что означает и как правильно использовать
В данной статье речь пойдет о самых популярных директивах Dissalow и Allow в файле robots.txt.
Disallow
Allow
Совместная интерпретация директив
Пустые Allow и Disallow
Специальные символы в директивах
Примеры совместного применения Allow и Disallow
Disallow
Disallow – директива, запрещающая индексирование отдельных страниц, групп страниц, их отдельных файлов и разделов сайта(папок). Это наиболее часто используемая директива, которая исключает из индекса:
- страницы с результатами поиска на сайте;
- страницы посещаемости ресурса;
- дубли;
- сервисные страницы баз данных;
- различные логи;
- страницы, содержащие персональные данные пользователей.
Примеры директивы Disallow в robots.
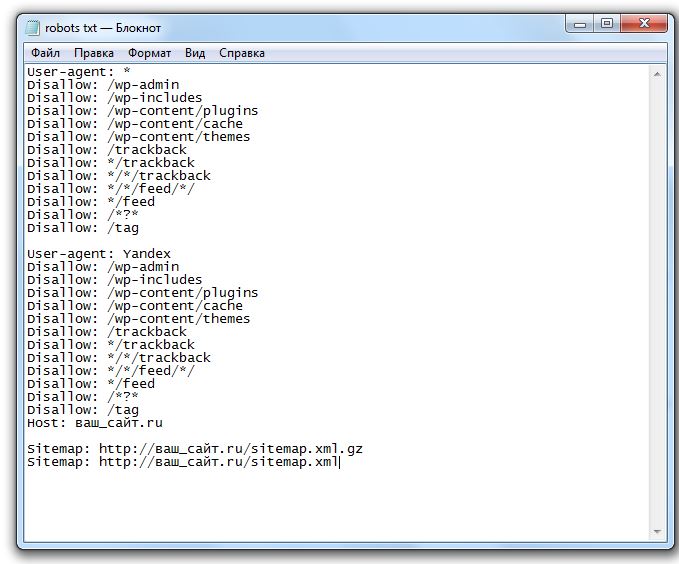
# запрет на индексацию всего веб-ресурса User-agent: Yandex Disallow: /
# запрет на обход страниц, адрес которых начинается с /category User-agent: Yandex Disallow: /category
# запрет на обход страниц, URL которых содержит параметры User-agent: Yandex Disallow: /page?
# запрет на индексацию всего раздела wp-admin User-agent: Yandex Disallow: /wp-admin
# запрет на индексацию подраздела plugins User-agent: Yandex Disallow: /wp-content/plugins
# запрет на индексацию конкретного изображения в папке img User-agent: Yandex Disallow: /img/images.jpg
# запрет индексации конкретного PDF документа User-agent: Yandex Disallow: /dogovor.pdf
# запрет на индексацию не только /my, но и /folder/my или /folder/my User-agent: Yandex Disallow: /*my
Правило Disallow работает с масками, позволяющими проводить операции с группами файлов или папок.
После данной директивы необходимо ставить пробел, а в конце строки пробел недопустим. В одной строке с Disallow через пробел можно написать комментарий после символа “#”.
В одной строке с Disallow через пробел можно написать комментарий после символа “#”.
Allow
В отличие от Disallow, данное указание разрешает индексацию определенных страниц, разделов или файлов сайта. У директивы Allow схожий синтаксис, что и у Disallow.
Хотя окончательное решение о посещении вашего сайта роботами принимает поисковая система, данное правило дополнительно призывает их это делать.
Примеры Allow в robots.txt:
# разрешает индексацию всего каталога /img/ User-agent: Yandex Allow: /img/
# разрешает индексацию PDF документа User-agent: Yandex Allow: /prezentaciya.pdf
# открывает доступ к индексированию определенной HTML страницы User-agent: Yandex Allow: /page.html
# разрешает индексацию по маске *your User-agent: Yandex Allow: /*your
# запрещает индексировать все, кроме страниц, начинающихся с /cgi-bin User-agent: Yandex Allow: /cgi-bin Disallow: /
Для директивы применяются аналогичные правила, что и для Disallow.
Совместная интерпретация директив
Поисковые системы используют Allow и Disallow из одного User-agent блока последовательно, сортируя их по длине префикса URL, начиная от меньшего к большему. Если для конкретной страницы веб-сайта подходит применение нескольких правил, поисковый бот выбирает последний из списка. Поэтому порядок написания директив в robots никак не сказывается на их использовании роботами.
Пример robots.txt написанный оптимизатором:
User-agent: Yandex Allow: / Allow: /catalog/phones Disallow: /catalog
Пример отсортированного файл robots.txt поисковой системой:
User-agent: Yandex Allow: / Disallow: /catalog Allow: /catalog/phones # запрещает посещать страницы, начинающиеся с /catalog, # но разрешает индексировать страницы, начинающиеся с /catalog/phones
Пустые Allow и Disallow
Когда в директивах отсутствуют какие-либо параметры, поисковый бот интерпретирует их так:
# то же, что и Allow: / значит разрешает индексировать весь сайт User-agent: Yandex Disallow:
# не учитывается роботом User-agent: Yandex Allow:
Специальные символы в директивах
В параметрах запрещающей директивы Disallow и
разрешающей директивы Allow можно применять специальные символы “$” и “*”, чтобы задать
конкретные регулярные выражения.
Специальный символ “*” разрешает индексировать все страницы с параметром, указанным в директиве. К примеру, параметр /katalog* значит, что для ботов открыты страницы /katalog, /katalog-tovarov, /katalog-1 и прочие. Спецсимвол означает все возможные последовательности символов, даже пустые.
User-agent: Yandex
Disallow: /cgi-bin/*.aspx # запрещает /cgi-bin/example.aspx
# и /cgi-bin/private/test.aspx
Disallow: /*private # запрещает не только /private
# но и /cgi-bin/privateПо стандарту в конце любой инструкции, описанной в Robots, указывается специальный символ “*”, но делать это не обязательно.
Пример:
User-agent: Yandex
Disallow: /cgi-bin* # закрывает доступ к страницам
# начинающимся с /cgi-bin
Disallow: /cgi-bin # означает то же самоеДля отмены данного спецсимвола в конце директивы применяют другой спецсимвол – “$”.
Пример:
User-agent: Yandex
Disallow: /example$ # закрывает /example,
# но не запрещает /example. html
User-agent: Yandex
Disallow: /example # запрещает и /example
# и /example.html
html
User-agent: Yandex
Disallow: /example # запрещает и /example
# и /example.htmlНа заметку. Символ “$” не запрещает прописанный в конце “*”.
Пример:
User-agent: Yandex
Disallow: /example$ # закрывает только /example
Disallow: /example*$ # аналогично, как Disallow: /example
# запрещает и /example.html и /exampleБолее сложные примеры:
User-agent: Yandex
Allow: /obsolete/private/*.html$ # разрешает HTML файлы
# по пути /obsolete/private/...
Disallow: /*.php$ # запрещает все *.php на сайте
Disallow: /*/private/ # запрещает все подпути содержащие /private/
# но Allow выше отменяет часть запрета
Disallow: /*/old/*.zip$ # запрещает все .zip файлы, содержащие в пути /old/
User-agent: Yandex
Disallow: /add.php?*user=
# запрещает все скрипты add.php? с параметром userПримеры совместного применения Allow и Disallow
User-agent: Yandex Allow: / Disallow: / # разрешено индексировать весь веб-ресурс User-agent: Yandex Allow: /$ Disallow: / # запрещено включать в индекс все, кроме главной страницы User-agent: Yandex Disallow: /private*html # заблокирован и /private*html, # и /private/test.html, и /private/html/test.aspx и т.п. User-agent: Yandex Disallow: /private$ # запрещается только /private User-agent: * Disallow: / User-agent: Yandex Allow: / # так как робот Яндекса # выделяет записи по наличию его названия в строке User-agent: # тогда весь сайт будет доступен для индексирования

Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Запрет индексации в robots.txt | REG.RU
Чтобы убрать весь сайт или отдельные его разделы и страницы из поисковой выдачи Google, Яндекс и других поисковых систем, их нужно закрыть от индексации. Тогда контент не будет отображаться в результатах поиска. Рассмотрим, с помощью каких команд можно выполнить в файле robots.txt запрет индексации.
Зачем нужен запрет индексации сайта через robots.txt
Первое время после публикации сайта о нем знает только ограниченное число пользователей. Например, разработчики или клиенты, которым компания прислала ссылку на свой веб-ресурс. Чтобы сайт посещало больше людей, он должен попасть в базы поисковых систем.
Например, разработчики или клиенты, которым компания прислала ссылку на свой веб-ресурс. Чтобы сайт посещало больше людей, он должен попасть в базы поисковых систем.
Чтобы добавить новые сайты в базы, поисковые системы сканируют интернет с помощью специальных программ (поисковых роботов), которые анализируют содержимое веб-страниц. Этот процесс называется индексацией.
После того как впервые пройдет индексация, страницы сайта начнут отображаться в поисковой выдаче. Пользователи увидят их в процессе поиска информации в Яндекс и Google — самых популярных поисковых системах в рунете. Например, по запросу «заказать хостинг» в Google пользователи увидят ресурсы, которые содержат соответствующую информацию:
Однако не все страницы сайта должны попадать в поисковую выдачу. Есть контент, который интересен пользователям: статьи, страницы услуг, товары. А есть служебная информация: временные файлы, документация к ПО и т. п. Если полезная информация в выдаче соседствует с технической информацией или неактуальным контентом — это затрудняет поиск нужных страниц и негативно сказывается на позиции сайта.
Кроме отдельных страниц и разделов, веб-разработчикам иногда требуется убрать весь ресурс из поисковой выдачи. Например, если на нем идут технические работы или вносятся глобальные правки по дизайну и структуре. Если не скрыть на время все страницы из поисковых систем, они могут проиндексироваться с ошибками, что отрицательно повлияет на позиции сайта в выдаче.
Для того чтобы частично или полностью убрать контент из поиска, достаточно сообщить поисковым роботам, что страницы не нужно индексировать. Для этого необходимо отключить индексацию в служебном файле robots.txt. Файл robots.txt — это текстовый документ, который создан для «общения» с поисковыми роботами. В нем прописываются инструкции о том, какие страницы сайта нельзя посещать и анализировать, а какие — можно.
Прежде чем начать индексацию, роботы обращаются к robots.txt на сайте. Если он есть — следуют указаниям из него, а если файл отсутствует — индексируют все страницы без исключений. Рассмотрим, каким образом можно сообщить поисковым роботам о запрете посещения и индексации страниц сайта. За это отвечает директива (команда) Disallow.
Рассмотрим, каким образом можно сообщить поисковым роботам о запрете посещения и индексации страниц сайта. За это отвечает директива (команда) Disallow.
Как запретить индексацию сайта
О том, где найти файл robots.txt, как его создать и редактировать, мы подробно рассказали в статье. Если кратко — файл можно найти в корневой папке. А если он отсутствует, сохранить на компьютере пустой текстовый файл под названием robots.txt и загрузить его на хостинг. Или воспользоваться плагином Yoast SEO, если сайт создан на движке WordPress.
Чтобы запретить индексацию всего сайта:
- 1.
Откройте файл robots.txt.
- 2.
Добавьте в начало нужные строки.
- Чтобы закрыть сайт во всех поисковых системах (действует для всех поисковых роботов):
User-agent: * Disallow: /
- Чтобы запретить индексацию в конкретной поисковой системе (например, в Яндекс):
User-agent: Yandex Disallow: /
- Чтобы закрыть от индексации для всех поисковиков, кроме одного (например, Google)
User-agent: * Disallow: / User agent: Googlebot Allow: /
 org/HowToStep»>
3.
org/HowToStep»>
3.Сохраните изменения в robots.txt.
Готово. Ресурс пропадет из поисковой выдачи выбранных ПС.
Запрет индексации папки
Гораздо чаще, чем закрывать от индексации весь веб-ресурс, веб-разработчикам требуется скрывать отдельные папки и разделы.
Чтобы запретить поисковым роботам просматривать конкретный раздел:
- 1.
Откройте robots.txt.
- 2.
Укажите поисковых роботов, на которых будет распространяться правило. Например:
- Все поисковые системы:
User-agent: *
— Запрет только для Яндекса:
User-agent: Yandex
- 3.
Задайте правило Disallow с названием папки/раздела, который хотите запретить:
Disallow: /catalog/
Где вместо catalog — укажите нужную папку.

- 4.
Сохраните изменения.
Готово. Вы закрыли от индексации нужный каталог. Если требуется запретить несколько папок, последовательно пропишите для каждой директиву Disallow.
Как закрыть служебную папку wp-admin в плагине Yoast SEO
Как закрыть страницу от индексации в robots.txt
Если нужно закрыть от индексации конкретную страницу (например, с устаревшими акциями или неактуальными контактами компании):
- 1.
Откройте файл robots.txt на хостинге или используйте плагин Yoast SEO, если сайт на WordPress.
- 2.
Укажите, для каких поисковых роботов действует правило.
- 3.

Задайте директиву Disallow и относительную ссылку (то есть адрес страницы без домена и префиксов) той страницы, которую нужно скрыть. Например:
User-agent: * Disallow: /catalog/page.html
Где вместо catalog — введите название папки, в которой содержится файл, а вместо page.html — относительный адрес страницы.
- 4.
Сохраните изменения.
Готово. Теперь указанный файл не будет индексироваться и отображаться в результатах поиска.
Помогла ли вам статья?
Да
раз уже
помогла
страниц запрещены в robots.txt, но проиндексированы Google. Как это возможно?
спросил
Изменено 3 года, 8 месяцев назад
Просмотрено 1к раз
Проблемы с отображением моего веб-сайта в Google Search Console. Проверьте следующее сообщение Google в GSC:
Проверьте следующее сообщение Google в GSC:
Проиндексировано, но заблокировано robots.txt
Я запрещаю страницу своей учетной записи ( https://www.joujou.com.au/account/) в robots.txt, но она индексируется Google. Можно ли проиндексировать страницу в Google, если эта страница уже запрещена в файле robots.txt?
- google-search
- robots.txt
Robots.txt просто не позволяет роботу Googlebot просматривать содержимое страницы. Однако если кто-то ссылается на вашу страницу, даже если Google не видит содержимого, Google знает, что по этому целевому URL-адресу есть веб-страница.
Если на страницу ссылается достаточное количество людей, Google может принять решение о ее добавлении и отображении в индексе. Много раз Google будет собирать контекст этой веб-страницы из контента, который ссылается на нее, и якорного текста ссылок.
Если вы действительно не хотите, чтобы URL-адрес был в индексе Google, есть 2 рекомендуемых подхода.
- Добавьте метатег robots на страницу с помощью команды NOINDEX. примечание: Вам нужно будет разрешить Google сканировать URL-адрес, чтобы он увидел команду NOINDEX. Поэтому вам придется отменить команду disallow в файле robots.txt 9.0022
- Добавить базовую HTTP-аутентификацию на страницу
Любой подход гарантирует, что Google не добавит URL-адрес в индекс. Однако время от времени Google по-прежнему будет сканировать URL-адрес.
Для большего контекста представитель Google Джон Мюллер недавно заявил об этом в Твиттере.
… robots.txt обязательно заблокирует сканирование контента (если запрещено), хотя это и не обязательно индексация URL-адресов. [однако] без содержание, трудно занять 9 место0005
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
robots.
 txt, чтобы запретить все страницы, кроме одной? Они переопределяют и каскадируют?
txt, чтобы запретить все страницы, кроме одной? Они переопределяют и каскадируют?спросил
Изменено 5 лет, 5 месяцев назад
Просмотрено 48 тысяч раз
Я хочу, чтобы сканировалась одна страница моего сайта и никакие другие.
Кроме того, если это отличается от ответа выше, я также хотел бы знать синтаксис для запрета всего, кроме корня (индекса) веб-сайта.
# robots.txt для http://example.com/ Пользовательский агент: * Запретить: /style-guide Запретить: /всплеск Запретить: /etc Запретить: /etc Запретить: /etc Запретить: /etc Запретить: /etc
Или можно так?
# robots.txt для http://example.com/ Пользовательский агент: * Запретить: / Разрешить: /в стадии строительства
Также я должен упомянуть, что это установка WordPress, поэтому, например, «в разработке» установлено на первой странице. Так что в этом случае он действует как индекс.
Так что в этом случае он действует как индекс.
Я думаю, что мне нужно, чтобы http://example.com ползали, но не другие страницы.
# robots.txt для http://example.com/ Пользовательский агент: * Запретить: /*
Означает ли это, что что-либо после корня запрещено?
- robots.txt
Самый простой способ разрешить доступ только к одной странице:
User-agent: * Разрешить: /в стадии строительства Запретить: /
В исходной спецификации robots.txt указано, что сканеры должны читать robots.txt сверху вниз и использовать первое правило соответствия. Если вы сначала поставите Disallow , то многие боты увидят, что они ничего не могут сканировать. Поставив Сначала разрешить , те, кто применяет правила сверху вниз, увидят, что они могут получить доступ к этой странице.
Правила выражения просты: выражение Disallow: / говорит «запретить все, что начинается с косой черты «. Так что значит все на сайте.
Так что значит все на сайте.
Ваш Disallow: /* означает одно и то же для Googlebot и Bingbot, но боты, которые не поддерживают подстановочные знаки, могут увидеть /* и подумать, что вы имели в виду буквальное * . Таким образом, они могли предположить, что сканирование /*foo/bar.html — это нормально.
Если вы просто хотите просканировать http://example.com , но ничего больше, вы можете попробовать:
Разрешить: /$ Запретить: /
$ означает «конец строки», как и в регулярных выражениях. Опять же, это будет работать для Google и Bing, но не будет работать для других сканеров, если они не поддерживают подстановочные знаки.
4
Если вы войдете в Инструменты Google для веб-мастеров, на левой панели перейдите к сканированию, затем перейдите к Просмотреть как Google. Здесь вы можете проверить, как Google будет сканировать каждую страницу.