Запретить /feed и /trackback на роботах wordpress, но Google все еще индексирует
У меня проблема с моим сайтом и файлом robots.txt. Я получил запрет на /feed и /trackback url на моих роботах, но по какой-то причине я все еще получаю на моем Google Webmaster url, как http://www.mydomain.net/year/month/post.html/feed и http://www.mydomain.net/year/month/post.html/trackback, и я не знаю, как правильно исправить. После этого случившегося мой сайт пошел вниз по визитам.
Кто-нибудь может мне помочь, пожалуйста?
С уважением
Это мой robots.txt
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Allow: /wp-content/uploads/
Disallow: /trackback
Disallow: /?ref=
Disallow: /feed
Disallow: /comments/feed
Disallow: /feed/$
Disallow: /*/feed/$
Disallow: /*/feed/rss/$
Disallow: /*/trackback/$
Disallow: /*/*/feed/$
Disallow: /*/*/feed/rss/$
Disallow: /*/*/trackback/$
Disallow: /*/*/*/feed/$
Disallow: /*/*/*/feed/rss/$
Disallow: /*/*/*/trackback/$
Disallow: /?s=
Disallow: /search
User-agent: Googlebot-Image
Allow: /
Sitemap: http://www.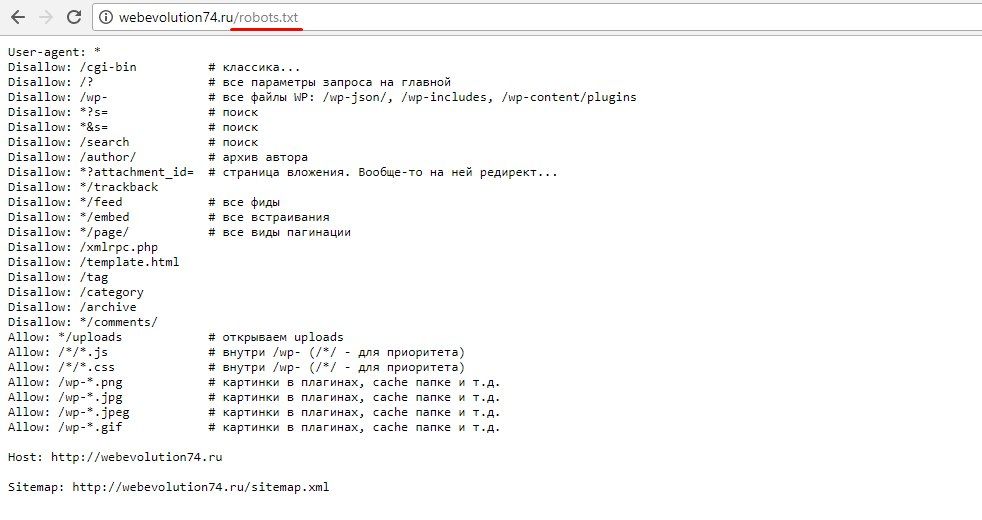
mydomain.net/sitemap.xml
Поделиться Источник user2143527 29 марта 2013 в 12:14
2 ответа
- SEO хаос от изменения файла robots.txt на сайте WordPress
Недавно я отредактировал файл robots.txt на своем сайте с помощью плагина wordpress. Однако с тех пор, как я это сделал, google, похоже, удалил мой сайт со своей страницы поиска. Я был бы признателен, если бы мог получить экспертное мнение о том, почему это так, и возможное решение. Сначала я…
- Как запретить Google индексировать сайт?
Мой клиент попросил меня запретить Google bot индексировать сайт, поэтому я добавил следующую мету в тег head моего основного слоя, который (теоретически) является заголовком всех страниц: <meta name=googlebot content=noindex> Это должно помешать Google индексировать любые страницы, однако.
1
ваш файл robtos, кажется, в порядке, я думаю, вы неправильно поняли, как его использовать. Вы не можете предотвратить индексацию определенной папки, добавив регулярное выражение в файл робота, потому что robots.txt управляет только активностью искателя. Поэтому для того, чтобы предотвратить индексацию определенных страниц, вы должны использовать мета-тег robots.
Поделиться user3310736 14 февраля 2014 в 15:17
0
Я думаю, что ваша проблема заключается в использовании подстановочного знака
Disallow: /feed/
То же самое относится и ко всем другим видам использования дикого символа.
Кроме того, дикие символы принимаются не всеми поисковыми системами.
Вы можете попробовать одну из синтаксических шашек robots. txt для получения дополнительной помощи.
txt для получения дополнительной помощи.
Поделиться Roy 11 апреля 2013 в 19:23
Похожие вопросы:
Роботы текст, wordpress — каталог блоков
Реализация Trackback: rel=»trackback» vs RDF
Я хочу, чтобы мое приложение Rails анализировало внешние веб-сайты для трекбэка URL, но я не совсем уверен, стоит ли мне просто искать <a href=url rel=trackback>Text</a> или следуйте…
WordPress Robots.txt имеет ли значение /feed?
У меня есть вопрос вопросы, касающиеся SEO, Robots.txt и wordpress Вот как выглядит мой robots.txt: User-agent: * Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow:.
SEO хаос от изменения файла robots.txt на сайте WordPress
Недавно я отредактировал файл robots.txt на своем сайте с помощью плагина wordpress. Однако с тех пор, как я это сделал, google, похоже, удалил мой сайт со своей страницы поиска. Я был бы…
Как запретить Google индексировать сайт?
Мой клиент попросил меня запретить Google bot индексировать сайт, поэтому я добавил следующую мету в тег head моего основного слоя, который (теоретически) является заголовком всех страниц: <meta…
Google дублирует теги заголовков и WordPress
robot.txt заставил Google прекратить индексировать мой сайт?
Это мой робот: User-agent: * Disallow: /feed/ Disallow: /trackback/ Disallow: /wp-admin/ Disallow: /wp-content/ Disallow: /wp-includes/ Disallow: /xmlrpc. php Disallow: /wp- Sitemap:…
php Disallow: /wp- Sitemap:…
Url заблокировано robots.txt сообщением в Google Webmaster
У меня есть сайт wordpress в корневом домене. Теперь я добавил форум в подпапку как mydomain/forum , который делает sitemap следующим образом: mydomain/forum/sitemap_index.xml. Отправляя этот…
Google не индексирует мои изображения (внешний сервер для изображений)
Мы пытаемся заставить наши изображения на www.csselectronics.com правильно индексироваться в google. К сожалению, Google Search Console, похоже, индексирует только 3 изображения, в то время как еще…
Запретить поисковым системам индексировать мой api
У меня есть мой api в api.website.com, который не требует аутентификации. Я ищу способ, чтобы запретить Google индексировать мой api. Есть ли способ сделать это? У меня уже есть запрет в моих…
Требования к RSS для рекомендательной системы Mail.Ru — Help Mail.ru. Рекомендательная система
Рекомендации
Публикации, которые попадают в RSS, должны быть в свободном доступе. Те материалы, для просмотра которых требуется регистрация или плата, в рекомендательную систему не попадают.
Те материалы, для просмотра которых требуется регистрация или плата, в рекомендательную систему не попадают.
-
Материал для рекомендательной системы должен содержать хотя бы одно изображение, которое размещается с помощью элемента enclosure. Ширина изображения должна быть не менее 400 пикселей.
-
Убедитесь, что в robots.txt нет директивы Disallow, которая запрещает адрес RSS, в противном случае публикацию не увидит наш робот «Mozilla/5.0 (compatible; Linux x86_64; Mail.RU_Bot/2.0; +http://go.mail.ru/help/robots)». Разрешить можно директивой Allow RSS_URL. Пример: если в robots.txt прописана директива Disallow /feed, то робот не сможет проиндексировать страницу example.ru/feed/some_url/rss.xml Чтобы разрешить индексацию, добавьте директиву Allow /feed/some_url/rss.xml.
- Убедитесь, что RSS открыта для доступа с IP адресов 95.163.255.0-95.163.255.255
- Убедитесь, что ваш провайдер не блокирует нашего робота.

HTTP/1.1 200 OKБольше про поисковых роботов$ curl -I —user-agent «Mozilla/5.0 (compatible; Linux x86_64; Mail.RU_Bot/2.0; +http://go.mail.ru/help/robots)» «YOU_URL»
-
Для более корректной работы старайтесь держать в RSS только свежие публикации (за последние 2-5 дней). Из-за нагрузки, которую создают устаревшие публикации, усложняется работа RSS.
Совет: Чтобы удостовериться, что RSS размечена правильно — проверьте ее нашим валидатором.
Если кроме нижеперечисленных тэгов в Вашей RSS есть другие тэги (например, content:encoded, etc.
), то это никак не помешает нашим парсерам вытащить контент из такой RSS. Ниже мы указали минимальные требования к RSS, которые могут попасть в нашу рекомендательную систему.
Описание источника
Элементы со строго ограниченным набором значений могут содержать только варианты, которые указаны в таблице. Любое другое значение приведет к ошибке.
Обязательные элементы отмечены значком .
|
<?xml version=»1.0″ encoding=»UTF-8″?> |
 com/logo_200x200.png</url>
com/logo_200x200.png</url>Описание публикации
Элементы, с помощью которых описывается публикация, находятся внутри item.
Элементы со строго ограниченным набором значений могут содержать только варианты, которые указаны в таблице. Любое другое значение приведет к ошибке.
Обязательные элементы отмечены значком .
| Элемент | Описание |
| title | Заголовок публикации. От 3 до 1000 символов. |
| link |
URL публикации, данные которой транслируются в RSS. Ссылка в RSS должна полностью повторять ссылку на сайте и не содержать лишних элементов. Например, utm метки не являются необходимыми. |
| amplink | Ссылка на AMP-версию материала. |
| pubDate |
Дата и время публикации в формате RFC822, ( «Sun, 08 Jan 2017 13:00:00 +03000»). |
| enclosure |
Описание изображений, аудио- и видеофайлов. Может быть единственным упоминанием медиаконтента. Если в материале есть много вариантов одной иллюстрации, которые отличаются друг от друга только размером, то в этот элемент эта иллюстрация прописывается единожды и в нем указывается URL изображения наибольшего размера. Если в тегах enclosure указано несколько разных иллюстраций — берётся самая первая по порядку. |
| description | Краткая аннотация. От 5 до 10000 символов. |
| content:encoded | Контент публикации — полный текст и медиаматериалы.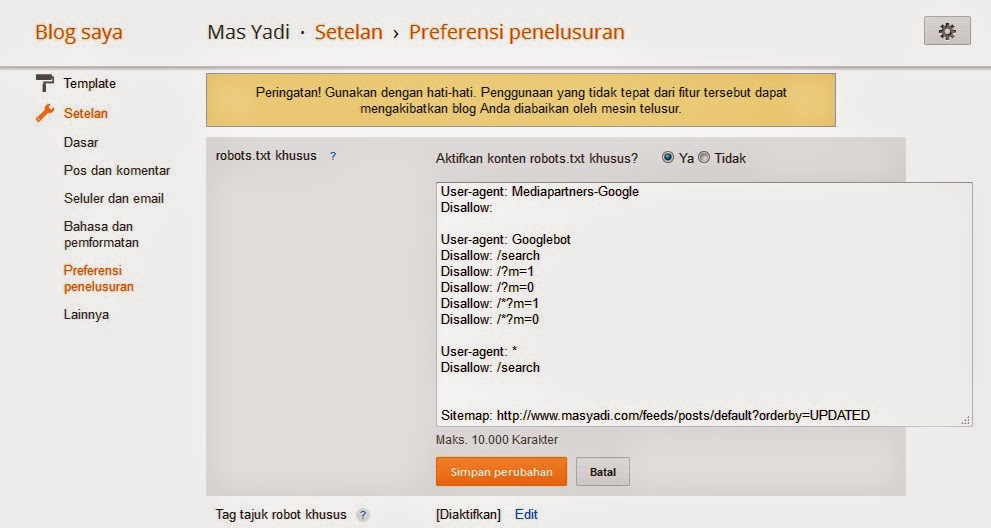 |

|
<item> |
Пример правильно оформленной RSS
|
<?xml version=»1. <rss version=»2.0″ xmlns:content=»http://purl.org/rss/1.0/modules/content/»> <channel> <title>Криптота</title> <link>http://example.com/</link> <description> Всё о криптовалютах: покупка, продажа, биржи и новости. </description> <language>ru</language> <item> <title>На марсе нашли воду</title> <link>http://example.com/2018/05/02/mars-water</link> <amplink>http://amp.example.com/2018/05/02/mars-waterr</amplink> <pubDate>Sun, 17 Aug 2018 16:10:00 +0300</pubDate> <enclosure url=»http://example. <enclosure url=»http://example.com/2018/05/02/pic2.jpg» type=»image/jpeg»/> <enclosure url=»http://example.com/2018/05/02/video/42420″ type=»video/x-ms-asf»/> <description> <![CDATA[ Давайте ваши шутки про картошку: на красной планете обнаружили ледник. Теперь учёные убеждены в наличии воды на поверхности планеты.. ]]> </description> </item> </channel> </rss> |
 0″ encoding=»UTF-8″?>
0″ encoding=»UTF-8″?> com/2018/05/02/pic1.jpg» type=»image/jpeg»/>
com/2018/05/02/pic1.jpg» type=»image/jpeg»/>robots.txt для WordPress
Окт 16, 2009 | 1 views
Надоели ошибки при индексации, попробую все-таки прописать правильный robots.txt для WordPress. Основные ошибки появляются при индексации feed, rss лент, /xmlrpc. php?rsd… при этом сообщая что «Формат документа не поддерживается». Особенно многочислены ошибки когда есть возможность подписаться на ленту комментариев отдельного поста, на отдельный тег или отдельную рубрику.Всего проще воспользоваться поиском и найти готовый для своих нужд файл:
php?rsd… при этом сообщая что «Формат документа не поддерживается». Особенно многочислены ошибки когда есть возможность подписаться на ленту комментариев отдельного поста, на отдельный тег или отдельную рубрику.Всего проще воспользоваться поиском и найти готовый для своих нужд файл:
User-agent: *
Disallow: /cgi-bin
# запрещаем индексацию системных папок
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
# запрещаем индексацию страницы входа и регистрации
Disallow: /wp-login.php
Disallow: /wp-register.php
# запрещаем индексацию трекбековDisallow: /trackback
Disallow: */trackback
Disallow: /xmlrpc.php
# запрещаем индексацию архива автора
Disallow: /author*
# запрещаем индексацию постраничных комментариев
Disallow: */comments
Disallow: */comment-page*
# запрещаем индексацию результатов поиска и другого возможного «мусора»
Disallow: /*?*
Disallow: /*?
# разрешаем индексацию вложений, особо мнительным можно запретить папку wp-content целиком
Allow: /wp-content/uploadsUser-agent: yandex
Disallow: /cgi-bin
# запрещаем индексацию системных папок
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
# запрещаем индексацию архива автора
Disallow: /author*
# запрещаем индексацию страницы входа и регистрации
Disallow: /wp-login.php
Disallow: /wp-register.php
# запрещаем индексацию трекбеков, rss-ленты
Disallow: /trackback
Disallow: /feed
Disallow: /rss
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: /xmlrpc.php
# запрещаем индексацию постраничных комментариев
Disallow: */comments
Disallow: */comment-page*
# запрещаем индексацию результатов поиска и другого возможного «мусора»
Disallow: /*?*
Disallow: /*?
# разрешаем индексацию вложений, особо мнительным можно запретить папку wp-content целиком
Allow: /wp-content/uploads
# прописываем директиву Host
Host: mysite.ruUser-agent: Googlebot-Image
Allow: /
# разрешаем индексировать изображенияUser-agent: YandexBlog
Allow: /
# разрешаем индексировать rss-ленту
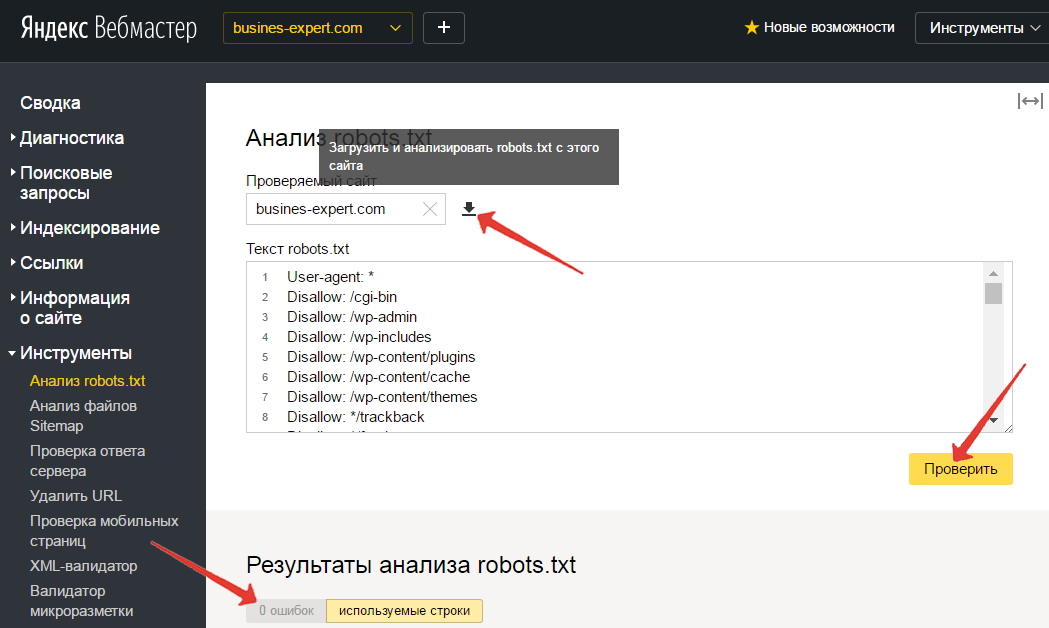
Чтобы проверить правильность обработки яшей, можно воспользоваться сервисом Яндекса «вебмастер» -> «Анализ robots.txt»
Microsoft Security EssentialsUser-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т. к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.
к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest. xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ — для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ — для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.
xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ — для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ — для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest. xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
Sitemap: https://freshmemory.ru/sitemap_index.xml
Host: https://freshmemory.ru/
xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
Sitemap: https://freshmemory.ru/sitemap_index.xml
Host: https://freshmemory.ru/
title | Заголовок. |
link | URL статьи, данные которой транслируются в ленте RSS. Ссылка в RSS должна полностью (с точностью до знака) дублировать ссылку на сайте.
|
pdalink | Ссылка на версию, адаптированную для мобильных устройств. |
amplink | Ссылка на AMP-версию. |
guid | Уникальный идентификатор статьи. Если вы хотите повторно отправить статью в ленту RSS, укажите ее изначальный |
media:rating | Возрастной рейтинг. В описании этого элемента используйте только значения, перечисленные ниже. Любое другое значение приведет к ошибке ленты.
|
pubDate | Дата и время публикации в формате RFC822: Wed, 02 Oct 2002 15:00:00 +0300. Если элемента нет, Дзен будет считать дату загрузки ленты RSS датой публикации. |
author | Имя автора. |
category | Тематика.
|
enclosure | Описание изображений, аудио- и видеофайлов в материале. Может быть единственным упоминанием медиаконтента или дублировать элементы Каждому элементу Если в материале несколько вариантов одной иллюстрации, которые отличаются только размером, укажите элемент |
description | Краткое содержание. |
content:encoded | Полный текст (рекомендуемый объем — не менее 300 знаков с пробелами) или видеоролик. Содержит элементы для размещения медиаконтента. |
 Например, эти URL не совпадают:
Например, эти URL не совпадают:


Как в wordpress исключить страницы из поиска. Настройка robots.txt
Периодически перед веб-мастерами встает вопрос, как в WordPress исключить страницы из поиска. Это нужно для того, чтобы поисковые машины не индексировали технические страницы, персональные данные — информацию, которая не должна находиться в свободном доступе по разным причинам.
Индексация страниц и поисковая выдача
Как правило, процесс индексации Гугла означает, что бесчисленные армии ботов поисковика заходят на страницы сайта, исследуют их и если находят новые, то копируют и добавляют себе в базу данных.
Чтобы нежелательные для всеобщего обозрения материалы с сайтов не оказались в открытом доступе, сканирующим роботам следует дать установку, что индексировать, а что нет. После чего любой пользователь по ключевым словам сможет найти ссылки с искомой информацией.
Благодаря грамотной оптимизации и правильно подобранным ключевикам, сайты могут претендовать на высокие ранги поисковой выдачи. Значит на сайт будут приходить новые пользователи, которые могут стать вашими подписчиками или покупателями, в зависимости от того, на чем вы зарабатываете.
Кстати, если у вашего сайта индексируются не все страницы, прочитайте статью о том, как избавиться от этой проблемы. Ранее мы разбирали этот вопрос.
Почему так важно ограничить индексацию страниц?
На каждом сайте присутствуют материалы или целые категории, которые небходимо исключить из поиска. К примеру данные, указывающие на версию ядра Вордпресс, плагинов и тем. Благодаря этой информации злоумышленникам будет легче найти уязвимости системы безопасности. О том, как улучшить защиту сайта и как удалить версию скрипта в wordpress мы говорили подробней в предыдущих статьях. В отсутствие аутентификации и кодов доступа приватные материалы рискуют стать достоянием общественности. Но если поисковым роботам не дать четкое направление, то они будут сканировать на вашем сайте все подряд, без разбора.
Около 20 лет назад злоумышленники использовали поисковик, чтобы найти информацию о банковских картах с сайтов.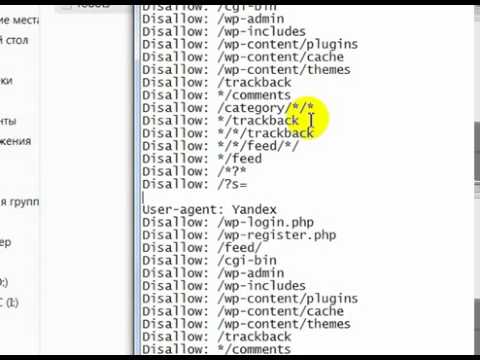 С помощью этой уязвимости хакеры похищали данные клиентов прямо с сайтов интернет-магазинов.
С помощью этой уязвимости хакеры похищали данные клиентов прямо с сайтов интернет-магазинов.
Такие казусы негативно скажутся на репутации бренда, что, как минимум, повлечет за собой отток клиентуры и соответственно экономические потери. Поэтому сотрудникам, отвечающим за безопасность интернет-магазинов или корпоративных ресурсов первым делом следует в wordpress исключить страницы поиска, то есть не допустить их индексации.
Как в WordPress исключить страницы из поиска
Исключить с помощью robots.txt
«Robots.txt» является файлом, указывающий поисковым ботам на контент, который нужно проиндексировать. В документе также можно запретить автоматике проникать и копировать определенные данные. В зависимости от того, какое кодовое значение вы внесете в файл. После того как вы закончите редактировать, документ надо будет разместить в корневой папке на хостинге. Как это сделать, рассмотрим ниже.
Какой код вставить в файл?
Перед вами перечень кодов, которые вы можете вставить в файл robots. txt. Их можно вставлять по отдельности или целыми блоками. В зависимости от того, что вы хотите индексировать в дальнейшем, а что скрыть. Сразу после списка вы сможете узнать, какой код к чему относится и что обозначает. Ознакомьтесь с ним ниже.
txt. Их можно вставлять по отдельности или целыми блоками. В зависимости от того, что вы хотите индексировать в дальнейшем, а что скрыть. Сразу после списка вы сможете узнать, какой код к чему относится и что обозначает. Ознакомьтесь с ним ниже.
User-agent: * Disallow: /cgi-bin # классика... Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search # поиск Disallow: /author/ # архив автора Disallow: *?attachment_id= # страница вложения. Вообще-то на ней редирект... Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */page/ # все виды пагинации Allow: */uploads # открываем uploads Allow: /*/*.js # внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-*.svg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.pdf # файлы в плагинах, cache папке и т.д. #Disallow: /wp/ # когда WP установлен в подкаталог wp Sitemap: http://site.ru/sitemap.xml Sitemap: http://site.ru/sitemap2.xml # еще один файл #Sitemap: http://site.ru/sitemap.xml.gz # сжатая версия (.gz) Host: site.ru # для Яндекса и Mail.RU. (межсекционная) # Версия кода: 1.0 # Не забудьте поменять `site.ru` на ваш сайт.
Подробнее о коде:
В строке User-agent: * вы можете разрешить какой-либо поисковой системе индексировать страницы вашего сайта. Звездочка в конце означает, что любой бот из любого поисковика может проверять сайт. Но в случае если вы хотите ограничиться одним или несколькими системами то их следует указать. Для Гугла и Яндекса например:
User-agent: Yandex, User-agent: Googlebot
Allow: */uploads, данной командой мы даем согласие на индексацию страниц, где в URL есть слово/uploads. Очень важно это указать, ведь далее мы закрываем от индексации страницы, которые начинаются с /wp-, а /wp- является составляющей /wp-content/uploads. Таким образом, чтобы изменить правило «Disallow» wp- необходима строка Allow: */uploads.
Иные строки ограничивают переход ботов по URL. Они начинаются с кодов:
Disallow: /cgi-bin - закрывает каталог скриптов на сервере Disallow: /feed - закрывает RSS фид блога Disallow: /trackback - закрывает уведомления Disallow: ?s= или Disallow: *?s= - закрыавет страницы поиска Disallow: */page/ - закрывает все виды пагинации
Правило Sitemap: http://site.ru/sitemap.xml сообщает боту где находится файл с картой сайта в XML, если о его создании вы позаботились заранее. Нет? Тогда создайте, затем укажите роботу полный путь к документу, который может быть и не один. Если так, то путь прописываем к каждому индивидуально.
В директиве Host: site.ru мы сообщаем поисковику, какой домен следует считать главным зеркалом сайта. Это необходимо выполнить если у ресурса есть копии на других доменах, тогда Yandex будет индексировать их равнозначно. Почему в данном контексте мы говорим именно об этой поисковой системе? Дело в том, что Host: понимает только Yandex, но не Google. Это важно!
А если вы добавили для сайта безопасный протокол https, то не забудьте его прописать в URL сайта. Например Host: https://sitename.com
Ввиду того, что данная директива работает в разных частях robots.txt, то лучше ее ввести в самом начале или наоборот — внизу файла, сделав отступ размером в одну строку.
Не забудьте упорядочить правила перед обработкой. Это важно!
Поисковики связываются с директивами Allow и Disallow, начиная не с первого и заканчивая последним, а в ином порядке — от короткого к длинному. Точка ставится после обработки крайнего правила:
User-agent: * Allow: */uploads Disallow: /wp-
То есть система считает данный код так:
User-agent: * Disallow: /wp- Allow: */uploads
Например, если бот исследует URL, заданные в формате: /wp-content/uploads/file.jpg, то правило Disallow: /wp- сообщит машине, что проверка не требуется, а Allow: */uploads сделает доступной для сканирования страницу по указанному вами адресу. Чтобы не перепутать и правильно отсортировать коды существует хороший совет: чем больше символов в конкретном правиле файла robots.txt, тем раньше оно будет обработано. Если же их количество не отличается друг от друга, то приоритет окажется у директив Allow.
С помощью WordPress плагина
Мы хотим вам рассказать о плагине, который может упростить вам задачу по работе с файлом robots.txt. Вам не нужно будет создавать его и самостоятельно размещать в корневой папке. Плагин оптимизации Clearfy готов сделать это за вас. Достаточно лишь подобрать необходимые директивы и создать правила. Скачайте и установите плагин, после чего в админке сайта перейдите в настройки приложения. Вот путь:
«Настройки» => «Clearfy меню» => «SEO»
Затем найдите строку «Создайте правильный robots.txt» и активируйте функцию, нажав кнопку ВКЛ.
После активации, ниже появится дополнительное поле, где вы сможете добавить правила для файла robots.txt. Туда нужно вставить код, который необходим, чтобы страницы сайта индексировались правильно.
Благодаря плагину вам не придется закачивать на хостинг файл robots.txt и скачивать обратно, чтобы внести правки.
Как удалить метатег noindex
Я произвольно проверил несколько сообщений и страниц вашего сайта, но не нашел никакого содержания, отмеченного знаком
Это все еще отображается при просмотре исходного кода сообщений или страниц? Если да, не могли бы вы предоставить несколько URL-адресов, отображающих этот тег robots.
Поддержка плагинов Джерлин(@jerparx)
Закрыто.Больше никаких опасений.
У меня такие же проблемы, как я получаю это сообщение на всех своих страницах
Я проверил все настройки внутри WordPress, и плагин ничего не должен блокировать robots.
Не знаю, что делать, помогите пожалуйста
Hi davidaviv,
Вы имеете в виду, что нашли для всех своих страниц в Google Search Console.Если это так, единственное, что вам нужно, это подождать, пока Google проиндексирует ваши страницы, потому что он показывает результат, который был несколько дней назад. Когда вы вводите свой URL-адрес в поле поиска Google Search Console, чтобы проверить, проиндексирован ли он, вам нужно нажать кнопку, например «проверить фактический URL-адрес», чтобы увидеть правильный. Или вы можете использовать этот инструмент для этого. URL тестирования: https://www.google.com/webmasters/tools/robots-testing-tool?utm_source=support.google.com/webmasters/&utm_medium=referral&utm_campaign=+6062598&siteUrl=https://www.yecayehome.com/&pli=1&authuser=1
Я покажу вам, как удалить мета name = ’robots’ content = ’noindex nofollow’ в WordPress, используя замену некоторого кода внутри панели администратора.
войдите в каталог public_html , теперь вы найдете папку с именем wp-includes , дважды щелкните, чтобы открыть эту папку, найдите имя файла general-template.php хотите отредактировать две функции.
Первый код находит внутри файла general-template.php :
function wp_no_robots () {
if (get_option ('blog_public')) {
echo " \ n";
возвращаться;
}
echo " \ n";
} Заменить первый код
function wp_no_robots () {
if (get_option ('blog_public')) {
echo " \ n";
возвращаться;
}
echo " \ n";
} Найдите второй код в файле general-template.php :
function wp_sensitive_page_meta () {
?>
Заменить второй код ниже:
function wp_sensitive_page_meta () {
?>
Когда это будет завершено, вернитесь к проверке веб-сайта, перейдите в Search Console, повторно отправьте URL-адрес, который вы пробовали ранее.Если вы правильно заменяете все коды, все должно петь другую мелодию.
Для получения полной информации проверьте: https://www.techboto.com/how-to-remove-wordpress-robots-meta-tag-noindex-nofollow.html
Узнайте, как оптимизировать файл Robots.txt
Так ты хочешь стать рок-звездой robots.txt, а? Что ж, прежде чем вы сможете заставить этих пауков танцевать в вашем ритме, вам следует ознакомиться с несколькими основными принципами. Создайте своих роботов.txt неправильно, и вы попадете в мир боли. Делайте это правильно, и поисковые системы полюбят вас.
Что такое файл Robots.txt?
Это «инструкция», которую используют поисковые роботы (Google, Bing и т. Д.) При посещении вашего веб-сайта.
Файл robots.txt указывает различным роботам / сканерам / паукам поисковых систем, где они могут и не могут заходить на ваш сайт. Вы сообщаете этим ботам (Google, Bing и т. Д.), Что им разрешено «видеть» на вашем веб-сайте, а что запрещено.
Ваш файл robots.txt - это полицейский на остановке, а машины - это веб-сканеры / пауки .
Имеет смысл? Хорошо.
Зачем мне нужен файл Robots.txt?
Часто игнорируемая часть SEO, файл robots.txt - это то, что люди склонны поспешно сколачивать. Может быть, это потому, что он имеет тенденцию быть одним из последних пунктов в списке запуска веб-сайта (не должно быть… но вы знаете….) Или, может быть, люди в целом просто ленивы. Вы ленивый веб-мастер? Надеюсь, что нет…
Что может пойти не так, если я не буду использовать этих роботов.txt файл?
Без файла robots.txt ваш веб-сайт будет :
- Не оптимизирован с точки зрения проходимости
- Более подвержен ошибкам SEO
- Открытость для просмотра конфиденциальных данных
- Злоумышленникам проще взломать сайт
- Пострадают от конкуренции
- Проблемы с индексацией
- Будет беспорядок, чтобы разобраться в инструментах для веб-мастеров
- Будет подавать непонятные сигналы поисковым системам
- и другие…
Давайте начнем: создание ваших роботов.txt файл
Минута №1: У вас уже есть файл Robots.txt?
Было бы неплохо определить, есть ли на вашем веб-сайте в настоящее время файл robots.txt для начала. Возможно, вы не захотите переопределить то, что есть в данный момент. Если вы не знаете, есть ли на вашем веб-сайте файл robots, просто зайдите на свой веб-сайт и укажите robots.txt. Пример того, как это будет выглядеть:
www.mywebsite.com/robots.txt
Конечно, замените часть «mywebsite» на свое собственное доменное имя.
* Примечание : файл robots.txt всегда должен находиться на «корневом» или «домашнем» уровне вашего веб-сайта, то есть он должен находиться в той же папке, что и ваша домашняя страница или страница индекса.
Если вы ничего не видите при посещении этого URL-адреса, на вашем веб-сайте нет файла robots.txt. Однако, если вы ДЕЙСТВИТЕЛЬНО видите информацию, у вас ДЕЙСТВИТЕЛЬНО есть текущий файл robots. В этом случае, когда вы собираетесь редактировать или добавлять какие-либо правила (как показано ниже), не удаляйте все, что у вас есть в настоящее время, так как это может «испортить» ваш сайт.
На всякий случай сделайте резервную копию файла robots.txt перед тем, как приступить к его редактированию. Когда дело доходит до работы с цифровыми файлами, у меня есть для вас три слова: ВСЕГДА ДЕЛАЙТЕ РЕЗЕРВНЫЕ КОПИИ
Минута № 2: Запуск файла Robots.txt
Создать файл robots.txt так же просто, как встать с постели. Ладно, мне трудно встать с постели, но я отвлекся.
Чтобы создать файл robots.txt, просто откройте любой текстовый редактор. Важно, чтобы вы не использовали программное обеспечение WYSIWYG (программное обеспечение для дизайна веб-страниц), поскольку эти инструменты могут добавлять дополнительный код, который нам не нужен.Сделайте это простым и используйте текстовый редактор. Общие включают:
- Блокнот
- Блокнот ++
- Кронштейны
- TextWrangler
- TextMate
- Превосходный текст
- Vim
- Атом
- и др.
Подойдет любая из этих программ, и, поскольку ваш компьютер по умолчанию поставляется с Блокнотом, вы также можете использовать его в этом руководстве.
Откройте Блокнот и начните вводить свои «правила». После того, как вы ввели свои правила, вы сохраняете файл, называя его «роботами», и убедитесь, что он сохранен с расширением «Текстовые документы (*.текст)".
Какие «правила» вы должны ввести в свой файл robots.txt? Это зависит от того, чего вы хотите достичь. Прежде чем вводить правила, вам необходимо решить, что вы хотите «заблокировать» или «скрыть» от сканирования на вашем веб-сайте. Папки на вашем веб-сайте, которые не нужно сканировать и индексировать в результатах поиска, включают такие вещи, как:
- Поиск по сайту
- Разделы оформления заказа / электронной торговли
- Зоны входа пользователей
- Конфиденциальные данные
- Тестирование / Подготовка / Дублирование данных
- и др..
Имея эту информацию под рукой, вы можете легко настроить свои правила. ВНИМАНИЕ !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! " Давайте посмотрим, как именно мы это делаем.
Общие сведения о правилах файла Robots.txt
Что касается файла robots.txt, существует стандартный формат для создания правил.
1) Звездочки используются в качестве подстановочного знака: *
2) Чтобы разрешить сканирование областей вашего веб-сайта, используется правило «Разрешить».
3) Чтобы запретить сканирование областей вашего веб-сайта, применяется правило «Запретить». б / у
Допустим, у вас есть веб-сайт (что, вероятно, у вас есть ??).На вашем веб-сайте (назовем его mywebsite.com) у вас была подпапка, содержащая дублирующуюся информацию / тестовые материалы / материалы, которые вы хотите сохранить в тайне. Возможно, у вас была настройка этой подпапки в качестве промежуточной или тестовой области. Назовем эту папку «постановкой». Ваш файл robots.txt будет выглядеть примерно так:
User-agent: *
Disallow: / staging /
Довольно просто, не правда ли? Давайте посмотрим, что здесь происходит.
Запускаем наших роботов.txt с User-agent: *
Определение User-agent обращается к паукам поисковых систем, а звездочка используется как подстановочный знак. Таким образом, это правило инструктирует ВСЕХ пауков из ВСЕХ поисковых систем, что они должны следовать ВСЕМ правилам, которые должны появиться позже.
Так будет до тех пор, пока в robots.txt не будет объявлено еще одно объявление User-agent (если вам придется использовать его снова). Что будет потом?
Следующее правило:
Запрещено: / staging /
Это правило запрета сообщает паукам поисковых систем, что им не разрешено сканировать что-либо на вашем веб-сайте, находящееся в «промежуточной» папке.Используя название нашего воображаемого веб-сайта, это место будет выглядеть так: www.mywebsite.com/staging/
* Совет : имейте в виду, что только потому, что вы запретили сканирование определенного раздела вашего веб-сайта, может по-прежнему отображаться в индексе поисковых систем ЕСЛИ ранее сканировалось И , если вы разрешили эти страниц для индексации .
Чтобы этого не произошло, лучше всего объединить правило запрета с метатегами noindex, добавленными на ваши веб-страницы (подробнее об этом ниже).Если страницы, которые вы не хотите сканировать, уже отображаются в индексе поисковой системы, возможно, вам придется удалить их вручную через область инструментов для веб-мастеров соответствующих поисковых систем (Google / Bing).
Просто, не правда ли?
Несколько примеров, которые вы можете использовать
Ниже вы видите несколько примеров из файла robots.txt, в которых показаны разные правила для разных ситуаций. Не все файлы robots.txt будут одинаковыми. Некоторые люди могут захотеть заблокировать сканирование всего своего веб-сайта.У других может возникнуть необходимость ограничить только определенные разделы своего веб-сайта.
Разрешение сканирования и индексации всего на веб-сайте
Агент пользователя: *
Разрешить: /
Блокировка сканирования всего веб-сайта
User-agent: *
Disallow: /
Блокировка сканирования определенной папки
Агент пользователя: *
Разрешить: / myfolder /
Разрешить определенному пауку / роботу (в данном случае Google) доступ к вашему сайту и запретить всем остальным
Пользовательский агент: Googlebot
Разрешить: /
User-agent: *
Disallow: /
Extra: специальные роботы WordPress.txt файл
Что касается WordPress, то при каждой установке WP есть три основных стандартных каталога. Их:
- wp-контент
- WP-администратор
- wp-включает
Папка wp-content содержит подпапку, известную как «загрузка». Это место содержит медиа-файлы, которые вы используете (изображения и т. Д.), И мы НЕ должны блокировать этот раздел. Зачем вам это нужно?
Ну, когда вы «запрещаете» папку в robots.txt, по умолчанию - все подпапки под ней также блокируются по умолчанию.Итак, мы должны создать уникальное правило для этой подпапки мультимедиа.
Ваш файл robots.txt WordPress теперь может выглядеть примерно так:
Агент пользователя: *
Disallow: / wp-admin /
Disallow: / wp-includes /
Disallow: / wp-content / plugins /
Disallow: / wp-content / themes /
Allow: / wp -content / uploads /
Теперь у нас есть очень простой robots.txt, который блокирует выбранные нами папки, но позволяет сканировать подпапку «uploads» внутри «wp-content». Есть смысл?
Если вы запрещаете папку «xyz», каждая папка, находящаяся под / помещенная внутри «xyz», также будет запрещена. Чтобы указать отдельные папки, которые следует сканировать, необходимо указать явное правило.
Вот что вы можете использовать для запуска файла robots.txt WordPress. Странность в этой группе, которую вы, возможно, не видели раньше, - «Disallow: / 20 *».Это отключает архивы дат, начиная с 20 года.
Агент пользователя: *
Disallow: / wp-admin /
Disallow: / wp-includes /
Disallow: / wp-content / plugins /
Disallow: / wp-content / cache /
Disallow: / wp -content / themes /
Disallow: /xmlrpc.php
Disallow: / wp-
Disallow: / feed /
Disallow: / trackback /
Disallow: * / feed /
Запрещено: * / trackback /
Запрещено: / *?
Disallow: / cgi-bin /
Disallow: / wp-login /
Disallow: / wp-register /
Disallow: / 20 *Разрешить: / wp-content / uploads /
Карта сайта: http: // example.ru / sitemap.xml
* Совет : Всегда рекомендуется включать ссылку на карту сайта из файла robots.txt. Карта сайта также должна быть размещена в «корне» вашего веб-сайта (в той же папке, что и файл домашней страницы).
Минута № 3: осторожное предупреждение / проверка ошибок
Убедитесь, что вы не допустили опечаток. Простая опечатка может испортить ваш файл, поэтому убедитесь, что вы написали все правильно и используете правильный интервал.
Также важно отметить, что не все пауки / сканеры следуют стандартному протоколу robots.txt. Вредоносные пользователи и спам-боты будут просматривать ваш файл robots.txt и искать конфиденциальную информацию, такую как личные разделы, папки с конфиденциальными данными, административные области и т. Д. Хотя многие люди ДОЛЖНЫ перечислять эти папки / области своего веб-сайта в файле robots.txt. (и это нормально в 99% случаев), чтобы сделать еще один шаг вперед, вы можете не помещать их в файл robots.txt и просто скрыть их с помощью метатега robots.
Итак, если вы хотите быть в большей безопасности и использовать блокировку конфиденциальных страниц с помощью метатегов, вот как вы это делаете:
- Откройте программу редактирования вашего веб-сайта (что бы вы ни использовали для разработки / редактирования настоящего веб-сайта)
- Используя «представление кода» или «представление текста» вашего программного обеспечения для редактирования, вы должны ввести следующий код между тегами «заголовок» страницы (верхняя часть страницы).
Теперь при просмотре исходного кода вашей страницы он должен выглядеть примерно так:
…
… и именно так вы легко блокируете индексирование и сканирование своих страниц!
Минута № 4: Загрузка на ваш веб-сайт
Конечно, все это бесполезно, если вы не загрузите и не сохраните файл обратно на свой веб-сайт.Поэтому обязательно сохраните файл роботов как robots.txt, и если вы также решили использовать опцию метатега, обязательно повторно загрузите эти веб-страницы после того, как вы их отредактировали и сохранили.
Минута № 5: Просмотр файла в Интернете
Последний шаг в этом простом процессе - просмотреть файл robots.txt в вашем веб-браузере, а также убедиться, что ваши недавно сохраненные страницы (если вы использовали метатег) также обновляются. На всякий случай обновите страницу или очистите кеш и файлы cookie на своем компьютере, прежде чем делать это.
Полезный ресурс:
Чтобы посмотреть хороший список имен пользовательских агентов веб-сканера, посетите: http://www.robotstxt.org/db.html. Здесь вы можете найти любое «имя» сканера и добавить его в свой список разрешенных / запрещенных… большинству людей это не понадобится.
Заключение и заключительные мысли
Итак, теперь у вас есть возможности и знания для эффективного создания и оптимизации файла robots.txt для вашего веб-сайта - замечательно! Однако есть еще много чего узнать. Роботы.txt - это только один из сотен элементов, которые мы ежедневно используем для наших клиентов и стараемся опережать их.
Если вы хотите, чтобы мы проанализировали оптимизацию вашего веб-сайта и резко повысили рейтинг вашего сайта, обязательно свяжитесь с нами, чтобы получить бесплатную 25-минутную маркетинговую оценку. Мы всегда рады помочь!
Есть вопросы? Обязательно оставьте свой комментарий ниже, и я свяжусь с вами так быстро, как молния.
роботов.txt Технические характеристики | Центр поиска | Разработчики Google
Абстрактные
В этом документе подробно описано, как Google обрабатывает файл robots.txt, который позволяет вы можете контролировать, как сканеры веб-сайтов Google сканируют и индексируют общедоступные веб-сайты.
Что изменилось
1 июля 2019 года Google объявил, что Протокол robots.txt работая над становится стандартом Интернета. Эти изменения отражены в этом документе.
Список изменений
Вот что изменилось:
- В этом документе удален раздел «Язык требований», так как язык Конкретный Интернет-проект.
- Robots.txt теперь принимает все На основе URI протоколы.
- Google выполняет как минимум пять переадресаций. Поскольку еще не было загружено правил, перенаправления выполняются как минимум для пяти переходов, а если нет, то robots.txt найден, гугл лечит это как 404 для robots.txt. Обработка логических перенаправлений для файла robots.txt на основе содержимого HTML, которое возвращает 2xx (кадры, JavaScript или мета-тип обновления перенаправления) не рекомендуется, и содержимое первой страницы используется для поиска применимых правила.
- Для 5xx, если robots.txt недоступен более 30 дней, последняя кэшированная копия используется файл robots.txt или, если он недоступен, Google предполагает, что сканирование отсутствует. ограничения.
- Google рассматривает неудачные запросы или неполные данные как ошибку сервера.
- «Записи» теперь называются «линиями» или «правилами», соответственно.
- Google не поддерживает обработку элементов
- Google в настоящее время применяет ограничение на размер в 500 кибибайт (KiB) и игнорирует содержимое после этого ограничения.
- Обновлен формальный синтаксис, чтобы он стал действительной расширенной формой Бэкуса-Наура (ABNF) в соответствии с RFC5234 и покрыть для символов UTF-8 в файле robots.txt.
- Обновлено определение «группы», чтобы сделать его короче и конкретнее. Добавил пример для пустой группы.
- Удалены ссылки на устаревшую схему сканирования Ajax.
Основные определения
| Определения | |
|---|---|
| Гусеничный ход | Сканер - это служба или агент, сканирующий веб-сайты.Вообще говоря, гусеничный автоматически и рекурсивно обращается к известным URL-адресам хоста, который предоставляет контент, который может быть доступными с помощью стандартных веб-браузеров. При обнаружении новых URL-адресов (различными способами, например как ссылки на существующие, просканированные страницы или из файлов Sitemap), они также сканируются в так же. |
| Агент пользователя | Средство идентификации определенного поискового робота или набора поисковых роботов. |
| Директивы | Список применимых рекомендаций для сканера или группы поисковых роботов, изложенный в роботы.txt файл. |
| URL | Унифицированные указатели ресурсов, как определено в RFC 1738. |
| Только для Google | Эти элементы относятся к реализации файла robots.txt в Google и не могут быть актуально для других сторон. |
Применяемость
Руководства, изложенные в этом документе, соблюдаются всеми автоматизированными сканеры в Google. Когда агент обращается к URL-адресам от имени пользователя (например, для перевода, каналов с ручной подпиской, вредоносных программ анализ), эти рекомендации применять не нужно.
Местоположение файла и срок действия
Файл robots.txt должен находиться в каталоге верхнего уровня хоста, доступны через соответствующий протокол и номер порта. Общепринятые протоколы для Все robots.txt основаны на URI, и в частности для поиска Google (например, сканирование веб-сайтов) это "http" и "https". По HTTP и HTTPS файл robots.txt извлекается с помощью HTTP безусловного GET. запрос.
Только для Google: Google также принимает роботов и следит за ними.txt файлы для FTP-сайтов. Доступ к файлам robots.txt на основе FTP осуществляется через Протокол FTP с использованием анонимного входа в систему.
Директивы, перечисленные в файле robots.txt, применяются только к хост, протокол и номер порта, на котором размещен файл.
URL-адрес файла robots.txt, как и другие URL-адреса, чувствителен к регистру.Примеры действительных URL-адресов robots.txt
| Robots.txt Примеры URL | |
|---|---|
http://example.com/robots.txt | Действителен до:
|
http://www.example.com/robots.txt | Действительно для: Недействительно для:
|
http://example.com/folder/robots.txt | Недействительный файл robots.txt. Сканеры не проверяют файлы robots.txt в подкаталоги. |
http://www.müller.eu/robots.txt | Действителен до:
Недействительно для: |
ftp://example.com/robots.txt | Действительно для: Недействительно для: Для Google: мы используем robots.txt для FTP-ресурсов. |
http://212.96.82.21/robots.txt | Действительно для: Недействительно для: |
http: // example.com: 80 / robots.txt | Действительно для:
Недействительно для: [номера портов] . |
http: // example.com: 8181 / robots.txt | Действительно для: Недействительно для: |
Обработка кодов результатов HTTP
Обычно существует три разных результата, когда файлы robots.txt извлечены:
- полное разрешение: все содержимое можно сканировать.
- полный запрет: сканирование контента невозможно.
- условное разрешение: директивы в robots.txt определяют возможность сканировать определенный контент.
| Обработка кодов результатов HTTP | |
|---|---|
| 2xx (успешно) | коды результатов HTTP, которые сигнализируют об успешном завершении сканирования. |
| 3xx (перенаправление) | Google выполняет не менее пяти переходов переадресации, как определено RFC 1945 для HTTP / 1.0 и затем останавливается и обрабатывает его как 404. Обработка переадресации robots.txt на запрещенные URL-адреса обескураженный; так как правила еще не загружены, перенаправления выполняются как минимум в течение пять переходов, и если файл robots.txt не найден, Google рассматривает его как 404 для файла robots.txt. Обработка логических перенаправлений для файла robots.txt на основе содержимого HTML, которое возвращает 2xx (фреймы, JavaScript или переадресация типа мета-обновления) не приветствуются, а содержимое первая страница используется для поиска применимых правил. |
| 4xx (ошибки клиента) | Все ошибки 4xx обрабатываются одинаково, и предполагается, что нет действительного файла robots.txt. существуют. Предполагается, что ограничений нет. Это «полное разрешение» для сканирования. Сюда входят коды результатов HTTP 401 «Неавторизованный» и 403 «Запрещенный». |
| 5xx (ошибка сервера) | Ошибки сервера рассматриваются как временные ошибки, которые приводят к «полному запрету» сканирования.Запрос повторяется до тех пор, пока не будет получен код результата HTTP, не связанный с ошибкой сервера. A 503 (обслуживание Недоступно) приводит к довольно частым повторным попыткам. Если robots.txt недоступен более 30 дней используется последняя кешированная копия robots.txt. Если недоступен, Google предполагает, что ограничений сканирования нет. Чтобы временно приостановить сканирование, рекомендуется использовать код результата 503 HTTP. для Google: если мы можем определить, что сайт неправильно настроен для возвращает 5xx вместо 404 для отсутствующих страниц, мы обрабатываем ошибку 5xx с этого сайта как 404. |
| Неудачные запросы или неполные данные | Обработка файла robots.txt, который не может быть получен из-за проблем с DNS или сетью, например как тайм-ауты, недопустимые ответы, сброс или прерванные соединения и ошибки фрагментации HTTP, рассматривается как ошибка сервера. |
| Кэширование | содержание robots.txt обычно кэшируется на срок до 24 часов, но может храниться в кэше дольше в ситуации, когда обновление кэшированной версии невозможно (например, из-за тайм-аутов или ошибки 5xx).Кешированный ответ может использоваться разными сканерами. Google может увеличить или уменьшить время жизни кеша в зависимости от максимальный возраст Заголовки HTTP Cache-Control. |
Формат файла
Ожидаемый формат файла - простой текст, закодированный в UTF-8. Файл состоит из строк, разделенных CR, CR / LF или LF.
Учитываются только действительные строки; все остальное содержимое игнорируется. Например, если полученный документ представляет собой HTML-страницу, только допустимый текст линии учитываются, остальные отбрасываются без предупреждение или ошибка.
Если используется кодировка символов, в результате которой используются символы которые не являются подмножеством UTF-8, это может привести к тому, что содержимое файл анализируется неправильно.
Дополнительный Unicode Спецификация (байт знак заказа) в начале файла robots.txt игнорируется.
Каждая допустимая строка состоит из поля, двоеточия и значения. Пространства
необязательно (но рекомендуется для улучшения читаемости). Комментарии могут быть
включается в любое место в файле с помощью символа «#»; все
содержимое после начала комментария до конца строки
рассматривается как комментарий и игнорируется.Общий формат <поле>: <значение> <# необязательный-комментарий> . Пробел
в начале и в конце строки игнорируется.
В элементе регистр не учитывается. <Значение> элемент может быть чувствительным к регистру, в зависимости от
Обработка элементов с простыми ошибками или опечатками
(например, useragent вместо user-agent) не поддерживается.
Для поискового робота может быть установлен максимальный размер файла.Контент после максимальный размер файла игнорируется. В настоящее время Google устанавливает размер лимит в 500 кибибайт (KiB). Чтобы уменьшить размер файла robots.txt, объедините директивы, которые приведут к слишком большой файл robots.txt. Например, поместите исключенный материал в отдельный каталог.
Формальный синтаксис / определение
Вот описание расширенной формы Бэкуса-Наура (ABNF), как описано в RFC 5234
robotstxt = * (группа / пустая строка)
group = startgroupline; Начнем с пользовательского агента
* (начальная линия / пустая строка); ... и, возможно, больше пользовательских агентов
* (правило / пустая строка); соблюдаются правила, относящиеся к UA
startgroupline = * WS "агент пользователя" * WS ":" * токен продукта WS EOL
rule = * WS ("разрешить" / "запретить") * WS ":" * WS (шаблон-путь / шаблон-пустой) EOL
; разработчики парсеров: добавьте необходимые вам дополнительные строки (например, карты сайта) и
; будьте снисходительны при чтении несоответствующих строк. Примените закон Постела.
product-token = идентификатор / "*"
путь-шаблон = "/" * (UTF8-char-noctl); действительный шаблон пути URI; см. 3.2.2
пустой шаблон = * WS
идентификатор = 1 * (% x2d /% x41-5a /% x5f /% x61-7a)
комментарий = "#" * (UTF8-char-noctl / WS / "#")
emptyline = EOL
EOL = * WS [комментарий] NL; конец строки может иметь необязательный завершающий комментарий
NL =% x0D /% x0A /% x0D.0A
WS =% x20 /% x09
; UTF8, полученный из RFC3629, но исключая управляющие символы
UTF8-char-noctl = UTF8-1-noctl / UTF8-2 / UTF8-3 / UTF8-4
UTF8-1-noctl =% x21 /% x22 /% x24-7F; без контроля, пробел, '#'
UTF8-2 =% xC2-DF UTF8-хвост
UTF8-3 =% xE0% xA0-BF UTF8-tail /% xE1-EC 2 (UTF8-tail) /
% xED% x80-9F UTF8-хвост /% xEE-EF 2 (UTF8-хвост)
UTF8-4 =% xF0% x90-BF 2 (UTF8-хвост) /% xF1-F3 3 (UTF8-хвост) /
% xF4% x80-8F 2 (UTF8-хвост)
UTF8-tail =% x80-BF
Группировка строк и правила
Одна или несколько строк user-agent , за которыми следуют одно или несколько правил.Группа закрывается user-agent строка или конец файла. Последняя группа может не иметь правил, что означает, что она неявно разрешает
все.
Примеры групп:
пользовательский агент: a запретить: / c пользовательский агент: b запретить: / d пользовательский агент: e пользовательский агент: f запретить: / г пользовательский агент: h
Определены четыре отдельные группы:
- Одна группа для "а"
- Одна группа для "б"
- Одна группа для "e" и "f"
- Одна группа для "h"
За исключением последней группы (группа "h"), каждая группа имеет свою собственную строку "член группы".Последний группа (группа "h") пуста. Обратите внимание на необязательное использование пробелов и пустых строк для улучшения читаемость.
Порядок приоритета для пользовательских агентов
Для конкретного поискового робота действительна только одна группа. Сканер должен определить правильную группу
строк, найдя группу с наиболее подходящим пользовательским агентом. Все остальные
поисковый робот игнорирует группы. Пользовательский агент чувствителен к регистру. Весь несоответствующий текст
игнорируются (например, googlebot / 1.2 и googlebot * эквивалентны googlebot ).
Порядок групп в файле robots.txt не имеет значения.
Если для определенного пользовательского агента объявлено несколько групп, все правила из групп применимые к конкретному пользовательскому агенту, объединяются в одну группу.
Примеры
Пример 1
Предполагается, что следующий файл robots.txt:
пользовательский агент: googlebot-news
(группа 1)
пользовательский агент: *
(группа 2)
пользовательский агент: googlebot
(группа 3)
Вот как поисковые роботы выберут соответствующую группу:
| Группа отслеживаемых на гусеничном ходу | |
|---|---|
| Новости Googlebot | Следующая группа - это группа 1.Прослеживается только самая конкретная группа, все остальные игнорируются. |
| Googlebot (Интернет) | Далее следует группа 3. |
| Изображения робота Google | Следующая группа - это группа 3. Нет конкретного googlebot-images group, поэтому более общая группа
последовал. |
| Googlebot News (при сканировании изображений) | Следующая группа - это группа 1.Эти изображения сканируются роботами Googlebot News, поэтому отслеживается только группа новостей робота Googlebot. |
| Otherbot (Интернет) | Далее следует группа 2. |
| Otherbot (Новости) | Следующая группа - это группа 2. Даже если есть запись для связанного поискового робота, она действителен только в том случае, если он специально совпадает. |
Пример 2
Предполагая, что следующие robots.txt файл:
пользовательский агент: googlebot-news
запретить: / рыба
пользовательский агент: *
запретить: / морковь
пользовательский агент: googlebot-news
запретить: / креветка
Вот как сканеры объединяют группы, относящиеся к определенному пользовательскому агенту:
пользовательский агент: googlebot-news
запретить: / рыба
запретить: / креветка
пользовательский агент: *
запретить: / морковь
См. Также поисковые роботы Google и строки пользовательского агента.
Правила для участников группы
Только стандартные правила для членов группы охватываются
эта секция. Эти правила также называются «директивами» для
краулеры. Эти директивы указаны в форме директивы :
[путь] , где [путь] является необязательным. По умолчанию ограничений нет
для сканирования для определенных поисковых роботов. Директивы без [путь] игнорируются.
Значение [путь] , если указано, следует рассматривать относительно корня
веб-сайт, для которого используется файл robots.txt был получен (используя тот же
протокол, номер порта, имя хоста и домена). Значение пути должно начинаться
с "/" для обозначения корня. Путь чувствителен к регистру. Более
информацию можно найти в разделе «Соответствие URL по пути
значения »ниже.
запретить
Директива disallow указывает пути, которые не должны быть
доступ к ним назначенные сканеры. Если путь не указан,
директива игнорируется.
использование:
запретить: [путь]
позволяют
Директива allow указывает пути, к которым может получить доступ
назначенные сканеры.Если путь не указан, директива
игнорируется.
использование:
разрешить: [путь]
Соответствие URL на основе значений пути
Значение пути используется в качестве основы для определения того, является ли правило применяется к определенному URL-адресу на сайте. За исключением подстановочных знаков, путь используется для соответствия началу URL-адреса (и любых действительных URL-адресов, начать с того же пути). Не 7-битные символы ASCII в пути могут быть включены как символы UTF-8 или как закодированные в кодировке UTF-8 с процентным экранированием символов на RFC 3986.
Google, Bing и другие основные поисковые системы поддерживают ограниченную форму "подстановочных знаков" для значения пути. Это:
-
*обозначает 0 или более экземпляров любого допустимого символа. -
$обозначает конец URL-адреса.
| Пример совпадения пути | |
|---|---|
/ | Соответствует корневому URL-адресу и любому URL-адресу нижнего уровня. |
/ * | Эквивалент /.Завершающий подстановочный знак игнорируется. |
/ рыба | Матчи:
Не соответствует:
|
/ рыба * | Эквивалент Матчей:
Не соответствует:
|
/ рыба / | Завершающая косая черта означает, что это соответствует чему-либо в этой папке. Матчей:
Не соответствует:
|
/*.php | Матчей:
Не соответствует:
|
/*.php $ | Матчей:
Не соответствует:
|
/fish*.php | Матчей:
Не соответствует: |
Поддерживаемые Google линии, не входящие в группу
Google, Bing и другие основные поисковые системы поддерживают карту сайта , поскольку
определяется картами сайта.орг.
использование:
карта сайта: [absoluteURL]
Линия [absoluteURL] указывает на расположение карты сайта или индекса карты сайта.
файл. Это должен быть полный URL-адрес, включая протокол и хост, и не обязательно
быть URL-кодированными. URL-адрес не обязательно должен находиться на том же хосте, что и файл robots.txt. Несколько карта сайта Может существовать записей. Как линии, не входящие в группу, это
не привязан к каким-либо конкретным пользовательским агентам и может отслеживаться всеми поисковыми роботами, если это не
запрещено.
Пример
пользовательский агент: otherbot запретить: / капуста карта сайта: https://example.com/sitemap.xml карта сайта: https://cdn.example.org/other-sitemap.xml карта сайта: https://ja.example.org/ テ ス ト - サ イ ト マ ッ プ .xml
Порядок приоритета для строк членов группы
На уровне членов группы, в частности для , разрешить и запретить директив, наиболее конкретное правило, основанное на
длина записи [путь] превосходит менее конкретное (более короткое) правило.В случае конфликта правил, в том числе с подстановочными знаками, используется наименее ограничивающее правило.
| Примеры ситуаций | |
|---|---|
http://example.com/page | Вердикт : |
http: // example.com / folder / page | Вердикт : |
http://example.com/page.htm | Вердикт : |
http: // example.com / | Вердикт : |
http://example.com/page.htm | Вердикт : |
Роботы-испытатели.txt разметка
Google предлагает два варианта тестирования разметки robots.txt:
- The robots.txt Тестер в Search Console.
- Открытый исходный код Google Библиотека robots.txt, которая также используется в поиске Google.
# Правила бота: # 1. Бот не может причинить вред человеку или своим бездействием позволить человеку причинить вред. # 2. Бот должен подчиняться приказам людей, за исключением случаев, когда такие приказы противоречат Первому закону.# 3. Бот должен защищать свое существование до тех пор, пока такая защита не противоречит Первому или Второму закону. # Если вы можете это прочитать, вам следует подать заявку здесь https://www.bloomberg.com/careers/ Пользовательский агент: * Запретить: / polska Запретить: / account / * Пользовательский агент: Mediapartners-Google Disallow: / about / карьера Disallow: / о / карьера / Запретить: / offlinemessage / Запретить: / apps / fbk Запретить: / bb / newsarchive / Запретить: / apps / news Запретить: / поиск Пользовательский агент: Spinn3r Запретить: / подкасты / Запретить: / feed / podcast / Запретить: / bb / avfile / Пользовательский агент: Googlebot-News Запретить: / спонсор / Запретить: / новости / спонсоры / * Карта сайта: https: // www.bloomberg.com/sitemap.xml Карта сайта: https://www.bloomberg.com/feeds/bbiz/sitemap_index.xml Карта сайта: https://www.bloomberg.com/feeds/bpol/sitemap_index.xml Карта сайта: https://www.bloomberg.com/feeds/businessweek/sitemap_index.xml Карта сайта: https://www.bloomberg.com/feeds/citylab/sitemap_index.xml Карта сайта: https://www.bloomberg.com/feeds/green/sitemap_index.xml Карта сайта: https://www.bloomberg.com/feeds/technology/sitemap_index.xml Карта сайта: https://www.bloomberg.com/feeds/bbiz/sitemap_securities_index.xml Карта сайта: https: // www.bloomberg.com/feeds/bbiz/sitemap_profiles_company_index.xml Карта сайта: https://www.bloomberg.com/billionaires/sitemap.xml Карта сайта: https://www.bloomberg.com/feeds/bbiz/sitemap_news.xml Карта сайта: https://www.bloomberg.com/feeds/dynamic/private-company-index.xml Карта сайта: https://www.bloomberg.com/feeds/dynamic/person-index.xml Карта сайта: https://www.bloomberg.com/feeds/curated/feeds/graphics_news.xml Карта сайта: https://www.bloomberg.com/feeds/curated/feeds/graphics_sitemap.xml Карта сайта: https://www.bloomberg.ru / feeds / equal / sitemap_index.xml Карта сайта: https://www.bloomberg.com/feeds/wealth/sitemap_index.xml Карта сайта: https://www.bloomberg.com/pursuits/property-listings/sitemap.xml Карта сайта: https://www.bloomberg.com/multimedia/sitemap.xml
Страницы продуктов не просканированы из-за ограничения robots.txt
Вы устраняете неполадки, связанные с отклонением другого продукта в Google Merchant Center (GMC)? Если отображается сообщение «Страницы продуктов не могут сканироваться из-за ограничения файла robots.txt», значит, вы попали в нужное место.Узнайте о некоторых из наиболее распространенных причин, по которым продукты Google Покупок отклоняются из-за ограничения файла robots.txt.
Что такое robots.txt и почему он важен?
Веб-сайт Robotstxt рекомендует: «Владельцы веб-сайтов используют файл /robots.txt, чтобы давать инструкции о своем сайте веб-роботам; это называется протоколом исключения роботов. «User-agent: *» означает, что этот раздел применим ко всем роботам. «Disallow: /» сообщает роботу, что он не должен посещать какие-либо страницы сайта.”Поместите файл robots.txt в корень веб-сайта.
Большинство веб-сайтов отправляют файл robots.txt в поисковые системы по разным причинам:
- Оптимизация ранжирования в обычных поисковых системах - чтобы сообщить поисковым системам, какие веб-страницы индексировать, а какие не индексировать
- Оптимизировать платные поисковые объявления - Если у вас нет хорошо сконструированного файла robots.txt, он может снизить ваши показатели качества, привести к тому, что ваши объявления не будут одобрены, запретить ваши продукты в GMC как часть товарных объявлений и создать множество другие проблемы
- Соблюдайте правила размещения рекламы - правила размещения рекламы, особенно для фармацевтических продуктов в некоторых странах, могут ограничивать отображение всего веб-сайта или только страниц фармацевтических продуктов в поиске
- Удаление содержания, бесполезного для поисковых систем - страницы входа , дублированный контент, некоторые PDF-файлы, страницы с благодарностями и любой другой контент, который не имеет смысла индексировать, можно поместить в папки, которые вы отключаете вл.
ПРИМЕЧАНИЕ. Отправка файла robots.txt не всегда может достичь вышеуказанных целей, особенно если вы настроены на исключение определенных страниц из показа в поисковых системах.
Причины, по которым ваши страницы все еще могут сканироваться Google SEM Rush предупреждает владельцев веб-сайтов, что их «контент веб-сайта, даже если он запрещен в вашем файле robot.txt, все равно может быть проиндексирован, если
страница была связанные из внешнего источника, боты по-прежнему будут проходить и индексировать страницу.Незаконные боты по-прежнему будут сканировать и индексировать контент ».
Почему ошибка «Страницы товаров не могут сканироваться из-за ограничения robots.txt» может помешать утверждению страниц товаров
Google учитывает пользовательский опыт при утверждении торговых кампаний. Они будут использовать ваш файл robots.txt для сканирования страниц продуктов вашего веб-сайта и сравнения страниц вашего веб-сайта с вашими объявлениями в Google Покупках. Если содержание страницы не соответствует, они могут запретить использование определенных продуктов.
- Google не может получить доступ к вашим целевым страницам
Чтобы Google мог получить доступ ко всему вашему сайту, убедитесь, что ваш файл robots.txt позволяет программным агентам "Googlebot" сканировать ваш веб-сайт. - Google не может получить доступ к вашим изображениям
Чтобы Google мог получить доступ ко всему вашему сайту, ваш файл robots.txt должен позволять агентам пользователя "Googlebot-image" сканировать ваш сайт.
Magento eCommerce robots.txt образец файла
Если вы ищете образец для начала, вот пример файла Magento robot.txt от агентства цифрового маркетинга Blue Acorn:
User-agent: *
Disallow: / index.php /
Запретить: / *?
Disallow: /*.js$
Disallow: /*.css$
Disallow: / customer /
Disallow: / checkout /
Disallow: / js /
Disallow: / lib /
Disallow: / media /
Разрешить: / media / catalog / product /
Disallow: /*.php$
Disallow: / skin /
Disallow: / catalog / product / view /
User-agent: Googlebot-Image
Запретить: /
Разрешить: / media / catalog / product /
Карта сайта: http: // example.ru / sitemap / sitemap
Тест Google Robots.txt
Что дальше? После того, как вы закончите работу над файлом robots.txt, следующим шагом будет его тестирование. Тестер robots.txt Google определит, какие конкретные URL-адреса на вашем сайте блокируются поисковыми роботами Google.
Тестовая веб-страница Google robots.txt предлагает следующие шаги для проверки вашего файла: Протестируйте файл robots.txt
- Откройте инструмент тестирования для своего сайта и прокрутите файлы robots.txt, чтобы найти выделенные синтаксические предупреждения и логические ошибки. Количество синтаксических предупреждений и логических ошибок отображается сразу под редактором.
- Введите URL-адрес страницы вашего сайта в текстовое поле внизу страницы.
- В раскрывающемся списке справа от текстового поля выберите агент пользователя, который вы хотите смоделировать.
- Нажмите кнопку ТЕСТ, чтобы проверить доступ.
- Проверьте, отображается ли теперь кнопка ТЕСТ ПРИНЯТО или ЗАБЛОКИРОВАНО, чтобы узнать, не заблокирован ли введенный вами URL для поисковых роботов Google.
- Отредактируйте файл на странице и при необходимости повторите попытку. Обратите внимание, что изменения, внесенные на странице, не сохраняются на вашем сайте! См. Следующий шаг.
- Скопируйте изменения в файл robots.txt на своем сайте. Этот инструмент не вносит изменений в фактический файл на вашем сайте, он только проверяет копию, размещенную в инструменте.
Для получения дополнительной помощи в устранении неполадок, связанных с отклонением продуктов GMC, свяжитесь с Highstreet.io, чтобы поговорить с экспертами в области управления потоками продуктов.
Подробнее о фидах продуктов:
Как создать фид продуктов Google Local Inventory
Как создать фид продуктов Instagram
4 Решения для фидов продуктов, чтобы сэкономить ваше время и деньги
# # роботов.текст # # Этот файл предназначен для предотвращения сканирования и индексации определенных частей # вашего сайта поисковыми роботами и пауками, управляемыми такими сайтами, как Yahoo! # и Google. Сообщая этим «роботам», куда нельзя заходить на вашем сайте, # вы экономите трафик и ресурсы сервера. # # Этот файл будет проигнорирован, если он не находится в корне вашего хоста: # Используется: http://example.com/robots.txt # Игнорируется: http://example.com/site/robots.txt # # Дополнительную информацию о стандарте robots.txt см. В следующих статьях: # http://www.robotstxt.org/robotstxt.html Пользовательский агент: * Задержка сканирования: 10 # CSS, JS, изображения Разрешить: /misc/*.css$ Разрешить: /misc/*.css? Разрешить: /misc/*.js$ Разрешить: /misc/*.js? Разрешить: /misc/*.gif Разрешить: /misc/*.jpg Разрешить: /misc/*.jpeg Разрешить: /misc/*.png Разрешить: /modules/*.css$ Разрешить: /modules/*.css? Разрешить: /modules/*.js$ Разрешить: /modules/*.js? Разрешить: /modules/*.gif Разрешить: /modules/*.jpg Разрешить: /modules/*.jpeg Разрешить: /modules/*.png Разрешить: /profiles/*.css$ Разрешить: /profiles/*.css? Разрешить: /profiles/*.js$ Разрешить: /profiles/*.js? Разрешить: / profiles / *.гифка Разрешить: /profiles/*.jpg Разрешить: /profiles/*.jpeg Разрешить: /profiles/*.png Разрешить: /themes/*.css$ Разрешить: /themes/*.css? Разрешить: /themes/*.js$ Разрешить: /themes/*.js? Разрешить: /themes/*.gif Разрешить: /themes/*.jpg Разрешить: /themes/*.jpeg Разрешить: /themes/*.png # Каталоги Disallow: / включает / Запретить: / misc / Запретить: / modules / Запретить: / profiles / Запретить: / scripts / Запретить: / themes / # Файлов Запретить: /CHANGELOG.txt Запретить: /cron.php Запретить: /INSTALL.mysql.txt Запретить: /INSTALL.pgsql.txt Запретить: / УСТАНОВИТЬ.sqlite.txt Запретить: /install.php Запретить: /INSTALL.txt Запретить: /LICENSE.txt Запретить: /MAINTAINERS.txt Запретить: /update.php Запретить: /UPGRADE.txt Запретить: /xmlrpc.php # Пути (чистые URL) Запретить: / admin / Запретить: / комментарий / ответ / Запретить: / filter / tips / Запретить: / узел / добавить / Запретить: / поиск / Запретить: / пользователь / регистрация / Запретить: / пользователь / пароль / Запретить: / пользователь / логин / Запретить: / пользователь / выход из системы / # Пути (без чистых URL) Запретить: /? Q = admin / Запретить: /? Q = комментарий / ответ / Запретить: /? Q = filter / tips / Запретить: /? Q = узел / добавить / Запретить: /? Q = search / Запретить: /? Q = пользователь / пароль / Запретить: /? Q = пользователь / регистрация / Запретить: /? Q = пользователь / логин / Запретить: /? Q = пользователь / выход из системы / # Копии студенческой жизни Запрещено: / studentlife-старший / Запретить: / studentlife-old-delete-pending / Запрещено: / studentlife-old / Запретить: / office / business / hr / staffandfaculty / jobdescriptions-archive Запретить: / офисы / бизнес / hr / staffandfaculty / jobdescriptions-archive / # Старые справочники Disallow: / about / handbook_old Disallow: / about / handbook_old / * # Кормов Monster Menus Disallow: * / feed ## Директивы сайта Института Миддлбери # CSS, JS, изображения Разрешить: / Institute / core / *.css $ Разрешить: /institute/core/*.css? Разрешить: /institute/core/*.js$ Разрешить: /institute/core/*.js? Разрешить: /institute/core/*.gif Разрешить: /institute/core/*.jpg Разрешить: /institute/core/*.jpeg Разрешить: /institute/core/*.png Разрешить: /institute/core/*.svg Разрешить: /institute/profiles/*.css$ Разрешить: /institute/profiles/*.css? Разрешить: /institute/profiles/*.js$ Разрешить: /institute/profiles/*.js? Разрешить: /institute/profiles/*.gif Разрешить: /institute/profiles/*.jpg Разрешить: /institute/profiles/*.jpeg Разрешить: / институт / профили / *.PNG Разрешить: /institute/profiles/*.svg # Каталоги Disallow: / Institute / core / Запретить: / институт / профили / # Файлов Запретить: /institute/README.txt Запретить: /institute/web.config # Пути (чистые URL) Запретить: / Institute / admin / Запретить: / институт / комментарий / ответ / Запретить: / институт / фильтр / советы / Запретить: / институт / узел / добавить / Запретить: / институт / поиск / Запретить: / институт / пользователь / регистрация / Запретить: / институт / пользователь / пароль / Запретить: / институт / пользователь / логин / Запретить: / Institute / user / logout / # Пути (без чистых URL) Disallow: / Institute / index.php / admin / Запретить: /institute/index.php/comment/reply/ Запретить: /institute/index.php/filter/tips/ Запретить: /institute/index.php/node/add/ Запретить: /institute/index.php/search/ Запретить: /institute/index.php/user/password/ Запретить: /institute/index.php/user/register/ Запретить: /institute/index.php/user/login/ Запретить: /institute/index.php/user/logout/ ## Директивы сайта офисов и служб # CSS, JS, изображения Разрешить: /office/core/*.css$ Разрешить: /office/core/*.css? Разрешить: /office/core/*.js$ Разрешить: / office / core / *.js? Разрешить: /office/core/*.gif Разрешить: /office/core/*.jpg Разрешить: /office/core/*.jpeg Разрешить: /office/core/*.png Разрешить: /office/core/*.svg Разрешить: /office/profiles/*.css$ Разрешить: /office/profiles/*.css? Разрешить: /office/profiles/*.js$ Разрешить: /office/profiles/*.js? Разрешить: /office/profiles/*.gif Разрешить: /office/profiles/*.jpg Разрешить: /office/profiles/*.jpeg Разрешить: /office/profiles/*.png Разрешить: /office/profiles/*.svg # Каталоги Запретить: / office / core / Запретить: / офис / профили / # Файлов Запретить: / office / README.текст Запретить: /office/web.config # Пути (чистые URL) Запретить: / office / admin / Запретить: / офис / комментарий / ответ / Запретить: / office / filter / tips / Запретить: / office / node / add / Запретить: / офис / поиск / Запретить: / office / user / register / Запретить: / офис / пользователь / пароль / Запретить: / office / user / login / Запретить: / office / user / logout / # Пути (без чистых URL) Запретить: /office/index.php/admin/ Запретить: /office/index.php/comment/reply/ Запретить: /office/index.php/filter/tips/ Запретить: /office/index.php/node/add/ Запретить: / office / index.php / поиск / Запретить: /office/index.php/user/password/ Запретить: /office/index.php/user/register/ Запретить: /office/index.php/user/login/ Запретить: /office/index.php/user/logout/ ## Директивы сайта колледжа Disallow: / admissions / admitted / connect-student ## Директивы сайта "Школы за рубежом" # CSS, JS, изображения Разрешить: /schools-abroad/core/*.css$ Разрешить: /schools-abroad/core/*.css? Разрешить: /schools-abroad/core/*.js$ Разрешить: /schools-abroad/core/*.js? Разрешить: /schools-abroad/core/*.gif Разрешить: / school-За границей / core / *.jpg Разрешить: /schools-abroad/core/*.jpeg Разрешить: /schools-abroad/core/*.png Разрешить: /schools-abroad/core/*.svg Разрешить: /schools-abroad/profiles/*.css$ Разрешить: /schools-abroad/profiles/*.css? Разрешить: /schools-abroad/profiles/*.js$ Разрешить: /schools-abroad/profiles/*.js? Разрешить: /schools-abroad/profiles/*.gif Разрешить: /schools-abroad/profiles/*.jpg Разрешить: /schools-abroad/profiles/*.jpeg Разрешить: /schools-abroad/profiles/*.png Разрешить: /schools-abroad/profiles/*.svg # Каталоги Disallow: / school-За границей / core / Запрещено: / школы-заграницы / профили / # Файлов Disallow: / school-За границей / README.текст Запрещено: /schools-abroad/web.config # Пути (чистые URL) Disallow: / School-За границей / admin / Запретить: / школы-заграницей / комментарий / ответ / Запретить: / школы-заграницей / фильтр / советы / Запретить: / школы-заграницей / узел / добавить / Запретить: / школы-заграницей / поиск / Запретить: / школы-заграницей / пользователь / регистрация / Запретить: / школы-заграницей / пользователь / пароль / Запретить: / школы-заграницей / пользователь / логин / Запретить: / школы-заграницей / пользователь / выход из системы / # Пути (без чистых URL) Запретить: /schools-abroad/index.php/admin/ Запрещено: / школы-заграницей / index.php / комментарий / ответ / Запретить: /schools-abroad/index.php/filter/tips/ Запретить: /schools-abroad/index.php/node/add/ Запрещено: /schools-abroad/index.php/search/ Запретить: /schools-abroad/index.php/user/password/ Запретить: /schools-abroad/index.php/user/register/ Запретить: /schools-abroad/index.php/user/login/ Запретить: /schools-abroad/index.php/user/logout/ ## Директивы сайта языковых школ # CSS, JS, изображения Разрешить: /language-schools/core/*.css$ Разрешить: /language-schools/core/*.css? Разрешить: / language-schools / core / *.js $ Разрешить: /language-schools/core/*.js? Разрешить: /language-schools/core/*.gif Разрешить: /language-schools/core/*.jpg Разрешить: /language-schools/core/*.jpeg Разрешить: /language-schools/core/*.png Разрешить: /language-schools/core/*.svg Разрешить: /language-schools/profiles/*.css$ Разрешить: /language-schools/profiles/*.css? Разрешить: /language-schools/profiles/*.js$ Разрешить: /language-schools/profiles/*.js? Разрешить: /language-schools/profiles/*.gif Разрешить: /language-schools/profiles/*.jpg Разрешить: /language-schools/profiles/*.jpeg Разрешить: / языковые-школы / профили / *.PNG Разрешить: /language-schools/profiles/*.svg # Каталоги Запретить: / language-schools / core / Запретить: / языковые-школы / профили / # Файлов Disallow: /language-schools/README.txt Запрещено: /language-schools/web.config # Пути (чистые URL) Запретить: / language-schools / admin / Запретить: / языковые-школы / комментарий / ответ / Запретить: / языковые-школы / фильтр / советы / Запретить: / языковые школы / узел / добавить / Запретить: / языковые-школы / поиск / Запретить: / языковые-школы / пользователь / регистрация / Запретить: / языковые-школы / пользователь / пароль / Запретить: / языковые-школы / пользователь / логин / Запретить: / языковые-школы / пользователь / выход из системы / # Пути (без чистых URL) Запретить: / language-schools / index.php / admin / Запретить: /language-schools/index.php/comment/reply/ Запретить: /language-schools/index.php/filter/tips/ Запрещено: /language-schools/index.php/node/add/ Запрещено: /language-schools/index.php/search/ Запретить: /language-schools/index.php/user/password/ Запрещено: /language-schools/index.php/user/register/ Запрещено: /language-schools/index.php/user/login/ Запретить: /language-schools/index.php/user/logout/ ## Директивы сайта библиотеки # CSS, JS, изображения Разрешить: /library/core/*.css$ Разрешить: / library / core / *.css? Разрешить: /library/core/*.js$ Разрешить: /library/core/*.js? Разрешить: /library/core/*.gif Разрешить: /library/core/*.jpg Разрешить: /library/core/*.jpeg Разрешить: /library/core/*.png Разрешить: /library/core/*.svg Разрешить: /library/profiles/*.css$ Разрешить: /library/profiles/*.css? Разрешить: /library/profiles/*.js$ Разрешить: /library/profiles/*.js? Разрешить: /library/profiles/*.gif Разрешить: /library/profiles/*.jpg Разрешить: /library/profiles/*.jpeg Разрешить: /library/profiles/*.png Разрешить: /library/profiles/*.svg # Каталоги Запретить: / библиотека / ядро / Запретить: / библиотека / профили / # Файлов Запретить: / библиотека / README.текст Запретить: /library/web.config # Пути (чистые URL) Запретить: / библиотека / администратор / Запретить: / библиотека / комментарий / ответ / Запретить: / библиотека / фильтр / советы / Запретить: / библиотека / узел / добавить / Запретить: / библиотека / поиск / Запретить: / библиотека / пользователь / регистрация / Запретить: / библиотека / пользователь / пароль / Запретить: / библиотека / пользователь / логин / Запретить: / библиотека / пользователь / выход из системы / # Пути (без чистых URL) Запретить: /library/index.php/admin/ Запретить: /library/index.php/comment/reply/ Запретить: /library/index.php/filter/tips/ Запретить: / библиотека / индекс.php / узел / добавить / Запретить: /library/index.php/search/ Запретить: /library/index.php/user/password/ Запретить: /library/index.php/user/register/ Запретить: /library/index.php/user/login/ Запретить: /library/index.php/user/logout/ ## Фотографии хлеба и директивы Bios Запретить: / хлеб-буханка-конференции / фотографии-и-биоса /
Пользовательский агент: * Разрешить: /wp-admin/admin-ajax.php Разрешить: /*/*.css Разрешить: /*/*.js Запретить: / wp-admin / Запретить: / wp-includes / Запретить: / readme.html Disallow: /license.txt Запрещено: /licenza.html Запретить: /xmlrpc.php Запретить: /wp-login.php Запретить: /wp-register.php Запрещение: * / отказ от ответственности / * Запретить: *? Attachment_id = Запретить: / политика-конфиденциальности Запретить: / конфиденциальность Запретить: / tag / Запретить: / старый / Запрещение: / show-error- * Запретить: / trackback / Запретить: / comment-page- Disallow: / cgi-bin Disallow: /? Черная дыра Пользовательский агент: Googlebot Позволять: / Пользовательский агент: Googlebot-Image Разрешить: / wp-content / uploads / Пользовательский агент: Googlebot-Mobile Позволять: / Пользовательский агент: Mediapartners-Google Позволять: / Пользовательский агент: AdsBot-Google Позволять: / Пользовательский агент: AdsBot-Google-Mobile Позволять: / Пользовательский агент: Bingbot Позволять: / Пользовательский агент: Msnbot Позволять: / Пользовательский агент: msnbot-media Разрешить: / wp-content / uploads / Пользовательский агент: Applebot Позволять: / Пользовательский агент: DuckDuckBot Позволять: / User-agent: Яндекс Запретить: / Пользовательский агент: ЯндексИзображения Запретить: / wp-content / uploads / Пользовательский агент: Qwantify Запретить: / # Популярные китайские поисковые системы Пользовательский агент: Baiduspider Запретить: / Пользовательский агент: Baiduspider / 2.0 Запретить: / Пользовательский агент: Baiduspider-video Запретить: / Пользовательский агент: Baiduspider-image Запретить: / Пользовательский агент: Sogou spider Запретить: / Пользовательский агент: Sogou web spider Запретить: / Пользовательский агент: Sosospider Запретить: / Пользовательский агент: Sosospider + Запретить: / Пользовательский агент: Sosospider / 2.0 Запретить: / Пользовательский агент: yodao Запретить: / Пользовательский агент: youdao Запретить: / Пользовательский агент: YoudaoBot Запретить: / Пользовательский агент: YoudaoBot / 1.0 Запретить: / # Блокировщик обратных ссылок спама Запретить: / feed / Запретить: / feed / $ Запретить: / комментарии / фид Запретить: / trackback / Запретить: * /? Author = * Запрещено: * / author / * Запрещено: / автор * Запретить: / author / Disallow: * / comments $ Disallow: * / feed Disallow: * / feed $ Disallow: * / trackback Disallow: * / trackback $ Запретить: /? Feed = Запретить: / wp-comments Запретить: / wp-feed Запретить: / wp-trackback Запретить: * / replytocom = # Блокировать плохих ботов Пользовательский агент: DotBot Запретить: / Пользовательский агент: GiftGhostBot Запретить: / Пользовательский агент: Сезнам Запретить: / Пользовательский агент: PaperLiBot Запретить: / Пользовательский агент: Genieo Запретить: / Пользовательский агент: Dataprovider / 6.101 Запретить: / Пользовательский агент: DataproviderSiteExplorer Запретить: / Пользовательский агент: Dazoobot / 1.0 Запретить: / Пользовательский агент: Diffbot Запретить: / Пользовательский агент: DomainStatsBot / 1.0 Запретить: / Пользовательский агент: DotBot / 1.1 Запретить: / Пользовательский агент: dubaiindex Запретить: / Пользовательский агент: eCommerceBot Запретить: / Пользовательский агент: ExpertSearchSpider Запретить: / Пользовательский агент: Feedbin Запретить: / Пользовательский агент: Fetch / 2.0a Запретить: / Пользовательский агент: FFbot / 1.0 Запретить: / Пользовательский агент: focusbot / 1.1 Запретить: / Пользовательский агент: HuaweiSymantecSpider Запретить: / Пользовательский агент: HuaweiSymantecSpider / 1.0 Запретить: / Пользовательский агент: JobdiggerSpider Запретить: / Пользовательский агент: LemurWebCrawler Запретить: / Пользовательский агент: LipperheyLinkExplorer Запретить: / Пользовательский агент: LSSRocketCrawler / 1.0 Запретить: / Пользовательский агент: LYT.SRv1.5 Запретить: / Пользовательский агент: MiaDev / 0.0.1 Запретить: / Пользовательский агент: Najdi.si/3.1 Запретить: / Пользовательский агент: BountiiBot Запретить: / Пользовательский агент: Experibot_v1 Запретить: / Пользовательский агент: биксокраулер Запретить: / Пользовательский агент: биксокраулер TestCrawler Запретить: / Пользовательский агент: Crawler4j Запретить: / Пользовательский агент: Crowsnest / 0.5 Запретить: / Пользовательский агент: CukBot Запретить: / Пользовательский агент: Dataprovider / 6.92 Запретить: / Пользовательский агент: DBLBot / 1.0 Запретить: / Пользовательский агент: Diffbot / 0.1 Запретить: / Пользовательский агент: Digg Deeper / v1 Запретить: / Пользовательский агент: discobot / 1.0 Запретить: / Пользовательский агент: discobot / 1.1 Запретить: / Пользовательский агент: discobot / 2.0 Запретить: / Пользовательский агент: Discoverybot / 2.0 Запретить: / Пользовательский агент: Dlvr.it/1.0 Запретить: / Пользовательский агент: DomainStatsBot / 1.0 Запретить: / Пользовательский агент: drupact / 0.7 Запретить: / Пользовательский агент: Ezooms / 1.0 Запретить: / Пользовательский агент: сканер fastbot beta 2.0 Запретить: / Пользовательский агент: сканер fastbot beta 4.0 Запретить: / Пользовательский агент: питательная социальная сеть Запретить: / Пользовательский агент: Feedly / 1.0 Запретить: / Пользовательский агент: FeedlyBot / 1.0 Запретить: / Пользовательский агент: Feedspot Запретить: / Пользовательский агент: Feedspotbot / 1.0 Запретить: / Пользовательский агент: Clickagy Intelligence Bot v2 Запретить: / Пользовательский агент: classbot Запретить: / Пользовательский агент: Уведомление об уязвимости CISPA Запретить: / Пользовательский агент: CirrusExplorer / 1.1 Запретить: / Пользовательский агент: Checksem / Nutch-1.10 Запретить: / Пользовательский агент: CatchBot / 5.0 Запретить: / Пользовательский агент: CatchBot / 3.0 Запретить: / Пользовательский агент: CatchBot / 2.0 Запретить: / Пользовательский агент: CatchBot / 1.0 Запретить: / Пользовательский агент: CamontSpider / 1.0 Запретить: / Пользовательский агент: Buzzbot / 1.0 Запретить: / Пользовательский агент: Buzzbot Запретить: / Пользовательский агент: BusinessSeek.biz_Spider Запретить: / Пользовательский агент: BUbiNG Запретить: / Пользовательский агент: 008/0.Ноготь Запретить: / Пользовательский агент: FyberSpider / 1.3 Запретить: / Пользовательский агент: findlinks / 1.1.6-beta5 Запретить: / Пользовательский агент: g2reader-bot / 1.0 Запретить: / Пользовательский агент: findlinks / 1.1.6-beta6 Запретить: / Пользовательский агент: findlinks / 2.0 Запретить: / Пользовательский агент: findlinks / 2.0.1 Запретить: / Пользовательский агент: findlinks / 2.0.2 Запретить: / Пользовательский агент: findlinks / 2.0.4 Запретить: / Пользовательский агент: findlinks / 2.0,5 Запретить: / Пользовательский агент: findlinks / 2.0.9 Запретить: / Пользовательский агент: findlinks / 2.1 Запретить: / Пользовательский агент: findlinks / 2.1.5 Запретить: / Пользовательский агент: findlinks / 2.1.3 Запретить: / Пользовательский агент: findlinks / 2.2 Запретить: / Пользовательский агент: findlinks / 2.5 Запретить: / Пользовательский агент: findlinks / 2.6 Запретить: / Пользовательский агент: FFbot / 1.0 Запретить: / Пользовательский агент: findlinks / 1.0 Запретить: / Пользовательский агент: findlinks / 1.1.3-beta8 Запретить: / Пользовательский агент: findlinks / 1.1.3-beta9 Запретить: / Пользовательский агент: findlinks / 1.1.4-beta7 Запретить: / Пользовательский агент: findlinks / 1.1.6-beta1 Запретить: / Пользовательский агент: findlinks / 1.1.6-beta1 Yacy Запретить: / Пользовательский агент: findlinks / 1.1.6-beta2 Запретить: / Пользовательский агент: findlinks / 1.1.6-beta3 Запретить: / Пользовательский агент: findlinks / 1.1.6-beta4 Запретить: / Пользовательский агент: bixo Запретить: / Пользовательский агент: bixolabs / 1.0 Запретить: / Пользовательский агент: Crawlera / 1.10.2 Запретить: / Пользовательский агент: Dataprovider Site Explorer Запретить: / # Защитник обратных ссылок Пользовательский агент: AhrefsBot Запретить: / Пользовательский агент: Alexibot Запретить: / Пользовательский агент: MJ12bot Запретить: / Пользовательский агент: SurveyBot Запретить: / Пользовательский агент: Xenu's Запретить: / Пользовательский агент: Xenu's Link Sleuth 1.1c Запретить: / Пользовательский агент: rogerbot Запретить: / # Избегайте ловушек сканера, вызывающих проблемы с бюджетом сканирования Запретить: / поиск / Запретить: *? S = * Запретить: *? P = * Запретить: * & p = * Запретить: * & предварительный просмотр = * Запретить: / поиск # Сканирование в социальных сетях Пользовательский агент: facebookexternalhit / 1.0 Позволять: / Пользовательский агент: facebookexternalhit / 1.1 Позволять: / Пользовательский агент: facebookplatform / 1.0 Позволять: / Пользовательский агент: Facebot / 1.