Работа с файлом robots.txt
Когда происходит создание сайта, то оптимизация его содержания происходит в двух направлениях :
- Оптимизируют дизайн и тексты для посетителей веб-ресурса
- Оптимизации подвергается программная часть сайта, которая важна для поисковых систем
Файл robots.txt имеет неоднозначную оценку в среде веб-программистов и специалистов по продвижению веб-сайтов. Этот файл существует во всех сайтах, его готовят специалисты для поисковых систем в ходе оптимизации веб-ресурса для раскрутки. Но все же не до конца понятно то, важен ли в наше время этот файл. Нужно заметить, что файл robots.txt представляет собой неисполняемый файл, который имеет содержание сугубо для поисковых систем. Причем те инструкции, которые указываются в файле robots.txt могут быть применены и без него, если установить в CMS сайта нужные функциональные плагины.
Например, через файл robots.txt имеется возможность запретить индексирование сайта, однако та же функция имеется и в специальных плагинов для seo, которые можно установить бесплатно через магазин плагинов для любой CMS, а также запретить индексировать сайт или отдельные страницы сайта можно и через панель управления служб Яндекс Вебмастер и Google Вебмастер. Также через эти службы, как и через файл robots.txt, можно запретить индексирование, например, версий страниц сайта для печати.
Также через эти службы, как и через файл robots.txt, можно запретить индексирование, например, версий страниц сайта для печати.
Когда начинается процесс индексирования контента сайта поисковыми системами, те в первую очередь ищут в корневом каталоге файл robots.txt, который должен с самого начала указать поисковым ботом то, какие страницы разрешено индексировать, а какие все же нет. Но, как указывают специалисты, поисковые боты индексируют все страницы сайтов, даже если их запрещает владелец сайта через файл robots.txt, только запрещенные к индексации страницы не попадут в поисковую выдачу. И вот опять можно задать вопрос- зачем тогда нужен файл robots.txt? Его функции заменяют панель управления сайтами через службы вебмастера от крупнейших поисковиков, и даже при запрещении индексирования некоторого контента через этот файл, все равно поисковики индексируют весь контент сайта.
Не стоит забывать, что файл robots.txt не исполняемый, то есть его можно только читать. Править этот файл можно разными способами. И через обычный бесплатный редактор Notepad, установленный на компьютер, либо через панель управления контентом CMS, где также есть возможность управлять записями этого файла. Конечно, не стоит забывать, что хоть файл robots.txt это всего лишь читаемый файл, содержание его обращено к поисковым ботам, а значит информация в этом файле должна быть написана на понятном языке для всех поисковых ботов в мире, и иметь ясную и четкую структуру.
И через обычный бесплатный редактор Notepad, установленный на компьютер, либо через панель управления контентом CMS, где также есть возможность управлять записями этого файла. Конечно, не стоит забывать, что хоть файл robots.txt это всего лишь читаемый файл, содержание его обращено к поисковым ботам, а значит информация в этом файле должна быть написана на понятном языке для всех поисковых ботов в мире, и иметь ясную и четкую структуру.
Структура файла robots.txt
Начинается записать в файле robots.txt всегда с упоминания того поискового бота, к которому будет обращены команды. Обращаться к поисковому боту можно с помощью директивы User-agent. Стоит отметить и то, что если после директивы User-agent стоит звездочка *, то значит команда директивы обращена ко всем поисковым ботам. Также не стоит забывать и о том, что текст в файле robots.txt не чувствителен к регистру, то есть можно писать как с большой буквы. Так и большими буквами. Но лучше всего, раз уж этот традиционный файл используется на сайте, лучше соблюдать все традиции.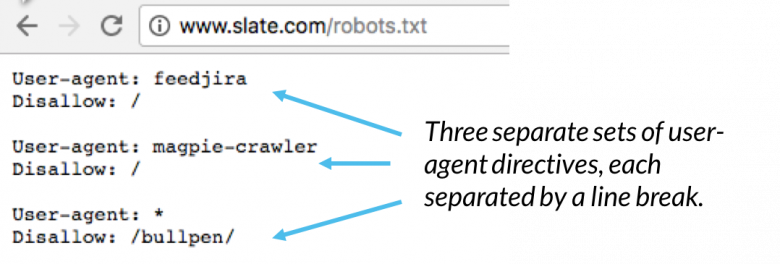 После директивы user-agent используется название поискового бота, к которому и обращено послание. Если к поисковому боту от Google, то после директивы первой стоит добавить googlebot, если к поисковой системе Яндекс, то Yandex. Таким образом, первая запись всегда в файле robots.txt имеет первую строку :
После директивы user-agent используется название поискового бота, к которому и обращено послание. Если к поисковому боту от Google, то после директивы первой стоит добавить googlebot, если к поисковой системе Яндекс, то Yandex. Таким образом, первая запись всегда в файле robots.txt имеет первую строку :
User-agent: googlebot
После обращению к поисковому боту стоит указать те папки или файлы, которые запрещено индексировать. Используется для этого простая директива Disallow. После ее объявления, нужно указать запрещенные к индексированию папки или файлы, как указано в примере ниже:
Disallow: /feedback.php Disallow: /cgi-bin/
В данном примере показано, что в файле robots.txt были запрещены к индексированию файл feedback.php и папка cgi-bin/ , которые находятся в корневом каталоге сайта. Для особо ленивых предусмотрена возможность блокировки по начальным символам, поэтому стоит всегда быть аккуратней с директивой
 Если указать в файле robots.txt :
Если указать в файле robots.txt :Disallow : prices
То поисковой бот не будет индексировать и имеющиеся файлы http://site.ru/prices.php и даже папку http://site.ru/prices/
Также не стоит забывать, что после директивы Disallow ничего не находится, то полностью все содержание сайта будет проиндексировано. Если же после директивы Disallow стоит символ /, то абсолютно полностью все содержимое сайта запрещено индексировать.
Если вдруг возникла свободная минутка и есть желание пообщаться с поисковыми ботами, но нет желание ничего запрещать для индексирования, то можно создать файл robots.txt с командой :
User-agent: * Disallow:
Поисковой бот любой поймет, что владелец сайта имеет много свободного времени, раз тратить свое время на создание файла robots.txt, в котором разрешает всем ботам индексировать все содержание сайта. Если не будет такой записи или даже вообще будет отсутствовать файл robots.txt, то любой поисковик так и сделает.
Директива Allow и ее магические свойства
Не все волшебство файла robots.txt заключено в запрете индексирования файлов сайта, также можно разрешать индексировать. Все точно также, как и с директивой
User-agent: Yandex Allow: /prices Disallow: /
Все ясно и понятно – Поисковому боту от Яндекса запрещается индексировать на сайте все, кроме папки prices. Стоит отметить, что директиву Allow используют всегда перед директивой Disallow. Если после Allow в файле robots.txt будет пусто , то это означает, что поисковому боту Яндекса запрещена индексация всех файлов :
User-agent: Yandex Allow:
Иными словами, в файле robots.txt директивы Disallow / и Allow равнозначны, запрещающие индексацию.
Все поисковые системы, по крайней мере речь если идет о крупнейших, понимают содержание записей файла robots.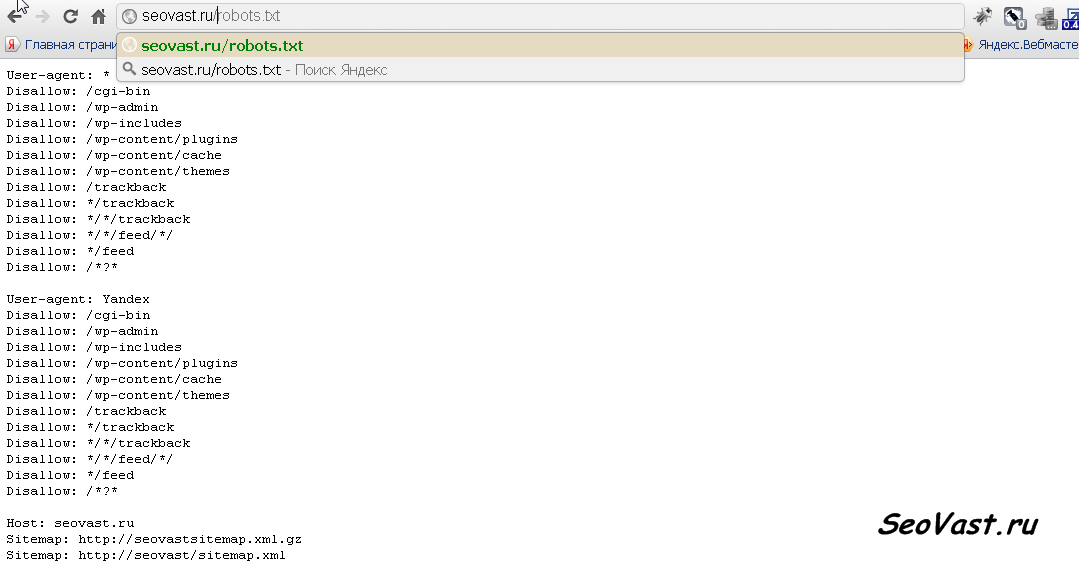 txt одинаково. Если есть опасения запутаться в директивах данного файла, то лучше всего использовать службы Яндекс Вебмастер и Google Вебмастер, через которые можно начать индексацию страниц сайта, а также без труда управлять индексацией страниц, разрешая или запрещая те или иные страницы для поисковых ботов. Эти службы помогают также загрузить карту сайта.
txt одинаково. Если есть опасения запутаться в директивах данного файла, то лучше всего использовать службы Яндекс Вебмастер и Google Вебмастер, через которые можно начать индексацию страниц сайта, а также без труда управлять индексацией страниц, разрешая или запрещая те или иные страницы для поисковых ботов. Эти службы помогают также загрузить карту сайта.
Специальные регулярные выражения для robots.txt
С помощью всемогущего файла robots.txt можно запретить индексировать не только отдельные страницы сайта или какие-то папки с файлами, но и отдельно файлы. Это очень удобно бывает в том случае, если сайт достаточно крупный, и в нем находится большое количество файлов различного содержания. Тут нужно отдельно указать, что регулярные выражение
User-agent: Yandex Allow: /prices/*.html$ Disallow: /
Ценителям магии файла robots.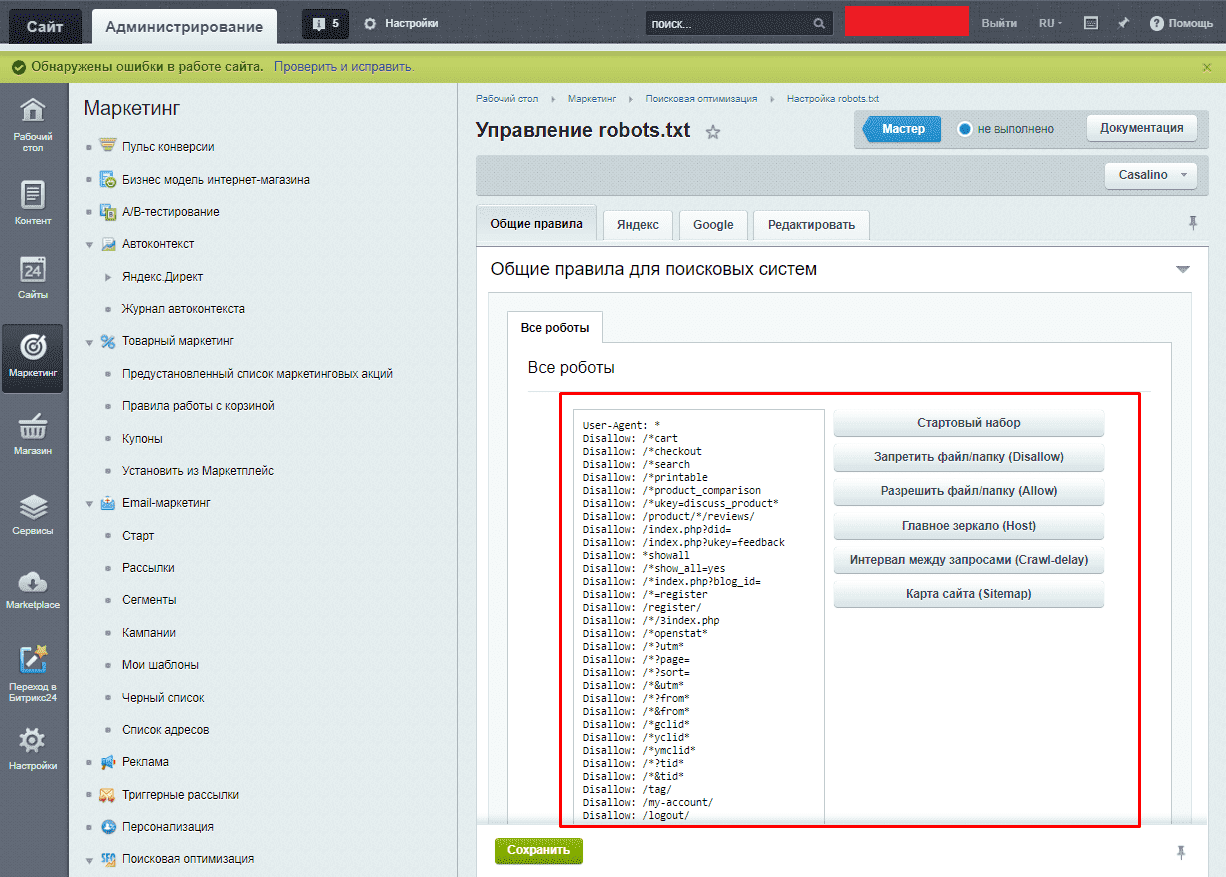 txt все понятно с этой записью, точно также, как и поисковому боту от Яндекса. Поисковик должен индексировать все файлы в папке prices в html формате, но запрещена индексация любых других файлов на сайте. Или еще один пример с регулярными выражениями для robots.txt :
txt все понятно с этой записью, точно также, как и поисковому боту от Яндекса. Поисковик должен индексировать все файлы в папке prices в html формате, но запрещена индексация любых других файлов на сайте. Или еще один пример с регулярными выражениями для robots.txt :
User-agent: Yandex Disallow: *.pdf$
Запись говорит, что Яндекс-боту запрещена индексация всех файлов в формате pdf.
Путь к карте сайта
Файл robots.txt многофункциональный читаемый файл, которые также указывает и направление поисков поисковыми ботами карты сайта. Стоит отметить, что карта сайта, если веб-ресурс действительно обширен, очень важна для того, чтобы поисковые системы могли проиндексировать все нужные страницы и файлы сайта. Послать поисковой бот можно с помощью директивы Sitemap :
User-agent: googlebot Disallow: Sitemap: http://site.ru/sitemap.xml
Загрузить карту сайта можно и с помощью служб Яндекс Вебмастер и Google Вебмастер, не работая с директивами robots.txt.
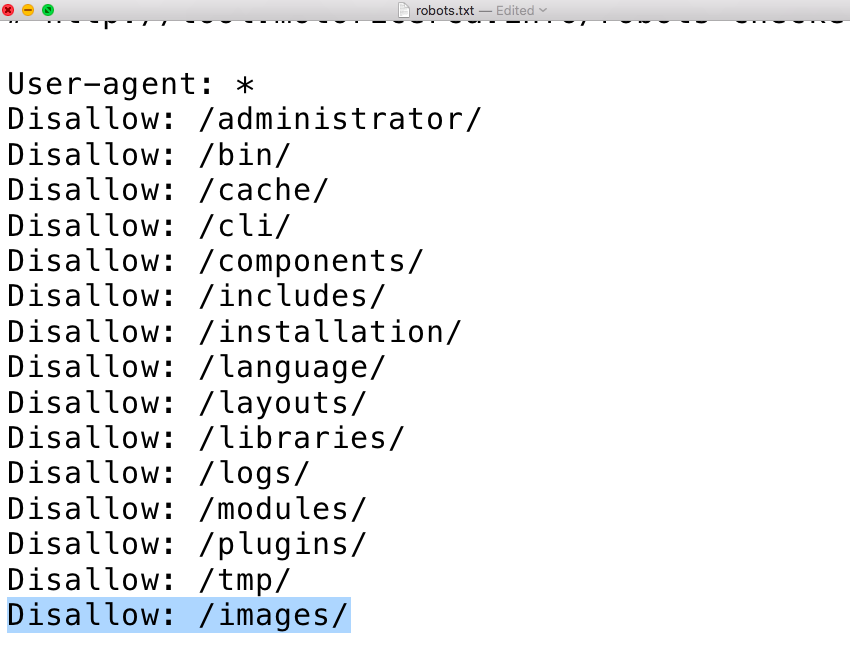
Работа с зеркалами сайта в файле robots.txt
Не так давно поисковой гигант Google решил начать борьбу за повышенную защищенность посетителей сайтов в интернете, и решил оценивать сайты с шифрованном трафиком с https протоколом выше сайтов, которые были всегда с стандартным http протоколом. И многие владельцы сайтов, даже если они не работали с платежными системами, должны были перейти на https протокол для того, чтобы поднять свой рейтинг в поисковой выдачи. Но как это сделать?
Начать нужно с того, что для поисковых систем сайты http://site.ru/ и https://site.ru/ являются различными, хотя имеют одинаковое название, и являются по сути зеркалами друг друга, но поисковые системы будут их по-разному индексировать и оценивать. Чтобы указать поисковым ботам, что нужно индексировать только одно главное зеркало сайта, требуется использовать директиву Hosts в файле robots.txt. Выглядеть это будет так :
User-agent: googlebot Disallow: /prices.php Host: https://site.(.*)$ http://www.site.ru/$1 [R=301,L]
Использование комментариев в robots.txt
Зачем комментировать что-то для поисковых ботов в файле robots.txt? Сложно сказать, но если кому-то захочется это делать, стоит использовать символ #. Вот пример :
User-agent: googlebot Disallow: /prices/ # тут нет ничего интересного
Краткое описание работы с файлом robots.txt
1.Как разрешить всем поисковым ботам индексацию всех файлов на сайте?
User-agent: * Disallow:
2.Как запретить всем поисковым ботам индексацию всех файлов на сайте?
User-agent: * Disallow: /
3.Как запретить поисковому боту от Google индексировать файл prices.html?
User-agent: googlebot Disallow: prices.html
4.Как разрешить всем поисковым ботам индексировать весь сайта, а боту от Google запрещаем индексацию папки prices?
User-agent: googlebot Disallow: /prices/ User-agent: * Disallow:
Какие ошибки могут возникнуть при работе с файлом robots.
 txt?
txt?Нужно сказать, что поисковые боты не чувствительны к регистру букв при написании директив, но с названием файлов и папок нужно быть осторожнее. Также проблем между директивами не стоит делать просто так для красоты, ведь для файла robots.txt проблем означает разделение команд для разных поисковых ботов.
Для каждого поискового бота нужно создавать свою директиву user-agent, а не пытаться в одну вписать несколько ботов. Очень часто забывают использовать символ / перед названием папок, что приведет к недопониманию поисковым ботом директивы. Также админка сайта исключается всегда поисковыми ботами из индексации и ее не следует указывать в файле. Есть мнение специалистов, что большой размер файла robots.txt с огромным списком страниц сайта и файлов, исключаемых из индексации, просто игнорируются поисковыми системами.
Поэтому надежней всего удалять ненужные файлы, а не указывать запрет на их индексацию.
Как проверить файл robots.txt на фатальные ошибки?
Если файл robots. txt отличается многословием, то есть в нем указаны команды для поисковых ботов для множества файлов и страниц сайта, то лучше провести проверку качества файла robots.txt с помощью ресурсов Яндекс Вебмастер и Google Вебмастер.
txt отличается многословием, то есть в нем указаны команды для поисковых ботов для множества файлов и страниц сайта, то лучше провести проверку качества файла robots.txt с помощью ресурсов Яндекс Вебмастер и Google Вебмастер.
Что такое файл robots.txt для сайта, как правильно составить и зачем нужен, его директивы, отличие для Яндек и Google
Автор Prodvigaem Team На чтение 12 мин. Просмотров 1.3k. Опубликовано
Поисковые системы, такие как Google, Yandex, Yahoo! и все прочие, управляются не вручную, а при помощи разнообразных программ-скриптов.
Как волонтеры во время переписи населения ходят по домам и считают жителей, так и поисковые программы-краулеры непрерывно блуждают по сети, проверяя старые ресурсы, разыскивая новые, — обновляют и пополняют базу данных поисковиков. От работы этих программ-ботов зависит, в том числе, популярность интернет-контента.
Содержание
- Для чего нужен robots.
 txt?
txt? - Что такое robots.txt и как его читают боты
- Как создать файл robots.txt
- Дополнительные операторы
- Директива User-agent
- Директивы Disallow и Allow
- Директива Host
- Директива Sitemap
- Директива Crawl-delay
- Директива Clean-param
- Настройка файла конфигурации и проверка
- Особенности настройки файла для Yandex и Google
- Тонкая настройка, что закрывать
- Robot.txt и типичные ошибки
- Использование robots.txt в WordPress
- Плагин для редактирования All in One SEO Pack
- Советы по настройке robots в CMS
- Оригинальные способы применения robots.txt
- Итог
Для чего нужен robots.txt?
Для более удачной работы по взаимодействию с поисковыми системами необходимо создавать некие наборы правил. В соответствии с этими правилами поисковые виртуальные машины-роботы будут получать доступ к разрешенным разделам сайта (файлам и директориям), а к тем разделам, которые не предназначены для ботов, доступ будет «не рекомендован».
Инструкции из файла robots.txt являются рекомендациями. То есть, поисковые системы могут и не исполнять их. Это имеет значение, если среди прочих данных есть конфиденциальная информация.
Причем неважно, есть ли на сайте файл robots.txt, или его нет, для поисковиков это не имеет значения. Но при отсутствии файла программы-боты станут хозяйничать на сайте, как у себя дома, загружая большие объемы информации и несколько тормозя работу сайта.
Таким образом, присутствие файла весьма желательно не только для оптимизации взаимодействия с поисковиками, но и для уменьшения нагрузки на сайт.
Что такое robots.txt и как его читают боты
По сути, robots.txt – это простой текстовый файл, который размещают в корневой директории сайта. Когда поисковый бот попадает на ресурс, он в первую очередь пытается обнаружить этот файл, после чего считывает его и при дальнейшей работе руководствуется описанными инструкциями.
Если файл не будет найден, то это не смутит робота, он будет скачивать и проверять все данные сайта.
Если масштаб проекта не слишком велик, — маленький и легкий сайт без сложной структуры, — то, возможно, и не следует создавать файл роботс.
Как создать файл robots.txt
Создать файл robots.txt можно в текстовом редакторе, после формирования сохранить с расширением *.txt. При желании можно использовать готовые шаблоны файлов, они есть в сети; есть также специальные онлайн-сервисы, позволяющие сгенерировать robots.txt автоматически.
Однако стоит заметить, что роботс, созданный онлайн-программами, нужно очень тщательно проверять. От этого будет зависеть правильная работа сайта, иначе могут быть серьезные трудности в будущей работе ресурса.
При написании команд, нужно учесть, что хотя не имеет значения, какими буквами написана директива, строчными или заглавными (user=USER), однако лучше писать так, чтобы потом не было проблем с прочтением и разбором файла. Разработчики ПО называют это культурой написания кода.
Дополнительные операторы
Помимо основных директив при создании роботса используются дополнительные символьные операторы:
- Символ «*» — показывает, что количество символов может быть любым, либо символы отсутствуют;
- символ «$» — значит, что предыдущий символ является последним;
- символ «#» — предупреждает, что за ним следует комментарий к коду, не читаемый ботом.
Директива User-agent
Это основная директива файла, которая сообщает, какие боты должны выполнять все остальные команды.
Например, имена основных поисковых программ:
- Google – googlebot;
- яндекс – Yandex;
- рамблер – StackRambler;
- yahoo – Slurp;
- msn – msnbot.
Это лишь наименование ключевых ботов, есть еще и другие, например, — Googlebot-Image – это поисковый робот Гугла, работающий с картинками, а YandexNews – проводит индексацию новостных данных. При разработке структуры роботс-файла нужно четко понимать, для каких данных следует допускать того или иного бота. Также можно обращаться ко всем поисковым программам определенного поисковика.
Команда для конкретного поисковика будет смотреться так:
User-agent: <наименование поисковой программы>
Или обращаемся ко всем ботам Яндекса:
User-agent: Yandex
Если перечень директив адресуется всем поисковикам, то вместо имени ставится звездочка:
User-agent: *
За этой командой должна идти следующая, то есть, обращаясь к конкретному боту, мы должны определить – что он должен делать, или не делать.
Директивы Disallow и Allow
Эти команды запрещают или разрешают ботам, указанным командой User-agent, читать определенные данные. Поскольку структура файла – блоковая, то пример будет выглядеть так:
User-agent: Googlebot # для Гугл-бота:
Disallow: /file_1.html # запрещено читать файл file_1.html
Можно прописать запрет на индексацию и файлов, и директорий:
User-agent: Googlebot
Disallow: /Foto # для Гугл-бота действует запрет на две директории
Disallow: /Docs
Disallow: /file_1.html # и один файл
На примере видно, как использовать команды Allow/Disallow для фалов и расширений файлов:
Allow: *.txt # разрешение действует на все файлы формата *txt
Disallow: /Temp # запрет для папки Temp
Если же необходимо разрешить доступ к файлам *txt , входящим в папку Temp, придется это делать так:
Allow: *.txt # Здесь разрешена индексация всех файлов *txt
Allow: Temp/*.txt # в том числе *txt из папки Temp
Disallow: /Temp # для остальных файлов Temp – доступ закрыт
Порядок очередности команд не имеет значения.
Директива Host
Необходима для объявления главного зеркала сайта. Объявляется только один раз. Основное назначение – если доступ к сайту возможен с нескольких доменов-зеркал(поддоменов), определить это, а при необходимости — отметить главный зекральный ресурс.
Пример использования:
User-Agent: Yandex
Disallow: /Docs
Host: www.site.ru # основное зеркало сайта
Cейчас вместо директивы Host используется перенаправление 301 редирект.
Директиву Host можно смело удалять изо всех файлов роботс, как «мертвую» команду.
Директива Sitemap
Сообщает роботам, где находится карта сайта в виде XML файла, в котором перечислены адреса всех страниц ресурса для сканирования. Поможет боту определить, как изменилась структура ресурса, для дальнейшей индексации и обновления базы данных поисковика.
Расположение команды – не имеет значения.
Написание команды:
Sitemap: http://site.ru/sitemap.xml
Директива Crawl-delay
Еще один вспомогательный оператор, актуальный только для Yandex. Сообщает поисковой программе, сколько времени в секундах будут загружаться страницы. Нужен, если ресурс расположен на слабом сервере или — если страниц слишком много и они много «весят», а индексация происходит очень часто. В этом случае боты могут сильно загружать систему.
Сообщает поисковой программе, сколько времени в секундах будут загружаться страницы. Нужен, если ресурс расположен на слабом сервере или — если страниц слишком много и они много «весят», а индексация происходит очень часто. В этом случае боты могут сильно загружать систему.
При помещении строки:
Crawl-delay: 4
Теперь Яндекс-программы будут оповещены, что не следует скачивать данные более одного раза в 4 секунды. Можно указывать не только целые, но и дробные числа.
Директива Clean-param
Команда обращается к боту с требованием не индексировать адреса страниц с указанными параметрами. Это более всего касается динамических ссылок, которые постоянно генерируются в процессе работы сайта и могут дублировать друг друга. Одна и та же страница может быть доступна одновременно по нескольким адресам:
www.site.ru/catalog/get_phone.ru?ref=page_1&phone_id=1
www.site.ru/catalog/get_phone.ru?ref=page_2&phone_id=1
www.site.ru/catalog/get_phone.ru?ref=page_3&phone_id=1
Решить проблему можно просто:
User-agent: Yandex
Disallow:
Clean-param: ref /catalog/get_phone. ru
ru
Ref – атрибут, который сообщает источник ссылки.
Настройка файла конфигурации и проверка
Одной из основ настройки конфигурационного файла роботс является четкое понимание, каких целей нужно добиться. Для этого следует сделать анализ, на основании лог-файлов, использовать специальные программы и сервисы, выяснить к каким отделам сайта краулеры проявляют наибольший интерес и какую нагрузку на систему они при этом создают. Если происходит постоянное торможение ресурса вследствие частой индексации, то есть резон запретить ботам качать большие фрагменты с сайта, ограничить доступ к соответствующим директориям.
Файл «robot.txt» размещают в корневом каталоге, например:
Адрес_сайта.рф/robots.txt
Отправить роботс на его законное место можно при помощи либо FTP клиента, либо через файловый менеджер портала, предоставляющего хостинг.
Есть различные платные/бесплатные онлайн-сервисы для тестирования готовых проектов. При их участии можно получить реальные рекомендации о способах оптимизации ресурса. На аналогичных порталах следует проверять отредактированный вручную файл «роботс», его тестирование укажет на ошибки, допущенные при составлении; после исправления которых можно будет снова поместить robots.txt в корневой каталог сайта.
На аналогичных порталах следует проверять отредактированный вручную файл «роботс», его тестирование укажет на ошибки, допущенные при составлении; после исправления которых можно будет снова поместить robots.txt в корневой каталог сайта.
Для заливки на ресурс можно использовать Total Commander. Ищем параметры хостинга на панели управления сайтом. Потребуются: логин FTP, пароль и хост. В Total Commander ищем – «Сеть» — «Соединиться с FTP», жмем на кнопку «Добавить» с правой стороны. Вводим данные хостинга, ставим галку в клетку «Пассивный режим обмена».
Если все введено правильно, то после нажатия кнопки «Ок», произойдет соединение и появится возможность загружать файла на сервер.
Особенности настройки файла для Yandex и Google
Считается, что настраивать конфиг-файл роботс следует для Яндекса, Гугла и остальных поисковиков тремя блоками команд-операторов, то есть — отдельно для каждого.
Тогда в файле будет такого рода скелет:
User-agent: *
User-agent: Yandex
User-agent: Googlebot
Между блоками директив для разных ПС нужно оставлять пустую строчку.

Не забываем указать адрес карты сайта в каталоге:
Sitemap: http://site.ru/sitemap.xml
Если проект крупный, состоящий из нескольких десятков тысяч страниц, то рекомендуется его разбить на части, тогда карт будет несколько. Каждую придется вписать в роботс.
При создании записей для Яндекса, учитываем, что сейчас директива Host больше им не поддерживается, поэтому используем 301 редирект.
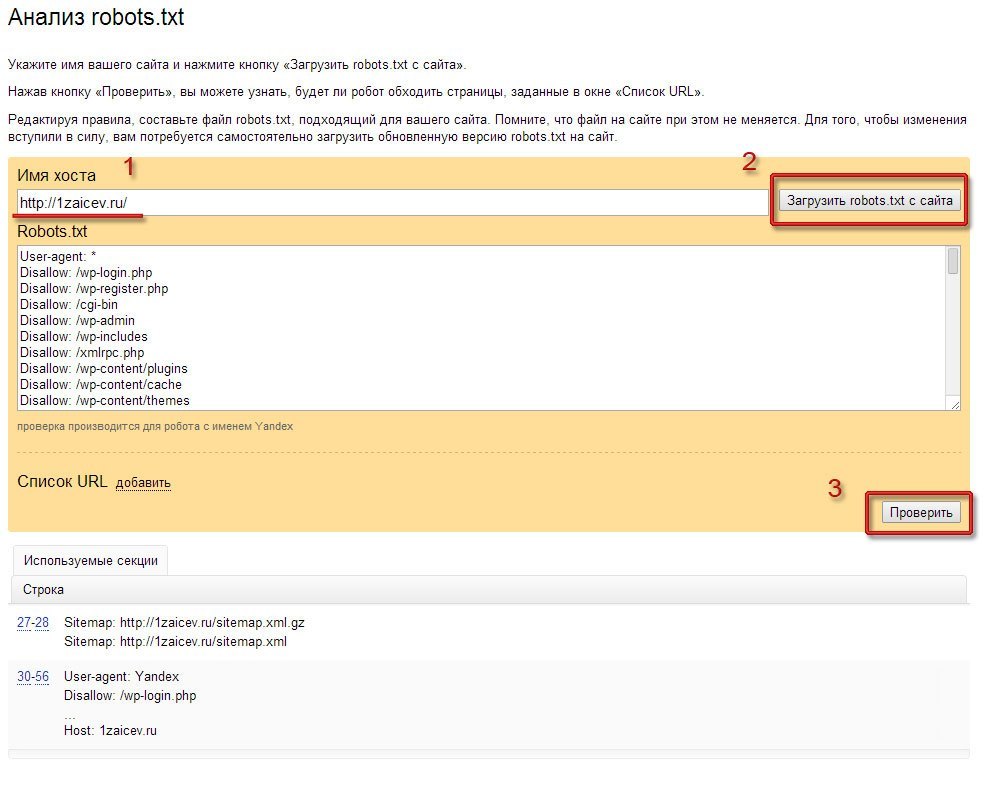
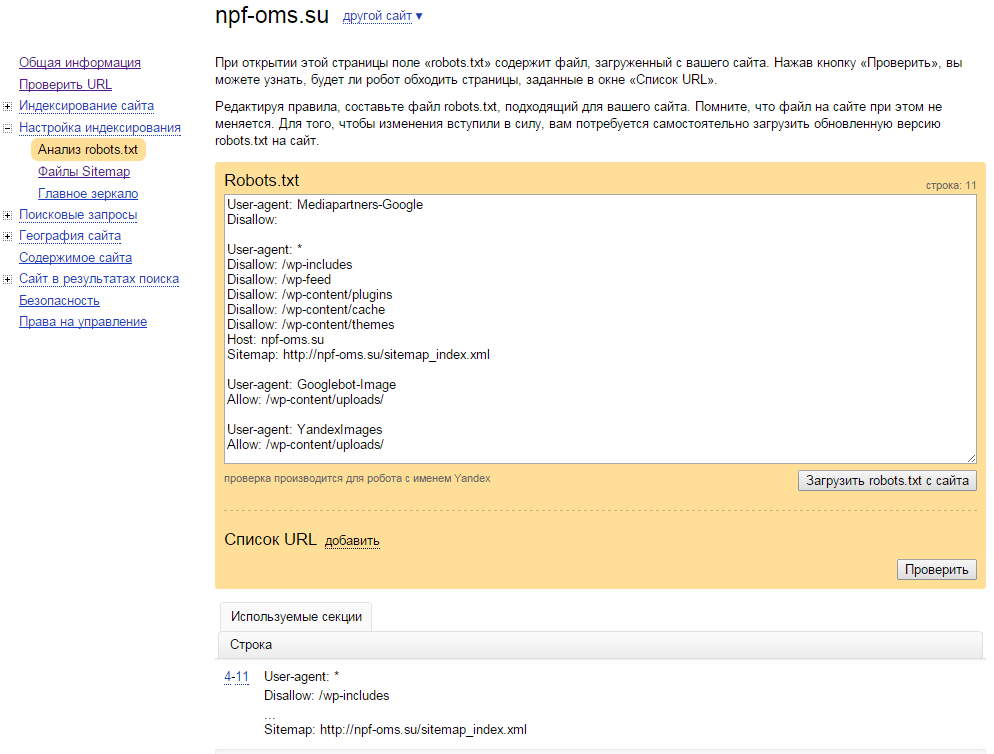
Проверить правильность записей в файле конфигурации можно на Яндекс Вебмастер. Используя соответствующие диалоговые окна, вводим содержимое роботса, ссылку на реальный сайт, нажимаем кнопку «проверить».
При редактировании блока для Гугла, отметим, что разработчики ПС советуют разрешать доступ к JS скриптам и CSS таблицам. С одной стороны, лишние страницы не должны появиться в выдаче ПС, с другой – краулеры будут более корректно обрабатывать сайт и заполнять базу данных ПС.
User-agent: Googlebot
Allow: *.css # разрешаем обработку таблиц
Allow: *. js # разрешаем индексирования скриптов
js # разрешаем индексирования скриптов
Robots.txt предназначенный для Гугла проверяем на сайте сервиса Google Webmaster Tools.
Тонкая настройка, что закрывать
Опытные вебмастера часто запрещают индексацию:
- Для ресурсов, связанных с интернет-торговлей, лучше ограничить доступ ботов к файлам корзины товаров и оформления покупок. Сюда же относятся различные фильтры для сравнения товаров.
- Запрет на индексацию конфиденциальной информации. Это то, что имеет отношение к регистрационным данным пользователей (посетителей) сайта. Базы данных логинов, паролей и так далее.
- Системные каталоги, – их перебор – лишняя трата времени для поисковой программы.
- Страницы поиска по сайту – в некоторых случаях, при их индексации, возможно появление множества дублей-ссылок.
- Временные страницы – например, если разрабатывается новый дизайн проекта, тоже лишние для краулеров.
В качестве дополнения: если нет возможности сделать ЧПУ (человеко-понятные URL адреса для ссылок), то лучше скрывать их от ботов.
Robot.txt и типичные ошибки
При написании команд, следует быть внимательными.
- Очень часто начинающие веб дизайнеры путают синтаксис команд:
User-agent: / # нет такого поискового робота
Disallow: Yandexbot # нет такой директории
Реакции на эти команды не последует. Правильно так:
User-agent: Yandexbot
Disallow: /
- К оператору Disallow пристраивают одновременно несколько папок или директорий:
Disallow: /Temp /home /Video
Следует определять для каждой команды Allow/Disallow – одну папку.
- Неправильное название файла. Если в тексте конфига можно использовать строчные и заглавные буквы, то название «robots.txt» — должно состоять только из маленьких.
- Оператор User-agent должен иметь параметр: или имя бота, или символ «*».
- Посторонние символы, нарушающие структуру роботс-файла.
- Нельзя писать полные адреса запрещаемых страниц:
Полный адрес документа: http://site.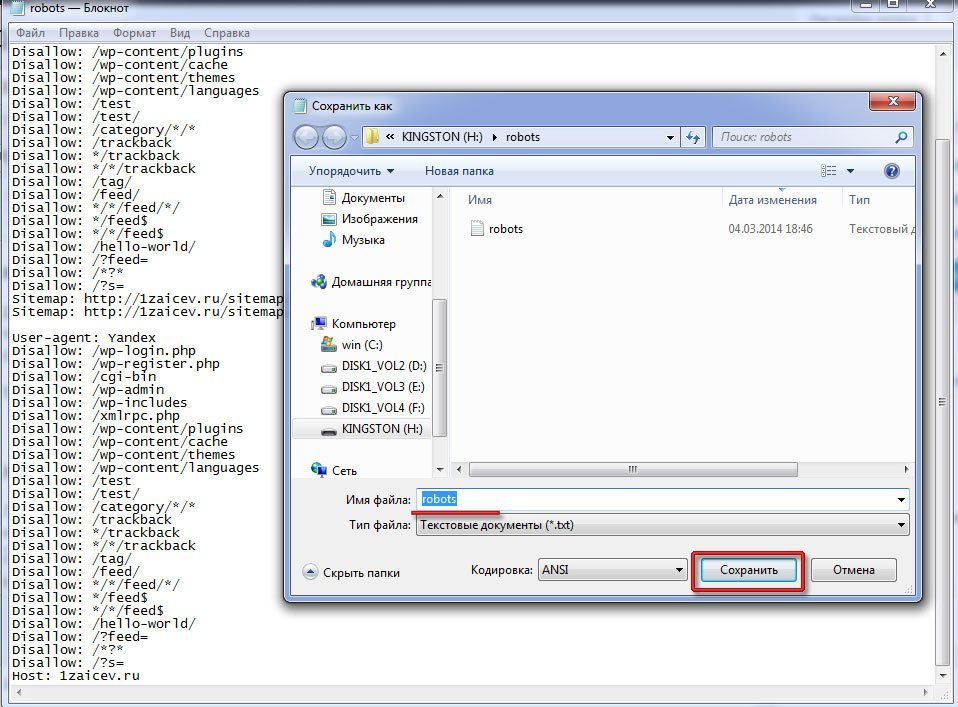 super/pupkin.html , но для запрета доступа к документу pupkin.html указываем:
super/pupkin.html , но для запрета доступа к документу pupkin.html указываем:
Disallow: /pupkin.html
Бывают менее распространенные ошибки: путь к карте сайта указан не тот, или сайт полностью закрыт от индексирования; либо не запрещен доступ к страницам с идентификаторами сессий, метками UTM.
Даже если файл составлен правильно и максимально оптимизирован, не стоит ждать мгновенных изменений в базах поисковиков. Обновление данных произойдет через 1-2 недели.
Использование robots.txt в WordPress
WP – это комплекс ПО (CMS – система управления содержимым) — для поддержки данных сайта, распространено в соответствии с лицензией GPL.
Создание файла ничем не отличается от всех прочих способов: открываем текстовый файл, редактируем по правилам, сохраняем в виде robots.txt и льем в корень ресурса.
Для создания роботс можно использовать плагин.
Плагин для редактирования All in One SEO Pack
All in One SEO Pack – плагин WordPress, позволяющий создавать и редактировать роботс.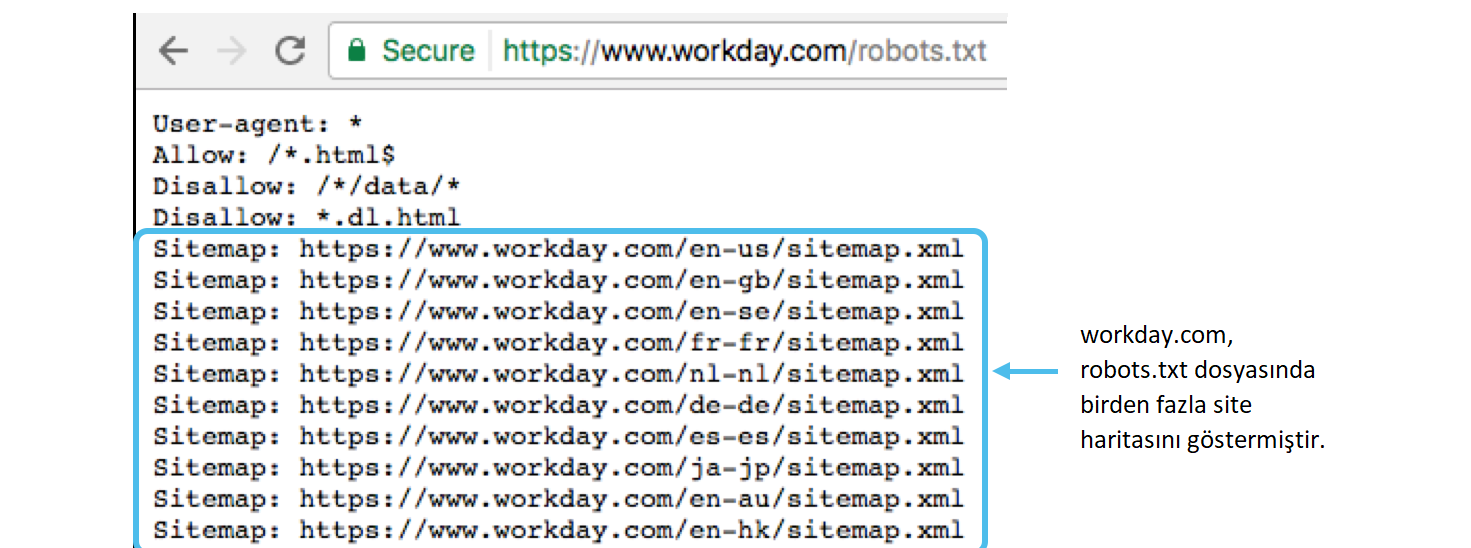 Этот файл является динамическим, то есть он формируется и показывается только при обращении краулера к сайту. XML карту сайта лучше приготовить заранее и поместить в корневой каталог проекта.
Этот файл является динамическим, то есть он формируется и показывается только при обращении краулера к сайту. XML карту сайта лучше приготовить заранее и поместить в корневой каталог проекта.
Хорош еще тем, что имеет множество настроек, помогающих оптимизировать проект.
Советы по настройке robots в CMS
- Modx – возможны трудности с ссылками-дублями. Соответственно решается запретами – Disallow:
Disallow: /index.php # дубль основной страницы ресурса
Disallow: *? # убираем все дублирующие ссылки
- Opencart — популярный движок онлайн-магазина. Стандартного шаблона в настройках нет, но никаких особых изменений тоже нет, создаем robots.txt, алгоритм запретов: база паролей, административные каталоги и прочее.
- Bitrix – используем штатные средства на сайте CMS: перейдя по пунктам меню: «Маркетинг» — «Настройка robot.txt». Главное не позволять достуформе регистрации во избежание появления дублей:
Disallow: /*register=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
- Django, yii2, cs cart и webasyst – особых отличий по установке и настройке нет.

Оригинальные способы применения robots.txt
- Некоторые фирмы размещают в роботсе вакансии для дизайнеров и оптимизаторов Сео;
- мастера-оптимизаторы публикуют в файле контакты для продвижения своих услуг;
- иногда разработчики шутят или оставляют на robots.txt целые картины из букв, цифр и символов;
- пишут советы по оптимизации конфигов;
Итог
Создание и редактирование файла robots.txt – это своего рода искусство. Заключается оно в таком создании правил индексации, — чтобы с одной стороны не ухудшить рейтинг ресурса, его доступность в общей базе конкретного поисковика — для пользователей, а с другой стороны – ограничить бессмысленные шатания поисковых ботов по директориям проекта.
apache2 — Как заставить Apache /robots.txt вести к файлу, независимо от домена?
спросил
Изменено 7 лет, 10 месяцев назад
Просмотрено 10 тысяч раз
Я запускаю локальный сервер со следующими URL-адресами:
foo.self бар.сам бла-бла.сам
Приведенный выше URL-адрес обрабатывается следующим оператором VirtualHost :
UseCanonicalName Выкл. имя_сервера Псевдоним сервера *.self VirtualDocumentRoot C:\Users\Foo\PhpstormProjects\%-2 <Каталог C:\Users\Foo\PhpstormProjects\*> Опционы Индексы FollowSymLinks включает ExecCGI MultiViews Отклонить заказ, разрешить Разрешить от всех Требовать все предоставленные
У каждого свои /robots.txt , но что мне нужно сделать, чтобы любой из URL-адресов возвращал одно и то же, независимо от того, что содержит их /robots.txt или даже если он не существует. Например, следующие URL-адреса:
- foo.self/robots.txt
- bar.self/robots.txt
- вздор.self/robots.txt
…вернет тот же текст:
Агент пользователя: * Запретить: /
Это без использования 301 Redirect или RewriteRule .
- apache
- apache2
- robots.txt
Просто создайте псевдоним для /robots.txt в настройках вашего хоста, указывающий на тот же файл. Плюс, возможно, для предоставления доступа требуется директива Location:
UseCanonicalName Выкл. имя_сервера Псевдоним сервера *.self Псевдоним /robots.txt C:\Somfolder\robots.txt <Расположение "C:\Somfolder\robots.txt"> Отклонить заказ, разрешить Разрешить от всех VirtualDocumentRoot C:\Users\Foo\PhpstormProjects\%-2 <Каталог C:\Users\Foo\PhpstormProjects\*> Опционы Индексы FollowSymLinks включает ExecCGI MultiViews Отклонить заказ, разрешить Разрешить от всех Требовать все предоставленные
Вы добавляете это к конфигурации всех хостов, все эти директивы Alias указывают на один и тот же файл. Файл C:\Somfolder\robots. — это «обычный» файл robots.txt, как вы его описали.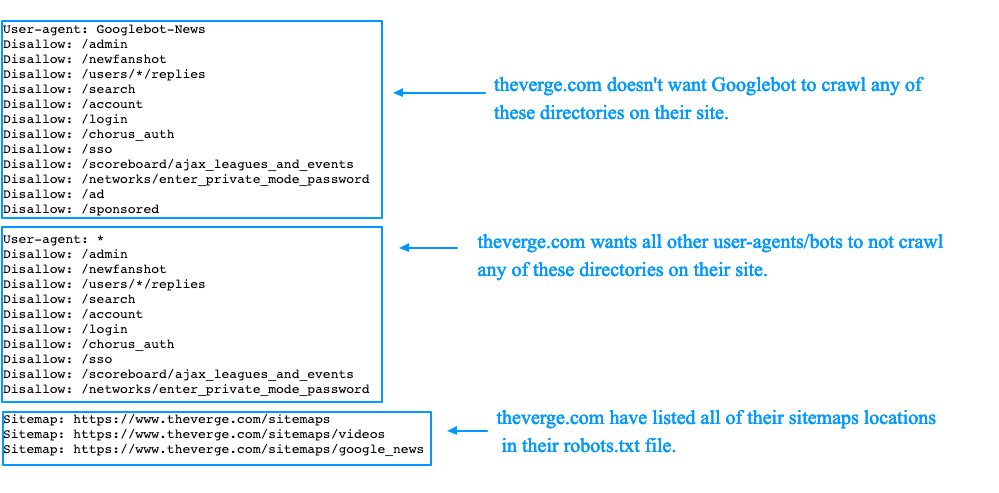 txt
txt
Вы можете упростить это, включив эту директиву в качестве шаблона. Таким образом, вы помещаете директиву в отдельный файл конфигурации и добавляете только директиву включения в конфигурации ваших хостов:
UseCanonicalName Выкл. имя_сервера Псевдоним сервера *.self Включить C:\path\to\file\robots.inc VirtualDocumentRoot C:\Users\Foo\PhpstormProjects\%-2 <Каталог C:\Users\Foo\PhpstormProjects\*> Опционы Индексы FollowSymLinks включает ExecCGI MultiViews Отклонить заказ, разрешить Разрешить от всех Требовать все предоставленные
Файл C:\path\to\file\robots.inc :
Псевдоним /robots.txt C:\Somfolder\robots.txt <Расположение "C:\Somfolder\robots.txt"> Отклонить заказ, разрешить Разрешить от всех
Обратите внимание, что я почти ничего не знаю о системах MS-Windows. Таким образом, примеры путей, которые я записал, могут не иметь смысла. Но вы должны понять 🙂
Таким образом, примеры путей, которые я записал, могут не иметь смысла. Но вы должны понять 🙂
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
Все, что вам нужно знать в 2023 году
Любой веб-мастер знает, что SEO в значительной степени не в ваших руках.
Несмотря на то, что вы можете создать сайт, следуя передовым методам SEO, чтобы получить наилучшие шансы на ранжирование, сканерам поисковых систем все равно необходимо найти и просканировать ваш сайт.
На самом деле у вас есть некоторый контроль над тем, как поисковые роботы индексируют ваш сайт с помощью файла Robots.txt, даже постранично.
Из этой статьи вы узнаете:
- Что такое файл robots.txt (и почему он важен для SEO)
- Объяснение синтаксиса
- Распространенные ошибки, которых следует избегать.
Начало работы с Robots.txt
Если вы хотите иметь право голоса в том, что роботы SEO просматривают на вашем сайте, вам понадобится файл robots.txt.
Хотя последнее слово в том, как Google обрабатывает ваш сайт, не обязательно остается за ним, оно может оказать сильное влияние на ваши результаты SEO. Позволяя вам влиять на то, как Google рассматривает ваш сайт, вы также можете влиять на их суждения.
Позволяя вам влиять на то, как Google рассматривает ваш сайт, вы также можете влиять на их суждения.
Итак, если вы хотите повысить частоту сканирования и эффективность поиска в Google, как создать файл robots.txt для SEO?
Возвращаемся к началу файлов robots.txt для разбивки:
- Что они на самом деле
- Где их найти
- Как создать свой
- Их синтаксис
- Преимущества их использования
- Как запретить против Noindex
- Ошибки, которых следует избегать
Начнем с изучения файла robots.txt.
Что такое файл robots.txt?
Когда Интернет был еще молод и полон потенциала, веб-разработчики придумали способ сканировать и индексировать новые страницы в Интернете.
Эти инструменты были названы сканерами, пауками или роботами. Вы, вероятно, слышали, что все они взаимозаменяемы.
Файл Robots.txt выглядит следующим образом:
Время от времени эти роботы отклонялись от того места, где они должны были находиться, и начинали сканировать и индексировать сайты, которые не предназначались для индексации — облегченные сайты, которые в настоящее время находятся под обслуживание.
Должно быть решение.
Создатель Aliweb, первой в мире поисковой системы, порекомендовал «дорожную карту», которая поможет роботам не сбиться с курса. 19 июня94, эта дорожная карта была доработана и названа «Протокол исключения роботов».
Как выглядит этот протокол при выполнении? Вот так (любезно предоставлено The Web Robots Pages):
Протокол устанавливает правила, которым должны следовать все боты, включая роботов Google. Однако некоторые темные роботы, такие как шпионское или вредоносное ПО, работают вне этих правил.
Хотите сами увидеть, каково это? Просто введите URL-адрес любого веб-сайта, а в конце добавьте «/robots.txt». Вот как выглядит файл Buffer:
User-agent: *
Disallow: /button
Disallow: /add
Disallow: /ajax
User-agent: bitlybot
Disallow: /
Карта сайта: https://buffer.com/карта сайта .xml
Так как это относительно небольшой сайт, в нем не так много всего.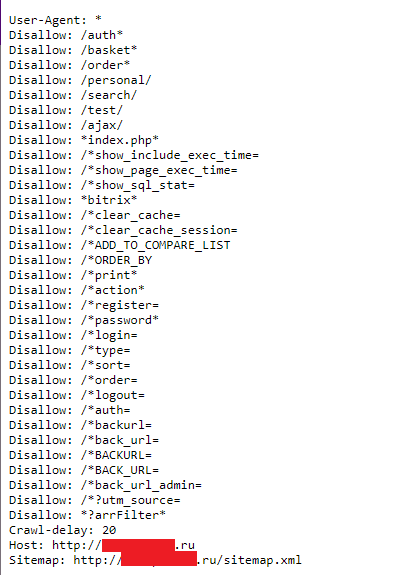 Например, введите то же самое в URL-адрес Google, и вы увидите гораздо больше.
Например, введите то же самое в URL-адрес Google, и вы увидите гораздо больше.
Где найти файл robots.txt
Файл robots.txt находится в корневом каталоге вашего сайта. Чтобы получить к нему доступ, откройте свою FTP cPanel, а затем выполните поиск в каталоге вашего сайта public_html.
В этих файлах немного, поэтому они не будут такими большими. Ожидайте увидеть максимум несколько сотен байтов.
После того, как вы откроете файл в текстовом редакторе, вы увидите некоторую информацию о карте сайта и терминах «User-Agent», «разрешить» и «запретить».
Вы также можете просто добавить /robots.txt в конец большинства URL-адресов, чтобы найти его:
Как создать файл robots.txt для SEO
простой текстовый файл, который достаточно прост для создания настоящим новичком.
Просто убедитесь, что у вас есть простой текстовый редактор, а затем откройте пустой лист, который вы сохраните как «robots.txt».
Затем войдите в свою cPanel и найдите папку public_html, как указано выше.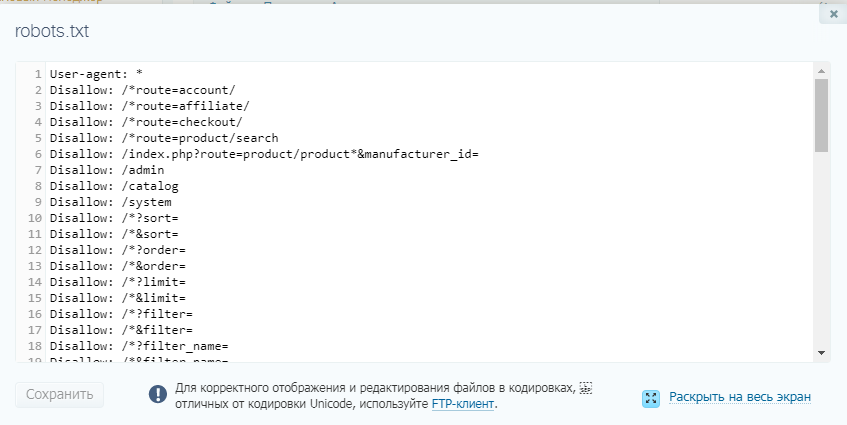 Открыв файл и вытащив папку, перетащите файл в папку.
Открыв файл и вытащив папку, перетащите файл в папку.
Теперь установите правильные разрешения для файла. Вы хотите настроить его так, чтобы вы, как владелец, были единственной стороной, имеющей разрешение на чтение, запись и редактирование этого файла. Вы должны увидеть код разрешения «0644».
Если вы не видите этот код, щелкните файл и выберите «Разрешение на доступ к файлу». Все сделано!
Объяснение синтаксиса robots.txt
Глядя на приведенный выше пример robots.txt, вы, скорее всего, увидите незнакомый синтаксис. Так что же означают эти слова? Давай выясним.
Файлы состоят из нескольких разделов, каждый из которых представляет собой «директиву». Каждая директива начинается с указанного пользовательского агента, который будет находиться под именем конкретного робота сканирования, на который направлен код.
Здесь у вас есть два варианта:
- Использовать подстановочный знак для одновременного обращения ко всем поисковым системам
- Адресуйте каждую поисковую систему отдельно, одну за другой
Когда сканер отправляется на сайт, он обращается к разделу, который с ним говорит. Каждая поисковая система будет обрабатывать файлы SEO robots.txt немного по-разному. Вы можете провести небольшое исследование, чтобы узнать больше о том, как Google или Bing обрабатывают вещи, в частности.
Каждая поисковая система будет обрабатывать файлы SEO robots.txt немного по-разному. Вы можете провести небольшое исследование, чтобы узнать больше о том, как Google или Bing обрабатывают вещи, в частности.
Директива агента пользователя
Видите часть «агент пользователя»? Это выделяет бота из толпы, по сути, вызывая его по имени.
Если ваша цель — указать одному из поисковых роботов Google, что делать на вашем сайте, начните с «User-agent: Googlebot».
Однако, чем больше конкретики вы получите, тем лучше. Обычно используется более одной директивы, поэтому при необходимости называйте каждого бота по имени.
Совет профессионала: Большинство поисковых систем используют более одного бота. Небольшое исследование подскажет вам, на каких ботов лучше всего ориентироваться.
Директива хоста
В настоящее время эта часть поддерживается только Яндексом, хотя вы можете увидеть заявления о том, что Google ее поддерживает.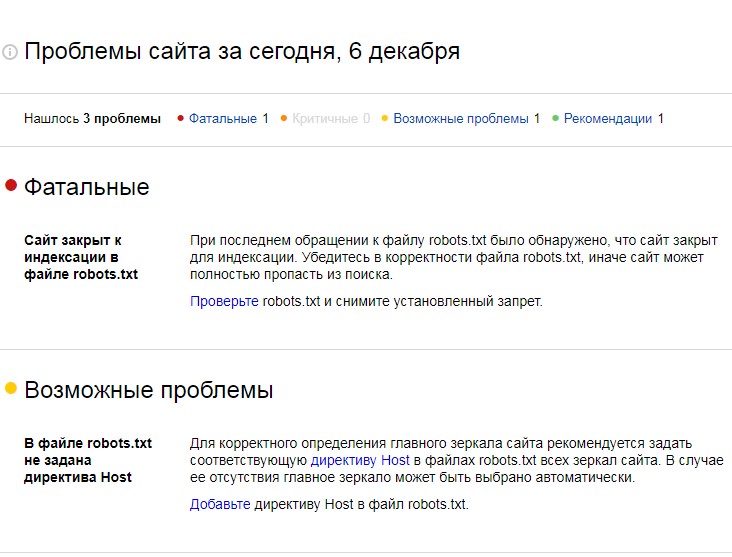
С помощью этой директивы вы можете определить, хотите ли вы показывать адрес www. перед URL вашего сайта, сказав что-то вроде этого:
Host:example.com
Поскольку мы можем только подтвердить, что Яндекс поддерживает это, не рекомендуется слишком полагаться на него.
Директива Disallow
Вторая строка в разделе — Disallow. Этот инструмент позволяет указать, какие части ваших веб-сайтов не должны сканироваться ботами. Если вы оставите запрет пустым, это, по сути, сообщает ботам, что это бесплатно для всех, и они могут сканировать, как им заблагорассудится.
Директива карты сайта
Директива карты сайта помогает вам сообщить поисковым системам, где они могут найти вашу XML-карту сайта, которая представляет собой цифровую карту, которая может помочь поисковым системам найти важные страницы на вашем сайте и узнать, как часто они обновляются.
Директива о задержке сканирования
Вы обнаружите, что поисковые системы, такие как Яндекс, Bing и Google, могут немного жадничать при сканировании, но вы можете некоторое время сдерживать их с помощью инициативы задержки сканирования.
Когда вы применяете строку «Crawl-delay:10», вы говорите ботам подождать десять секунд перед сканированием сайта или десять секунд между сканированиями.
Преимущества использования Robots.Txt для SEO
Теперь, когда мы рассмотрели основы файлов robots.txt и рассмотрели несколько способов использования директив, пришло время собрать ваш файл.
Хотя файл robots.txt не является обязательным аспектом успешного веб-сайта, существует множество ключевых преимуществ, о которых вам следует знать: в ваших личных папках, что значительно затрудняет их индексацию.

Естественно, вы хотите, чтобы поисковые системы просматривали наиболее важные страницы вашего сайта.
Если вы ограничите ботов определенными страницами, у вас будет лучший контроль над тем, какие страницы затем размещаются перед поисковиками в Google.
Только убедитесь, что вы никогда полностью не блокируете сканер от просмотра определенных страниц — это может привести к штрафу.
Disallow или Noindex
Если вы не хотите, чтобы поисковый робот обращался к странице, обычно вы должны использовать либо директиву disallow, либо директиву noindex. Однако в 2019 году Google объявил, что прекратил его поддержку вместе с несколькими другими правилами.
Однако в 2019 году Google объявил, что прекратил его поддержку вместе с несколькими другими правилами.
Тем, кто все еще хотел применить директиву noindex, пришлось проявить изобретательность. Вместо этого есть несколько вариантов на выбор:
- Тег Noindex — вы можете реализовать это как заголовок ответа HTTP с X-Robots-Tag, или вы можете создать тег, который вы можете реализовать в раздел. Просто помните, что если вы заблокировали ботов на этой странице, они, скорее всего, никогда не увидят тег и могут по-прежнему включать страницу в поисковую выдачу.
- Защита паролем . В большинстве случаев, если вы скрываете страницу за вводом пароля, ее не должно быть в индексе Google.
- Правило запрета . Когда вы добавляете определенные правила запрета, поисковые системы не будут сканировать страницу, и она не будет проиндексирована. Просто имейте в виду, что они все еще могут индексировать его на основе информации, которую они собирают с других страниц и ссылок.
- Коды состояния HTTP 404/410 — коды состояния 404 и 410 иллюстрируют веб-страницы, которых больше не существует. Как только такая страница будет полностью обработана один раз, она будет навсегда удалена из индекса Google.
- Search Console Удалить URL — этот инструмент не решит проблему индексации полностью, но временно удалит страницу.
Итак, что лучше? Noindex или правило запрета? Давайте углубимся.
Поскольку Google больше официально не поддерживает noindex, вам придется полагаться на альтернативы, перечисленные выше, или полагаться на проверенное правило запрета. Просто знайте, что правило запрета будет не таким эффективным, как стандартный тег noindex.
Хотя он блокирует сканирование этой страницы ботами, они все же могут собирать информацию с других страниц, а также внутренние и внешние ссылки, что может привести к отображению этой страницы в поисковой выдаче.
Полезная информация о SEO 🔍 Предоставьте нам свой сайт (или клиентов), и мы проанализируем SEO-элементы сайта (на странице, URL-адреса, конкурентов и т. д.), а затем организуем эти данные для действенного SEO-аудита.
д.), а затем организуем эти данные для действенного SEO-аудита.
Аудит моего SEO сейчас
5 ошибок robots.txt, которых следует избегать
Мы поговорили о том, что такое файл robots.txt, как его найти или создать, а также о различных способах его использования. Но мы не говорили о распространенных ошибках, которые допускают многие люди при использовании файлов robots.txt.
При неправильном использовании вы можете столкнуться с SEO-катастрофой. Избегайте этой участи, избегая следующих распространенных ошибок:
1. Блокирование полезного контента
Вы не хотите блокировать какой-либо полезный контент, который может помочь поисковым роботам и пользователям, ищущим ваш сайт в поисковых системах.
Если вы используете тег noindex или файл robots.txt для блокировки хорошего контента, вы повредите своим собственным результатам SEO.
Если вы заметили отставание в результатах, тщательно проверьте свои страницы на наличие правил запрета или тегов noindex.
2. Чрезмерное использование директивы Crawl-Delay
Слишком частое использование директивы Crawl-delay ограничивает количество страниц, которые могут сканировать боты.
Хотя это может не быть проблемой для крупных сайтов, небольшие сайты с ограниченным контентом могут снизить свои шансы на получение высокого рейтинга в поисковой выдаче из-за чрезмерного использования этих инструментов.
3. Предотвращение индексирования контента
Если вы хотите запретить ботам напрямую сканировать страницу, лучше всего запретить это.
Однако это не всегда сработает. Если на страницу была установлена внешняя ссылка, она все равно может пройти на страницу.
Кроме того, незаконные боты, такие как вредоносные программы, не подписываются на эти правила, поэтому они все равно будут индексировать контент.
4. Использование недопустимых регистров
Важно отметить, что файлы robots.txt чувствительны к регистру.
Создать директиву и использовать заглавную букву не получится.