексацией и показом сниппета с помощью
роботы метатег и X-Robots-Tag . Каждое значение представляет определенный
правило. Несколько правил могут быть объединены через запятую.
списке или в отдельных мета-тегах . Эти правила нечувствительны к регистру.
| Правила | |
|---|---|
все | Нет никаких ограничений для индексации или обслуживания. Это правило является значением по умолчанию и не имеет никакого эффекта, если явно указан. |
без индекса | Не показывать эту страницу, медиа или ресурс в результатах поиска. Если вы не укажете это правило, страница, медиа или ресурс могут быть проиндексированы и показаны в результатах поиска. Чтобы удалить информацию из Google, следуйте нашим
пошаговое руководство. |
nofollow | Не переходите по ссылкам на этой странице. Если вы не укажете это правило, Google может использовать
ссылки на странице, чтобы обнаружить эти связанные страницы. Узнать больше о nofollow . |
нет | Эквивалентно noindex, nofollow . |
без архива | Не показывать
кешированная ссылка
в результатах поиска. Если вы не укажете это правило, Google может создать кешированную страницу.
и пользователи могут получить к нему доступ через результаты поиска. |
nositelinkssearchbox | Не показывать окно поиска дополнительных ссылок в результатах поиска для этой страницы. Если вы не укажете это правило, Google может создать поле поиска, относящееся к вашему сайту, в результатах поиска вместе с другими прямыми ссылками на ваш сайт. |
нет фрагмента | Не показывать фрагмент текста или предварительный просмотр видео в результатах поиска для этой страницы. А
миниатюра статического изображения (если доступна) может быть видна, когда это приводит к лучшему
Пользовательский опыт. Это относится ко всем формам результатов поиска (в Google: веб-поиск,
Google картинки, Откройте для себя). Если вы не укажете это правило, Google может создать фрагмент текста и видео. предварительный просмотр на основе информации, найденной на странице. |
indexifembedded | Google разрешено индексировать содержимое страницы, если оно встроено в другую страницу.
через |
макс-фрагмент: [число] | Используйте не более [число] символов в текстовом фрагменте для этого результата поиска. Если вы не укажете это правило, Google выберет длину фрагмента. Специальные значения:
Примеры: Чтобы остановить отображение фрагмента в результатах поиска: Чтобы во фрагменте отображалось до 20 символов: Чтобы указать, что нет ограничений на количество символов, которые могут отображаться в фрагмент: |
максимальный предварительный просмотр изображения: [настройка] | Установить максимальный размер предварительного просмотра изображения для этой страницы в результатах поиска. Если вы не укажете правило Принятые значения [настройки]:
Это относится ко всем формам результатов поиска (таким как веб-поиск Google, изображения Google,
Откройте для себя, помощник). Если вы не хотите, чтобы Google использовал большие эскизы изображений на своих AMP-страницах
и каноническая версия статьи отображаются в Поиске или Обнаружении, укажите Пример: |
макс-видео-превью: [номер] | Используйте максимум [число] секунд в качестве фрагмента видео для видео на этой странице в поиске
Результаты. Если вы не укажете правило Специальные значения:
Это относится ко всем формам результатов поиска (в Google: веб-поиск, изображения Google, Google Видео, Discover, Ассистент). Это правило игнорируется, если нет анализируемого [число] указано. Пример: |
без перевода | Не предлагать перевод этой страницы в результатах поиска. Если вы не укажете это
правило, Google может предоставлять
перевод заглавной ссылки и сниппета
результатов поиска для результатов, которые не на языке
поискового запроса. Если пользователь щелкает переведенную ссылку заголовка, все дальнейшие пользовательские
взаимодействие со страницей осуществляется через Google Translate, который будет автоматически переводить
любые ссылки. Если вы не укажете это
правило, Google может предоставлять
перевод заглавной ссылки и сниппета
результатов поиска для результатов, которые не на языке
поискового запроса. Если пользователь щелкает переведенную ссылку заголовка, все дальнейшие пользовательские
взаимодействие со страницей осуществляется через Google Translate, который будет автоматически переводить
любые ссылки. |
индекс индекса изображения | Не индексировать изображения на этой странице. Если не указать это значение, изображения на странице могут быть проиндексированы и показаны в результатах поиска. |
недоступен_после: [дата/время] | Не показывать эту страницу в результатах поиска после указанной даты/времени. Если вы не укажете это правило, эта страница может отображаться в результатах поиска. на неопределенный срок. Робот Googlebot значительно снизит скорость сканирования URL-адреса после указанного Дата и время. Пример: |

 (Примечание
что URL-адрес может отображаться как несколько результатов поиска на странице результатов поиска.) Это
не влияет на предварительный просмотр изображений или видео. Это относится ко всем формам результатов поиска
(например, веб-поиск Google, Google Images, Discover, Assistant). Однако этот предел
не применяется в случаях, когда издатель отдельно предоставил разрешение на использование
содержание. Например, если издатель предоставляет контент в виде встроенных
структурированные данные или имеет лицензионное соглашение с Google, этот параметр не прерывает
более конкретное разрешенное использование. Это правило игнорируется, если нет анализируемого [число]
указано.
(Примечание
что URL-адрес может отображаться как несколько результатов поиска на странице результатов поиска.) Это
не влияет на предварительный просмотр изображений или видео. Это относится ко всем формам результатов поиска
(например, веб-поиск Google, Google Images, Discover, Assistant). Однако этот предел
не применяется в случаях, когда издатель отдельно предоставил разрешение на использование
содержание. Например, если издатель предоставляет контент в виде встроенных
структурированные данные или имеет лицензионное соглашение с Google, этот параметр не прерывает
более конкретное разрешенное использование. Это правило игнорируется, если нет анализируемого [число]
указано. Эквивалентно
Эквивалентно 
 Однако это ограничение не применяется в случаях, когда издатель
отдельно предоставленное разрешение на использование контента. Например, если издатель
предоставляет контент в виде структурированных данных на странице (таких как AMP и канонические
версии статьи) или имеет лицензионное соглашение с Google, этот параметр не будет
прерывать эти более конкретные разрешенные виды использования.
Однако это ограничение не применяется в случаях, когда издатель
отдельно предоставленное разрешение на использование контента. Например, если издатель
предоставляет контент в виде структурированных данных на странице (таких как AMP и канонические
версии статьи) или имеет лицензионное соглашение с Google, этот параметр не будет
прерывать эти более конкретные разрешенные виды использования.
 Дата/время
должны быть указаны в общепринятом формате, включая, но не ограничиваясь
RFC 822,
RFC 850 и
ИСО 8601.
Правило игнорируется, если не указаны допустимые дата/время. По умолчанию нет
срок годности контента.
Дата/время
должны быть указаны в общепринятом формате, включая, но не ограничиваясь
RFC 822,
RFC 850 и
ИСО 8601.
Правило игнорируется, если не указаны допустимые дата/время. По умолчанию нет
срок годности контента.Обработка комбинированных правил индексации и обслуживания
Вы можете создать инструкцию с несколькими правилами, объединив роботов мета правила тегов с запятыми или с использованием нескольких мета-тегов . Вот пример метатега robots
Вот пример метатега robots , который предписывает поисковым роботам не индексировать
страницу и не сканировать ни одну из ссылок на странице:
Список, разделенный запятыми
Несколько
метатегов Вот пример, который ограничивает текстовый фрагмент до 20 символов и позволяет использовать большое изображение. предварительный просмотр:
В ситуациях, когда несколько искателей указаны вместе с разными правилами,
поисковая система будет использовать сумму отрицательных правил. Например:
Страница, содержащая эти метатега , будет интерпретироваться как имеющая правило noindex, nofollow при сканировании роботом Googlebot.
Использование HTML-атрибута
data-nosnippet Вы можете определить текстовые части HTML-страницы, которые не будут использоваться в качестве фрагмента. Это можно сделать
на уровне HTML-элемента с HTML-атрибутом data-nosnippet на диапазон , раздел и раздел элементов. data-nosnippet считается
логический атрибут.
Как и для всех логических атрибутов, любое указанное значение игнорируется. Чтобы обеспечить машиночитаемость,
раздел HTML должен быть действительным HTML, и все соответствующие теги должны быть соответствующим образом закрыты.
Примеры:
Этот текст можно отобразить во фрагменте и эта часть не будет отображаться.
не во фрагментетоже не во фрагментетоже не во фрагментекакой-то тексткакой-то текст Google обычно отображает страницы для их индексации, однако обработка не гарантируется.
Из-за этого извлечение
data-nosnippetможет произойти как до и после рендеринга. Во избежание неопределенности при рендеринге не добавляйте и не удаляйтеатрибут data-nosnippetсуществующих узлов через JavaScript. При добавлении элементов DOM через JavaScript включитеатрибут data-nosnippetпо мере необходимости при первоначальном добавлении элемент в DOM страницы. Если используются пользовательские элементы, оберните их или визуализируйте с помощьюраздел,интервалилиразделэлементов, если вам нужно использоватьdata-nosnippet.Использование структурированных данных
Метатеги Robots
регулируют объем контента, который Google автоматически извлекает из Интернета.мета тегограничения не влияют на использование этих структурированных данных, за исключениемартикул.описаниеи т.д.описаниезначения для структурированных данных, указанных для других творческие работы. Чтобы указать максимальную продолжительность предварительного просмотра на основе этихописаниезначения, используйте Правилоmax-snippet. Например,рецептструктурированные данные на странице подходят для включения в карусель рецептов, даже если в противном случае предварительный просмотр текста был бы ограничен.max-snippet, но этот тег robotsmetaне применяется, когда информация предоставляется с использованием структурированных данных для расширенных результатов.Чтобы управлять использованием структурированных данных для ваших веб-страниц, измените типы структурированных данных и сами значения, добавляя или удаляя информацию, чтобы предоставить только те данные, которые вам нужны сделать доступным. Также обратите внимание, что структурированные данные остаются пригодными для использования в результатах поиска, когда объявлено в
data-nosnippetэлемент.Практическая реализация
X-Robots-TagВы можете добавить
X-Robots-Tagв HTTP-ответы сайта через файлы конфигурации программного обеспечения веб-сервера вашего сайта.X-Robots-Tagс ответами HTTP заключается в том, что вы можете указать сканирование правила, которые применяются глобально на сайте. Поддержка регулярных выражений позволяет высокий уровень гибкости.Например, чтобы добавить noindex
, nofollowX-Robots-Tagв ответ HTTP для всехфайлов .PDFв весь сайт, добавьте следующий фрагмент в корневой файл сайта.htaccessили файлhttpd.confна Apache или файл.confсайта на NGINX.Апач
<Файлы ~ "\.pdf$"> Набор заголовков X-Robots-Tag "noindex, nofollow"НГИНКС
расположение ~* \.Вы можете использовать
X-Robots-Tagдля файлов, отличных от HTML, таких как файлы изображений. где использование тегов robotsmetaв HTML невозможно. Вот пример добавленияnoindexX-Robots-Tagправило для файлы изображений (.png,.jpeg,.jpg,.gif) по всему сайту:Апач
<Файлы ~ "\.(png|jpe?g|gif)$"> Набор заголовков X-Robots-Tag "noindex"НГИНКС
расположение ~* \.(png|jpe?g|gif)$ { add_header X-Robots-Tag "noindex"; }Вы также можете установить заголовки
X-Robots-Tagдля отдельных статических файлов:Апач
# файл htaccess должен быть помещен в каталог соответствующего файла.