Проверка файла robots.txt | REG.RU
Файл robots.txt — это инструкция для поисковых роботов. В ней указывается, какие разделы и страницы сайта могут посещать роботы, а какие должны пропускать. В фокусе этой статьи — проверка robots.txt. Мы рассмотрим советы по созданию файла для начинающих веб-разработчиков, а также разберем, как делать анализ robots.txt с помощью стандартных инструментов Яндекс и Google.
Зачем нужен robots.txt
Поисковые роботы — это программы, которые сканируют содержимое сайтов и заносят их в базы поисковиков Яндекс, Google и других систем. Этот процесс называется индексацией.
robots.txt содержит информацию о том, какие разделы нельзя посещать поисковым роботам. Это нужно для того, чтобы в выдачу не попадало лишнее: служебные и временные файлы, формы авторизации и т. п. В поисковой выдаче должен быть только уникальный контент и элементы, необходимые для корректного отображения страниц (изображения, CSS- и JS-код).
Если на сайте нет robots. txt, роботы заходят на каждую страницу. Это занимает много времени и уменьшает шанс того, что все нужные страницы будут проиндексированы корректно.
txt, роботы заходят на каждую страницу. Это занимает много времени и уменьшает шанс того, что все нужные страницы будут проиндексированы корректно.
Если же файл есть в корневой папке сайта на хостинге, роботы сначала обращаются к прописанным в нём правилам. Они узнают, куда нельзя заходить, а какие страницы/разделы обязательно нужно посетить. И только после этого начинают обход сайта по инструкции.
Веб-разработчикам следует создать файл, если его нет, и наполнить его правильными директивами (командами) для поисковых роботов. Ниже кратко рассмотрим основные директивы для robots.txt.
Основные директивы robots.txt
Структура файла robots.txt выглядит так:
- Директива User-agent. Обозначает, для каких поисковых роботов предназначены правила в документе. Здесь можно указать все поисковые системы (для этого используется символ «*») или конкретных роботов (Yandex, Googlebot и другие).
- Директива Disallow (запрет индексации). Указывает, какие разделы не должны сканировать роботы.
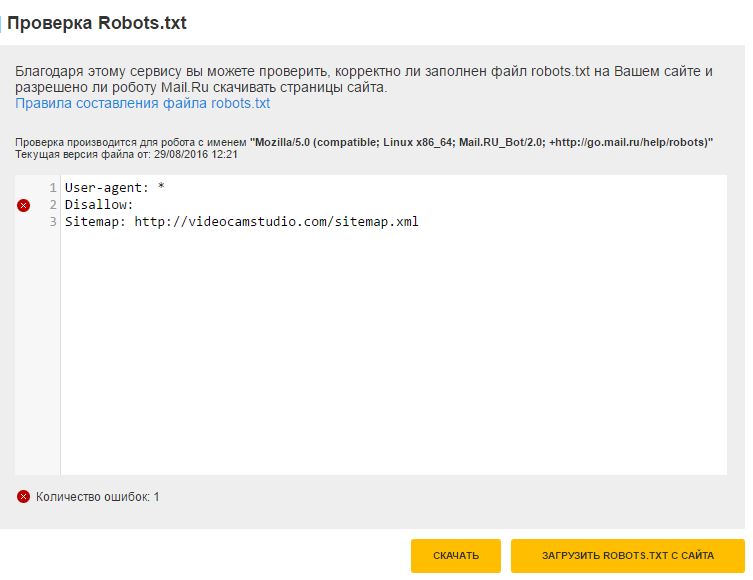 Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.
Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами. - Директива Allow (разрешение). Указывает, какие разделы или файлы должны просканировать поисковые роботы. Здесь не нужно указывать все разделы сайта: все, что не запрещено к обходу, индексируется автоматически. Поэтому следует задавать только исключения из правила Disallow.
- Sitemap (карта сайта). Полная ссылка на файл в формате .xml. Sitemap содержит список всех страниц, доступных для индексации, а также время и частоту их обновления.
Пример простого файла robots.txt (после # указаны пояснительные комментарии к директивам):
User-agent: * # правила ниже предназначены для всех поисковых роботов Disallow: /wp-admin # запрет индексации служебной папки со всеми вложениями Disallow: /*? # запрет индексации результатов поиска на сайте Allow: /wp-admin/admin-ajax.php # разрешение индексации JS-скрипты темы WordPress Allow: /*.jpg # разрешение индексации всех файлов формата .jpg Sitemap: http://site.ru/sitemap.xml # адрес карты сайта, где вместо site.ru — домен сайта
Советы по созданию robots.txt
Для того чтобы файл читался поисковыми программами корректно, он должен быть составлен по определенным правилам. Даже детали (регистр, абзацы, написание) играют важную роль. Рассмотрим несколько основных советов по оформлению текстового документа.
Группируйте директивы
Если требуется задать различные правила для отдельных поисковых роботов, в файле нужно сделать несколько блоков (групп) с правилами и разделить их пустой строкой. Это необходимо, чтобы не возникало путаницы и каждому роботу не нужно было сканировать весь документ в поисках подходящих инструкций. Если правила сгруппированы и разделены пустой строкой, робот находит нужную строку User-agent и следует директивам. Пример:
User-agent: Yandex # правила только для ПС Яндекс Disallow: # раздел, файл или формат файлов Allow: # раздел, файл или формат файлов # пустая строка User-agent: Googlebot # правила только для ПС Google Disallow: # раздел, файл или формат файлов Allow: # раздел, файл или формат файлов Sitemap: # адрес файла
Учитывайте регистр в названии файла
Для некоторых поисковых систем не имеет значение, какими буквами (прописными или строчными) будет обозначено название файла robots. txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
Не указывайте несколько каталогов в одной директиве
Для каждого раздела/файла нужно указывать отдельную директиву Disallow. Это значит, что нельзя писать Disallow: /cgi-bin/ /authors/ /css/ (указаны три папки в одной строке). Для каждой нужно прописывать свою директиву Disallow:
Disallow: /cgi-bin/ Disallow: /authors/ Disallow: /css/
Убирайте лишние директивы
Часть директив robots.txt считается устаревшими и необязательными: Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующегося контента). Вы можете удалить эти директивы, чтобы не «засорять» файл.
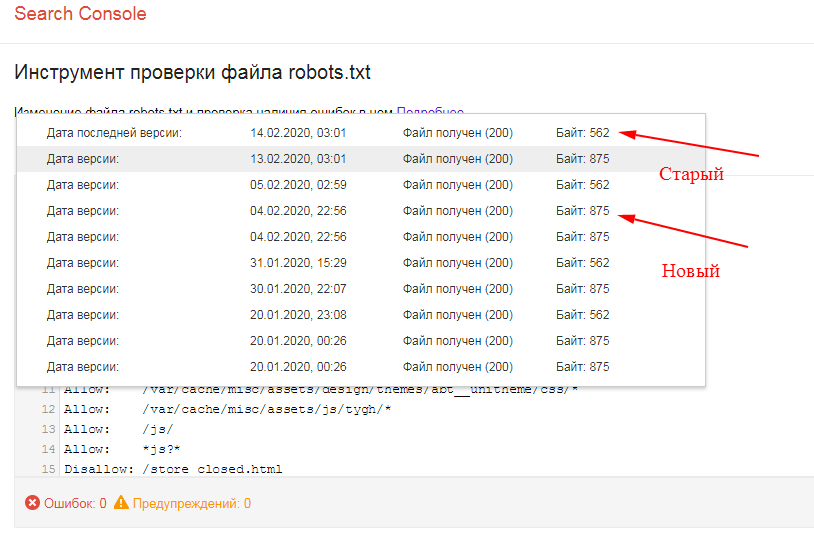
Как проверить robots.txt онлайн
Чтобы убедиться в том, что файл составлен грамотно, можно использовать веб-инструменты Яндекс, Google или онлайн-сервисы (PR-CY, Website Planet и т. п.). В Яндекс и Google есть собственные правила для проверки robots.
Яндекс.Вебмастер
Если вы впервые пользуетесь сервисом Яндекс.Вебмастер, сначала добавьте свой сайт и подтвердите права на него. После этого вы получите доступ к инструментам для анализа SEO-показателей сайта и продвижения в ПС Яндекс.
Чтобы проверить robots.txt с помощью валидатора Яндекс:
- 1.
Зайдите в личный кабинет Яндекс.Вебмастер.
Выберите в левом меню раздел Инструменты → Анализ robots.txt.
- 3.
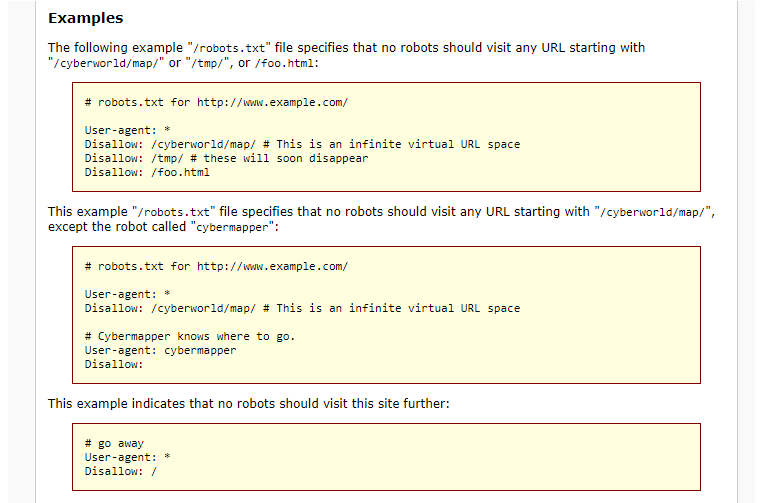
Содержимое нужного файла подставиться автоматически. Если по какой-то причине этого не произошло, скопируйте код, вставьте его в поле и нажмите Проверить:
 org/HowToStep»>
4.
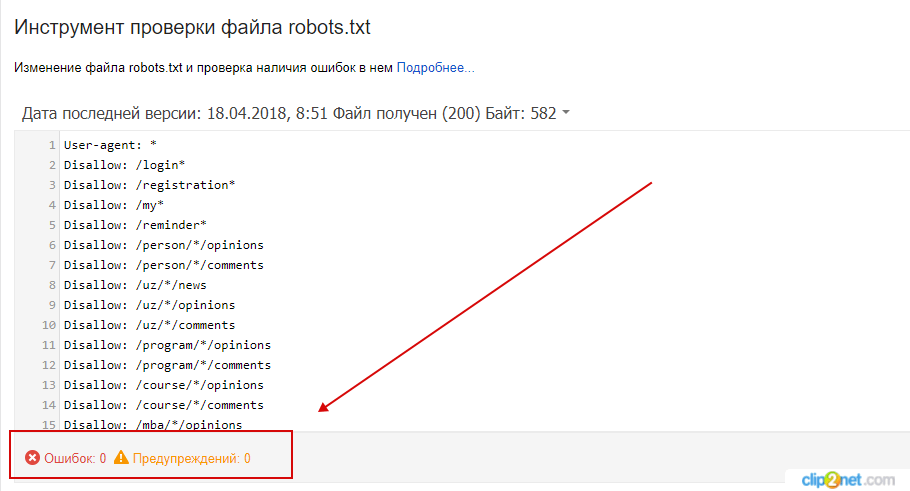
org/HowToStep»>
4.Ниже будут указаны результаты проверки. Если в директивах есть ошибки, сервис покажет, какую строку нужно поправить, и опишет проблему:
Google Search Console
Чтобы сделать проверку с помощью Google:
- 1.
Перейдите на страницу инструмента проверки.
- 2.
Если на открывшейся странице отображается неактуальная версия robots.txt, нажмите кнопку Отправить и следуйте инструкциям Google:
- 3.
Через несколько минут вы можете обновить страницу. В поле будут отображаться актуальные директивы. Предупреждения/ошибки (если система найдет их) будут перечислены под кодом.
Проверка robots.txt Google не выявила ошибок
Обратите внимание: правки, которые вы вносите в сервисе проверки, не будут автоматически применяться в robots. txt. Вам нужно внести исправленный код вручную на хостинге или в административной панели CMS и сохранить изменения.
txt. Вам нужно внести исправленный код вручную на хостинге или в административной панели CMS и сохранить изменения.
Помогла ли вам статья?
Да
2 раза уже помогла
Расшифровка файла robots.txt — База знаний uCoz
В данной статье мы рассмотрим материал: Расшифровка файла Robots.txt для uCoz и uWeb, в котором подробно рассмотрим какая директива и для чего предназначена и как можно улучшить роботс и что можно удалить.
На данный момент в uCoz и uWeb robots.txt настроен так, чтобы запретить к индексации лишь необходимые страницы, точнее системные ненужные и страницы дубли, которые не должны отображаться в поиске. Соответственно, все остальное доступно к индексации, так как что не запрещено значит разрешено, хотя для робота Google нет слова запрещено с временем вы это поймете.
Отметим, если вы не понимаете зачем создан системный файл роботс и для чего в нем приписаны и запреты и разрешения, удалять не обдумав ничего нельзя и устанавливать сторонний роботс, который вы нашли в сети интернет, который не предназначен для Юкоз так же не нужно.
Если вы необдуманно удалите системный и установите сторонний роботс, на таких сайтах с временем в поиске появляются тысячи системных страниц, которые там не должны быть, которые вредят посещаемости сайта.
Как выглядит системный файл Robots.txt ?
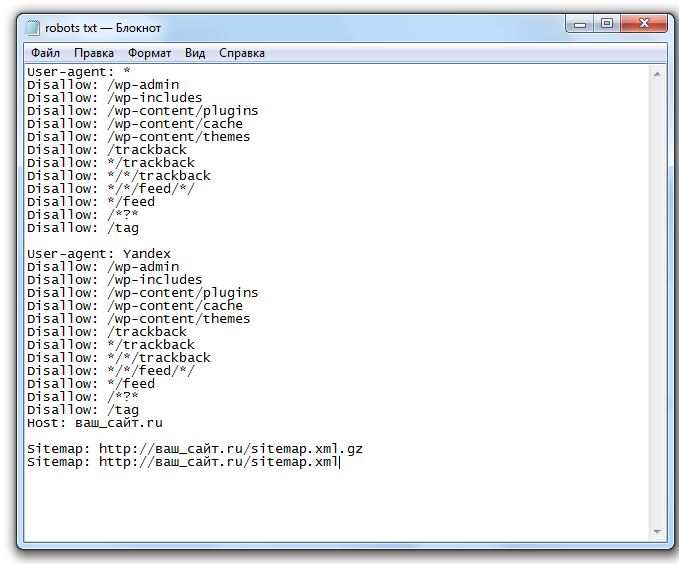
User-agent: * Allow: /*.js Allow: /*.css Allow: /*.jpg Allow: /*.png Allow: /*.gif Allow: /*?page Allow: /*?ref= Disallow: /*? Disallow: /stat/ Disallow: /index/1 Disallow: /index/3 Disallow: /register Disallow: /index/5 Disallow: /index/7 Disallow: /index/8 Disallow: /index/9 Disallow: /index/sub/ Disallow: /panel/ Disallow: /admin/ Disallow: /informer/ Disallow: /secure/ Disallow: /poll/ Disallow: /search/ Disallow: /abnl/ Disallow: /*_escaped_fragment_= Disallow: /*-*-*-*-987$ Disallow: /shop/order/ Disallow: /shop/printorder/ Disallow: /shop/checkout/ Disallow: /shop/user/ Disallow: /shop/search Disallow: /*0-*-0-17$ Disallow: /*-0-0- Sitemap: http://sitename.ucoz.ru/sitemap.xml Sitemap: http://sitename.ucoz.ru/sitemap-forum.xml

Расшифровка Robots.txt
Описание каждой строки файла robots.txt для uCoz и uWeb:
User-agent: *
общее обращение ко всем сканерам, читающим файл robots.txt
Allow: /*.js
Allow: /*.css
Allow: /*.jpg
Allow: /*.png
Allow: /*.gif
Эти директивы разрешают индексирование скриптов, картинок, файлов стилей. нужны они для избежания ошибок заблокированные ресурсы на проверках эмуляторов
Allow: /*?page
Разрешение страниц пагинации на главных страницах модулей (связанно со строчкой Disallow: /*? )
Allow: /*?ref=
Нужна для правильной переиндексации компонентов социальной регистрации
Disallow: /*?
Запрет к индексации поисковых запросов, кода безопасности на uCoz, проксированных ссылок, компонентов рекламного баннера, дублей главной страницы и блога (компоненты кода системы, связанные с сессиями ssid), дубли ссылок на изображения в фотоальбомах, других мусорных компонентов системы
Disallow: /stat/
Запрет индексации компонента счетчика статистики (картинка с данными)
Disallow: /index/1
Техническая страница входа / авторизации
Disallow: /index/3
Запрет индексации страницы регистрации (локальная регистрация)
Disallow: /register
Запрет индексации страницы регистрации (социальная и uID регистрация)
Disallow: /index/5
Запрет к индексации аякс окна напоминания пароля в старой форме входа
Disallow: /index/7
Служебная страница выбора аватара из коллекции
Disallow: /index/8
Запрет к индексации профилей пользователей (один из способов защиты от спама)
Disallow: /index/9
Запрет индексации аякс окна Доступ запрещен
Disallow: /index/sub/
Запрет к индексации локальной авторизации (связано со старой формой входа)
Disallow: /panel/
Запрет к индексации входа в панель управления
Disallow: /admin/
Запрет к индексации входа в панель управления
Disallow: /informer/
Запрет к индексации информеров, вставленных скриптом (при этом содержимое информеров, вставленных системным кодом $MYINF_х$ будет индексироваться свободно)
Disallow: /secure/
Запрет на индексацию кода безопасности (связано со строчкой Disallow: /*?)
Disallow: /poll/
Запрет индексации служебной папки опросов
Disallow: /search/
Запрет индексации страницы поиска, тегов и поисковых запросов (связано со строчкой Disallow: /*?)
Disallow: /abnl/
Запрет индексации компонентов системного рекламного баннера (для сайтов с не отключенной рекламой)
Disallow: /*_escaped_fragment_=
Запрет технического компонента кода
Disallow: /*-*-*-*-987$
Запрет дублей страниц в модулях Новости и Блог, связанных с кодом комментариев на странице
Disallow: /shop/checkout/
Запрет к индексации корзины и кода оформления заказа для Интернет магазина
Disallow: /shop/user/
Запрет к индексации пользователей магазина (субагенты)
Disallow: /*0-*-0-17$
Запрет к индексации различных фильтров, страниц материалов пользователя, ссылки на последнее сообщение форума, дублей системы и т.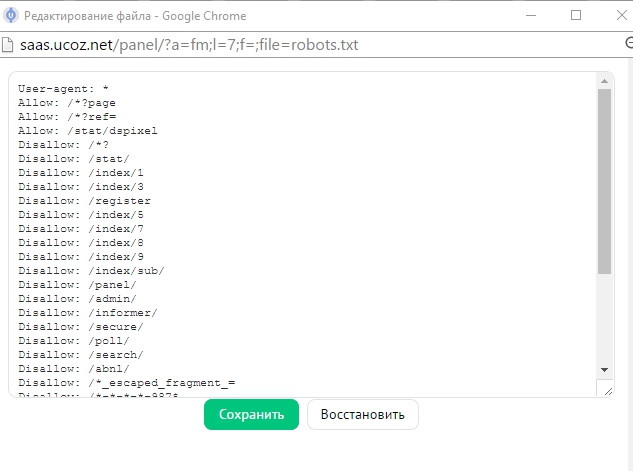 д
д
Disallow: /*-0-0-
Запрет к индексации страниц добавления материалов, списков материалов пользователей, ленточного варианта форума (некоторые дублирующие URL), страниц со списком пользователей (некоторые дублирующие URL), поиска по форуму, правил форума, добавления тем на форуме, различные фильтры (с дублями), страницы с редиректами на залитые на сервер файлы
Sitemap: //адрес сайта/sitemap.xml
Общая карта сайта
Sitemap: //адрес сайта/sitemap-forum.xml
Карта форума (оставлять в файле, если активирован модуль форум)
Sitemap: //адрес сайта/sitemap-shop.xml
Карта магазина (прописывать только, если активирован модуль Интернет магазин)
Host: адрес сайта без https://
Прописывать, если прикреплен домен для определения главного зеркала. директива прописывается в любом месте robots, предназначена для Яндекса, при этом отдельное обращение к роботам Яндекса не нужно. Google игнорируется. На данный момент директива Host Яндексом перестала учитываться и прописывать её не надо.
Google игнорируется. На данный момент директива Host Яндексом перестала учитываться и прописывать её не надо.
От чего можно избавиться в файле Robots.txt ?
Если вы не используете модуль Интернет-магазин, с файла роботс можно удалить следующие директивы:
Disallow: /shop/order/ Disallow: /shop/printorder/ Disallow: /shop/checkout/ Disallow: /shop/user/ Disallow: /shop/search Sitemap: //адрес сайта/sitemap-shop.xml
Если вы не используете модуль Форум, можно удалить карту сайта для форума:
Sitemap: //адрес сайта/sitemap-forum.xml
Что можно добавить, чтобы улучшить файл Robots.txt ?
Можно добавить в самом начале файла роботс перед всем содержимым директиву с доступом для мобильного робота гугла:
User-agent:Googlebot-Mobile Allow: /
это позволит мобильному роботу без проблем сканировать ваш сайт.
С наших рекомендаций, после директив с доступом индексировать изображения сайта, стоит и добавить доступ к индексации шрифтов на сайте, чтобы роботы имели полный доступ к сайту и корректно его видели с шрифтами, которые на сайте подключены.
В роботс стоит добавить директивы:
Allow: /*.ttf Allow: /*.woff Allow: /*.woff2 Allow: /*.eot Allow: /*.svg
это существенно улучшит отображение вашего сайта для поисковиков и они будут корректно видеть сайт с вашими шрифтами.
В дополнение, было замечено по отчетам с индексации яндекса, что робот посещает страницу регистрации и находит сгенерированные урл подобно /confirm/ и индексирует их. Для решения данной проблемы рекомендую в роботс добавить директиву:
Disallow: /confirm/
это сохранит ваш сайт от индексации мусора.
Для борьбы с дублями в модуле Интернет-магазин, в роботс можно добавить такие директы:
Disallow: /shop/*comm Disallow: /shop/*spec Disallow: /shop/*imgs Disallow: /shop/all/ Disallow: /shop/*;
эти директивы закроют от индексации подстраницы модуля магазин, которые не несут пользы в поиске и страницы переключателей страниц в модуле магазин.
На данном этапе мы закончим материал, если будут обновления, мы их добавим в статью.
Robots.txt Руководство по передовой практике + примеры
Файл robots.txt часто упускают из виду, а иногда забывают о части веб-сайта и SEO.
Тем не менее, файл robots.txt является важной частью любого набора инструментов SEO, независимо от того, являетесь ли вы новичком в отрасли или опытным ветераном SEO.
Что такое файл robots.txt?
Файл robots.txt можно использовать для самых разных целей: от информирования поисковых систем, куда идти, чтобы найти карту сайта вашего сайта, до указания им, какие страницы сканировать, а какие нет, а также в качестве отличного инструмента для управления вашим сайтом. краулинговый бюджет сайтов.
Вы можете спросить себя: « подождите минутку, что такое краулинговый бюджет? ”Сканирующий бюджет — это то, что Google использует для эффективного сканирования и индексации страниц вашего сайта. Каким бы большим ни был Google, у них по-прежнему есть только ограниченное количество ресурсов, доступных для сканирования и индексации контента ваших сайтов.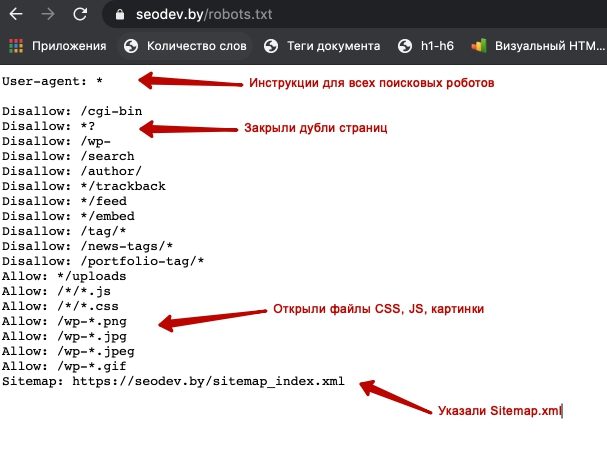
Если на вашем сайте всего несколько сотен URL-адресов, Google сможет легко сканировать и индексировать страницы вашего сайта.
Однако, если ваш сайт большой, например, сайт электронной коммерции, и у вас есть тысячи страниц с большим количеством автоматически сгенерированных URL-адресов, Google может не просканировать все эти страницы, и вы потеряете много потенциального трафика и видимость.
Здесь важно расставить приоритеты, что, когда и сколько сканировать.
Google заявил, что « наличие большого количества URL-адресов с низкой добавленной стоимостью может негативно повлиять на сканирование и индексирование сайта. » Здесь файл robots.txt может помочь с факторами, влияющими на бюджет сканирования вашего сайта.
Вы можете использовать этот файл для управления бюджетом сканирования вашего сайта, следя за тем, чтобы поисковые системы тратили свое время на ваш сайт максимально эффективно (особенно если у вас большой сайт) и сканировали только важные страницы и не тратили впустую время на таких страницах, как вход, регистрация или страницы благодарности.
Прежде чем робот, такой как Googlebot, Bingbot и т. д., просканирует веб-страницу, он сначала проверит, существует ли на самом деле файл robots.txt, и, если он существует, они обычно будут следовать и соблюдать указания, указанные в нем. этот файл.
Файл robots.txt может быть мощным инструментом в арсенале любого SEO-специалиста, поскольку это отличный способ контролировать, как сканеры/боты поисковых систем получают доступ к определенным областям вашего сайта. Имейте в виду, что вы должны быть уверены, что понимаете, как работает файл robots.txt, иначе вы случайно запретите Googlebot или любому другому боту сканировать весь ваш сайт, и он не будет найден в результатах поиска!
Ресурсы
Но если все сделано правильно, вы можете контролировать такие вещи, как:
- Блокирование доступа ко всем разделам вашего сайта (среда разработки и промежуточной среды и т. д.)
- Предотвращение сканирования, индексации или отображения страниц результатов внутреннего поиска вашего сайта в результатах поиска.

- Указание местоположения вашей карты сайта или карт сайта
- Оптимизация краулингового бюджета путем блокировки доступа к страницам с низкой ценностью (вход в систему, спасибо, корзины покупок и т. д.)
- Предотвращение индексации определенных файлов на вашем веб-сайте (изображений, PDF-файлов и т. д.)
Ниже приведены несколько примеров того, как вы можете использовать файл robots.txt на своем сайте.
Разрешение всем веб-краулерам/роботам доступа ко всему содержимому ваших сайтов:
User-agent: * Disallow:
Блокировка всех поисковых роботов/роботов на всех ваших сайтах:
User-agent: * Disallow: /
Вы можете видеть, как легко сделать ошибку при создании ваших сайтов robots.txt, поскольку отличие от блокировки всего вашего сайта от просмотра заключается в простой косой черте в директиве запрета (Disallow: /).
Блокировка определенных веб-сканеров/ботов из определенной папки:
Агент пользователя: Googlebot Disallow: /
Блокировка поисковых роботов/роботов на определенной странице вашего сайта:
User-agent: Disallow: /thankyou.html
Исключить всех роботов из части сервера:
User-agent: * Запретить: /cgi-bin/ Запретить: /tmp/ Disallow: /junk/
Вот пример того, как выглядит файл robots.txt на сайте theverge.com:
Пример файла можно посмотреть здесь: www.theverge.com/robots.txt
Вы можете увидеть, как The Verge использует свой файл robots.txt, чтобы специально вызвать новостного бота Google «Googlebot-News», чтобы убедиться, что он не сканирует эти каталоги на сайте.
Важно помнить, что если вы хотите убедиться, что бот не сканирует определенные страницы или каталоги на вашем сайте, вы должны указать эти страницы и / или каталоги в объявлениях «Запретить» в файле robots.txt. , как в приведенных выше примерах.
Вы можете просмотреть, как Google обрабатывает файл robots.txt в своем руководстве по спецификациям robots.txt, у Google есть текущий предел максимального размера файла robots.txt, максимальный размер для Google установлен на уровне 500 КБ, поэтому важно помните о размере файла robots.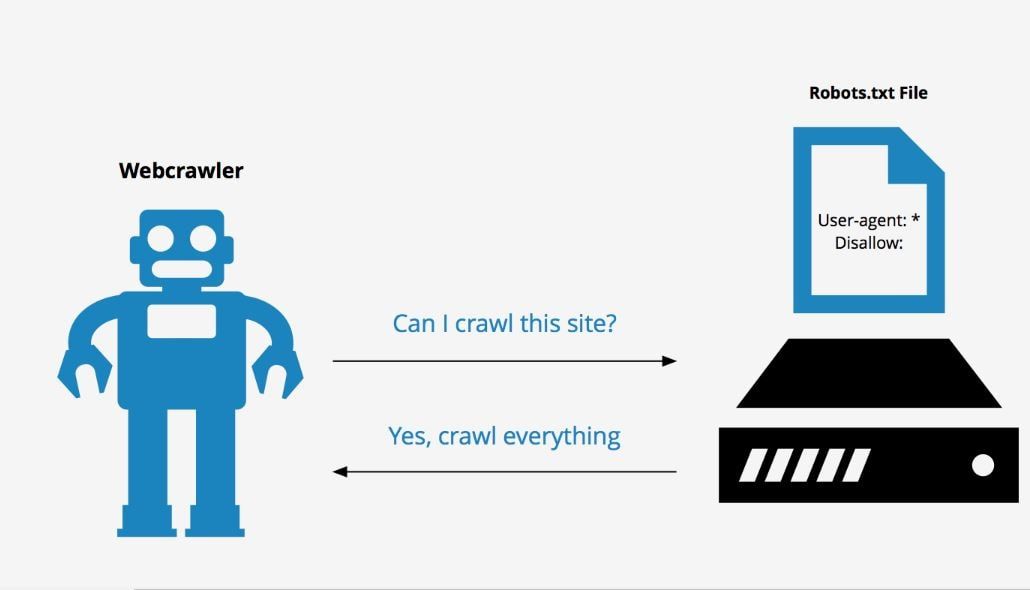 txt вашего сайта.
txt вашего сайта.
Создание файла robots.txt для вашего сайта — довольно простой процесс, но в нем легко ошибиться. Не позволяйте этому отговорить вас от создания или изменения файла robots для вашего сайта. Эта статья от Google проведет вас через процесс создания файла robots.txt и должна помочь вам научиться создавать собственный файл robots.txt.
Когда вы освоитесь с созданием или изменением файла robots вашего сайта, у Google есть еще одна замечательная статья, в которой объясняется, как проверить файл robots.txt вашего сайта, чтобы убедиться, что он настроен правильно.
Проверка наличия файла robots.txt Если вы не знакомы с файлом robots.txt или не уверены, есть ли он на вашем сайте, вы можете быстро проверить его. Все, что вам нужно сделать, чтобы проверить, это перейти в корневой домен вашего сайта, а затем добавить /robots.txt в конец URL-адреса. Пример: www.yoursite.com/robots. txt
txt
Если ничего не отображается, значит у вас нет файла robots.txt для вашего сайта. Сейчас самое подходящее время, чтобы приступить к работе и попробовать создать его для своего сайта.
Передовой опыт:- Убедитесь, что все важные страницы доступны для сканирования, а контент, который не представляет реальной ценности в случае обнаружения в поиске, заблокирован.
- Не блокируйте файлы JavaScript и CSS на своих сайтах
- Всегда выполняйте быструю проверку файла, чтобы убедиться, что ничего не изменилось случайно
- Правильное использование заглавных букв в именах каталогов, подкаталогов и файлов
- Поместите файл robots.txt в корневой каталог вашего веб-сайта, чтобы его можно было найти
- Файл robots.txt чувствителен к регистру, файл должен называться «robots.txt» (без других вариантов)
- Не используйте файл robots.txt, чтобы скрыть личную информацию о пользователе, так как она все равно будет видна
- Добавьте местоположение карты сайта в файл robots.
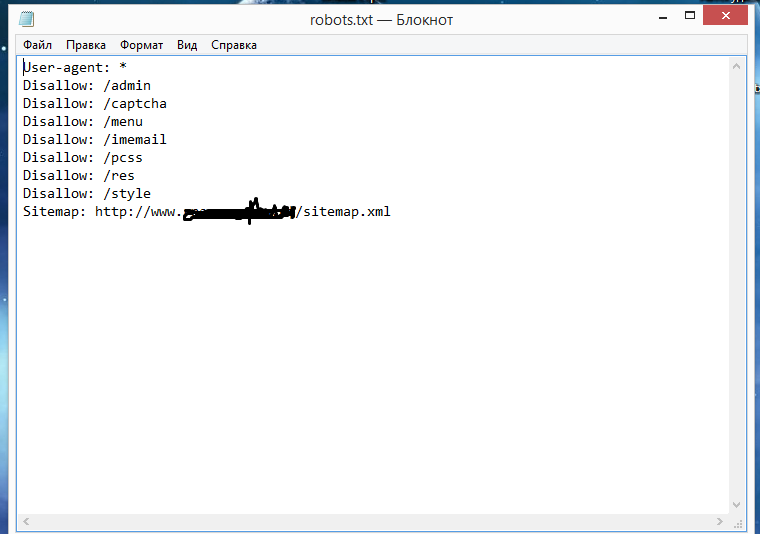 txt.
txt. - Убедитесь, что вы не блокируете какой-либо контент или разделы вашего веб-сайта, которые вы хотите просканировать.
Если на вашем сайте есть субдомен или несколько субдоменов , вам потребуется файл robots.txt для каждого субдомена, а также для основного корня. домен. Это будет выглядеть примерно так: store.yoursite.com/robots.txt, и yoursite.com/robots.txt.
Как упоминалось выше в разделе « лучших практик », важно помнить, что нельзя использовать файл robots.txt для предотвращения сканирования конфиденциальных данных, таких как личная информация пользователя, и их появления в результатах поиска.
Причина этого в том, что возможно, что другие страницы могут ссылаться на эту информацию, и если есть прямая обратная ссылка, она будет обходить правила robots.txt, и этот контент все равно может быть проиндексирован. Если вам нужно заблокировать действительное индексирование ваших страниц в результатах поиска, используйте другой метод, например, добавление защиты паролем или добавление метатега noindex к этим страницам. Google не может войти на защищенный паролем сайт/страницу, поэтому они не смогут сканировать или индексировать эти страницы.
Если вам нужно заблокировать действительное индексирование ваших страниц в результатах поиска, используйте другой метод, например, добавление защиты паролем или добавление метатега noindex к этим страницам. Google не может войти на защищенный паролем сайт/страницу, поэтому они не смогут сканировать или индексировать эти страницы.
Хотя вы можете немного нервничать, если вы никогда раньше не работали с файлом robots.txt, будьте уверены, что он довольно прост в использовании и настройке. Как только вы освоитесь со всеми тонкостями файла robots, вы сможете улучшить SEO своего сайта, а также помочь посетителям вашего сайта и ботам поисковых систем.
Правильно настроив файл robots.txt, вы поможете ботам поисковых систем разумно расходовать краулинговые бюджеты и убедитесь, что они не тратят впустую свое время и ресурсы на сканирование ненужных страниц. Это поможет им наилучшим образом организовать и отобразить контент вашего сайта в поисковой выдаче, что, в свою очередь, означает, что вы будете более заметны.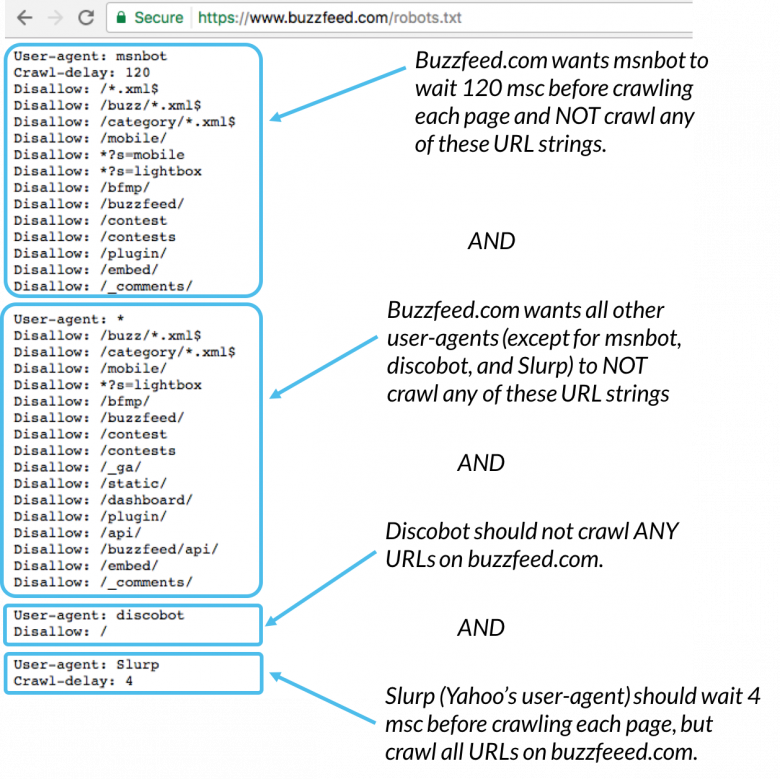
Имейте в виду, что настройка файла robots.txt не обязательно требует много времени и усилий. По большей части это одноразовая настройка, которую вы можете затем внести в нее небольшими настройками и изменениями, чтобы улучшить свой сайт.
Я надеюсь, что методы, советы и предложения, описанные в этой статье, помогут вам обрести уверенность при создании/изменении файла robots.txt вашего сайта и в то же время помогут вам плавно пройти через этот процесс.
Майкл Макманус — руководитель практики Earned Media (SEO) в iProspect.
Что такое файл robots.txt?
Несмотря на то, что SEO-специалисты прилагают большую часть усилий для улучшения видимости страниц по соответствующим ключевым словам, в некоторых случаях требуется скрыть определенные страницы от поисковых систем.
Давайте узнаем немного больше об этой теме.
Содержание
Что такое файл robots.txt?
Robots.txt — это файл, который содержит области веб-сайта, которые роботам поисковых систем запрещено сканировать . В нем перечислены URL-адреса, которые веб-мастер не хочет индексировать в Google или любой другой поисковой системе, что не позволяет им посещать и отслеживать выбранные страницы. Мы выполняем это действие с помощью тега disallow в robots.txt, который вы увидите в примерах ниже.
В нем перечислены URL-адреса, которые веб-мастер не хочет индексировать в Google или любой другой поисковой системе, что не позволяет им посещать и отслеживать выбранные страницы. Мы выполняем это действие с помощью тега disallow в robots.txt, который вы увидите в примерах ниже.
Когда бот находит веб-сайт в Интернете, первое, что он делает, это проверяет файл robots.txt , чтобы узнать, что ему разрешено исследовать, а что он должен игнорировать во время обхода.
Robots.txt пример
Чтобы дать вам пример robots.txt , его синтаксис:
User-agent: *
# Все боты - Старые URL
Разрешить: /
Запретить: /admin/*
Что такое robots.txt в SEO
Эти теги необходимы для того, чтобы роботы Google могли найти новую страницу. Они необходимы, потому что:
- Они помогают оптимизировать краулинговый бюджет , так как паук будет посещать только то, что действительно важно, и будет более эффективно использовать свое время при сканировании страницы.
 Примером страницы, которую вы бы не хотели, чтобы Google нашел, является «страница благодарности».
Примером страницы, которую вы бы не хотели, чтобы Google нашел, является «страница благодарности». - Файл Robots.txt — хороший способ принудительно проиндексировать страницы, указывая страницы.
- Файлы robots.txt контролируют доступ поисковых роботов к определенным областям вашего сайта.
- Они могут обеспечить безопасность целых разделов веб-сайта, поскольку вы можете создавать отдельные файлы robots.txt для каждого корневого домена. Хорошим примером является, как вы уже догадались, страница сведений о платеже, конечно.
- Вы также можете заблокировать отображение страниц результатов внутреннего поиска в поисковой выдаче.
- Robots.txt может скрывать файлы, которые не должны индексироваться, например PDF-файлы или определенные изображения.
Где найти robots.txt
Файлы robots.txt являются общедоступными. Вы можете просто ввести корневой домен и добавить /robots.txt в конец URL-адреса, и вы увидите файл… если он есть!
Предупреждение. Не указывайте личную информацию в этом файле.
Не указывайте личную информацию в этом файле.
Вы можете найти и отредактировать файл в корневом каталоге вашего хостинга, проверив файлы admin или FTP сайта.
Как редактировать robots.txt
Вы можете сделать это самостоятельно
- Создайте или отредактируйте файл с помощью текстового редактора
- Назовите файл robots.txt без каких-либо изменений, например, используя заглавные буквы.
Вот пример, когда вы хотите просканировать сайт. Обратите внимание, как мы используем тег disallow в robots.txt.
Агент пользователя: *
Запретить:
Обратите внимание, что мы оставили «Запретить» пустым, что указывает на то, что нет ничего, что нельзя было бы сканировать.
Если вы хотите заблокировать страницу, добавьте это (на примере «страницы благодарности»):
User-agent: *
Disallow: /thank-you/
- Используйте отдельный файл robots.
 txt для каждого поддомена.
txt для каждого поддомена. - Поместите файл в каталог верхнего уровня веб-сайта.
- Вы можете протестировать файлы robots.txt с помощью инструментов Google для веб-мастеров, прежде чем загружать их в корневой каталог.
- Обратите внимание, что FandangoSEO — это конечная программа проверки robots.txt. Используйте его, чтобы следить за ними!
Посмотрите, не так уж сложно настроить файл robots.txt и отредактировать его в любое время. Просто имейте в виду, что все, что вы хотите от этого действия, — это максимально использовать посещения ботов. Блокируя им просмотр нерелевантных страниц, вы гарантируете, что их время, проведенное на веб-сайте, будет намного более прибыльным.
Наконец, помните, что лучшая практика SEO для robots.txt заключается в том, чтобы убедиться, что весь соответствующий контент индексируется и готов к сканированию! Вы можете увидеть процент индексируемых и неиндексируемых страниц среди общего числа страниц сайта с помощью сканирования FandangoSEO, а также страницы, заблокированные файлом robots. txt.
txt.
Варианты использования файла robots.txt
Файл robots.txt управляет доступом сканера к некоторым областям веб-сайта. Иногда это может быть рискованно, особенно если роботу GoogleBot случайно не разрешено сканировать весь сайт, но бывают ситуации, когда может пригодиться файл robots.txt .
В некоторых случаях рекомендуется использовать robots.txt:
- Если вы хотите сохранить конфиденциальность некоторых разделов веб-сайта , например, потому что это тестовая страница.
- Чтобы избежать появления дублирующегося контента на странице результатов Google, мета-боты являются еще более желательным вариантом.
- Когда вы не хотите, чтобы страницы результатов внутреннего поиска отображались на общедоступной странице результатов .
- Указать расположение карты сайта .
- К запретить поисковым системам индексировать определенные файлы на веб-сайте.

- Для укажите задержку сканирования , чтобы избежать перегрузки сервера, когда сканеры загружают несколько фрагментов контента одновременно.
Если на сайте нет областей, где вы хотите контролировать доступ агента пользователя, вам может не понадобиться файл robots-txt.
Robots.txt SEO Best Practices
Следуйте этим советам, чтобы правильно управлять файлами robots.txt :
Не блокируйте контент, который вы хотите отслеживать
Вы также не должны блокировать разделы веб-сайта, которые необходимо отслеживать .
Имейте в виду, что боты не будут переходить по ссылкам страниц, заблокированных robots.txt
Если они также не связаны с другими страницами, к которым поисковые системы могут получить доступ, поскольку они не были заблокированы, связанные ресурсы не будут сканироваться и нельзя индексировать .
Кроме того, значение ссылки не может быть передано с заблокированной страницы на место назначения ссылки. Если у вас есть страницы, которым вы хотите предоставить права доступа, вы должны использовать механизм блокировки, отличный от robots.txt.
Если у вас есть страницы, которым вы хотите предоставить права доступа, вы должны использовать механизм блокировки, отличный от robots.txt.
Не используйте robots.txt, чтобы избежать показа конфиденциальных данных на странице результатов поисковой системы
Другие страницы могут напрямую ссылаться на страницу, содержащую конфиденциальную информацию (таким образом не соблюдаются правила robots.txt в корневом домене или домашней странице) , поэтому он все еще может быть проиндексирован.
Чтобы страница не отображалась в результатах поиска Google, следует использовать другой метод, например защиту паролем или метатег noindex.
Помните, что некоторые поисковые системы имеют несколько пользовательских агентов
Google, например, использует GoogleBot для обычного поиска и GoogleBot-Image для поиска изображений.
Большинство пользовательских агентов одной и той же поисковой системы следуют одним и тем же правилам, поэтому вам не нужно указывать рекомендации для каждого сканера поисковой системы, но это позволяет вам контролировать, как будет сканироваться содержимое сайта.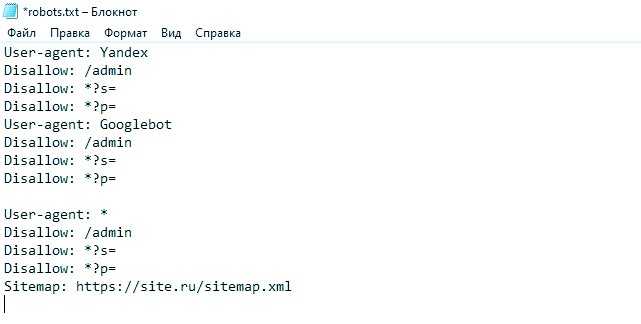
Поисковая система кэширует содержимое robots.txt, но обычно обновляет кэшированные данные ежедневно.
Если вы изменяете файл и хотите обновлять его быстрее, вы можете отправить URL-адрес robots.txt в Google.
Ограничения файла robots.txt
Наконец, мы увидим, какие аспекты ограничивают функцию файла robots.txt:
Страницы будут по-прежнему появляться в результатах поиска
файл robots.txt, но имеющие ссылки на них, могут по-прежнему отображаться в результатах поиска со сканируемой страницы.
Содержит только директивы
Компания Google с большим уважением относится к файлу robots.txt, но это по-прежнему директива, а не предписание.
Размер файла
Google поддерживает ограничение в 521 килобайт для файлов robots.txt, и если содержимое превышает этот максимальный размер, оно может игнорироваться. Мы не знаем, устанавливают ли другие поисковые системы ограничение для этих файлов.
Робот тхт.