Файл robots txt — основные директивы и инструкция по редактированию в Нубексе
Robots.txt — это текстовый файл, который содержит специальные инструкции для роботов-поисковиков, исследующих ваш сайт в интернете. Такие инструкции — они называются директивами — могут запрещать к индексации некоторые страницы сайта, указывать на правильное «зеркалирование» домена и т.д.
Для сайтов, работающих на платформе «Нубекс», файл с директивами создается автоматически и располагается по адресу domen.ru/robots.txt, где domen.ru — доменное имя сайта. Например, с содержанием файла для сайта nubex.ru можно ознакомиться по адресу nubex.ru/robots.txt.
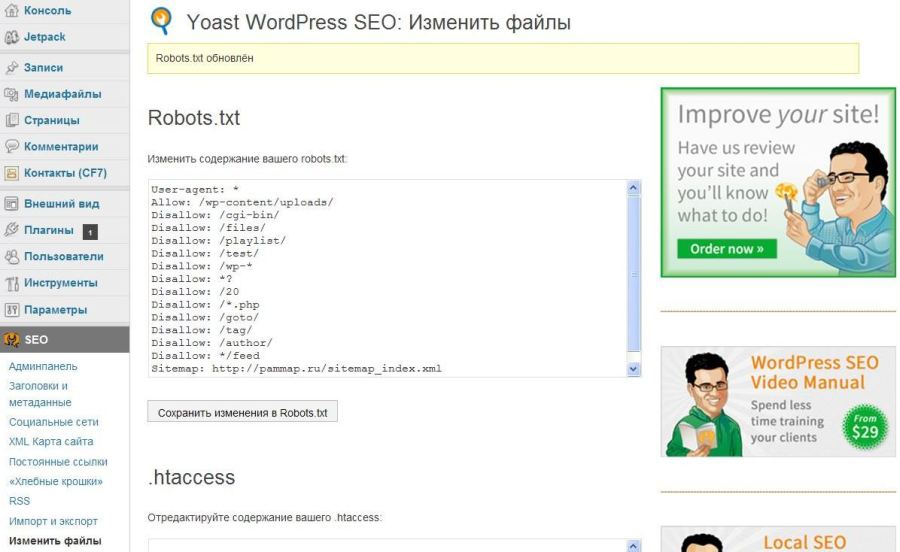
Изменить robots.txt и прописать дополнительные директивы для поисковиков можно в админке сайта. Для этого на панели управления выберите раздел «Настройки», а в нем — пункт «SEO».
Найдите поле «Текст файла robots.txt» и пропишите в нем нужные директивы. Желательно активировать галочку «Добавить в robots.txt ссылку на автоматически генерируемый файл sitemap.xml»: так поисковый бот сможет загрузить карту сайта и найти все необходимые страницы для индексации.
Желательно активировать галочку «Добавить в robots.txt ссылку на автоматически генерируемый файл sitemap.xml»: так поисковый бот сможет загрузить карту сайта и найти все необходимые страницы для индексации.
Не забудьте сохранить страницу после внесения необходимых изменений.
Загружая robots.txt, поисковый робот первым делом ищет запись, начинающуюся с User-agent: значением этого поля должно являться имя робота, которому в этой записи устанавливаются права доступа. Т.е. директива User-agent — это своего рода обращение к роботу.
1. Если в значении поля User-agent указан символ «*», то заданные в этой записи права доступа распространяются на любых поисковых роботов, запросивших файл /robots.txt.
2. Если в записи указано более одного имени робота, то права доступа распространяются для всех указанных имен.
3. Заглавные или строчные символы роли не играют.
4. Если обнаружена строка User-agent: ИмяБота, директивы для User-agent: * не учитываются (это в том случае, если вы делаете несколько записей для различных роботов). Т.е. робот сначала просканирует текст на наличие записи User-agent: МоеИмя, и если найдет, будет следовать этим указаниям; если нет — будет действовать по инструкциям записи User-agent: * (для всех ботов).
Если обнаружена строка User-agent: ИмяБота, директивы для User-agent: * не учитываются (это в том случае, если вы делаете несколько записей для различных роботов). Т.е. робот сначала просканирует текст на наличие записи User-agent: МоеИмя, и если найдет, будет следовать этим указаниям; если нет — будет действовать по инструкциям записи User-agent: * (для всех ботов).
Кстати, перед каждой новой директивой User-agent рекомендуется вставлять пустой перевод строки (Enter).
5. Если строки User-agent: ИмяБота и User-agent: * отсутствуют, считается, что доступ роботу не ограничен.
Запрет и разрешение индексации сайта: директивы Disallow и Allow
Чтобы запретить или разрешить поисковым ботам доступ к определенным страницам сайта, используются директивы Disallow и Allow соответственно.
В значении этих директив указывается полный или частичный путь к разделу:
- Disallow: /admin/ — запрещает индексацию всех страниц, находящихся внутри раздела admin;
- Disallow: /help — запрещает индексацию и /help.
 html, и /help/index.html;
html, и /help/index.html; - Disallow: /help/ — закрывает только /help/index.html;
- Disallow: / — блокирует доступ ко всему сайту.
Если значение Disallow не указано, то доступ не ограничен:
- Disallow: — разрешена индексация всех страниц сайта.
Для настройки исключений можно использовать разрешающую директиву Allow. Например, такая запись запретит роботам индексировать все разделы сайта, кроме тех, путь к которым начинается с /search:
User-agent: *
Allow: /search
Disallow: /
Неважно, в каком порядке будут перечислены директивы запрета и разрешения индексации. При чтении робот все равно рассортирует их по длине префикса URL (от меньшего к большему) и применит последовательно. То есть пример выше в восприятии бота будет выглядеть так:
User-agent: *
Disallow: /
Allow: /search
— разрешено индексировать только страницы, начинающиеся на /search. Таким образом, порядок следования директив никак не повлияет на результат.
Таким образом, порядок следования директив никак не повлияет на результат.
Директива Host: как указать основной домен сайта
Если к вашему сайту привязано несколько доменных имен (технические адреса, зеркала и т.д.), поисковик может решить, что все это — разные сайты. Причем с одинаковым наполнением. Решение? В бан! И одному боту известно, какой из доменов будет «наказан» — основной или технический.
Чтобы избежать этой неприятности, нужно сообщить поисковому роботу, по какому из адресов ваш сайт участвует в поиске. Этот адрес будет обозначен как основной, а остальные сформируют группу зеркал вашего сайта.
Сделать это можно с помощью директивы Host. Ее нужно добавить в запись, начинающуюся с User-Agent, непосредственно после директив Disallow и Allow. В значении директивы Host нужно указать основной домен с номером порта (по умолчанию 80). Например:
User-Agent: *
Disallow:
Host: test-o-la-la.ru
Такая запись означает, что сайт будет отображаться в результатах поиска со ссылкой на домен test-o-la-la. ru, а не www.test-o-la-la.ru и s10364.nubex.ru (см. скриншот выше).
ru, а не www.test-o-la-la.ru и s10364.nubex.ru (см. скриншот выше).
В конструкторе «Нубекс» директива Host добавляется в текст файла robots.txt автоматически, когда вы указываете в админке, какой домен является основным.
В тексте robots.txt директива host может использоваться только единожды. Если вы пропишите ее несколько раз, робот воспримет только первую по порядку запись.
Директива Crawl-delay: как задать интервал загрузки страниц
Чтобы обозначить роботу минимальный интервал между окончанием загрузки одной страницы и началом загрузки следующей, используйте директиву Crawl-delay. Ее нужно добавить в запись, начинающуюся с User-Agent, непосредственно после директив Disallow и Allow. В значении директивы укажите время в секундах.
User-Agent: *
Disallow:
Crawl-delay: 3
Использование такой задержки при обработке страниц будет удобным для перегруженных серверов.
Существуют также и другие директивы для поисковых роботов, но пяти описанных — User-Agent, Disallow, Allow, Host и Crawl-delay — обычно достаточно для составления текста файла robots. txt.
txt.
robots.txt host — директива. Как указать главное зеркало?
Есть официальная документация у поисковиков на тему данной директивы, но к примеру у Google данная директива не задокументирована, но и не считается ошибкой в валидаторе…
Ну что ж приступим…
Яндекс
User-Agent: *
Disallow: /forum
Disallow: /cgi-bin
Host: https://soltyk.ru
Валидатор для проверки в Яндексе
Про главное зеркало:
«Директива Host не гарантирует выбор указанного главного зеркала, тем не менее, алгоритм при принятии решения учитывает ее с высоким приоритетом.»
Примечание. Для каждого файла robots.txt обрабатывается только одна директива Host. Если в файле указано несколько директив, робот использует первую.
Директива Host должна содержать:
- Протокол HTTPS, если зеркало доступно только по защищенному каналу. Если вы используете протокол HTTP, то его указывать необязательно.
- Одно корректное доменное имя, соответствующего RFC 952 и не являющегося IP-адресом.

- Номер порта, если необходимо (Host: myhost.ru:8080).
Некорректно составленные директивы Host игнорируются.
Официальная документация.
Вот как выглядит это в вебмастере (ошибок и предупреждений нет):
Про главное зеркало:
«Директивой можно указать роботу главный сайт, в том случае если вы используете сайты-зеркала. Значением в данной строке выступает доменное имя. Для поддержания формата файла robots.txt директива должна идти внутри записи, начинающейся с User-agent.»
Пример:
User-agent: *
Disallow: # обязательная для каждой записи строка с директивой Disallow
Host: https://soltyk.ru
Официальная документация
Валидатор в вебмастере
Аналогичная проверка (ошибок и предупреждений нет):
А теперь самое интересное…
Есть официальная документация, но в ней ничего не сказано про данную директиву…
Можно выделить 3 основных задокументированных факта:
- Инструкции robots.
 txt носят рекомендательный характер
txt носят рекомендательный характер - Каждый поисковый робот использует собственный алгоритм обработки файла robots.txt
- Страница, заблокированная для поисковых роботов, все же может быть обработана, если на других сайтах есть ссылки на нее
А вот что выдает валидатор в вебмастере Google (смотрим и делаем выводы):
Выводы, предположения и возможная польза…
Так что можно смело предположить при использовании валидатора robots от Google не возникает ни предупреждений, ни ошибок. В 2016 — начало 2017 такая картина еще наблюдалась (помечалось как ошибка). Следовательно, можно предположить, что они решили использовать данную директиву host как рекомендацию. Также проводя тесты на клиентских сайтах при переходе на https (без применения междоменного 301-редиректа), было замечено, как Гугл начинал потихоньку индексировать https версию. И к тому времени, когда Яндекс завершал склейку, в Google-вебмастере было видно, как часть индекса перетекала уже на новый хост.
Конечно это только догадки, основанные на практических тестах. Поэтому я составляю одну общую конфигурацию для всех роботов:
User-agent: *
Поэтому, если у Вас также есть опыт в определении такого стандарта для Google, то можете написать мне или в комментариях ниже.
Следующие страницы вас также могут заинтересовать:
- SEO-консультации по продвижению сайта
- Написание объявлений Avito
- Эксперты об алгоритмах. SEO тренды будущего
- Комплекс платных каналов: начни тотальную охоту на клиентов
- Средняя зарплата SEO специалиста
Обновлено: 27.04.2021 11466
как установить файлы robots.txt для субдоменов?
спросил
Изменено 3 месяца назад
Просмотрено 2к раз
У меня есть поддомен, например, blog. example.com, и я хочу, чтобы этот домен не индексировался Google или любой другой поисковой системой. Я поместил свой файл robots.txt в папку «блог» на сервере со следующей конфигурацией:
example.com, и я хочу, чтобы этот домен не индексировался Google или любой другой поисковой системой. Я поместил свой файл robots.txt в папку «блог» на сервере со следующей конфигурацией:
Агент пользователя: * Запретить: /
Можно ли не индексировать Google?
За несколько дней до этого мой сайт:blog.example.com показывал 931 ссылку, но теперь он отображает 1320 страниц. Мне интересно, правильный ли мой файл robots.txt, тогда почему Google индексирует мой домен.
Если я делаю что-то не так, пожалуйста, поправьте меня.
- robots.txt
- субдомен
Рахул,
Не уверен, что ваш robots.txt дословный, но обычно директивы находятся в ДВУХ строках:
Агент пользователя: * Запретить: /
Этот файл должен быть доступен по адресу http://blog.example.com/robots.txt. Если он недоступен по этому URL-адресу, поисковый робот не найдет его.
Если у вас есть страницы, которые уже были проиндексированы Google, вы также можете попробовать удалить страницы из индекса вручную с помощью инструментов Google для веб-мастеров.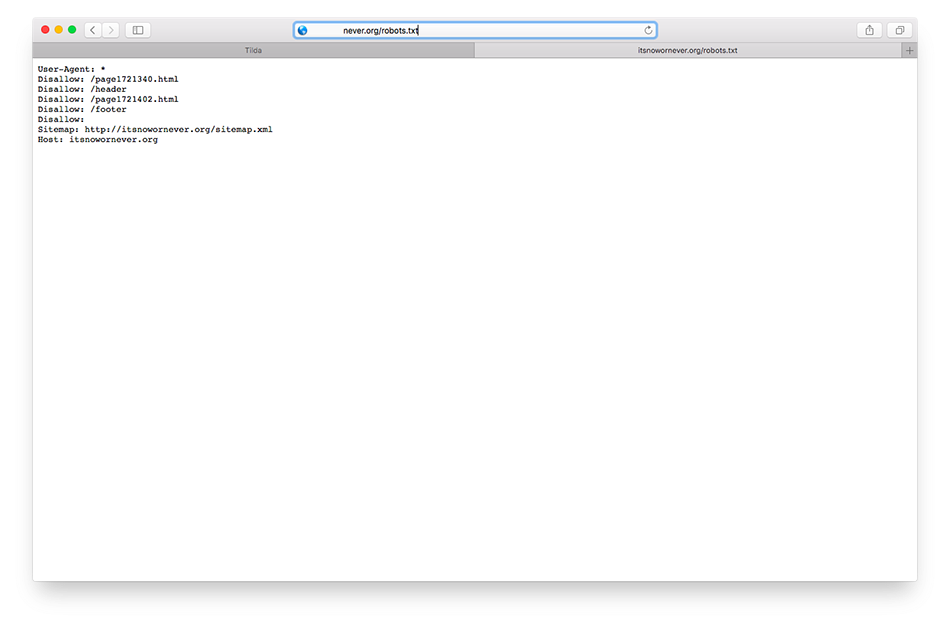
1
Этот вопрос на самом деле о том, как предотвратить индексацию поддомена, здесь ваш файл robots фактически предотвращает индексацию вашего сайта.
Не используйте файл robots.txt, чтобы скрыть свои веб-страницы от результатов поиска Google.
Введение в robots.txt: для чего используется файл robots.txt? Центральная документация поиска Google
Чтобы директива noindex действовала, страница или ресурс не должны быть заблокированы файлом robots.txt и должны быть доступны для сканера иным образом. Если страница заблокирована файлом robots.txt или краулер не может получить к ней доступ, краулер никогда не увидит директиву noindex, и страница по-прежнему может отображаться в результатах поиска, например, если на нее ссылаются другие страницы.
Заблокировать индексацию поиска с помощью noindex Центральная документация Google Search
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
apache2 — Как заставить Apache /robots.
 txt вести к файлу, независимо от домена?
txt вести к файлу, независимо от домена?спросил
Изменено 7 лет, 3 месяца назад
Просмотрено 10 тысяч раз
Я запускаю локальный сервер со следующими URL-адресами:
foo.self бар.сам бла-бла.сам
Приведенный выше URL-адрес обрабатывается следующим оператором VirtualHost :
UseCanonicalName Выкл. имя_сервера Псевдоним сервера *.self VirtualDocumentRoot C:\Users\Foo\PhpstormProjects\%-2 <Каталог C:\Users\Foo\PhpstormProjects\*> Опционы Индексы FollowSymLinks включает ExecCGI MultiViews Отклонить заказ, разрешить Разрешить от всех Требовать все предоставленные
У каждого есть свой собственный /robots. , но что мне нужно сделать, чтобы любой из URL-адресов возвращал одно и то же, независимо от того, что содержится в их  txt
txt /robots.txt или даже если он не существует. Например, следующие URL-адреса:
- foo.self/robots.txt
- bar.self/robots.txt
- вздор.self/robots.txt
…вернет тот же текст:
Агент пользователя: * Запретить: /
Это без обращения к 301 Перенаправление или RewriteRule .
- apache
- apache2
- robots.txt
0
Просто создайте псевдоним для /robots.txt в настройках вашего хоста, указывающий на тот же файл. Плюс, возможно, для предоставления доступа требуется директива Location:
UseCanonicalName Выкл. имя_сервера Псевдоним сервера *.self Псевдоним /robots.txt C:\Somfolder\robots.txt <Расположение "C:\Somfolder\robots. txt"> Отклонить заказ, разрешить Разрешить от всех VirtualDocumentRoot C:\Users\Foo\PhpstormProjects\%-2 <Каталог C:\Users\Foo\PhpstormProjects\*> Опционы Индексы FollowSymLinks включает ExecCGI MultiViews Отклонить заказ, разрешить Разрешить от всех Требовать все предоставленные
Вы добавляете это к конфигурации всех хостов, все эти директивы Alias указывают на один и тот же файл. Файл C:\Somfolder\robots.txt является «обычным» файлом robots.txt, как вы его описали.
Вы можете упростить это, включив эту директиву в качестве шаблона. Таким образом, вы помещаете директиву в отдельный файл конфигурации и добавляете только директиву включения в конфигурации ваших хостов:
UseCanonicalName Выкл. имя_сервера Псевдоним сервера *.self Включить C:\path\to\file\robots.inc VirtualDocumentRoot C:\Users\Foo\PhpstormProjects\%-2 <Каталог C:\Users\Foo\PhpstormProjects\*> Опционы Индексы FollowSymLinks включает ExecCGI MultiViews Отклонить заказ, разрешить Разрешить от всех Требовать все предоставленные
Файл C:\path\to\file\robots.