Типы частотности и операторы | SEOWORK
WS – общая частота запроса — это суммарное количество запросов к поиску Яндекса (по выбранному региону) в течение последнего месяца, в котором содержатся минимум все слова из запроса в любом порядке и словоформе.
В примере показано, что по региону Россия за предыдущий месяц было 142060 запросов, в которых были одновременно слова “шторы”, “на”, “кухню” и возможно еще какие-то слова. Например, частота запроса [современные шторы на кухню] также включена в общую частоту запроса [шторы на кухню].
«WS» (кавычки) – частота показа именно заданных слов запроса (без дополнительных слов). А также в любом порядке и с любыми окончаниями.
В примере показана суммарная частота запроса, включая такие вариации: [шторы на кухнИ купить], [купить шторУ на кухню] и так далее. И не включены запросы типа [шторы на кухню купить современные].
!WS – восклицательный знак – это суммарное количество запросов к поиску Яндекса именно в указанных словоформах (падежах), но с любые хвостами запросов.
То есть не учитываются, например, запросы вида [шторА на кухню].
«!WS» (восклицательный знак и кавычки) – частота показа именно заданных слов запроса с указанными окончаниями, но без “хвостов”.
То есть не учитываются, например, запросы вида [шторы на кухню фото].
[WS] (квадратные скобки) – частота запроса в любых словоформах и с любыми хвостами, но точно в таком порядке как в запросе.
То есть, учитываются запросы вида [шторА на кухню купить НЕДОРОГО], но не учитываются запросы вида [купить шторы на кухню недорого] (потому что уже другой порядок слов).
«[WS]» (кавычки и квадратные скобки) — частота показа именно заданных слов запроса, в любых словоформах, но без каких-либо хвостов и именно в заданном порядке.
То есть, НЕ учитываются запросы вида [купить шторы на кухню] или [шторы на кухню купить недорого].
«[!WS]» (кавычки, квадратные скобки и восклицательный знак) – частота показа именно заданной формулировки без каких-либо хвостов.
То есть только частота запроса [шторы на кухню купить]. НЕ учитываются запросы вида [шторА на кухню купить] или [купить шторы на кухню].
WS? – это запросы к сервису с любыми операторами Яндекс.Вордстата.
Помимо рассмотренных выше, есть еще несколько операторов.
Оператор минуса – это оператор исключения каких-либо запросов.
Можно задавать как одно, так и несколько минус слов.
То есть, не будут учитываются запросы, содержащие слова “современные” или “фото”.
Оператор или (вертикальная черта) – это оператор, которые позволяет учитывать или одно или другое слово.
Данный оператор применяется с оператором группировки (круглых скобок).
Оператор плюса – позволяет указать, что данное слово обязательно должно учитываться.
Например, при общем запросе:
Могут будут включены и другие предлоги, и союзы. Оператор плюса однозначно задает, что именно этот предлог должен быть в запросе.
Итого, загружая задание в сервис с выбором WS? мы можем собирать частоту сложных или специфических конструкций.
Например:
Инструменты — Частотность — WS
Логика работы инструментаВ инструменте WordStat (Частотность) можно собирать частотность по произвольному списку запросов.
Частотность — WS — Новое заданиеЧтобы сформировать задание по сбору частотности, нужно перейти на страницу WS– Новое задание.
Перед выполнением задания следует указать:
Название задания.
Указать регион.
Тип устройства. Выбрать можно только один тип устройства.
Тип частотности (WS). Чтобы использовать конструкции с произвольным синтаксисом — нужно выбрать чек-бокс «WS?» Примеры произвольных конструкций:(жд|авиа) билеты [москва казань]авиа билеты [москва казань] — отзывы Подробнее про типы частотности тут.
Указать список запросов. Файлом/Списком через интерфейс. При добавлении файлом, обязательно тип входного файла должен в формате CSV, в файле как и списком запросы нужно указать столбиком.
Важно! В случае произвольных конструкций не нужно применять стандартные
Частотность — WS — История заданийВ разделе история доступна история по загруженным заданиям. Страница состоит из списка загруженных заданий в порядке убывания.
По каждому заданию из списка есть краткая информация:
Кол-во регионов,
Выбранный тип устройства,
Выбранный тип WS,
Кол-во запросов,
Готовность задания,
Автор задания,
Дата выполнения.
В верхней части находится поиск по названию задания и кол-во отображаемых на данный момент заданий.
Кнопка скачать состоит из списка:
Задание — входной файл,
Отчет задания (таблица со списком запросов с частотностью по регионам.)
Частотность — WS — Детализация задания
Страница состоит из списка запросов из входного задания.
Напротив каждого запроса, столбцом значение ws по запросу по каждому типу частотности
При нажатии на значение частотности по запросу можно перейти в wordstat и посмотреть значение в wordstat по этому же запросу
Также в детализации есть кнопка скачать, при нажатии на кнопку будет скачан Отчет задания (таблица со списком запросов — частотность по каждому типу частотности, которые ранее были указаны в задании).
Какая частотность бывает у яндекса. Виды частотностей поисковых запросов или почему позиция по однословнику не гарантирует получение трафика
Обсудим работу операторов, которые можно и нужно использовать при работе с ключевыми словами. В начале своей деятельности оптимизатора, я долго не понимал, что означают полученные цифры в Яндекс Вордстате . Чем отличается запрос в кавычках от обычного? Зачем ставить восклицательный знак? Об этих и других операторах поговорим дальше.
Для примера возьму предыдущую статью и запрос «Как заработать на блоге ». Регион в расчёт не берём. В результатах получаем 2 587 показов за последний месяц . Отличный ключ, пишем статью
— получаем профит в виде тысячи посетителей на сайт!
Регион в расчёт не берём. В результатах получаем 2 587 показов за последний месяц . Отличный ключ, пишем статью
— получаем профит в виде тысячи посетителей на сайт!
Шучу, но было бы круто! 😀
Полученное число показывает количество всех возможных запросов где встречается данная фраза . Под «показами» понимаем количество пользователей, которые вводили эти запросы в поисковую строку Яндекса. Можно менять слова местами, изменять окончания, убирать предлоги — число показов остается неизменным.
Ок, как узнать количество показов более точно, без использования других слов?
Запрос «в кавычках»
Что бы отследить показы запроса без использования других слов — используем кавычки . Получаем 489 показов в месяц.
Можно менять окончания, порядок слов, но нельзя добавлять другие слова.
Запрос «в кавычках и с восклицательным знаком»
А теперь узнаем реальное количество показов ключевой фразы в том виде, как её ищет пользователь — используем кавычки с восклицательным знаком . То есть здесь не учитывается перестановка слов,
смена окончаний и использование других слов и предлогов. Получаем 334 показа в месяц.
То есть здесь не учитывается перестановка слов,
смена окончаний и использование других слов и предлогов. Получаем 334 показа в месяц.
Представим идеальную ситуацию. Мы получили первое место по данному запросу а CTR сниппета равен 100%. Не трудно посчитать, что запрос будет давать 11-12 посетителей в сутки .
Работая с программой Key Collector, на большом массиве данных, можно увидеть разницу запросов с разными окончаниями.
Запросы из большого количества слов, являются высоко-целевыми и набирают частотность за счёт поисковых подсказок.
А вот пример когда запрос равен, казалось бы, более высокочастотной фразе.
Запрос «с плюсом» и «с минусом»
Часто встречаем запросы со «знаком плюс» перед предлогами и другими частями речи. Оператор позволяет
Оператор «с минусом» — обратного действия, то есть убирает фразы.
Запрос «со скобками и прямым слэшем»
Оператор «со скобками и прямым слэшем» используется редко, но позволяет выводить список фраз с нужными группами слов .
На этом закончим. Операторы в Яндекс Вордстат помогают найти рабочие ключи . Однако, после сбора фраз советую проверять выдачу на принадлежность к коммерческой или информационной группе, так как встречаются не очевидные случаи.
Один из наиболее популярных модулей в Rush Analytics – парсер Яндекс Вордстат, и это не случайно. При сборе семантического ядра необходимо точно знать частотность собранных запросов, чтобы правильно расставить приоритеты по продвижению и избавится от «мусорных» и нулевых запросов. Часто стоит задача пробить несколько десятков тысяч запросов на частотность в Яндексе, но это не совсем простая задача для самописных парсеров Вордстата и десктопных программ, и вот почему:
- Yandex Wordstat имеет хорошую защиту от парсинга, например бан IP-адресов с которых
осуществляется парсинг и выбрасывание капчи в ответ на запросы от ботов.

- Для парсинга большого количества данных с помощью десктопных программ понадобится много IP-адресов (прокси), которые Яндекс с легкостью банит при неоптимальном алгоритме подключения, а прокси – удовольствие недешевое
- Так же для парсинга понадобится автоматическое введение большого количества капчи (например подключение Antigate для этой задачи). Данный фактор, при неоптимальном алгоритме парсинга, может сделать сам парсинг нерентабельным, так как стоимость капчи будет чрезмерно высока
- Большинство десктопных программ не имеют защиты от потери данных при сборе. Так, например, собрав половину данных и потратив на это деньги, при сбое в парсере, вы рискуете не только не получить оставшиеся данные, но и потерять уже собранные
Парсинг Яндекс Вордстат в
Rush Analytics
Учитывая все трудности которые могут возникнуть при парсинге Вордстата, мы сделали свой парсер Wordstat максимально быстрым, удобным и устойчивым к максимальному количеству проблем, связанных с парсингом:
Если вам нужен скоростной сбор частотностей Яндекс Wordstat – Rush Analytics лучшее решение, особенно
если вам нужно собирать большие объемы данных.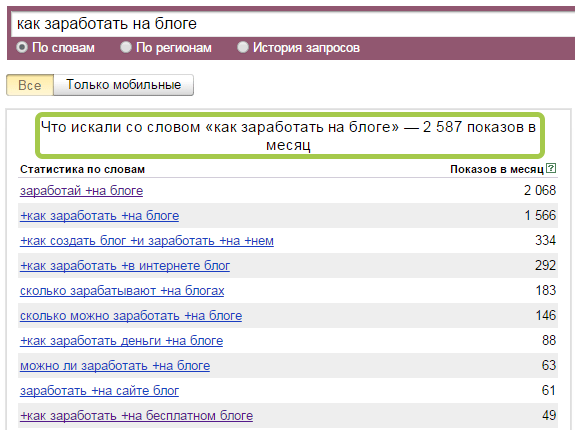 Для пользователей с потребностью сбора боле 100 000
запросов в месяц предусмотрены индивидуальные условия, просто напишите в нашу поддержку на
Для пользователей с потребностью сбора боле 100 000
запросов в месяц предусмотрены индивидуальные условия, просто напишите в нашу поддержку на
Очень важно убедиться, что запросы, по которым вы собрались продвигаться, вообще кто-то ищет. Если вы наберете «семантическое ядро», где все ключи будут с нулевой частотностью — то ваш сайт и будет нулём. Поэтому давайте не будем вола нагибать, а приступим.
Что такое частота ключевого слова
Очевидно, что различные запросы имеют разную популярность среди пользователей поисковых систем. Число ввода конкретного запроса в поисковик берется за один месяц. Таким образом, частота ключевых слов — это количество вводов запросов за месяц.
Вполне возможно, что даже тут есть запросы-пустышки
Для продвижения вашего сайта необходимо создавать оригинальный контент. Например, если вы пишете статьи, уникальность вашего текста должна быть, как правило, выше 90%. В теории, уникальный контент приносит высокий показатель посещаемости, состоящий в большей мере из переходов с Яндекса и Гугла. Однако в реальных условиях ранжирования написать уникальную статью — только половина успеха.
Однако в реальных условиях ранжирования написать уникальную статью — только половина успеха.
Поисковые системы обращают внимание не только на уникальность текста, но и на содержания в нем ключевых запросов, соответствующих тематике статьи или любого другого текстового контента. Правильное распределение ключевых слов в статье называют текстовой оптимизацией. Уникальная, но не оптимизированная статья, содержащие неопределенные запросы, может и вовсе не привлечь на сайт посетителей. Такая ситуация будет означать зря потраченные время и ресурсы на создание контента.
Для оптимизаторов, частотность это критерий по выбору того или иного запроса для его использования в тексте. В зависимости от частотности, на высокочастотные (ВЧ), среднечастотные (СЧ) и низкочастотные (НЧ) запросы. При оптимизации статьи, в первую очередь, обращают внимание на ВЧ и СЧ запросы. Однако с каждым годом продвижение новых сайтов становится все затруднительным, а оптимизация все тоньше. Сейчас считается, что использование НЧ ключей также может принести некоторый объем трафика.
Как проверить частотность запроса
Частотность ключевых слов можно узнать с помощью соответствующих сервисов поисковых систем, а также специальных программ по составлению семантического ядра. Поисковики предоставляют свои сервисы с расчетом подбора запросов для контекстной рекламы.
Wordstat (Яндекс)
Wordstat — cервис Яндекса по определению статистики ключевых запросов. Вордстат использует большинство оптимизаторов не только в целях составления коммерческих запросов под рекламу, но и для добычи ключевых слов в рамках обычной текстовой оптимизации. У Вордстата выделяют три вида частотностей:
- Частотность WS — базовая частотность запроса в Вордстате.
- Частотность «» WS — частотность по точному вводу запроса. Например, статистика по запросу [«автомобиль»] будет соответствовать запросу [автомобиль] без добавлений других слов.
- Частотность «!» WS — частотность по точному вводу каждого слова в запросе, исключая склонения и т.п. Запрос [!китайский] означает, что будет выдана статистика по слову [китайский] без возможных склонений (китайская, китайское).
По запросу [автомобиль] текущая частотность превышает десять миллионов показов. Однако базовый показатель предполагает добавление всевозможных слов к ключевому слову, по которым будет ранжироваться статья.
Если заключить запрос в кавычки, то статистика сократится с десяти миллионов до 28 тысяч. Для оптимизатора может оказаться полезной правая колонка с похожими запросами, которые дополняют семантический сбор.
Вкладка «По словам» означает, что статистика приводится по общей сумме показов введенного запроса. На вкладке «по регионам» отображается статистика показов в разных регионах страны. А на «Истории запросов» можно отследить по графике изменение частотности запроса в течении месяца или недели, а также статистику по по запросам через ПК или мобильные устройства.
Сервис Google AdWords сам по себе более заточен под контекстную рекламу, нежели Вордстат. В разделе «Инструменты» можно подобрать необходимые ключи под нужный запрос.
В отличии от Вордстата, где указывается статистика за месяц, в AdWords можно выбирать месячный диапазон показов в колонке «Диапазон дат». Недостатком является усредненный число результатов. Сама статистика разделена на два блока:
- Ключевые слова — аналог частотности «» Вордстата;
- Ключевые слова (по релевантности) — аналог базовой частотности и похожих запросов WS.
Плюсами являются присутствие уровня конкурентности, а также возможность скачать подобранные слова в CSV-файл или на Гугл Диск.
Помимо AdWords, Гугл имеет еще один инструмент по анализу запросов под названием Google Trends . Данный сервис оценивает популярность введенного запроса на определенный период времени и представляет статистику в виде графика. Можно сравнивать несколько ключевых запросов между собой. Также отображается статистика по регионам.
Для графика используются не точные числа, а относительные, основанные в том числе на релевантных запросах.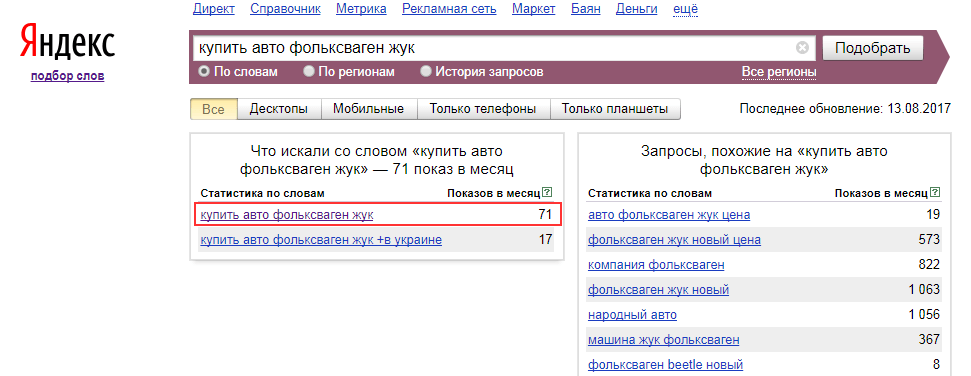
Mail.ru
Mail.ru также имеет в сервисе для вебмастеров инструмент по статистике поисковых запросов. Помимо общих показов, в таблице представлены распределение запросов по полу и возрасту пользователей.
Не секрет, что Mail сотрудничает с Яндексом, так как поисковик размещает рекламу Яндекса.
Rambler
Rambler с каждым годом теряет свою популярность, однако их Wordstat может оказаться весьма полезным. Дело в том, что статистика запросов в Яндексе и Гугле не всегда может отображать реальное положение вещей. Многие компании могут вводить «в холостую» коммерческие запросы в целях слежки за конкурентами, т.е. для анализа ТОПа, тайтлов и т.д.
По причине низкой популярности Рамблера, статистика их Вордстата обладает меньшей заспамленностью и может внести некоторую ясность для оптимизаторов. В общем, в качестве дополнительного инструмента вполне сгодится.
Как проверить массово частотность запросов
Большинство оптимизаторов выбирают для сбора и анализа семантического ядра такие программы, как Key Collector или Slovoeb. Также существуют онлайн-сервисы по определению частотностей.
Также существуют онлайн-сервисы по определению частотностей.
Key Collector
Получить необходимые ключи для семантического ядра и массово проверить их частотность можно при помощи десктопной программы Key Collector . Открываем Вордстат, в поле заносим основные ключи с новой строки по вашей тематике и нажимаем «Начать сбор».
В настройках можно задавать требуемый регион для сбора, а также стоп-слова. После того как ключи соберутся, определяем частотности через Директ.
В итоге у вас будет таблица с ключами и частотой показов. Сразу удаляем все ключи, у которых точная частотность «!» равна нулю. Для этого делаем фильтрацию в колонке «Частотность!». Кликаем на синюю иконку. Появится окно с фильтром. Выбираем «больше или равно» > «1» и жмем «Применить».
Для получения большего списка ключей можно собрать поисковые подсказки с Яндекса. Делаем новую группу (окно справа).
Также убедитесь, что включена галка «Собирать только ТОП подсказок без перебора…». Теперь кликаем на созданную группу – откроется новая пустая вкладка. Жмем иконку сбора поисковых подсказок.
Теперь кликаем на созданную группу – откроется новая пустая вкладка. Жмем иконку сбора поисковых подсказок.
После сбора фраз делаем то же самое, что и при парсинге Вордстата: снимаем частотности, убираем неподходящие по смыслу фразы и фразы, где частотность «!» равна нулю.
Аналогично с помощью Key Collector можно собрать ключи и частотности с Гугла.
Rush Analytics
Сервис Rush Analytics является онлайн-альтернативой Key Collector. Плюсом инструмента по сбору ключей является отсутствие необходимости использовать прокси, антикапчу и т.п.
Для сбора частотности с Вордстата, необходимо перейти на вкладку «Сбор частотности» и поставить галочку напротив !ключевое слово , то есть точной частотности. Далее заносим ключевые слова. После того, как сервис посчитает затраты, нажимаем «Создать новый проект».
Результаты можно сохранить в Excel-файл.
У нас иногда спрашивают:
«Почему мой сайт в ТОПе по такому на первый взгляд «жирному» запросу как «металлоконструкции», но трафика на сайт с этого ключевика совсем мало.
Какие-то 50-100 человек в месяц! Но ведь частотность у этого запроса огромная, аж 250 тысяч в месяц! Почему такое происходит?»
И правда, если вбить в wordstat.yandex.ru такой запрос, то частотность он нам покажет довольно внушительную:
При такой частотности позиция даже на 10 месте в выдаче должна приносить много трафика, но на деле все происходит совершенно иначе. В чем же причина? Давайте разбираться по порядку. Здесь есть несколько моментов, которые нужно учитывать. Начнем с самых простых и далее – по нарастающей.
Регион
Первое, про что все часто забывают, – это выбор региона при съеме частотности. Ни один коммерческий сайт не может продвигаться сразу по всем регионам, если он, конечно, не имеет офисы в каждом из них. Поэтому частотность снимается именно по тому региону, где находится офис компании. Если регионов несколько – отмечаем их все.
Например, компания, которая специализируется на поставках металлоконструкций и металлопроката, имеет офис в Москве, который добавлен в Яндекс. Справочник. Таким образом, ни по каким другим регионам данный сайт ранжироваться не будет, поэтому и ориентироваться надо в первую очередь на посетителей из Москвы. Значит, в wordstat нужно выставить соответствующий регион: Москва.Ключевой момент – наличие организации в Яндекс.Справочнике, так как именно по нему происходит привязка региона сайту.
Справочник. Таким образом, ни по каким другим регионам данный сайт ранжироваться не будет, поэтому и ориентироваться надо в первую очередь на посетителей из Москвы. Значит, в wordstat нужно выставить соответствующий регион: Москва.Ключевой момент – наличие организации в Яндекс.Справочнике, так как именно по нему происходит привязка региона сайту.
Иногда клиенты нам говорят:
«Я хочу продвигаться по всей России, мой интернет-магазин доставляет товар в любой регион».
И здесь мы вынуждены их разочаровать: к сожалению, даже внутри России интернет-магазин не может ранжироваться, если у него нет филиалов в соответствующих регионах. Под филиалами подразумевается привязанная в Яндекс.Справочнике карточка организации с подтвержденным офисом в регионе.Таким образом, при оценке спроса всегда нужно строго определять региональность.
Виды частотности
После выбора региона сразу видно, что частотность значительно уменьшилась.
Однако все равно это не реальные цифры конкретных фраз и, чтобы точно определить частотность каждого ключевика, нужно использовать специальный синтаксис.
Базовая частотность
Пока что мы собрали так называемую «Базовую частотность». Такой частотностью называют ту, которую мы получаем при вводе запроса в wordstat без какого-либо синтаксиса, выбрав регион или нет. Такая частотность представляет собой сумму частотностей всех фраз, где встречаются слова из запроса в любых словоформах и в любом порядке. Например, в нашем случае запрос «Металлоконструкции» без указания региона имел частотность около 250 тыс. в месяц по всему миру и 33 тыс по Москве. В эту частотность вошли все фразы, которые содержат слово «металлоконструкции». Причем слово может иметь разные окончания, то есть сюда войдут фразы: «завод металлоконструкций», «сварные металлоконструкции», «купить металлоконструкции недорого» и т.п.
Частотность в кавычках
Если мы хотим узнать частотность поискового запроса более точно, например, отсечь из нее те запросы, где присутствуют другие слова, то нужно брать запрос в кавычки. Иными словами, если вбить в wordstat запрос в таком виде – “металлоконструкции” – то получим следующую цифру:
Теперь мы видим, что отдельно слово «металлоконструкции» по Москве запрашивают в Яндексе только 948 человек. Однако сюда все равно еще подмешиваются словоформы, например, «металлоконструкций» «металлоконструкция». Чтобы их убрать, воспользуемся следующим видом частотности.
Однако сюда все равно еще подмешиваются словоформы, например, «металлоконструкций» «металлоконструкция». Чтобы их убрать, воспользуемся следующим видом частотности.
Частотность в кавычках и с восклицательным знаком (точная частотность)
Если задать запрос в wordstat в таком виде – “!металлоконструкции” – мы получим самую точную частотность. То есть будет отображаться частотность данного слова именно в таком виде, как мы написали:
В многословных запросах восклицательный знак нужно ставить перед каждым словом, так как данный оператор фиксирует словоформу каждого слова запроса по отдельности.
Таким образом, видна существенная разница в финальной частотности однословного запроса «металлоконструкции» по сравнению с изначальной базовой.
Точная частотность с учетом порядка слов
Однако, если мы подобным образом будем оценивать запрос, состоящий из двух слов, например, «купить металлоконструкции», то нужно еще учитывать порядок слов.
Так, например, если мы проверим точную частотность запросов: “!купить!металлоконструкции” и “!металлоконструкции!купить”, то обнаружим, что странным образом частотность у них будет одинаковая:
Это происходит по той причине, что операторы «кавычки» и «восклицательный знак» не учитывают порядок слов. Чтобы собрать точную частотность фразы «купить металлоконструкции» с учетом порядка слов, нужно использовать оператор «скобки» и вводить фразу следующим образом: “[!купить!металлоконструкции]”:
Чтобы собрать точную частотность фразы «купить металлоконструкции» с учетом порядка слов, нужно использовать оператор «скобки» и вводить фразу следующим образом: “[!купить!металлоконструкции]”:
Таким образом, мы видим, что «купить металлоконструкции» ищут чаще, чем «металлоконструкции купить».
В результате мы разобрались, что основным фактором в оценке спроса по ключевым запросам, который обязательно нужно учитывать, является правильный съем частотности для семантического ядра. В качестве примера мы сравнили базовую и точную частотность для первых трех десятков фраз, которые выдает wordstat по запросу «металлоконструкции». В приведенной таблице в колонке «Показов в месяц» указана базовая частотность, которую выдал Яндекс без учета региона. В колонке «Реальная частотность» указана уже точная частотность по региону Москва и снятая с использованием операторов «кавычки», «восклицательный знак» и «квадратные скобки».
Как видно, точная частотность значительно меньше базовой.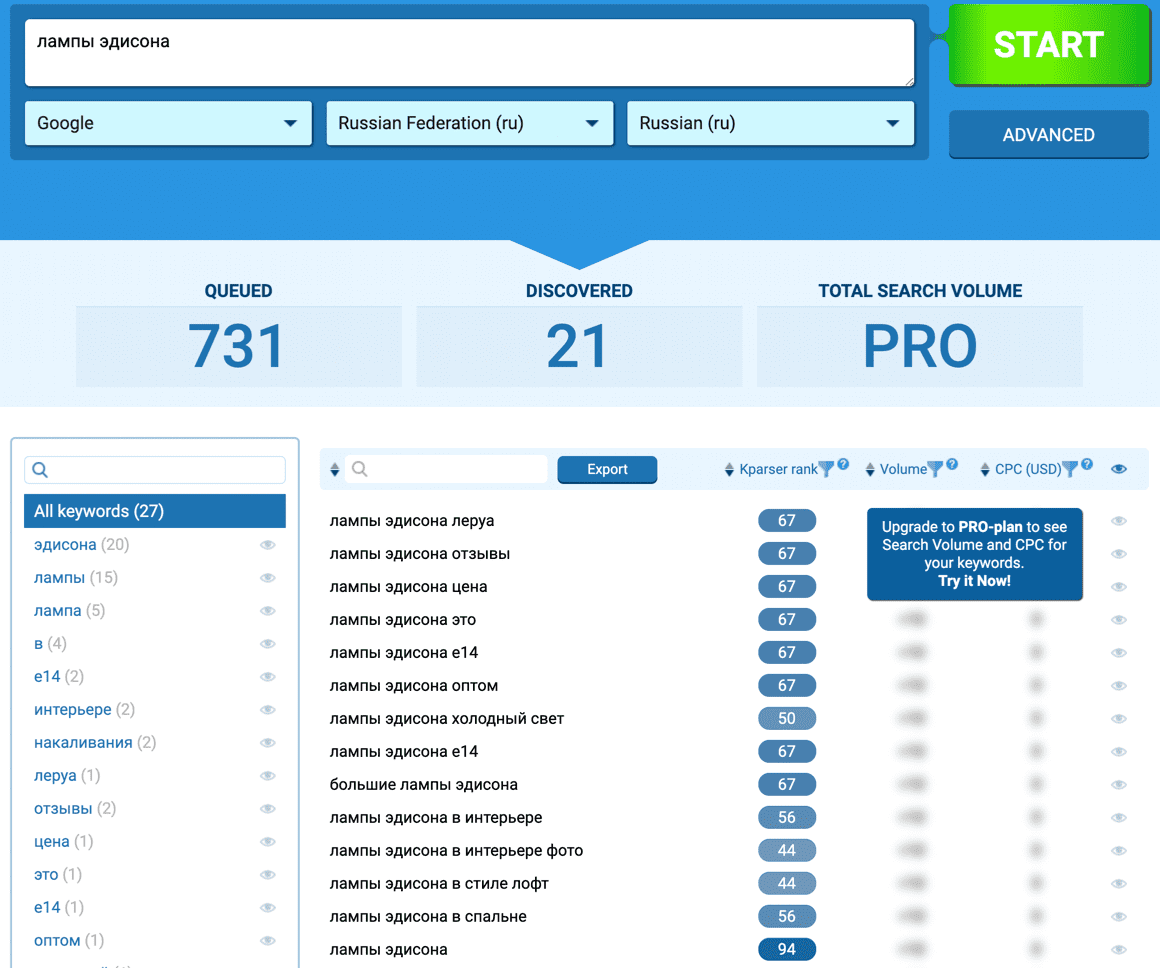 Если исходить из такой методики оценки спроса, то картина, при которой позиция в ТОП-10 Яндекса по ключевой фразе «металлоконструкции», имеющей частотность 839, приносит 50-100 посетителей, уже выглядит более реальной.
Если исходить из такой методики оценки спроса, то картина, при которой позиция в ТОП-10 Яндекса по ключевой фразе «металлоконструкции», имеющей частотность 839, приносит 50-100 посетителей, уже выглядит более реальной.
Распределение кликабельности на первой странице выдачи
Но можно справедливо возразить:
Неужели при позиции в ТОП-10 с ключевика частотностью 839 будет всего лишь 50-100 посещений?
В общем-то да!
По разным оценкам распределение CTR в органической выдаче в ТОП-10 примерно такое:
- ТОП-1: 15-35%
- ТОП-2: 10-25%
- ТОП-3: 7-20%
- ТОП-4: 5-15%
- ТОП-5 – ТОП-10: 3-12%
Подсчеты, конечно, очень обобщенные, но примерно отражают актуальную картину: 3 или даже 4 блока контекстной рекламы забирают больше половины всего CTR. Далее могут идти сервисы Яндекса: маркет, картинки, карты, что делает кликабельность на обычные сайты еще меньше. Учитывая еще то, что позиция в Яндексе редко у какого сайта бывает стабильной в ТОП-10 вследствие работы так называемого алгоритма «бандита», можно смело заключить, что вышеприведенные цифры по количеству трафика являются нормальными.
Оценка CTR через Яндекс.Директ
Наши слова легко проверить – достаточно зайти в Яндекс.Директ в прогноз бюджета и посмотреть там прогнозируемый CTR в зависимости от позиции в блоках контекстной рекламы на поиске.
Яндекс обычно слишком занижает показатели кликабельности в своих прогнозах, но это еще раз показывает, что даже высокая позиция по какому-либо запросу не гарантирует большого количества посетителей.
Заключение
В заключении подытожим, что для правильной оценки спроса и составления на ее основе стратегии поискового продвижения сайта важно собирать максимально полное семантическое ядро и правильно снимать частотность у всех фраз, а также задавать регион. Абсолютно неправильно «зацикливаться» на отдельных и предположительно самых «жирных» поисковых фразах и полагать, что, продвинувшись по ним в ТОП-10, сайт станет лидером тематики. Лидерство сайта в поисковом продвижении определяется исключительно совокупной видимостью сайта по определенному семантическому ядру, то есть многочисленному списку поисковых запросов различной частотности и длины.
Милки, сейчас добрый дедушка вам поведает самую секретную информацию о сервисе подбора ключевых слов, запрашиваемых пользователями в поисковой системе «Яндекс» , Yandex Wordstat . =) Он существует!
Ну, а если серьёзно, то основная информация, которую мы, сеошники, получаем от использования данного сервиса, — это частотность слов и словосочетаний ключевых фраз. Чтобы получить данные по нужной частоте, достаточно использовать в запросах такие символы, как кавычки(«»») и восклицательный знак («!»). Рассмотрим частоту на примере запроса «продвижение сайтов» в регионе «Санкт-Петербург и Ленинградская область» .
Базовая частота
Базовая частота — это количество запросов, которые содержат в себе словосочетание «продвижение сайтов» и все его склонения. Например:
- продвижение сайтов
- продвижение сайтов в санкт-петербурге
- поисковое продвижение сайта
- что нужно для продвижения сайта
В нашем случае базовая частота равняется 7651 показу в месяц.
Фразовая частота
Заключим выбранную фразу в кавычки:
Фразовая частота включает в себя все склонения данного словосочетания, которые запрашиваю пользователя Яндекса. Например:
- продвижение сайтов
- продвижение сайта
- продвижение сайтами
В данном случае фразовая частота равняется 2841 показу в месяц.
Точная частота
Добавим в запрос восклицательные знаки перед каждым словом:
Результатом получим точное количество запросов по данному словосочетанию. Именно это и есть истинная частота данного запроса. В нашем случае она равна 1965 показов в месяц.
Дополнительно следует учитывать, что сервис «Яндекс Вордстат» выдает устаревшие на 2-4 месяца данные. Можно посмотреть динамику данного запроса по временам года и спрогнозировать ситуацию на ближайшее время.
За сим разрешите откланяться. Ваш дед-сеошник.
Задавайте вопросы.
Key Collector — что это + простая инструкция ✅
Key Collector — это программа для работы с ключевыми словами. Позволяет собирать слова со многих сервисов + быстро с ними работать. Если руками 10 000 запросов вы будете обрабатывать неделю, то я справлюсь за пол дня благодаря кей коллектору.
Кей коллектор настолько чудесен, что его стоимость в 1.7к мне кажется самой жуткой халявой, что я встречал за последнее время. Должна быть у каждого сеошника и спеца по контексту. Ускоряет и упрощает сбор семантического ядра (ключей) до безобразия.
В конце будет подробное видео от меня по сбору семантического ядра в нем
Key Collector умеет
Собирать ключи с разных сервисов, ускоряет сбор минус слов, быстро сегментирует, фильтрует ключи, собирает статистику, снимает позиции с поисковой выдачи.
Расскажу и покажу, как собрать семантическое ядро на примере ускорения работы с Яндекс Вордстат. Дам только базовые знания, чтоб не затягивать материал. Весь путь настройки Яндекс Директ (для гугла тоже подойдет) с помощью Key Collector есть в моем видеокурсе.
Настройки Key Collector
Что нужно сделать в Кей Коллекторе, чтобы работать с ним по Яндекс Директ:
- Шестеренка, которая открывает настройки, выделена.
- Удалите плюсик из «Общее» — «удалять символы», ибо плюсики в Директе нужны.
- Выделена вкладка Яндекс Директ, где надо прописать аккаунт, созданный специально для парсинга (а вдруг забанят основной?).Яндекс Вордстат здесь сбор слов, а Яндекс Директ — сбор статистики по фразам.
4. По стандарту интервалы и прочие радости во вкладке Yandex Wordstat настроены адекватно. Трогать ничего не надо.
Интерфейс выглядит так:
В самом низу настройка регионов — на вордстат (сбор слов), на директ (сбор статистики по словам). Обязательно пропишите целевой регион.
Как собирать ключи в Кей Коллектор:
Вставляете ключи в нужный сервис, жмете «начать сбор», уходите пить чай и плевать в потолок. Ярлычок вордстата выделил.
Иногда может вылезать капча. Чтобы не вводить ее самому — идете в настройки и слева будет вкладка «Антикапча». Выбираете любой ресурс антикапчи, регистриуетесь, кладете на баланс, берете ключ API в личном кабинете и вставляете в настройки Key Collector. 5 баксов вам хватит на полгода постоянных настроек, а времени сэкономите уйму.
5 баксов вам хватит на полгода постоянных настроек, а времени сэкономите уйму.
Собрал для примера 500 ключей, пора включить сбор статистики по разным частотностям через Yandex.Direct.
Про частотность «ключевое слово» второго столбца
Обратите внимание на мусорные ключи, которые имеют большую разницу между базовой частотой и закавыченной. Базовую частотность (без операторов) 1000, а закавыченную (второй столбец) в 0-1, например. Это несуществующий ключ, огрызок.
Что такое «павильоны в Оренбурге»? Цветов? Заказать? Купить? В таком виде ключ не вводят, а предложение по нему будет не точным.
Я удаляю ВЫБОРОЧНО ключи 30+ по базовой частоте и 0-1 по закавыченной (на первый столбец фильтр 30+, на второй столбец — меньше или равно 1). Естественно, вы это все просматриваете, ибо адекватные ключи попадаются.
Меньшие частотности не надо, ибо велик шанс, что более точного ключа у вас не будет.
Удаление неявных дублей в Key Collector
Вкладка «Данные» — «Удаление неявных дублей» — «Выполнить умную групповую отметку» и «Удалить отмченное».
Из ключей «Построить баня стоимость» «Баня стоимость построить» останется самый популярный в форме «!слово !слово». Они между собой не конкурируют, просто вы сократите кол-во ключей и время на написание объявлений. Иногда удаляется 100 ключей из 1000.
Сбор минус слов в Key Collector
Пока статистика собирается, мы можем начать собирать минус слова и сразу же удалять их из таблицы.
Первое время смотрите, что удаляете!
Само окно стоп слов Кей Коллектор имеет два режима — применять при парсинге с вордстата (галочка + нажатие обведенной кнопки), либо можете почистить уже существующий список, нажав «Отметить фразы в таблице». Он выделит все вхождения.
Экспериментируйте с типом вхождения Зависимое — Независимое, полное, частичное, соответствие. Для личного удобства. Я работаю ТОЛЬКО с зависимостью от словоформы и полным вхождением!
Метод выделения по стандарту будет опасный — выбрав слово «а», вы выделите все слова, содержащие эту букву.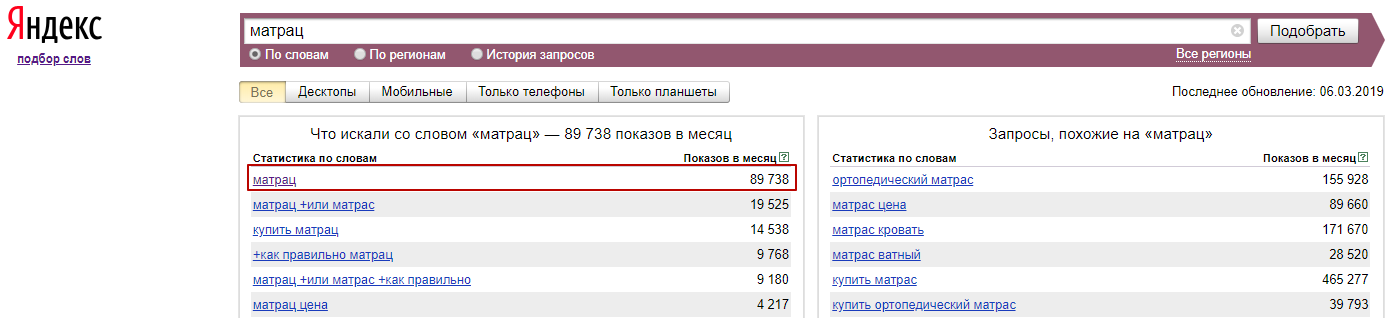 Настраивается в окне стоп-слов.
Настраивается в окне стоп-слов.
Выделить галочкой плохие ключи, жмите правой кнопкой мыши, отправить фразы в стоп-слова, выделяете ненужные и жмите «Добавить в стоп-слова». После этого все вхождения будут выделены в таблице.
Но в самом начале, когда ключей дофига, надо пользоваться группировкой слов — вы мигом удалите треть ненужных ключей.
Вкладка «Данные» — «Анализ групп», а дальше по инструкции. Прошлись по голубым щиткам, добавили в стоп слова, закрыли анализ и удаляйте выделенные ключи из таблицы.
Просматривать ключи в Кей Коллектор удобнее всего, когда они упорядочены по алфавиту. Или вы можете отобрать себе ключи с частотностью от 10 (это для закавыченных кампаний, иначе будет грязно).
Сбор стоп-слов (минус-слов) в Key Collector через «Анализ групп».
Через «Данные — Анализ групп» можете выделить слова, содержащие «мобильные» в разных склонениях и отправить в отдельную группу (Кнопка переноса рядом с окном стоп-слов).
Удобнее всего собирать минус-слова в Кей Коллектор через Анализ Групп. Там есть кнопочка «синий щиток», который сразу выделает нужные минуса, остается только их отправить и выделить вхождения в таблице.
С этой настроечкой (выделено зеленым) будут отмечаться вхождения в таблице по выбранным словам. После этого в таблице выделяются слова, которые нужно переместить в Корзину (или любую другую группу). Вас интересует перенос отмеченных слов (это про галочку. выделение кликом называется «выделенные»)
Вот и конец инструкции.
Видео по работе с ключами в Кей Коллектор:
Там и про ключи и про минуса. Обязательно повторяйте за видео, иначе ничего не запомните.
− Я хочу скачать его бесплатно, где его найти?
Ребят, цените то, что вам не продали продукт по 3 000р в месяц — они могли это сделать. Сам по себе кейколлектор дико полезен, а вы еще и бесплатно хотите.
Сам по себе кейколлектор дико полезен, а вы еще и бесплатно хотите.
Учитесь ценить время разработчиков, купите на официальном сайте. Если хотите сэкономить — скооперируйтесь и купите 3 программы сразу, но подешевле.
Как я могу вам помочь?
Точная частотность запросов в яндексе. Как быстро уточнить частотность запросов в Wordstat
Милки, сейчас добрый дедушка вам поведает самую секретную информацию о сервисе подбора ключевых слов, запрашиваемых пользователями в поисковой системе «Яндекс» , Yandex Wordstat . =) Он существует!
Ну, а если серьёзно, то основная информация, которую мы, сеошники, получаем от использования данного сервиса, — это частотность слов и словосочетаний ключевых фраз. Чтобы получить данные по нужной частоте, достаточно использовать в запросах такие символы, как кавычки(«»») и восклицательный знак («!»). Рассмотрим частоту на примере запроса «продвижение сайтов» в регионе «Санкт-Петербург и Ленинградская область» .
Базовая частота
Базовая частота — это количество запросов, которые содержат в себе словосочетание «продвижение сайтов» и все его склонения. Например:
- продвижение сайтов
- продвижение сайтов в санкт-петербурге
- поисковое продвижение сайта
- что нужно для продвижения сайта
В нашем случае базовая частота равняется 7651 показу в месяц.
Фразовая частота
Заключим выбранную фразу в кавычки:
Фразовая частота включает в себя все склонения данного словосочетания, которые запрашиваю пользователя Яндекса. Например:
- продвижение сайтов
- продвижение сайта
- продвижение сайтами
В данном случае фразовая частота равняется 2841 показу в месяц.
Точная частота
Добавим в запрос восклицательные знаки перед каждым словом:
Результатом получим точное количество запросов по данному словосочетанию. Именно это и есть истинная частота данного запроса. В нашем случае она равна 1965 показов в месяц.
Дополнительно следует учитывать, что сервис «Яндекс Вордстат» выдает устаревшие на 2-4 месяца данные. Можно посмотреть динамику данного запроса по временам года и спрогнозировать ситуацию на ближайшее время.
За сим разрешите откланяться. Ваш дед-сеошник.
Задавайте вопросы.
Здравствуйте, уважаемые читатели!
Появилась идея объединить все статьи, касающиеся темы частотности поисковых запросов. И вот я спешу ее воплотить.
Сегодня мы поговорим об анализе частотности поисковых запросов, объединив все знания, накопленные в предыдущих текстах.
Частотность запросов
Прежде всего, снова определимся, как мы будем группировать запросы. Уже ни для кого не секрет, что выделяются низкочастотники (НЧ), среднечастотники (СЧ) и высокочастотники (ВЧ). Но как определить, к какой группе отнести запрос? Ранее я предложил такую схему:
- НЧ – до 700 запросов в месяц;
- СЧ – до 2000 запросов в месяц;
- ВЧ – все остальные.
Эта схема и сейчас справедлива, но применима она для сео-тематики.
В действительности же большинство сеошников руководствуются следующей схемой:
- до 1000 – низкочастотные;
- 1 – 10 тыс. – среднечастотники;
- свыше 10 тыс. – высокочастотники.
Эта формула также верна, но она считается общей. Если же вы работаете в конкурентных тематиках, где пробиться в ТОП поисковиков крайне сложно, то эти цифры снижаются.
Теперь вы понимаете, что частотность лучше определять в зависимости от того, к какой тематике принадлежит ваш ресурс.
НЧ, СЧ и ВЧ
Я думаю, не стоит подробно описывать каждый тип запросов, его особенности и нюансы. Все это уже было достаточно подробно изложено в предыдущих статьях, вам просто нужно их прочитать:
Эта тема также неоднократно поднималась в предыдущих статьях (например, в статье ), но, как говорится, повторение – мать учения.
Итак, есть три сервиса, которые подходят для анализа частотности запросов:
- Гугл.Адвордс
- Рамблер.Адстат
Самый точный – Яндекс. Вордстат, т.к. он охватывает более 50% русскоязычной аудитории (через поисковики Яндекс, Мейл и т.д.), соответственно и цифры здесь самые близкие к истине.
Вордстат, т.к. он охватывает более 50% русскоязычной аудитории (через поисковики Яндекс, Мейл и т.д.), соответственно и цифры здесь самые близкие к истине.
На втором месте – Адвордс от Гугла. Область охвата рунета – около 30%, поэтому точность определения запросов тут ниже. Но все же этот сервис не стоит сбрасывать со счетов.
Хуже всего определяет частотность запросов Рамблер.Адстат, статистика которого покрывает около 10% рунета. Про Гугл.Адвордс и Рамблер.Адстат читайте в статье « ». Про вордстат поговорим подробнее.
Вордстат
Перейти на этот сервис можно по этой ссылке .
Введя поисковый запрос, вы получите картину его частотности. Не забывайте использовать операторы вордстата:
- Если введен в окошко запрос (окна пвх), то будет посчитано, сколько раз был вообще набран этот запрос в яндексе (окна пвх, стоимость окн пвх, купить окна пвх, окна пвх в Москве и т.д.)
- Если запрос введен в кавычках («окна пвх»), то будет посчитано, сколько раз использовался этот запрос и его словоформы (окна пвх, окон пвх, окнами пвх, окнам пвх и т.
 д.)
д.) - Если ввести запрос в кавычках и с восклицательным знаком перед каждым словом («!окна!пвх»), то будет посчитано, сколько раз вводился конкретно данный запрос.
Поэтому если вам нужно знать точное количество запросов, то используйте кавычки и восклицательные знаки.
Определяя частотность, не забывайте, что низкочастотный запрос не всегда бывает низко конкурентным, а высокочастотный – высоко конкурентным. Поэтому будьте внимательны, старайтесь определять и частотность и конкурентность запроса.
На этот счет существует множество мнений: кто то считает, что нужно оставлять запросы с частотностью не ниже 50 по «! «, а кто то работает с запросами частотностью от 1 по «! «. В данном руководстве мы подробно ответим на все вопросы, касающиеся данной темы.
При сборе подсказок Яндекса существует проблема так называемых «фантомных» подсказок — подсказки которые Яндекс автоматические генерирует на основе персонализации или других данных. Наши алгоритмы эффективно находят такие подсказки и вырезают их, позволяя вам экономить множество времени и денег.
Что мы имеем в итоге:
- более частотные, но, часто накрученные, запросы из «левой колонки» Wordstat
- нетипичные для русского языка, накрученные запросы вроде «коляска детская москва купить»
- менее частотные, но реальные, живые запросы пользователей из поисковых подсказок
- *поисковые запросы из Яндекс Метрики и Google Analytics
* Такие запросы могут быть выгружены за большой период времени и в момент сбора частотности могут иметь нулевую частотность из-за сезонности или неактуальности запроса в момент сбора частотности.
Я собрал подсказки, но многие из них имеют небольшую частотность «!ws», стоит ли их использовать?
Безусловно стоит. Наш сервис призван найти как можно больше целевых ключевых слов, которые можно использовать и о которых не знают конкуренты.
Большинство таких ключевых слов — низкочастотные и они приносят до 70% поискового трафика на веб-сайты в любой стране мира. Плюс, как уже было сказано выше, это живые запросы пользователей, которые актуальны в данный момент времени и могут (часто так и происходит) достаточно быстро набирать популярность, создавая новые семантические тренды и срезы.
Ключевые слова ниже какой частотности отбрасывать?
Здесь все зависит от тематики вашего сайта:
В тематиках, где поисковый спрос узкий (как пример — ремонт телефонов Vertu) — целесообразно использовать даже ключевые слова с частотностью «!» = 1 т.к. здесь важен каждый пользователь из поисковых систем — их в принципе немного.
Для электронной коммерции, например магазинов электроники/подарков/одежды, где очень большой поисковый спрос — можно отбрасывать все ключевые слова с частотностью менее «!» = 5, сконцентрировав усилия на более частотных запросах, а к совсем непопулярным НЧ вернуться позже, при второй итерации.
Для информационных сайтов, таких, как сайты рецептов, сайты кино-тематики, сайты рефератов, автомобильные порталы и для других аналогичных сайтов — можно отбрасывать все ключевые слова с частотностью менее «!» = 50 т.к. спрос в этих нишах просто огромный и физически нереально работать над всем семантическим ядром. Идите от самых популярных потребностей пользователей, к менее популярным. Работайте итерациями.
Работайте итерациями.
Как не потерять нужные запросы и не выкинуть лишнее?
Бывают такие ситуации и тематики, в которых:
- поискового спроса очень мало в принципе
- преобладают многословные запросы в различных словоформах и переформулировках
а) Первый вариант — оставлять запросы с частотностью от «!» = 1, как было сказано выше. Но не везде это возможно, в некоторых тематиках такие запросы или слишком конкретные (не имеют общих URL в SERP с другими запросами и не кластеризуются) и продвигать их нецелесообразно (нет смысла создавать отдельную страницу под такой низкий спрос) или не совсем целевые.
б) Второй вариант — использовать » «, вместо «!». Этот способ работает, когда в вашей семантике преобладают многословные запросы в различных словоформах и переформулировках. Дело в том, что «!» закрепляет конкретную словоформу, а так как многословный запрос может иметь огромное множество переформулировок, а «!» учитывает только одну конкретную, все остальные вы потеряете. Этот метод целесообразно использовать в том случае, если вы видите устойчивый тренд резкого падения частотности от » » к «!» — падение на 70% и более.
Этот метод целесообразно использовать в том случае, если вы видите устойчивый тренд резкого падения частотности от » » к «!» — падение на 70% и более.
Не забываем про сезонность
Так же необходимо учитывать сезонность для некоторых запросов. Ее можно просмотреть в Яндекс Wordstat, если выбрать «История запросов» после ввода ключевого слова.
Так, например запросы связанные с Новогодними праздниками начинают увеличиваться в частотности с сентября, а с середины декабря уже падают.
Так же очень важно учитывать то, что Яндекс показывает данные за прошлый месяц. И если у вас новый запрос, такой, что только что появился, данных о нем может и не быть, либо будет низкая частотность. Или, возможен вариант, что вы снимаете частотность в «низкий сезон». Если вы имеете примерное представление о популярности запросов, но частотности по ним получились сильно меньше, чем вы ожидали, проверьте сезонность и не спешите отказываться от этих запросов! Начиная продвигать запросы в «низкий сезон», вы получите преимущество перед конкурентами, которые начнут продвигать те же запросы в «высокий сезон».
Эта статья рассчитана на новичков в SEO, а также на владельцев сайтов, которые выбрали себе запросы для продвижения, но не знают, частотные ли это запросы.
Итак, начнём.
Частотность запроса — это количество запросов или фраз, набранных пользователем в поисковой системе в определённый промежуток времени. Способы определения частотности запроса в поисковых системах отличаются. В этой статье мы рассмотрим частотность запросов в самых популярных поисковых системах — в Google и Яндексе.
Из этой статьи мы узнаем следующее:
1. Как определять частотность запросов в Яндексе
1.1. Сервис подбора слов в Яндексе
Для определения частоты запросов в Яндексе есть простой и удобный «Сервис подбора слов в Яндексе» или, как его ещё называют, Яндекс Wordstat .
Вбивая запрос в строку подбора, мы получаем следующую картину:
Примечательно, что сейчас мы видим общую картину по показам в месяц, но можно посмотреть частоту запроса отдельно по виду устройств (планшеты, мобильные телефоны, компьютеры), с которых пользователи искали запрос.
Так, мы видим, что 269 733 показа от общего количества пришлись на телефоны.
1.2. Виды частотности в Яндексе
Итак, мы узнали, что у запроса [пластиковые окна] было 1 006 660 показов в месяц — это будет базовая частота запроса.
Всего в Яндекс Wordstat выделяют три вида частоты:
- Базовая частота — обозначает число показов по всем запросам с нужным ключевым запросом. В нашем случае это запрос [пластиковые окна]. При сборе базовой частоты по этому запросу были учтены все возможные словоформы, а также варианты запросов [купить пластиковые окна], [цены на пластиковые окна] и т. д.
- Фразовая частота — для её определения нужно взять запрос в кавычки. Это позволит нам узнать частоту запроса по интересующей нас фразе.
Как видно по скриншоту, фразовая частота значительно ниже базовой, так как во фразовой частоте могут учитываться словоформы, падежи, разные окончания, но игнорируются добавочные слова (например, запрос [купить пластиковые окна] при сборе фразовой частоты не учитывается).
- Точная частота — для её определения нужно взять запрос в кавычки и перед каждым словом в запросе поставить восклицательный знак.
В таком виде мы узнаем количество показов в месяц конкретно по этому запросу.
1.3. Геозависимость
Помимо различной частоты запроса, мы можем узнать частоту по запросам в разных регионах. Для этого нужно вместо пункта «По словам» отметить пункт «По регионам».
На скриншоте видно общее число запросов, а также их количество конкретно по регионам. К примеру, в регионе «Москва» 13 847 показов, региональная популярность составляет 206%.
Что такое региональная популярность? Ответ Яндекса:
«Региональная популярность» — это доля, которую занимает регион в показах по данному слову, делённая на долю всех показов результатов поиска, пришедшихся на этот регион. Популярность слова/словосочетания, равная 100%, означает, что данное слово в данном регионе ничем не выделено. Если популярность более 100%, это означает, что в данном регионе существует повышенный интерес к этому слову, если меньше 100% — пониженный. Для любителей статистики можем заметить, что региональная популярность – это affinity index.
Если популярность более 100%, это означает, что в данном регионе существует повышенный интерес к этому слову, если меньше 100% — пониженный. Для любителей статистики можем заметить, что региональная популярность – это affinity index.
Также можно задать регион при сборе частоты. По умолчанию установлен сбор по всем регионам.
Выбираем регион.
Таким образом, при поиске точной частоты запроса по конкретному региону можно узнать, какое количество людей ищут интересующий вас запрос в указанном регионе.
1.4. Как определить сезонность запроса
В Яндекс Wordstat есть ещё одна интересующая нас функция. Для её использования нужно отметить пункт «История запросов».
Таким образом, мы видим, какой была частота запроса по месяцам в разные периоды. С помощью этой информации можно примерно спрогнозировать падения/подъёмы трафика на сайте.
1.5. Плагины для удобства пользования сервисом
Сервис Wordstat полезный, но не очень удобный, поэтому для того чтобы облегчить себе жизнь, при работе с ним я использую плагин Yandex Wordstat Assistant .
Вот так он выглядит в окне Вордстата:
Первое, что бросается в глаза, — это плюсы около запросов. Нажимая на них, мы добавляем запросы в колонку слева:
Это очень удобно, так как обычно нужно выделять каждый запрос и его частоту, чтобы его скопировать. Более того, можно спокойно переключаться на другие запросы, и список запросов, добавленных в колонку, сохранится.
Также этот плагин позволяет сортировать запросы прямо в колонке по частоте или алфавиту, а после — копировать эти запросы с частотой в нужный вам документ. Рекомендую использовать плагин для браузера Chrome, так как там более свежая версия, которая постоянно обновляется. Для FireFox тоже есть плагин, но он не обновлялся с апреля 2015 года, так что не все функции работают корректно.
2. Как определять частотность запросов в Google?
Если с Яндексом всё относительно просто, то узнать частоту запроса в Google будет сложнее. У Google нет сервиса вроде Яндекс Wordstat, поэтому приходится использовать сервис контекстной рекламы Google AdWords . Вам нужно будет зарегистрироваться в нём. После регистрации перед вами появится панель.
Вам нужно будет зарегистрироваться в нём. После регистрации перед вами появится панель.
Откройте вкладку меню «Инструменты» и в выпавшем меню найдите «Планировщик ключевых слов».
После этого откроется страница планировщика. На этой странице нужно выбрать «Получение статистики запросов и трендов». Там вбейте интересующий вас запрос и укажите регион.
Нажмите на кнопку «Узнать количество запросов». Вы получите такой результат:
Из-за ограничений AdWords у запроса среднее число запросов в месяц колеблется от 1000 до 10 000. Чтобы получить более подробную информацию, нужно создать и запустить кампанию.
При запущенной платной кампании частота запроса будет выглядеть следующим образом:
3. Программный сбор частоты запросов
Выше были описаны способы ручного сбора частоты запросов. При большом количестве запросов собирать их частоту вручную очень неудобно, поэтому я использую специальные программы.
3. 1. Программа «Словоёб»
После настройки программы нужно запустить её и так же, как и в случае со «Словоёбом», добавить запросы, указать «Регион» и нажать на «Сбор статистики Yandex. Direct».
Key Collector, в отличие от «Словоёба», парсит данные, используя Яндекс. Директ, что значительно ускоряет процесс парсинга. Жмём «Получить данные» и получаем результат:
Программа позволяет собирать частоту и для Google, используя Google AdWords. Для этого нужно её настроить. Настройки можно посмотреть на официальном сайте Key Collector . Затем нужно будет нажать на кнопку «Сбор статистики Google. Adwords», которая находится рядом с кнопкой «Сбор статистики Yandex.Direct».
4. Онлайн-сбор частоты запросов
Иногда бывают ситуации, когда любимого инструмента нет под рукой, а частоту собрать нужно. В этом случае можно воспользоваться онлайн-сервисами для сбора частоты. Я рассмотрю 2 сервиса, которые использую сам. Один будет под Яндекс, другой — под Google.
4.1. Онлайн-инструмент для сбора частоты от SeoLib для Яндекса
Всё, что нужно сделать, — это открыть вкладку «Анализ ключевых фраз» и скопировать в форму для запросов или прикрепить отдельным файлом список интересующих запросов. После этого нужно выбрать необходимую частоту и регион, при необходимости указать дополнительные параметры. После нажать на «Начать анализ».
В форму нужно через запятую добавить ключевые слова и указать регион около кнопки «Пояса».
Результат:
Переходим во вкладку «Метрики»:
Итоги
Работа с Яндексом :
- Если запросов несколько, можно смотреть их вручную через Яндекс Wordstat. В таком случае я настоятельно рекомендую поставить плагин Yandex Wordstat Assistant — он заметно облегчает процесс;
- Если у вас есть список запросов и вам необходима быстрая разовая проверка, используйте онлайн-инструмент «Подбора ключевых слов» от SeoLib;
- Если вы постоянно работаете с запросами, рекомендую купить Key Collector. «Словоёб» хоть и бесплатный, но парсит слишком медленно, а время, которое вы сэкономите на парсинге запросов в Key Collector, с лихвой отобьёт затраты. «Словоёб» можно использовать, если вы работаете с небольшим списком запросов и пользуетесь им нечасто. Я сам им пользовался, когда начинал работу в SEO, но когда приобрёл Key Collector, пожалел, что не купил его раньше.
Работа с Google :
- Если запросов несколько, используйте Google AdWords;
- Если у вас есть список запросов, то удобнее будет воспользоваться онлайн-сервисом Ahrefs или настроить Key Collector.
Я перечислил сервисы, которые сам использую для сбора частоты запросов. Возможно, вы пользуетесь другими сервисами? Тогда укажите их в комментариях, буду рад ознакомиться с ними!
На этом пока всё, желаю вам хороших позиций по частотным запросам!
Подписаться на рассылкуВ нашей статье о видах поисковых запросов, было рассказано о том, что запросы делятся на ВЧ, СЧ, НЧ и МНЧ. Подробнее почитать обо всех видах Вы можете в статье — Виды поисковых запросов . Сегодня хотелось бы поговорить о том, как проверить частотность запроса и узнать к какому именно виду он относится. Мы рассмотрим наиболее удобный способ проверки — с помощью сервиса Яндекс Wordstat или подбор слов Яндекса. Данный сервис предназначен для показа статистики по поисковым запросам в этой системе.
Частотность запросов в ПС ЯндексПоисковая система Яндекс, помимо своих основных функций для пользователей — поиск сайтов для ответа на поставленные вопросы, имеет отличный сервис для владельцев сайтов, который позволяет узнать, насколько популярен тот или иной запрос, то есть определить его частотность.
Частотность поисковых запросов — это число раз вводимых пользователем определенного запроса в поисковой системе за промежуток времени (в Яндексе за 1 месяц). То есть при проверке запроса «Квартиры в Москве» на его частотность, мы узнаем, сколько раз в месяц пользователи вбивали это словосочетание в поисковую строку.
Определяем частотность запросаКак было сказано выше мы имеем 4 вида поисковых запросов: высокочастотные, среднечастотные, низкочастотные, микронизкочастотные. Теперь пришло время научиться определять это. Нам понадобится сервис Вордстат — wordstat.yandex.ru . Так же стоит отметить, что для использования этого сервиса Вам необходима регистрация в самом Яндексе (достаточно завести почтовый ящик). Сервис полностью бесплатный, что не может не радовать.
Как видите, страница имеет лишь адресную строку для ввода запроса и несколько дополнительных функций. Нас же в настоящий момент интересует определение частотности запроса. Для этого вбиваем в поисковую строку необходимый запрос и получаем результат. Для примера возьмем запрос «Новости политики» .
Как видите, данный поисковый запрос имеет 23 473 показа в месяц . Соответственно запрос является высокочастотным . Так же в левом столбце Вы можете посмотреть на запросы в Яндексе, которые содержали данное словосочетание, а в правом столбце показаны похожие запросы.
Итак, давайте еще раз рассмотрим, какие запросы у нас будут высокочастотными, а какие относится к другим видам.
Высокочастотный запрос — более 5 000 показов в месяц
Среднечастотный запрос — от 500 до 5 000 показов в месяц
Низкочастотный запрос — от 50 до 500 показов в месяц
Микронизкочастотный запрос — Менее 50 показов в месяц.
Важно! Данные цифры не являются точными, и частотность поискового запроса для определенного вида может меняться в зависимости от тематики. Например, для некоторых тематик высокочастотными будут являться запросы, имеющие более 10 000 показов в месяц.
Давайте попробуем ввести в Вордстат микронизкочастотный запрос. Например «исследования коронарного шунтирования»
Как видите, в Яндексе такой запрос вводится всего 35 раз в месяц, и его стоит отнести к МНЧ. Продвижение по такому запросу самое простое, но при этом количество посетителей, пришедших на сайт, будет очень низким.
Важно! Данные, которые Вы видите в графе «показов в месяц», не являются точными. Яндекс предоставляет Вам информацию обо всех запросах, которые содержали данное словосочетание.
Например, у запроса «Зубной врач Москва» — 500 показов в месяц. Но в эти показы будут так, же входить запросы «Зубной врач на дому в Москве», «Платный зубной врач Москва» и другие. Для определения количества точных вхождений необходимо использовать дополнительные возможности Вордстата. Как именно это сделать рассмотрим ниже.
Определение числа точных и морфологических вхождений запроса
Показанные выше результаты, как уже было сказано, не дают точной картины по определенному запросу. Чтобы определить точное вхождение слов в Вордстате нам понадобится использовать некоторые дополнительные функции.
Давайте возьмем запрос «Купить мопед» .
Как видите, у данного запроса 105 048 показов в месяц. Однако эти показы будут включать в себя фразы «Купить мопед б/у», «Купить мопеды Альфа» и другие.
Для того, чтобы определить точное вхождение поискового запроса нам необходимо поместить запрос в кавычки.
Как видите, у данного запроса стало всего 4 400 показов. Именно такое количество раз пользователи вводят этот запрос в Яндексе за месяц. При этом, 4 400 показов включают в себя морфологические изменения этого запроса. То есть, здесь же показаны результаты запросов «Купить мопеды», «Покупаю мопед», «Куплю мопедик» и другие.
Чтобы получить точное число показов запроса в определенной форме, времени и падеже, необходимо перед каждым словом в этом запросе поставить восклицательный знак. Семантическое ядро — что это такое
Как правильно настроить KeyCollektor и обрабатывать семантику для информационных запросов
Существует множество методик работы настройки Кейколлектора и обработки семантики с его помощью. В этом посте я опишу свои методы работы, которые отличаются простотой и по моему опыту дают хорошие результаты.
Статья не для новичков. Поэтому тем, кто впервые сталкивается с программой Кейколлектор, рекомендую предварительно ознакомиться с официальной справкой.
Итак, инструкция по настройке и работе KeyCollektor для обработки инфо-запросов
Подготавливаем софт к работе. Первым делом настраиваем:
- фильтры — для поиска и удаления мусорных запросов;
- видимость колонок — для удобства работы и последующего экспорта;
- саму программу — для комфортной работы и минимизации вероятности блокировки от ПС.
Настройка фильтров
Навигация по тексту
Настраиваем базовые фильтры по фразам
Выставляем фильтр по колонке «Фраза», как на скриншоте:
Пример настроек фильтра KeyCollektor по колонке с ключевыми фразамиПочему именно так?
- Убираем однословники, т.к. двигать зайт по ним нецелесообразно, кроме очень редких случаев. К тому же, если мы пилим инфо-сайт, то однословник не даёт нам полной картины по интенту, а это очень важно.
- Убираем фразы, состоящие более чем из 8 слов, т.к. по этим фразам Вордстат Яндекса не даст нам частотку. (Хотя отмечу, что частотность таких длинных фраз собрать можно. На текущий день сервис Rush-Analytics даёт такую возможность. Но это уже тема отдельного поста).
- Убираем фразы с повторами слов — тут всё понятно.
- Убираем фразы со служебными символами. Например, если собираем ядро под RU-сегмент, то этот фильтр уберёт все мусорные фразы с символами i, который характерен для UA-сегмента.
Фильтруем по частотности
Фильтр по точной частотности в КейколлектореЧастотность, равная нулю означает, что за последний месяц не было показов рекламы в ПС Яндекс по данному запросу. Нам такие запросы не интересны, т.к. высока вероятность, что их никто и не вводил в поиск. Тут правда стоит учитывать сезонность вашей тематики.
Строки с пустым значением также не интересны. Пустое значение свидетельствует о том, что Вордстат Яндекса не смог обработать ключ. Ну «не шмог, так не шмог» — нам тоже это не нужно, убираем 🙂
Важный фильтр по KEI — убираем фразы-пустышки
По этому фильтру у меня есть отдельный подробный пост как фильтровать фразы по KEI и почему это эффективно. Почитайте тут.
Сами настройки фильтра выглядят так:
Настройки фильтра по KEIЗначение KEI задаётся формулой в настройках программы на одноимённой вкладке:
Формула KEIСаму формулу можете скопировать и вставить в программу:
YandexWordstatBaseFreq / ( YandexWordstatQuotePointFreq + 1.0001 )
YandexWordstatBaseFreq / ( YandexWordstatQuotePointFreq + 1.0001 ) |
Фильтр убирает фразы-пустышки. Данная формула KEI представляет собой отношение базовой частотности к точной. Чем больше это отношение, тем больше вероятность того, что фраза пустая с точки зрения целесообразности оптимизации под неё. Такие слова хоть и имеют большую частоту, но по факту запрашиваются в поиске крайне мало. Это нам не интересно, фильтруем.
Почему я ставлю больше или равно 95 в фильтре? Такую степень фильтрации вывел опытным путём, неплохо работает при чистке фраз.
Настраиваем видимость колонок
Как показала практика, наиболее нужные колонки в программе:
- Фраза;
- Базовая частотность [WS];
- Частотность в кавычках “ ” [WS];
- Точная частотность “!” [WS];
- Значение KEI.
Для удобства настраиваем шаблон вида в самом Кейколлекторе:
И аналогично указываем нужные колонки в файле экспорта:
Настраиваем программу KeyCollektor
Удобство пользования зависит от правильно расположенных на панели кнопок быстрого доступа. Тут всё индивидуально. Я например, перенёс в быстрый доступ кнопки поиска неявных дублей и анализ групп:
Можно вообще вынести наиболее полезные кнопки на панель, остальное скрыть, освободив больше рабочего пространства. Например, так:
Тут всё индивидуально. Кнопки на панель быстрого доступа отправляются из контекстного меню по клику правой кнопки мыши.
Далее настраиваем вкладки.
Yandex Wordstat
Настройки вкладки Yandex Wordstat
Google Adwords
Настройки вкладки Google AdwordsНа вкладке надо также указать аккаунт Google Adwords для сбора статистики. Не используйте свой основной аккаунт. Его могут заблокировать.
Yandex Direct
Настройка вкладки Yandex Direct — Часть №1 Настройка вкладки Yandex Direct — Часть №2На вкладке надо указать аккаунты Яндекс Директ. Желательно штук 10. Также как и с Adwords не используйте свой основной аккаунт в Яндексе. Его могут заблокировать.
Сеть
Настройка вкладки СетьПрокси можно бесплатно взять в сервисе Hideme. Важно при этом прокси использовать только для снятия частотности и менять каждый день. Также перед стартом парсинга проверяйте прокси в Яндексе.
Вкладка Антикапча
Настройка вкладки АнтикапчаЕсли у вас валится много капчи, то совет такой: сделайте принудительную очистку данных об авторизации и удалите куки коллектора.
Данные об авторизации чистятся на вкладке настроек Yandex Direct — там такая большая кнопка есть:
Куки удаляются в папке Preferences, которая лежит где установлен Кей Коллектор:
Куки Кей КоллектораУ вас этот путь может быть другим.
Вкладка KEI
Формула текстом
YandexWordstatBaseFreq / ( YandexWordstatQuotePointFreq + 1.0001 )
Анализ неявных дублей
Бонус: где брать ключи для обработки.
Понятно, что прежде чем обрабатывать ключи, их надо где-то собрать. Для прямого парсинга Вордстат как ни странно, не очень эффективен из-за ограничений по глубине парсинга. Поэтому я делаю так: собираю начальные ключи по данным сервиса Кейсо. Также можно брать массивы по запросам-маскам из баз Букварикса или МОАВа. Далее загружаем выборки в Кейколлектор, собираем явные минус фразы (инструмент анализа групп вам в помощь) и дальше парсим список через вордстат и подсказки.
Итак, сам алгоритм
- Загружаем все слова из всех источников;
- Применяем «базовый» фильтр и удаляем слова;
- Собираем общую и точную частотку;
- Применяем фильтр «0 или пустое значение по точной» и удаляем слова;
- Рассчитываем показатель KEI;
- Применяем фильтр «Пустышки» и удаляем слова;
- Фильтруем по стоп-словам;
- Пробегаемся по списку и руками фильтруем оставшиеся мусорные фразы;
- Делаем анализ неявных дублей;
- Собираем частотку Adwords по регионам для всех дублей;
- Делаем умную групповую отметку дублей.
В итоге получается достаточно хорошая и полная семантика, имеющая спрос в ПС. Останется правильно кластеризовать, составить ТЗ, опубликовать материалы и ждать профита)
Есть вопросы, задавайте в комментариях.
Ещё интересные материалы для вас:
Как мы сделали студию перманентного макияжа одним из лидеров в тематике и что случилось в период пандемии и самоизоляции
БРОВИ Permanent Make Up — студия перманентного макияжа на Васильевском острове. Квалифицированные мастера и безболезненные процедуры на страже красоты.
Баннер с главной страницы сайта brovi.spb.ru
Задача
Сотрудничество «Иващенко и Низамов» с этим клиентом началось в октябре 2018 года. И началось с ошибки. Так вышло, что при продаже мы упустили, что это сайт-одностраничник. Конечно, как только мы обнаружили свою ошибку (в первый же рабочий день по проекту), то принесли извинения клиенту и объяснили ему ситуацию. Однако клиент вооружился отвагой и решился писать сайт.
Первичная задача свелась к подготовке семантики, структуры и контента для заполнения будущего сайта.
С того момента, как выкатили сайт, конечно, стало важно увеличить трафик из органической выдачи поисковых систем и за счет этого повысить количество заявок с сайта.
Результат
Мы с нуля запустили продвижение сайта brovi.spb.ru в поисковых системах «Яндекс» и Google.
Ключевой показатель эффективности (KPI) в этом проекте — привлечение целевого трафика. При этом семантика присутствует как коммерческая, так и информационная. И инфотрафик тоже важен в данной тематике.
С марта 2019 года (в марте выкатили сайт) по март 2020 года поисковый трафик рос с внушающей скоростью. Новогодняя просадка понятна, а вот в конце марта Путин обратился к россиянам с обращением, и начались наши домашние будни.
Отчет по визитам на «Яндекс.Метрике»
Что для этого сделали
Провели анализ коммерческих факторов конкурентов
Чтобы у разрабов были наметки для работы с сайтом, мы проанализировали конкурентов и дали рекомендации, на что следует обратить внимание: не забыть добавить мессенджеры, кнопки взаимодействия, необходимую информацию в шапку.
Собрали список целевых запросов
Данный салон не работает в технике микроблейдинг. Однако такие запросы мы тоже взяли, ведь у салона с настолько крутыми специалистами есть причины для такого выбора. Эти запросы мы оставили для статей в блог: «почему микроблейдинг вреден», «чем пудровое напыление лучше микроблейдинга» и т. д.
Помимо общих запросов вроде «татуаж», «перманентный макияж бровей» и прочих категорийных ключей были взяты все известные техники татуажей — нанонапыление, пиксельное напыление, теневое напыление, эффект помады, стрелка, стрелка с тенью и так далее. Представители индустрия красоты всегда были падкими на новые громкие названия, поэтому порой одни и те же техники принципиально могут называться по-разному либо иметь незначительные отличия с одинаковым результатом.
Самые жирные запросы были взяты в раздел «Услуги», остальное без потерь ушло в блог.
Первичная семантика и позиции сайта на период старта работ
Также на основе кластеризации и конкурентов была предложена структура, которую мы отправили напрямую разработчику.
Написание контента
Тематика такая, что в топе — огромные полотна текста. И ладно, когда это инфозапросы вроде «можно ли мочить татуаж» (одна из популярных статей) или «можно ли делать татуаж при грудном вскармливании». Однако немало запросов смешанного интента, и надо пробиться сквозь огромное количество статейников.
Поисковая выдача по запросу «пудровые брови»
Первичные работы с сайтом
Добавили фавикон, sitemap, robots, убрали битые ссылки. Подчистили все ненужное, что оставили разрабы, добавили системы аналитики и прочее. Проанализировали, что к нам пришло, и начали работу по сайту.
Добавили мессенджеры (да, разраб все-таки забыл), режим работы, сертификаты, информацию о способах оплаты, реквизиты, онлайн-консультанта. На счет последнего пришлось с клиентом объясниться. Дело в том, что на старом сайте не было обращений через этот инструмент, и клиент не видел смысла в его установке. Однако мы напомнили ему, что на старом сайте и посетителей не было, к тому же это немаловажный коммерческий фактор. Так что, поспорив пару дней, мы настояли на своем.
Внедренные на сайт «примочки»
Микроразметка контактов
Для салона красоты очень важно отметить местоположение — карты, справочники и отработка страницы контактов стали приоритетными задачами.
«Яндекс.Вебмастер» — скрин от марта 2019 года
Правда, примерно после Нового года 2020 (уж сколько этот год принес нам новостей) микроразметка на этом и многих других проектах слетела и пришлось продублировать задачу.
«Яндекс.Вебмастер» — скрин от марта 2020 года
Добавили сайт в каталоги
Для улучшения ссылочной массы сайта стали прорабатывать «бесплатные» ссылки. Начали с тематических каталогов.
Страница клиента в каталоге spb-beauty.ru
Добавили на сайт соцсети клиента
Очень нравится, что клиент не просто имеет аккаунты во всех необходимых соцсетях, но и активно их ведет.
Канал клиента на YouTube: https://www.youtube.com/channel/UC1duk__bss_qpFFKMWNRvrg/featured
Оформили страницы мастеров
Проанализировали страницы мастеров на сайтах конкурентов и составили форму страницы, которую хотим получить мы. Совместно с разработчиком и клиентом собрали информацию для каждого специалиста салона. Очень радует, что клиент ответственно подходит к обновлению информации на сайте, и аватары мастеров периодически меняются.
Страница мастера. Скрин с сайта brovi.spb.ru
Прочие результаты
Конверсия отзывов
После введения карантина этот показатель пошел на спад. Хотя именно отзывы и примеры работ — достаточно важные сегменты информации для данной категории услуг.
Отчет «Яндекс.Метрики» — Конверсии, отзывы
Конверсия кнопки «записаться на прием»
Параметр «Достижение целей» с переходом на самоизоляцию уменьшился, однако процент конверсии не так сильно изменился.
Отчет «Яндекс.Метрики» — Конверсии, кнопка «Записаться»
Конкуренты
Статистика по «Яндексу» показывает, что сайт имеет основных конкурентов в лице отзовика и трех инфошников.
SEOWORK — Статистика по конкурентам в «Яндекс»
По Google конкурентов больше, и среди них достаточно сильные (с точки зрения видимости) — студия Ольги Добряковой и социальная сеть «Вконтакте», группы которой часто конвертят в заказы.
SEOWORK — Статистика по конкурентам в Google
Видимость сайта
В топ-10 вышли 37% запросов в «Яндексе» и 21% в Google. Стоит понимать, что подавляющая часть из них — это инфозапросы, и статьи ещё требуют доработки. Увеличение числа запросов в топ-10 — наша ближайшая задача.
SEOWORK — Метрика видимости всего семантического ядра
Видимость самого популярного кластера
Если выбрать отдельно сегмент «татуаж бровей» (кластер запросов, соответствующий этой странице), мы видим, что топ-10 составляют 66% категории.
SEOWORK— Метрики видимости для категории запросов «татуаж бровей»
Конкуренты по базовой частоте
%«WS»10 — это доля в частотности «WS» запросов, находящихся в топе-10, которая считается по формуле: %«WS»10 = «WS» запросов в топе-10 / «WS» всех запросов. По «Яндексу» мы имеем отличные показатели.
SEOWORK — 10 лучших конкурентов в «Яндекс» и Google за последние 14 сборов (2 раза в месяц)
Конкуренты по топ-10
%ТОП10 — это доля запросов находящихся в топе. По «Яндексу» прямых конкурентов у нас нет. Впереди только IRecommend.ru (сайт с отзывами на всё), площадка «Яндекс.Дзен» и парочка женских журналов. Результаты по Google чуть хуже: нас обгоняет dobryakovastudio, однако мы всё равно находимся в десятке лучших. Нам есть куда расти! Добрякова Ольга, мы ещё отвоюем топ! 🙂
SEOWORK — Конкуренты топе-10
Конкуренты по трафику
Метрика, сильно коррелирующая с трафиком (не клики или трафик, а именно относительная метрика), оценивается исходя из позиции запроса в топе-10 поисковой выдачи и частотности запроса. Считается по формуле:
PTraf = «WS» запроса × средний CTR позиции
При этом средний CTR позиции берутся из таблицы:
Например: запрос «купить телевизор» находится на 2-й позиции в «Яндексе» и на 3-ей позиции в Google. Частотность по WordStat —10356 просмотров. Подставим данные значения, пользуясь вышеуказанной таблицей, в формулу для расчета потенциального трафика:
PTraf («Яндекс») = 10356 * 0,07 (CTR 2 места в «Яндексе») = 724,92
PTraf (Google) = 10356 * 0,05 (CTR 3 места в Google) = 517,8
С помощью SEOWORK показатель PTraf можно посчитать для категории, группы, выборки, отдельного документа или для всего сайта, суммируя значения.
SEOWORK — Конкуренты (метрика трафика)
Видимость (топ-3)
Начинающие специалисты часто пренебрегают низкочастотными запросами, считая, что они не стоят отработанного времени. Однако вывести в топ НЧ-запросы легче, чем высокочастотные. Суммарно все низкочастотные запросы дают немалую долю трафика, поэтому не стоит про них забывать.
SEOWORK — Отчёт видимости по НЧ-запросам
Что делаем сейчас
Для улучшения позиций по уже написанным статьям запланированы реворки. Предварительно мы обновили семантику и кластеризовали запросы. В текстах будем менять вхождения ключевых слов, добавлять фотографии и видео в соответствии с точечным анализом конкурентов. Важно подтянуть инфотрафик и не потерять позиции по услугам.
На страницах с портфолио, статьями и услугами будут проработаны сниппеты посредством микроразметки данных для повышения кликабельности.
Что планируем сделать
Отзывы на сайте — это важный коммерческий фактор. Однако некоторые клиенты не доверяют им, считая, что плохие отзывы просто затираются администратором. Не многие посетители сайта понимают, откуда подтягивается эта информация (в нашем случае это spb.flamp.ru) и начинают искать информацию в интернете. Поэтому необходимо закрыть и этот сектор. Работа с SERM не влияет напрямую на SEO, однако не стоит упускать этот момент.
Работа с отзывами. Скрин с сайта brovi.spb.ru
Каталоги и справочники дадут дополнительную ссылочную массу, а заодно и повысят узнаваемость бренда.
Еще одно направление — контроль и внедрение дизайнерских работ на сайте. В процессе анализа конкурентов мы нашли много интересных идей, для реализации которых необходим дизайнер. Вот некоторые из них:
- добавить на сайт страницу «Требуются модели» с красивым, цепляющим баннером, чтобы привлечь аудиторию заинтересованных в услугах людей;
- разработать форму для проведения различных опросов и тестов, оформив кнопку на их прохождение красочной иллюстрацией, что не только улучшит поведенческие факторы, но и позволит пополнять базу потенциальных клиентов;
- создать динамичную инфографику, демонстрирующую эффекты различных видов татуажа, а также этапов процедуры, и другие советы по оформлению страниц с услугами и мастерами.
Очень ждем от разработчика настройку адаптивной версии сайта и работы по увеличению скорости загрузки страниц, так как мобильная версия крайне важна для данной тематики.
На сегодняшний день клиент доволен достигнутыми успехами и готов продолжать сотрудничество.
SEO в самоизоляции
Развивать и оптимизировать сайт никогда не поздно, и можно получить отличные результаты даже в конкурентных областях — стоит только захотеть. Периоды падения спроса можно использовать для кардинальных изменений, а пока ваши конкуренты жалеют денег на рекламу, вы можете занять более выгодные позиции.
SEO — это работа с сайтом, и результаты этой работы видны не сразу. Планируйте бюджет на рекламу с умом, и у вас всегда будут продажи!
Компания «Иващенко и Низамов» также занимается контекстом и таргетом. Если вы хотите получить постоянный поток клиентов, достаточно сделать первый шаг — связаться с нами и заказать бесплатный аудит сайта.
Кейс подготовлен SEO-специалистом Валентиной Данилюк. Менеджер проекта — Элина Япрынцева.
Как использовать функцию ЧАСТОТА (WS)
В этом руководстве Excel объясняется, как использовать функцию ЧАСТОТА Excel с синтаксисом и примерами.
Описание
Функция ЧАСТОТА в Microsoft Excel возвращает частоту появления значений в наборе данных. Он возвращает вертикальный массив чисел.
Функция ЧАСТОТА — это встроенная функция Excel, относящаяся к категории статистической функции . Его можно использовать как функцию рабочего листа (WS) в Excel.Как функцию рабочего листа, функцию ЧАСТОТА можно ввести как часть формулы в ячейку рабочего листа.
Синтаксис
Синтаксис функции ЧАСТОТА в Microsoft Excel:
ЧАСТОТА (данные, интервалы)
Параметры или аргументы
- данные
- Массив или диапазон значений, для которых нужно подсчитать частоты.
- интервалы
- Массив или диапазон интервалов, значения которых вы хотите сгруппировать в данных .
Возвращает
Функция ЧАСТОТА возвращает вертикальный массив чисел.
Относится к
- Excel для Office 365, Excel 2019, Excel 2016, Excel 2013, Excel 2011 для Mac, Excel 2010, Excel 2007, Excel 2003
Пример (как функция рабочего листа)
Давайте рассмотрим несколько примеров ЧАСТОТА в Excel и рассмотрим, как использовать функцию ЧАСТОТА в качестве функции рабочего листа в Microsoft Excel.
Начнем с простых примеров.
На основе приведенной выше таблицы Excel будут возвращены следующие примеры ЧАСТОТЫ:
= ЧАСТОТА (B2: B10, D2) Результат: 2 = ЧАСТОТА (B2: B10; D3) Результат: 3 = ЧАСТОТА (B2: B10; D4) Результат: 5 = ЧАСТОТА (B2: B10; D5) Результат: 7 = ЧАСТОТА (B2: B10,89) Результат: 7 (аналогично предыдущему)
В этих примерах просто просматриваются данные, находящиеся в ячейках B2: B10, и вычисляются все значения, которые ниже второго параметра.Так в случае:
= ЧАСТОТА (B2: B10, D5) Результат: 7
В ячейках B2: B10 указано 7 результатов тестов <= 89.
Пример
Теперь давайте рассмотрим более сложный пример с формулами массива.
При создании формулы массива необходимо использовать Ctrl + Shift + Введите вместо Введите при заполнении формулы. В результате ваша формула будет заключена в квадратные скобки.Об этом очень важно помнить. Если формула не заключена в скобки {}, она НЕ интерпретируется Excel как формула массива.
На основе приведенной выше электронной таблицы следующая формула Excel {= ЧАСТОТА (B2: B12, D2: D5)} в ячейки E2: E6 с помощью Ctrl + Shift + Введите , чтобы завершить формулу. Это вернет вертикальный массив с 5 значениями следующим образом:
Первое значение в массиве будет отображаться в ячейке E2.Результатом будет 2 (потому что 2 тестовых балла <= 59).
-секундное значение в массиве будет отображаться в ячейке E3. Результатом будет 1 (потому что 1 тестовый балл находится между 60 и 69).
Третье значение в массиве будет отображаться в ячейке E4. Результатом будет 2 (потому что есть 2 тестовых балла от 70 до 79).
, четвертое значение в массиве будет отображаться в ячейке E5. Результатом будет 3 (потому что есть 3 результата теста между 80 и 89).
Пятое значение в массиве будет отображаться в ячейке E6. Результатом будет 3 (потому что 3 тестовых балла> 89). Это захватывает все значения, превышающие последнее значение в интервале.
Часто задаваемые вопросы
Вопрос: В Microsoft Excel я пытаюсь использовать ЧАСТОТА для вычисления частот на основе 5-минутных интервалов, но мне не удается заставить функцию ЧАСТОТА правильно сгруппировать значения. Вот скриншот того, что у меня есть:
Я использую формулу:
{= ЧАСТОТА (B2: B12, D2: D9)} Как видите, существует шесть значений «8:40:00 AM», но они отображаются в интервале «8:45:00 AM».Это почему?
Ответ: Значение Microsoft Excel «8:40:00 AM» фактически сохраняется как числовое значение 0,361111111111111 с повторяющейся единицей 1. Excel должен неявно округлять значение времени во время вычислений ЧАСТОТЫ. Чтобы решить эту проблему, округлите данные и интервалы до 13 десятичных знаков следующим образом:
{= ЧАСТОТА (КРУГЛЫЙ (B2: B12,13), КРУГЛЫЙ (D2: D9,13))} Теперь, если мы посмотрим на результаты, функция ЧАСТОТА, кажется, правильно группирует временные интервалы, и шесть значений «8:40:00 AM» отображаются под правильным интервалом.
Этот сайт использует файлы cookie для повышения производительности. Если ваш браузер не принимает файлы cookie, вы не можете просматривать этот сайт.
Настройка вашего браузера для приема файлов cookie
Существует множество причин, по которым cookie не может быть установлен правильно. Ниже приведены наиболее частые причины:
- В вашем браузере отключены файлы cookie. Вам необходимо сбросить настройки своего браузера, чтобы он принимал файлы cookie, или чтобы спросить, хотите ли вы принимать файлы cookie.
- Ваш браузер спрашивает вас, хотите ли вы принимать файлы cookie, и вы отказались. Чтобы принять файлы cookie с этого сайта, нажмите кнопку «Назад» и примите файлы cookie.
- Ваш браузер не поддерживает файлы cookie. Если вы подозреваете это, попробуйте другой браузер.
- Дата на вашем компьютере в прошлом. Если часы вашего компьютера показывают дату до 1 января 1970 г., браузер автоматически забудет файл cookie. Чтобы исправить это, установите правильное время и дату на своем компьютере.
- Вы установили приложение, которое отслеживает или блокирует установку файлов cookie. Вы должны отключить приложение при входе в систему или проконсультироваться с системным администратором.
Почему этому сайту требуются файлы cookie?
Этот сайт использует файлы cookie для повышения производительности, запоминая, что вы вошли в систему, когда переходите со страницы на страницу. Чтобы предоставить доступ без файлов cookie потребует, чтобы сайт создавал новый сеанс для каждой посещаемой страницы, что замедляет работу системы до неприемлемого уровня.
Что сохраняется в файле cookie?
Этот сайт не хранит ничего, кроме автоматически сгенерированного идентификатора сеанса в cookie; никакая другая информация не фиксируется.
Как правило, в файлах cookie может храниться только информация, которую вы предоставляете, или выбор, который вы делаете при посещении веб-сайта. Например, сайт не может определить ваше имя электронной почты, пока вы не введете его. Разрешение веб-сайту создавать файлы cookie не дает этому или любому другому сайту доступа к остальной части вашего компьютера, и только сайт, который создал файл cookie, может его прочитать.
WS-15: 1-й семинар по ортогональной пространственно-временной модуляции (OTFS) для 6G и будущей высокоскоростной связи | Международная конференция по коммуникациям IEEE
1-й СЕМИНАР ПО ОРТОГОНАЛЬНОЙ ВРЕМЕННО-ЧАСТОТНО-ПРОСТРАНСТВЕННОЙ МОДУЛЯЦИИ (OTFS) ДЛЯ 6G И БУДУЩЕЙ ВЫСОКОМОБИЛЬНОЙ СВЯЗИ
Июнь 2021 г., Монреаль, Канада
Объявлена программа семинара
СОПРЕДСЕДАТЕЛИ МАСТЕРСКОЙ:
ЧЛЕНЫ РУКОВОДСТВА:
- Др.Ронни Хадани , главный научный сотрудник, Cohere Technologies, США, ([email protected])
- Проф. Лайош Ханзо , Саутгемптонский университет, Великобритания ([email protected])
- Проф. Эмануэле Витербо , Университет Монаша, Австралия ([email protected])
- Проф. Вэй Юй , Университет Торонто, Канада ( [email protected] )
- Проф. Пинчжи Фань , Юго-западный университет Цзяотун, Китай (pzfan @ swjtu.edu.cn)
СОПРЕДСЕДАТЕЛИ TPC:
- Проф. Анантанараянан Чоккалингам , Индийский институт науки, Индия ([email protected])
- Проф. Баомин Бай , Сидянский университет, Китай ([email protected])
- Проф. Джулио Колавольпе , Университет Пармы, Италия ([email protected])
- Доктор Вейджи Юань , Университет Нового Южного Уэльса, Австралия ([email protected])
- Др.Чжицян Вэй , Университет Нового Южного Уэльса, Австралия ([email protected])
ОСНОВНЫЕ ДИНАМИКИ:
- Д-р Ронни Хадани , главный научный сотрудник, Cohere Technologies, США
- Проф. Эмануэле Витербо , Университет Монаша, Австралия
ОБЪЕМ И ТЕМЫ СЕМИНАРА
Ожидается, что будущие беспроводные сети обеспечат высокоскоростную и сверхнадежную связь для широкого спектра новых мобильных приложений, включая онлайн-игры, связь между транспортными средствами (V2X) и высокоскоростные железнодорожные системы.Связь в сценариях с высокой мобильностью страдает от сильных доплеровских расширений каналов, которые ухудшают характеристики широко распространенной модуляции мультиплексирования с ортогональным частотным разделением каналов (OFDM) в текущих сетях четвертого поколения (4G) и новых пятого поколения (5G). С другой стороны, перегрузка спектра в полосах частот 6 ГГц и приложения, требующие обработки данных, делают желательной связь в диапазонах высоких частот, таких как диапазоны миллиметровых волн (миллиметровые волны) в диапазоне от 30 ГГц до 300 ГГц с гораздо более широкой доступной полосой пропускания.
Недавно была предложена новая двумерная (2D) схема модуляции, называемая ортогональным частотно-временным пространством (OTFS), в которой информационные символы мультиплексируются в области задержки-Доплера (DD), а не в частотно-временной (TF). как традиционные методы модуляции. Мультиплексирование в области DD дает возможность учесть нарушения канала, такие как задержка и доплеровские сдвиги, и обеспечить преимущества устойчивости к задержке и доплеровскому сдвигу. Что еще более важно, OTFS использует полное частотно-временное разнесение канала, что является ключом к обеспечению надежной связи.Кроме того, модуляция OTFS эффективно преобразует изменяющийся во времени канал в эффективный 2D-канал, не зависящий от времени в области DD, где проявляются привлекательные свойства, такие как разделимость, компактность, стабильность и, возможно, разреженность, и которые потенциально могут быть использованы для OTFS. системные конструкции.
Поскольку существующие принципы и технологии проектирования беспроводной связи были в основном предназначены для характеристик канала с низкой мобильностью на низкой несущей частоте, OTFS представляет новые критические проблемы для архитектуры приемопередатчиков и разработки алгоритмов.Чтобы полностью раскрыть потенциал OTFS, необходимо решить сложные фундаментальные исследовательские проблемы и многие практические вопросы проектирования, включая оценку канала, методы обнаружения и проектирование систем с несколькими антеннами и пользователями. Этот семинар направлен на объединение академических и промышленных исследователей для выявления и обсуждения основных технических проблем, недавних достижений и новых приложений, связанных с OTFS. Темы, представляющие интерес, включают, но не ограничиваются:
- Измерение и моделирование каналов в области DD
- Основная информация Теоретические пределы для OTFS
- Масштабирование емкости OTFS для многоантенных и многопользовательских систем
- Обработка сигналов для конструкций приемопередатчиков OTFS
- Оценка канала для OTFS
- Конструкция приемника ОТФС
- Машинное обучение / усовершенствованный ИИ OTFS
- MIMO и массивный дизайн MIMO для OTFS
- Схемы множественного доступа для OTFS
- Сетевые архитектуры и протоколы передачи для OTFS
- Моделирование, прототипирование и полевые испытания на системном уровне для OTFS
- Стандартизация OTFS
- Совместная РЛС и связь через ОТФС
- Проекты фильтров доменов DD и TF для OTFS
- Проекты окон приема и передачи для OTFS
- Анализ производительности системы OTFS с кодировкой
- Сосуществование сигнализации 5G и OTFS
- Системы FDD и TDD OTFS
- OTFS для URLLC
- Проблемы безопасности и конфиденциальности в OTFS
- Применение OTFS в ммWave и Tera Hertz
ВАЖНЫЕ ДАТЫ
| Подача статей | 19 февраля 2021 (ФИРМА) |
| Извещение о приемке | 22 марта 2021 г. |
| Подача заключительных документов | 8 апреля 2021 (ФИРМА) |
| Дата семинара | TBA |
ССЫЛКА ДЛЯ ПОДАЧИ
https: // edas.info / N27513
Раздел Env-Ws 360.13 — Частота проверок систем водоснабжения общего пользования, Администрация кодекса штата Нью-Йорк. R. Env-Ws 360.13
Текущий через регистр Vol. 41, No. 14, 8 апреля 2021 г.
Раздел Env-Ws 360.13 — Частота проверок систем водоснабжения общего пользования (a) Владелец системы водоснабжения должен проверять систему в соответствии со следующим: (1) Источники насосных станций и бустерные станции без обработки должны проверяться не реже одного раза в месяц; (2) Такие объекты, как камеры понижения давления и выпускные клапаны воздуха, должны проверяться не реже одного раза в 6 месяцев; (3) Связанные со здоровьем неострые процессы однофункциональной обработки добавлением химикатов должны проверяться не реже одного раза в 2 дня; (4) Процессы однофункциональной обработки, связанные со здоровьем бактерий, при наличии контаминантов навыше ПДК, должны проверяться не реже одного раза в день.
(5) Процессы обработки нитратов / нитритов должны проверяться не реже одного раза в неделю; (6) Объекты полной поверхностной фильтрации воды, за исключением установок медленной фильтрации песка, должны проверяться каждый день; и (7) Не связанные со здоровьем очистные сооружения, кроме медленных песочных фильтров, должны проверяться не реже одного раза в неделю. (b) Владелец системы может запросить сокращение частоты проверок, указанных выше, в зависимости от: (1) Тип загрязнителя; (2) Уровень дублирования и резервирования оборудования; и (3) Уровень онлайн-телеметрического мониторинга концентрации загрязняющих веществ. (c) Лицо, проводящее инспекцию, должно знать оборудование и функции, требующие действий или технического обслуживания, но это лицо не должно быть сертифицированным оператором. (d) Сертифицированный оператор должен определить конкретные функции, которые должны выполняться при этих проверках. (e) Владелец или оператор по указанию владельца должен вести записи всех проверок. Эти записи должны быть доступны для просмотра сотрудниками отдела.N.H. Code Admin. R. Env-Ws 360.13
(см. Примечание к редакции в заголовке главы Env-Ws 300) # 6521, eff 6-4-97; ss by # 8360, INTERIM, eff 6-4-05, СРОК ДЕЙСТВИЯ: 12-1-05; ss by # 8475, eff 11-30-05
Чебышевский тип II фильтр заказ
Частота угла (отсечки) полосы пропускания, заданная как скаляр или двухэлементный вектор
со значениями от 0 до 1 включительно, где 1 соответствует нормализованному Найквисту
частота, π рад / отсчет.Для цифровых фильтров единица полосы пропускания
угловая частота в радианах на выборку. Для аналоговых фильтров угловая частота полосы пропускания
измеряется в радианах в секунду, а полоса пропускания может быть бесконечной. Ценности Wp и Ws определяют тип фильтра
cheb2ord возвращает:
Если
WpиWsявляются скалярами иWp<Ws, затемcheb2ordвозвращает порядок и частоту среза фильтр нижних частот.Полоса заграждения фильтра колеблется отWsдо 1, а полоса пропускания находится в диапазоне от 0 доWp.Если
WpиWsявляются скалярами иWp>Ws, затемcheb2ordвозвращает порядок и частоту среза фильтр верхних частот. Полоса заграждения фильтра колеблется от 0 доWs, а полоса пропускания колеблется отWpдо 1.Если
WpиWsявляются векторами и интервал, указанный вWs, содержит указанный интервал поWp(Ws (1)<Wp (1)<Wp (2)<Ws (2)), тоcheb2ordвозвращает порядок и частоты среза полосовой фильтр. Полоса заграждения фильтра колеблется от 0 доWs (1)и сWs (2)до 1.Полоса пропускания варьируется отВт (1)доВт (2).Если
WpиWsявляются векторами и интервал, указанный вWp, содержит указанный интервал поWs(Wp (1)<Ws (1)<Ws (2)<Wp (2)), тоcheb2ordвозвращает порядок и частоты среза полосовой фильтр.Полоса заграждения фильтра составляет отВт (1)кWs (2). Полоса пропускания колеблется от 0 доWp (1)и отWp (2) отдо 1.Используйте следующее руководство, чтобы указать фильтры различных типов.
Тип фильтра Характеристики полосы задерживания и полосы пропускания
Тип фильтра
Условия полосы задерживания и полосы пропускания
0346 905 Lowpass Wp<Ws, оба скаляры(Ws, 1)(0, Wp)Highpass
Wp3>Wp, оба скаляры(0, Ws)(Wp, 1)Bandpass
Интервал, указанный в
Ws, содержит один, указанный вWp(Ws (1)). (0, Ws (1))и(Ws (2), 1)(Wp (1), Wp (2))Bandstop
Интервал, указанный в
Wp, содержит один, указанный вWs(Wp (1)). (0, Wp (1))и(Wp (2), 1)(Ws (1), Ws (2))
Типы данных: одиночный | двойной
Возможность настройки метаматериала треугольного SRR и проволочной ленты (TSRR-WS) на ТГц
В этой статье описывается новый настраиваемый метаматериал, состоящий из треугольного разрезного кольцевого резонатора (TSRR) и проволочной ленты (WS) на частоте ТГц.Имитатор высокочастотной структуры Ansoft (HFSS) был использован для проектирования и анализа метаматериала, имеющего Rogers RT / duroid 5870 (= 2,33) и FR4 (= 4,4) в качестве материала подложки. Метод Николсона Росс Вейра (NRW) использовался для получения параметров материала по коэффициенту пропускания и отражения. При использовании FR4 с толщиной подложки 0,75 мкм м вместо 1,25 мкм м было получено 4% максимизации в расположении отрицательной области (или резонансной частоты для проницаемости).Кроме того, минимизация на 18% была достигнута за счет использования FR4 с 0,25 мкм мкм вместо подложки RT / duroid 5870 с той же толщиной. Возможность настройки была подтверждена путем демонстрации зависимости резонансной частоты от толщины и материала подложки.
1. Введение
«Метаматериалы» (МТМ) разработаны для изменения объемной проницаемости и / или диэлектрической проницаемости среды. Это реализуется путем размещения периодически изменяющих параметры материала структур с элементами, размер которых меньше длины волны падающей электромагнитной волны.Это приводит к «мета», то есть «измененному» поведению или поведению, недостижимому для природных материалов. Незначительные изменения повторяющейся элементарной ячейки могут быть использованы для настройки эффективных свойств объемного материала MTM, заменив необходимость поиска подходящих материалов для применения на возможность спроектировать структуру для достижения желаемого эффекта. Примерами МТМ являются одиночные отрицательные материалы (SNG), такие как ε, отрицательные (ENG), которые имеют эффективную отрицательную диэлектрическую проницаемость, и мкм отрицательные (MNG), которые имеют эффективную отрицательную проницаемость, и двойные отрицательные материалы (DNG).
Последние несколько лет были очень насыщенными с точки зрения эволюции концепции и внедрения «леворуких материалов (LHM)». Перекрестное произведение E и H пропорционально вектору k и полю E или H . Эти векторы подчиняются правилу правой руки. Поток мощности описывается вектором Пойнтинга ( S ). Материальные ценности, представляющие особый интерес для электромагнитного сообщества, - это значения диэлектрической проницаемости, ε , и проницаемости, μ .Взятые вместе, ε и μ определяют скорость распространения электромагнитного излучения в среде, а квадратный корень из их произведения определяет показатель преломления ( n ). Реальный волновой вектор указывает на распространяющуюся волну, в то время как воображаемый волновой вектор указывает на затухание (исчезающая волна). Следовательно, при входе в среду с измененными параметрами материала, то есть отрицательными ε и μ , групповая и фазовая скорости имеют противоположные знаки и антипараллельны, что указывает на то, что волновые фронты движутся к источнику в этом материале, создавая «обратный ход». волна.Однако вектор Пойнтинга, который определяется, по-прежнему положительный, сила уходит от источника и сохраняется причинность. Таким образом, вектор S следует правилу правой руки, в то время как вектор k антипараллелен вектору S . Это можно проиллюстрировать на рисунке 1.
В таблице 1 показаны правила знаков для показателя преломления материала, а в таблице 2 представлены некоторые основные свойства и названия материалов для различных комбинаций проницаемости и диэлектрической проницаемости.
Представлен свежий подход к микроволновым и оптическим приборам. lf с интересным прорывом в области МТМ на высоких частотах.Потребность в часе состоит в том, чтобы оптимизировать параметры антенны (усиление, полосу пропускания и направленность) без изменения ее размеров, то есть внешний контроль над параметрами антенны с помощью MTM. Программный инструмент имитатор высокочастотной структуры (HFSS) используется потому, что это высокопроизводительный симулятор полноволнового электромагнитного (ЭМ) поля для произвольного трехмерного объемного моделирования пассивных устройств. Он объединяет моделирование, визуализацию, твердотельное моделирование и автоматизацию в удобной для изучения среде, в которой быстро и точно получаются решения трехмерных электромагнитных проблем [1]. В разделе 2 рассматривается метаматериал в области высоких частот, в том числе в режиме ТГц. Раздел 3 сокращает конструкцию метаматериала, состоящего из треугольного SRR и проволочной ленты. Раздел 4 иллюстрирует возможность настройки метаматериала с различной толщиной подложки и материалом подложки. Раздел 5 завершает статью. 2. Метаматериалы на высоких частотах (включая режим ТГц)Терагерцовую область электромагнитного спектра можно определить как область высоких частот 0.1–10 ТГц и ограничивая микроволновую и среднюю инфракрасную области. За последние двадцать лет было замечено множество приложений, реализующих «терагерцовый промежуток». Демонстрация поведения LH была проведена с помощью двух схем: первая - это SRR с проволочными структурами, а вторая - закрытая SRR с проволочными структурами [2], как показано на рисунке 2 (a). Измеренный спектр пропускания дает первую ширину запрещенной зоны (3,55–4,0 ГГц) в SRR, а не в среде CSRR. В нем говорится, что стоп-зона среды SRR не может быть автоматически отнесена к отрицательному поведению μ ; некоторые наблюдаемые промежутки могут также возникать из-за электрического отклика SRR или из-за брэгговских промежутков из-за периодичности.Кроме того, это доказывает, что SRR вносят вклад в эффективную диэлектрическую проницаемость композитных MTM (CMM), вызывая сдвиг вниз плазменной частоты, определяемой исключительно из проволочных структур. Также было замечено, что увеличение количества слоев уменьшало фазу прошедшей ЭМ волны в области частот LH. Еще одна демонстрация отрицательной диэлектрической проницаемости МТМ была проведена с помощью структурной элементарной ячейки предлагаемого электрического дискового резонатора, который состоял из двух дисков, соединенных центральной стойкой, как на рисунке 2 (b).Используя закон Ампера, мы можем связать поток на гранях диска и резонансное поведение элементарной ячейки МЭД. Выше резонансной частоты элементарной ячейки эффективная диэлектрическая проницаемость отрицательна, а частота электрического резонанса не зависит от емкости утечки между пластинами и стойкой. Было замечено, что электрическое поле меняет направление на противоположное чуть выше или чуть ниже резонансной частоты элементарной ячейки, таким образом отображая отрицательные значения ε симулятором высокочастотной структуры Ansoft. Образец MTM, состоящий из гексаферритовой пластины и металлического массива параллельных проводов, обеспечивает соответствующие отрицательные значения эффективной проницаемости в частотной области, которая перекрывает область с отрицательной диэлектрической проницаемостью [3], как показано на рисунке 2 (c). Выражение тензора эффективной диэлектрической проницаемости утверждает, что подобласть отрицательных значений диэлектрической проницаемости может контролироваться путем изменения некоторых параметров в конечном диапазоне. Было замечено, что для более тонких проводов максимум диэлектрической проницаемости смещается в сторону более высоких частот, но величина диэлектрической проницаемости уменьшается. Grbic [4] продемонстрировал 2D композитную среду, которая имеет широкополосную отрицательную проницаемость и отрицательную диэлектрическую проницаемость, как на рисунке 2 (d). Среда была изотропной и показывала поведение ЛГ в диапазоне 60%. В широкополосной среде с отрицательной проницаемостью использовались встроенные резонансные элементы (миниатюрные SRR), настроенные на разные частоты и разделенные слоями инверторов импеданса. SRR квадратной формы с металлическими полосами, заполненными сосредоточенными конденсаторами, имеющими вертикальный провод, реагировали на направленное электрическое поле z в центре элементарной ячейки и давали отрицательную величину ε .Ansoft HFSS использовался для определения 60% полосы пропускания LH с центральной частотой там, где левая полоса (обратная волна) пересекает световую линию. В ссылках [5–9] во всех статьях использовались сокращенные микроволновые частоты (X-диапазон или ниже). Сообщается о первом электромагнитном метаматериале, полученном микротехнологией [10]. За счет уменьшения общего структурного размера стержневой SRR ниже 100 мкм, м и структурных деталей до 5 мкм м частота, на которой композитный материал демонстрирует электромагнитное поведение MTM, увеличилась (до нескольких ТГц).Расчетные данные конструкции были определены с использованием аналитических формул Пендри [7], а также численного моделирования с помощью микроволновой студии. Было рассмотрено пять геометрических вариантов путем замены r , d , c , l . Эта структура обладает электромагнитными свойствами в диапазоне 1–2,7 ТГц. Таким образом, спектральный диапазон расширен на три порядка. Две разные планарные МТМ, состоящие из элементарной ячейки SRR и eSRR, были изготовлены на собственной подложке GaAs [11].Это обеспечило активное и динамическое управление МТМ на ТГц частотах с помощью динамически переключаемых ТГц МТМ. Используя сверхрешетку наноостровков ErAs / GaAs, было достигнуто очень короткое время жизни носителей заряда и сверхбыстрое переключение восстановления резонанса МТМ. Все устройства ТГц МТМ с электронным переключением являются гибридом диодной структуры Шоттки и массива eSRR, где необходимо соединить все eSRR вместе, служащие контактом Шоттки. Доказано, что нет ни сдвига резонансной частоты, ни изменения резонансной силы eSRR при соединении проводов.Фотовозбуждение использовалось для изменения значений ε (реальных) при резонансе. Однако при отсутствии фотовозбуждения наблюдается сильный резонансный провал. Шесть исходных элементарных ячеек MTM (OE1 – OE6) и их дополнений (CE1 – CE6), которые представляют собой планарные электрические разъемные кольцевые резонаторы (eSRR), MTM и их соответствующие обратные структуры [4] были спроектированы, смоделированы и охарактеризованы, как показано на Рисунок 3 (а), которые являются резонансными на частотах ТГц. Подобно принципу Бабине, их дополнительные свойства передачи связаны со свойствами, полученными с помощью ТГц спектроскопии во временной области (THz-TDS).Это проиллюстрировало, что отклики Друде и Лоренца приводят к максимуму передачи комплементарного MTM, а второй минимум передачи (OE) или максимум (CE) был результатом возбуждения электрических диполей. Также наблюдались различные типы субволновых резонаторов, например, тонкая проволока, рулоны, SRR, пара стержней, пара крестовин и eSRR [12], как показано на рисунках 3 (b) –3 (d). Экспериментально доказано, что плоская пластина из метаматериала может действовать как волновод в ТГц диапазоне частот, то есть как структура кольцевого разрезного резонатора, тем самым отображая сильные резонансы лоренцевского типа на желаемых частотах [13].Любую волноводную моду можно возбудить с помощью ТГц спектроскопии TD-ATR. Здесь через призму НПВО генерировалось затухающее поле, которое взаимодействовало с образцом, и, таким образом, возбуждалась собственная мода, при условии, что ее волновое число равно волновому числу затухающего поля. Было показано, что там, где пересекаются дисперсионные кривые волноводных мод и затухающего поля, возбуждается волноводная мода. 3. Предлагаемый MTMБыл предложен перестраиваемый метаматериал, имеющий электрический и магнитный резонанс [14, 15].Он ведет себя как DNG, то есть двойная отрицательная группа. Такие материалы имеют отрицательную проницаемость и отрицательную диэлектрическую проницаемость в некоторой области частот [16]. Восстановление параметров, то есть извлечение параметров с использованием параметров S [9], было выполнено с использованием подхода NRW для наблюдения области отрицательной проницаемости SRR MTM. 3.1. Конструктивные особенностиСостоит из треугольного SRR и проволочной ленты. На рис. 4 показана геометрия элементарной ячейки, имеющей TSRR на одной стороне и WS на другой стороне материала подложки.TSRR и WS состоят из меди с проводимостью 5,8 * 10 -7 См / м и толщиной 35 нм. WS проходит по всей подложке с шириной полосы 0,5 мкм м. Ширина TSRR составляет 0,3 мкм м, а расстояние между двумя TSSR составляет 0,4 мкм м. Основание треугольника 7,794 мкм м, высота треугольника 6,75 мкм м. В качестве подложки используются два типа материалов: FR4 (с относительной диэлектрической проницаемостью и тангенс угла потерь ± = 0:02) и Rogers RT / duroid 5880 (с относительной диэлектрической проницаемостью).SRR представляют собой металлические кольца из металла с введенным в его структуру разрезом. Когда ток циркулирует по катушке, он создает магнитный дипольный момент. Вектор генерируемого дипольного момента расположен под прямым углом к плоскости катушки. Катушка с пластинчатым конденсатором вместе дает нам LC-контур и, следовательно, увеличенный дипольный момент в его резонансе. Таким образом, данную структуру можно рассматривать как резонансную структуру типа ЖК с резонансной частотой, задаваемой формулой где емкость () в обычных вложенных МТМ на основе SRR формируется за счет стыковки кромок между внутренним и внешним кольцами.Когда толщина подложки уменьшается, емкость увеличивается, и, следовательно, резонансная частота уменьшается. 3.2. Результаты моделированияAnsoft HFSS использовался для моделирования элементарной ячейки, спроектированной на Рисунке 5 (а), имеющей метаматериал в диэлектрической подложке, ограниченной коробкой с обеих сторон, имеющей воздух в качестве материала и границу излучения. При моделировании используются открытые, электрические, магнитные и периодические граничные условия. Каждая конфигурация помещена в двухпортовый волновод, образованный парой стенок из идеального электрического проводника (PEC) и идеального магнитного проводника (PMC).Все подложки FR4 с TSRR и WS центрируются в волноводе. Границы и сосредоточенные порты (1 и 2) назначены согласно рисункам 5 (b), 5 (c) и 5 (d). Метод Николсона Росс Вейра (NRW) использовался для расчета свойств материала по коэффициентам пропускания и отражения. Подход NRW [11] начинается с введения составных членов, Затем рассчитайте диэлектрическую проницаемость и магнитную проницаемость по формуле 4. Возможность настройкиВозможность настройки была достигнута путем изменения толщины подложки и проверки ее влияния на резонансную частоту проницаемости МТМ и плазменную частоту диэлектрической проницаемости МТМ.Это поможет нам понять, как смещаются резонансная частота и плазменная частота при изменении толщины подложки: 0,25 мкм м, 0,5 мкм м, 0,75 мкм м и 1,25 мкм м. Это исследование было выполнено сначала с использованием дуроида RT в качестве субстрата, а затем FR4 в качестве субстрата. На рисунках 6 (a), 6 (b), 6 (c) и 6 (d) показаны изменения резонансной частоты проницаемости, а на рисунках 7 (a) –7 (d) показаны изменения плазменной частоты диэлектрической проницаемости с RT. дюроид в качестве субстрата ().В таблице 3 приведены изменения плазменной частоты диэлектрической проницаемости и резонансной частоты проницаемости для различной толщины подложки для подложки из твердого сплава RT.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||