Wordstat Яндекс: как использовать в маркетинге
Содержание
- Что такое Яндекс Вордстат
- Какие задачи помогает решать сервис Яндекс.Подбор слов
- Сервис Яндекс.Подбор слов — преимущества и недостатки
- Статистика Яндекс Wordstat — что показывает
- Виды частотностей Wordstat
- Базовая частотность
- Фразовая частотность
- Точная частотность
- Все операторы Подбора слов Яндекса и их назначения
- Как маркетологу или владельцу бизнеса работать с Яндекс Wordstat
- Как смотреть сезонность
- Как разделить показы по регионам
- Как оценить популярность запросов Wordstat по типу устройств
- Как собрать семантическое ядро сайта в Wordstat
- Расширения для браузера при работе с Wordstat
- Как отключить капчу в Вордстате
- Когда Яндекс Wordstat считает запросы похожими
Узнаете, как работать с сервисом Яндекс Wordstat маркетологу, какие задачи помогает решить и почему Вордстат запрашивает капчу.
Что такое Яндекс Вордстат
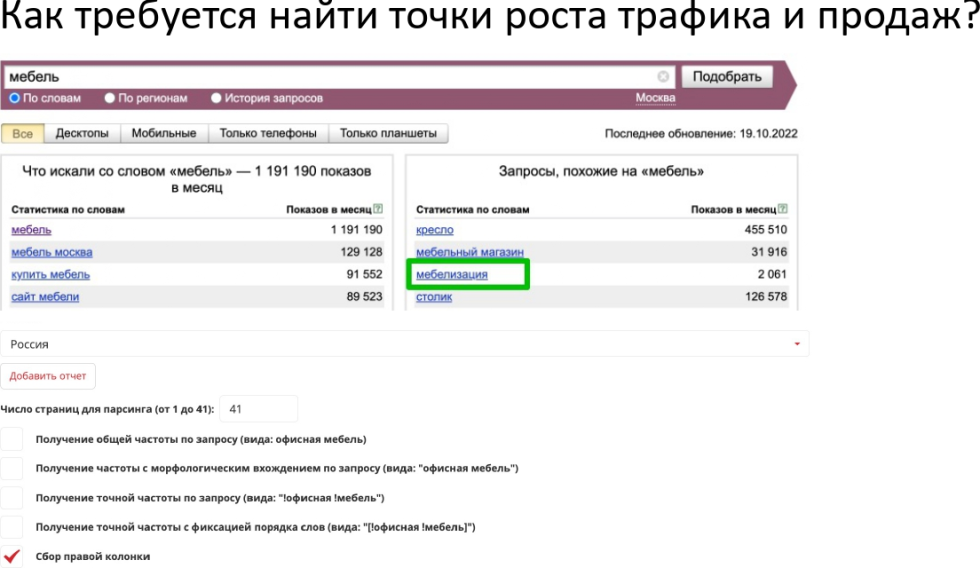
Яндекс.Подбор слов, Яндекс Wordstat или просто Wordstat — бесплатный сервис для определения популярности поисковых запросов. С его помощью можно проанализировать интерес аудитории к теме, проверить спрос на товар или услугу. Сервис подсчитывает количество показов в поисковике Яндекса по заданным ключевым словам за последний месяц, а также показывает историю показов за последние 2 года.
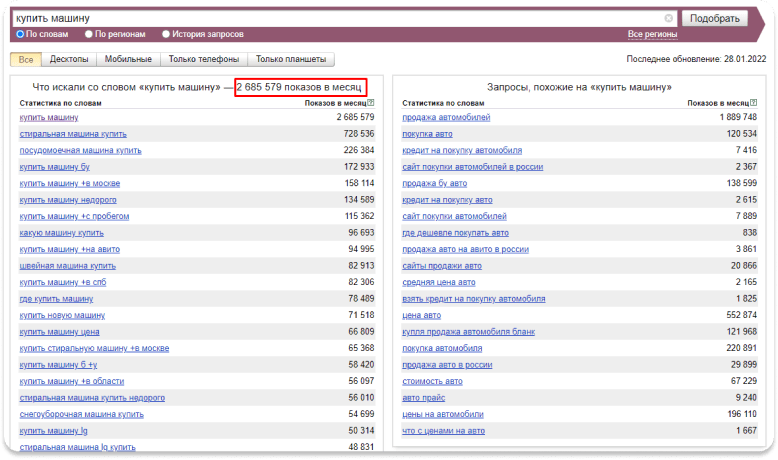
Пример: вводим запрос «купить фен москва» — Вордстат собрал статистику по этому ключевому слову в двух колонках:
Слева — данные по показам, которые включают указанное слово или фразу. Справа — похожие на указанное слово или фразу запросыКакие задачи помогает решать сервис Яндекс.Подбор слов
1. Собрать семантическое ядро. Первый инструмент, с которого нужно начинать поиск ключевых слов, — Яндекс Вордстат. Семантика нужна для SEO и запуска контекстной рекламы. Изучите популярные запросы — поймёте, какие из них стоит взять на заметку, а какие не понадобятся.
Хотите освоить сквозную аналитику?
Посетите регулярный мастер-класс по аналитике от Roistat.
Подключиться2. Выбрать тему для публикации. Когда не знаете, о чём написать в первую очередь, проверьте ваши темы в Подборе слов. Статистика ключевых слов подскажет, что интересует пользователей больше, а какие темы «гуглят» реже.
3. Оценить сезонность продукта. Wordstat хранит данные по показам ключевых слов в выдаче Яндекса за последние два года. Можно посмотреть, были ли пики популярности запроса в какие-либо периоды года и узнать, как меняется популярность запросов в зависимости от сезона. Для этого выберите селектор «История запросов» и изучите график. Подробнее о том, как работать с сезонностью в Вордстате, расскажем дальше.
4. Найти новые регионы для продажи продукта. Чтобы посмотреть, в каких регионах популярен ваш запрос, выберите селектор «По регионам» под поисковой строкой Поиска слов.
Сервис Яндекс.
 Подбор слов — преимущества и недостатки
Подбор слов — преимущества и недостатки| ➕ | ➖ |
| На одном экране Яндекс Вордстат показывает частотность ключей и подсвечивает похожие запросы — не нужно искать отдельно по каждой словоформе | Яндекс.Wordstat не указывает на тренды — сервис ищет похожие запросы, а не показывает, что популярно в поисковике |
| С помощью «Истории запросов» можно оценить сезонность ключей | Результаты поиска ограничены. На одной странице не более 50 запросов, максимум — 40 страниц |
| Сервис покажет статистику по указанным регионам | Сбор ключевых слов из Wordstat основан на ручном добавлении запросов, не учитывает семантику конкурентов. Если вам нужно полноценное семантическое ядро — необходимо использовать дополнительные сервисы |
| Можно использовать расширения для Wordstat, чтобы быстро собирать семантику | Перед каждым новым поиском нужно заполнять «капчу» |
Статистика Яндекс Wordstat — что показывает
Основная информация, которую собирает и выдаёт сервис — количество показов в месяц по искомому запросу. Эту цифру также называют поисковым спросом или частотностью. Справа от каждого ключевого слова находится цифра, которая фиксирует частотность:
Эту цифру также называют поисковым спросом или частотностью. Справа от каждого ключевого слова находится цифра, которая фиксирует частотность:
Информация в Яндекс Вордстат приблизительная: данные по запросу включают все показы в поисковой выдаче с введёнными ключевыми словами. Например, в запрос «фен строительный» входят показы как по запросам «фен строительный купить», так и «ремонт строительного фена», «пайка строительным феном».
Тем не менее, статистика Вордстат может стать хорошим ориентиром для оценки спроса или планирования рекламной кампании. Сервис делает прогноз показов, оценивая данные по каждому запросу за последние 30 дней. Данные собираются только с поиска Яндекса — запросы в других поисковых системах и не учитываются в Яндекс Вордстат. Статистика по запросам — это предварительный прогноз показов в месяц.
Виды частотностей Wordstat
Базовая частотность
Базовая частотность Wordstat — это показы по всем возможным вариантам указанного запроса.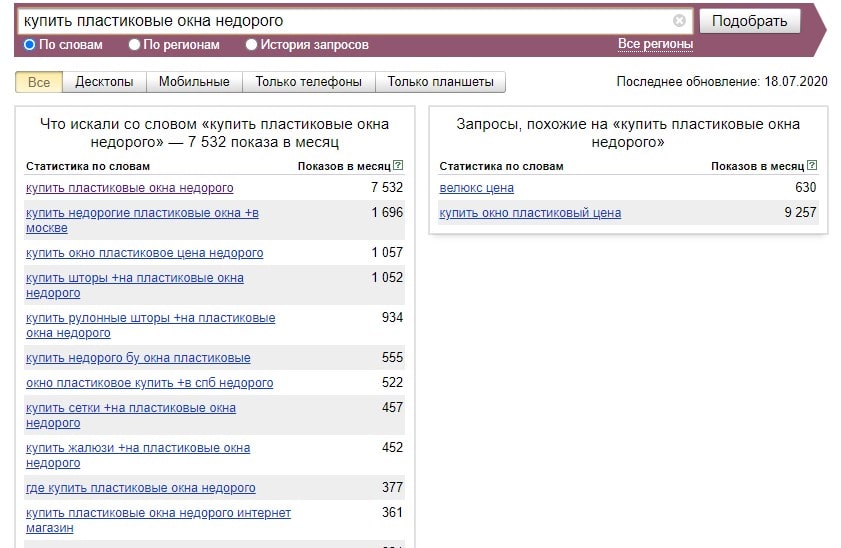 Базовая частотность — самая неточная. Например, в запрос «купить машину» попадёт множество смежных запросов — «стиральная машина купить», «посудомоечная машина купить», «швейная машина купить», «купить машину автомат». Если вы продаёте автомобили, вам не нужны данные по другим запросам, потому ключевое слово нужно уточнить.
Базовая частотность — самая неточная. Например, в запрос «купить машину» попадёт множество смежных запросов — «стиральная машина купить», «посудомоечная машина купить», «швейная машина купить», «купить машину автомат». Если вы продаёте автомобили, вам не нужны данные по другим запросам, потому ключевое слово нужно уточнить.
Фразовая частотность
Фразовая частотность показывает статистику только по конкретным запросам, когда пользователи вводили их в поиск без лишних слов. Чтобы посмотреть частотность выбранной фразы, нужно использовать оператор кавычки (‟”).
Оператор Wordstat кавычки (‟”) фиксирует поисковую фразу при сборе статистики в Подборе слов. Так можно отсеять все дополнительные слова. При этом в статистике Wordstat по выбранному запросу будет учтён любой порядок слов и все склонения фразы.
Введём запрос в кавычках (‟”) — «купить машину». Число показов сократилось почти в 100 раз, потому что во фразовой частотности не учитываются дополнительные слова, указывающие на регион — «купить машину Москва» или «купить машину Казань», тип покупки — «купить машину бу» и другие.
Число показов сократилось почти в 100 раз, потому что во фразовой частотности не учитываются дополнительные слова, указывающие на регион — «купить машину Москва» или «купить машину Казань», тип покупки — «купить машину бу» и другие.
Точная частотность
Яндекс.Подбор слов покажет точное вхождение по запросу, если ввести ключевые слова, сохранив склонения, спряжения, число. Точное вхождение — когда в тексте на веб-странице ключевая фраза встречается с заданным порядком слов, в выбранной грамматической форме.
Чтобы посмотреть точную частотность по выбранному запросу, нужно взять его в кавычки (‟”) и добавить оператор восклицательный знак (!) перед каждым словом.
Оператор Wordstat восклицательный знак (!) фиксирует форму слова. Так в статистике можно увидеть показы поискового запроса в выдаче Яндекса в конкретной словоформе без учёта склонений и множественного числа.

В примере с запросом «купить машину» используем оба оператора и видим, что точное вхождение использовали 23 500 раз при базовой частотности 2,6 млн.
Точный запрос в Вордстат указывает на высокочастотный ключ- высокочастотные — от 5 000 запросов в месяц;
- среднечастотные — 5 000-10 000;
- низкочастотные — меньше 1 000.
Высокочастотные запросы приводят больше трафика. Низкочастотные ключи могут приводить целевой трафик и положительно влиять на конверсию.
Все операторы Подбора слов Яндекса и их назначения
Чтобы понимать, как правильно искать в Wordstat, нужно научиться пользоваться операторами. Это символы, с помощью которых сервис меняет характер запроса. Всего в Вордстат их 5.
- Оператор «минус» ( — ). Убирает из поиска слово, перед которым расположен оператор. Нужно добавлять минус в начале слова без пробела.

- Оператор «плюс» ( + ). Добавляет предлоги и союзы, запросы с которыми сервис самостоятельно не учитывает. Например, «автомобиль +в Воронеже».
- Оператор «или» ( | ). Помогает находить запросы с несколькими вариантами слов. Такие слова нужно обязательно указывать в скобках — символ | выполняет роль союза «или». Например, по запросу «автомобиль (купить|арендовать)» Вордстат покажет статистику по обеим фразам — «автомобиль купить» и «автомобиль арендовать».
- Оператор «восклицательный знак» ( ! ).
- Оператор квадратные скобки ( [ ] ). Закрепляет порядок слов в ключе.
 Например, для запроса «[автомобиль купить]» Wordstat не учтёт показы фразы «купить автомобиль».
Например, для запроса «[автомобиль купить]» Wordstat не учтёт показы фразы «купить автомобиль». - Оператор кавычки ( ‟” ). Сохранит соответствие словам из запроса, но не учтёт их порядок и окончания. Например, по запросу «недорогой автомобиль купить» сервис может показать ключ «купить автомобиль недорого».
Как маркетологу или владельцу бизнеса работать с Яндекс Wordstat
Как смотреть сезонность
Спрос на продукты и информацию взлетает в пик сезона и падает, когда сезон проходит. Перед праздниками люди ищут подарки, а в августе закупают канцелярию перед стартом учебного года. Важно отслеживать сезонность, чтобы грамотно расходовать деньги на рекламу. Например, снижать стоимость клика CPC по запускам в несезон и подогревать интерес перед стартом сезона.
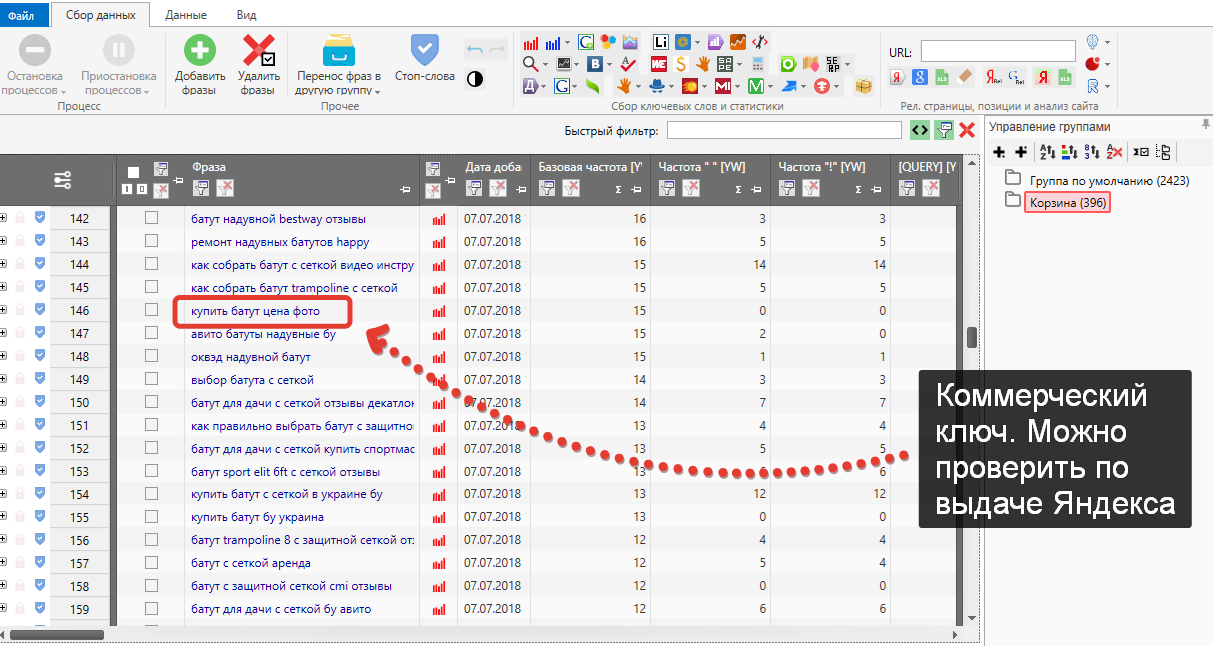
Wordstat поможет оценить сезонность с помощью истории запросов. Для этого укажите запрос и под строчкой поиска выберите «История запросов». Сервис покажет результаты за последние 2 года. Например, проверяем запрос «конструктор лего». На графике выделяются 2 пиковых периода с наибольшим спросом — декабрь 2020 и декабрь 2021. Этот товар покупали в качестве подарков на Новый год.
Например, проверяем запрос «конструктор лего». На графике выделяются 2 пиковых периода с наибольшим спросом — декабрь 2020 и декабрь 2021. Этот товар покупали в качестве подарков на Новый год.
С помощью истории запросов можно находить ключи-пустышки. Это запросы, которые выстрелили в один момент, а потом не давали никакого охвата. В таком случае показы искусственно накрутили или товар был популярен некоторое время, а потом о нём забыли.
Важно: история запросов показывает динамику по базовой частотности и не учитывает операторы — кавычки и восклицательные знаки.
Хотите освоить сквозную аналитику?
Посетите регулярный мастер-класс по аналитике от Roistat.
ПодключитьсяКак разделить показы по регионам
Полезно знать статистику по регионам, если запускаете новый продукт или ищете перспективный рынок для расширения бизнеса. Для запуска рекламной кампании данные по регионам тоже пригодятся — сможете оценить целесообразность рекламы в выбранных регионах.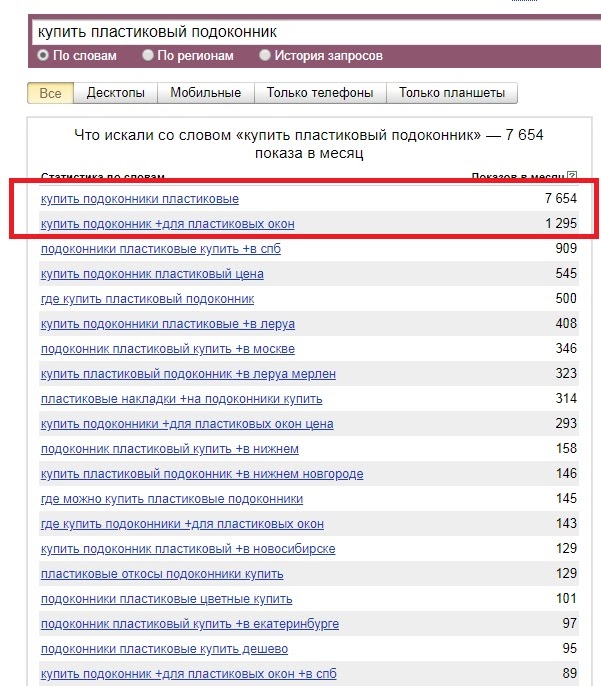
Чтобы посмотреть запросы Яндекс.Подбор слов по регионам, укажите запрос и под строчкой поиска выберите «По регионам». Сервис предоставит 3 списка:
- по регионам — например, Центральный федеральный округ;
- города;
- все — регионы + города.
Результаты поиска можно посмотреть в виде географической карты. Регионы, где запрос очень популярен, окрашены в красный цвет, а где непопулярен — в жёлтый.
Как оценить популярность запросов Wordstat по типу устройств
Если продвигаете сервисы только с десктопов или со смартфонов, важно отслеживать данные по просмотрам с этих устройств. Например, не всегда выгодно продвигать приложение на телефон по запросам с наибольшим охватом для пользователей ПК. Лучше изучить запросы для смартфонов или запускать отдельную рекламу для десктопов, мотивируя пользователей переходить в приложение.
Чтобы посмотреть запросы по типу устройств, укажите запрос и после того, как сервис подгрузит результаты, выберите один из пяти вариантов:
- все — Вордстат по умолчанию покажет охват по всем устройствам;
- десктопы;
- мобильные — смартфоны + планшеты;
- только телефоны;
- только планшеты.

Например, с помощью разделения статистики по запросам с десктоп и мобильных устройств, видим, что Вордстат чаще ищут с компьютеров. Можно предположить, что сервисом пользуются чаще всего с десктопных устройств.
Как собрать семантическое ядро сайта в Wordstat
Семантика нужна для анализа конкурентов, запуска контекстной рекламы, SEO-продвижения сайта. Это список отобранных ключевых слов, которые можно брать в работу. Вордстат поможет собрать основу семантического ядра — самые очевидные запросы, актуальные фразы и похожие ключи.
Чтобы собрать семантику, введите самые простые ключевые слова, которые первыми приходят на ум. Например, для интернет-магазина цветов подойдёт запросы «цветы», «цветы москва», «розы», «цветы доставка». Этого хватит для начала — сервис покажет похожие и близкие по тематике запросы.
Копируйте запросы Яндекс Вордстат в отдельный документ — например, в Google Таблицу. Указывайте частотность — пригодится, чтобы поделить запросы на высокочастотные и низкочастотные.
Вордстат — первый шаг для сбора семантики. Ключи нужно отсортировать и почистить, добавить минус-слова. Подробнее о том, как довести семантическое ядро до ума и в каких сервисах это сделать, рассказали в блоге Roistat.
Расширения для браузера при работе с Wordstat
Удобнее собирать семантику в Вордстат с помощью расширений для браузера. Например, для Google Chrome можно использовать расширение Wordstater. Оно умеет собирать не только запросы, но и минус-фразы, стоп-слова. Можно настроить работу вручную или запустить автоматически сбор слов по параметрам. Wordstater поможет спрогнозировать приблизительную цену клика для каждой фразы.
При установке расширения в сервисе Подбор слов Яндекса вы увидите кнопку плюса у каждого запроса. С помощью неё удобно копировать запросы в окно расширения, чтобы дальше с ними работать. После сбора семантики можно будет забрать из этого окна семантику в выбранном виде:
- через запятую или столбиком;
- с частотностью или без неё;
- с операторами или без них.

Также при использовании расширения для Вордстат под поисковой строкой появляются операторы Wordstat: можно подставлять их в проверяемый запрос одним кликом.
Другие расширения для Вордстат
Yandex Wordstat Helper. Помогает копировать запросы в один клик, узнавать частотность, добавлять и удалять ключи из таблицы.
Yandex Wordstat Assistant. Более продвинутый сервис — поможет добавить слова в Word или Excel, автоматически очистит ключи от дублей, отфильтрует по нужным параметрам.
Как отключить капчу в Вордстате
Капча нужна, чтобы Яндекс Wordstat убедился, что вы человек, а не робот. Её придётся вводить перед запросом. Иногда сервис реже показывает капчу, если отключить плагины и расширения браузера — например, блокировщик рекламы, который мешает получать cookie.
Когда Яндекс Wordstat считает запросы похожими
- Когда в одном месте использовали букву «ё», а в другом — «е».
- Когда использовали единственное или множественное числа — ёжик, ёжики.

- Когда употребили различные падежи и степени сравнения — вовлеку, вовлечёшь.
- Когда слова ввели с опечатками — купить, кпуить.
Виды запросов по частотности
Содержание статьи:
- По частотности
- Высокочастотные (ВЧ)
- Среднечастотные (СЧ)
- Низкочастотные (НЧ)
- По частотности в Яндекс Вордстат
- Базовая частотность
- Точная частотность
- Уточненная частотность
Виды запросов по частотностиГде использовать описанные определения мы разобрали в статье «Сервисы для проверки частотности поисковых запросов»
Для начала давайте определимся что такое частотность запросов.
Частотность поисковых запросов – это число, которые показывает какое количество раз (обычно за календарный месяц) пользователи искали определенную информацию.
Для получения частотностей поисковых запросов будем использовать бесплатный сервис Яндекс Вордстат
Пример
Запрос – погода на Бали в мае
Частотность – 1763 показа в месяц
Это значит что 1763 раза за месяц пользователи ищут в Яндексе информацию о погоде на Бали в мае
Так как количество раз за месяц, которое пользователи искали в Яндексе, может кратно различаться, то введена определенная классификация поисковых запросов по частотности.
Высокочастотные запросы (ВЧ)Высокочастотные запросы обладают огромной частотностью, которая измеряется десятками тысяч запросов в месяц. Чаще такие запросы состоят из 1-2 слов. По таким запросам очень трудно понять что именно хочет найти пользователь.
Пример
Высокочастотный запрос установка пластиковых окон
Среднечастотные запросы имеют частотность ориентировочно в диапазоне 1000-10000 запросов в месяц.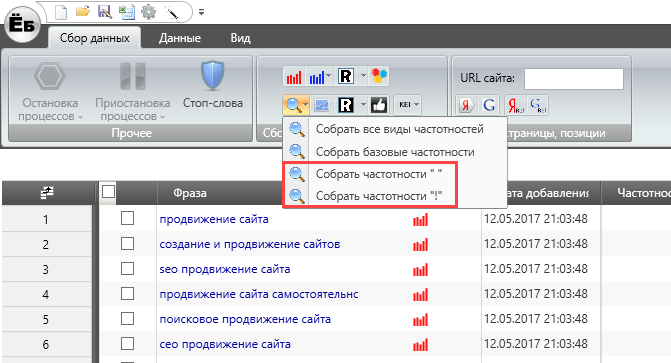 Такие запросы уже состоят из 3-5 слов и несут в себе более сформированный запрос. Это может быть желание приобрести, найти отзывы, узнать характеристики популярного товара и так далее.
Такие запросы уже состоят из 3-5 слов и несут в себе более сформированный запрос. Это может быть желание приобрести, найти отзывы, узнать характеристики популярного товара и так далее.
Пример
Среднечастотный запрос установка пластиковых окон цена
Низкочастотные запросы зачастую имеют частотность менее 100-200 запросов в месяц. Но несмотря на невысокую частотность этих запросов они имеют наибольший интерес с коммерческой точки зрения. Человек уже имеет сформированный запрос и вам будет легко удовлетворить его предложив свою услугу или товар.
Именно поэтому сбор таких запросов наиболее приоритетная задача при настройке контекстной рекламы и создания семантического ядра сайта.
Пример
Низкочастотный запрос купить откосы для пластиковых окон Москва
Также существуют виды частотности запросов в Яндексе, что это такое сейчас разберемся.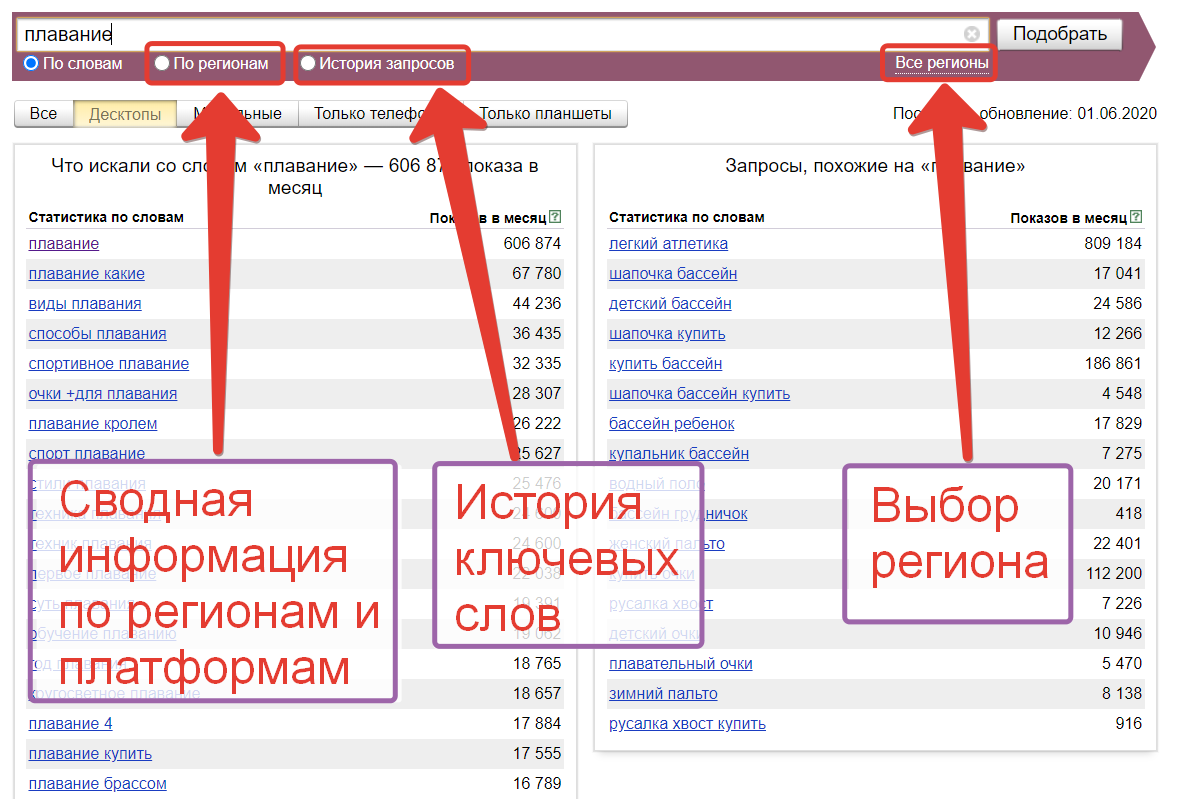
В Яндексе существует такая вещь как операторы, вот два из них, которые нам пригодятся:
- «» (кавычки), фиксирует количество слов в запросе
- ! (восклицательный знак), фиксирует форму слова
Полный список операторов в Яндексе, а также как они работают вы можете посмотреть в статье «Операторы в Яндексе»
Итак, с операторами коротко познакомились, теперь давайте посмотрим как они помогают узнать получить разные виды запросов по частотности в Яндексе.
Базовая частотностьБазовая частотность не предполагает использование каких-либо оператор. То есть вы просто вводите запрос и вам выдается базовая частотность.
Пример
Базовая частотность запроса куда сходить в Москве равна 275292 показа в месяц
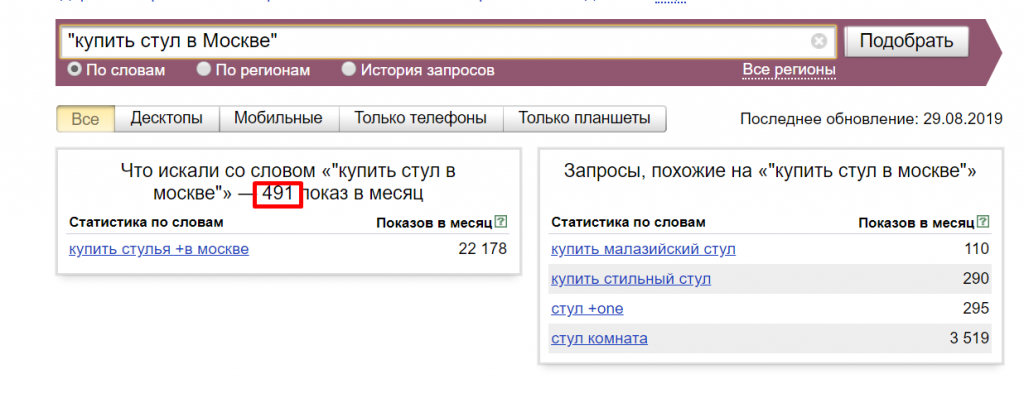
Точная частотность получается тогда, когда запрос заключается в кавычки («»). Это позволяет ограничить количество слов в запросе, но не фиксирует их форму. Например в запрос «куда сходить в Москве» войдет запрос куда ходил в Москве.
Например в запрос «куда сходить в Москве» войдет запрос куда ходил в Москве.
Пример
Точная частотность запроса «куда сходить в Москве» равна 30661 показа в месяц
Уточненная частотность получается тогда, когда запрос заключается в кавычки («»), а также перед каждым словом ставиться восклицательный знак (!). Последнее позволяет дополнительно зафиксировать форму слов, входящих в запрос. Данный вариант чаще всего используется при написании статей под определенных ключевой запрос или при сборе семантического ядра.
Пример
Уточненная частотность запроса «!куда !сходить !в !Москве» равна 30571 показа в месяц
Теперь вы знаете какие бывают виды запросов по частотности, а также как узнать базовую, точную и уточненную частотность.
запросов Throttle API для повышения пропускной способности
запросов Throttle API для повышения пропускной способности — Amazon API Gateway Вы можете настроить регулирование и квоты для своих API, чтобы защитить их от чрезмерного количества
Запросы.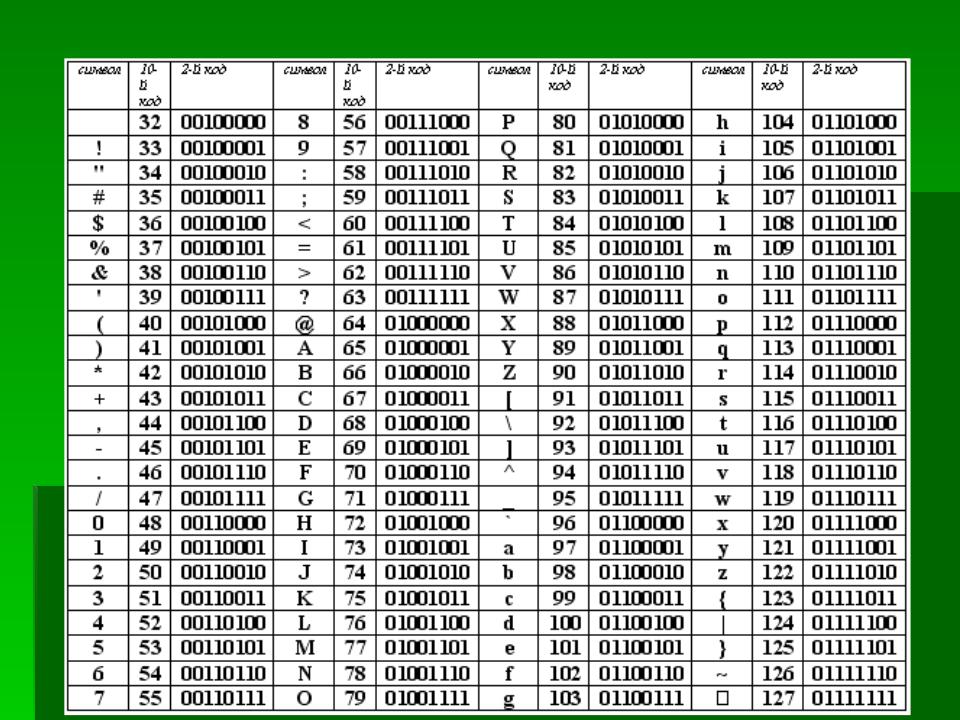 Как ограничения, так и квоты применяются на основе максимальных усилий, и их следует рассматривать скорее как целевые показатели.
чем гарантированные потолки запроса.
Как ограничения, так и квоты применяются на основе максимальных усилий, и их следует рассматривать скорее как целевые показатели.
чем гарантированные потолки запроса.
Шлюз API регулирует запросы к вашему API, используя алгоритм корзины токенов, где токен учитывается в запросе. В частности, API Gateway проверяет скорость и количество отправленных запросов для всех API в вашей учетной записи на каждую Область, край. В алгоритме корзины токенов всплеск может привести к заранее определенному превышению этих пределов, но другие факторы могут также привести к превышению лимитов в некоторых случаях.
Когда отправленные запросы превышают стабильную скорость запросов и предельные значения пакетов, шлюз API начинает дросселировать
Запросы. Клиенты могут получить 429 Too Many Requests Ответы с ошибками на данный момент. При ловле такого
исключений, клиент может повторно отправить неудавшиеся запросы способом, ограничивающим скорость.
Как разработчик API, вы можете установить целевые ограничения для отдельных этапов или методов API, чтобы улучшить общее
производительность всех API в вашей учетной записи. Кроме того, вы можете включить планы использования, чтобы установить ограничения на клиенте.
отправка запросов на основе указанных ставок запросов и квот.
Кроме того, вы можете включить планы использования, чтобы установить ограничения на клиенте.
отправка запросов на основе указанных ставок запросов и квот.
Темы
- Как применяются настройки ограничения регулирования в Шлюз API
- Регулирование на уровне учетной записи для каждого региона
- Настройка регулирования на уровне API и на уровне этапа цели в плане использования
- Настройка целей регулирования на уровне метода в плане использования plan
Как применяются настройки ограничения регулирования в Шлюз API
Прежде чем настраивать параметры ограничения и квоты для вашего API, полезно понять, как они применяются. через Amazon API Gateway.
Amazon API Gateway предоставляет четыре основных типа настроек, связанных с регулированием:
Ограничения регулирования AWS применяются ко всем учетным записям и клиентам в регионе. Эти ограничения существуют для того, чтобы ваш API и ваша учетная запись не перегружались слишком большим количеством запросов.
 Эти ограничения устанавливаются AWS и не могут быть изменены клиентом.
Эти ограничения устанавливаются AWS и не могут быть изменены клиентом.Ограничения на учетную запись применяются ко всем API в учетной записи в указанном регионе. Ставка на уровне аккаунта лимит может быть увеличен по запросу — более высокие лимиты возможны с API, которые имеют более короткие тайм-ауты и меньшие полезные нагрузки. Чтобы запросить увеличение ограничений регулирования на уровне аккаунта для каждого региона, обратитесь в Центр поддержки AWS. Дополнительные сведения см. в разделе Квоты Amazon API Gateway и важные примечания. Обратите внимание, что эти ограничения не могут превышать ограничения регулирования AWS.
Ограничения регулирования для каждого API и этапа применяются на уровне метода API для этапа. Ты можно настроить одни и те же параметры для всех методов или настроить разные параметры дроссельной заслонки для каждого метода. Обратите внимание, что эти ограничения не могут превышать ограничения регулирования AWS.

Ограничения регулирования для каждого клиента применяются к клиентам, которые используют ключи API, связанные с ваш тарифный план в качестве идентификатора клиента. Обратите внимание, что эти ограничения не могут быть выше, чем ограничения для каждой учетной записи.
Настройки, относящиеся к регулированию шлюза API, применяются в следующем порядке:
Регулирование для каждого клиента или метода ограничения, которые вы устанавливаете для этапа использования API план
Ограничения регулирования для каждого метода, установленные для этапа API.
Регулирование на уровне учетной записи за Регион
Региональное регулирование AWS
Регулирование на уровне аккаунта по регионам
По умолчанию API Gateway ограничивает количество запросов в устойчивом состоянии в секунду (RPS) для всех API в AWS
учетной записи для каждого региона.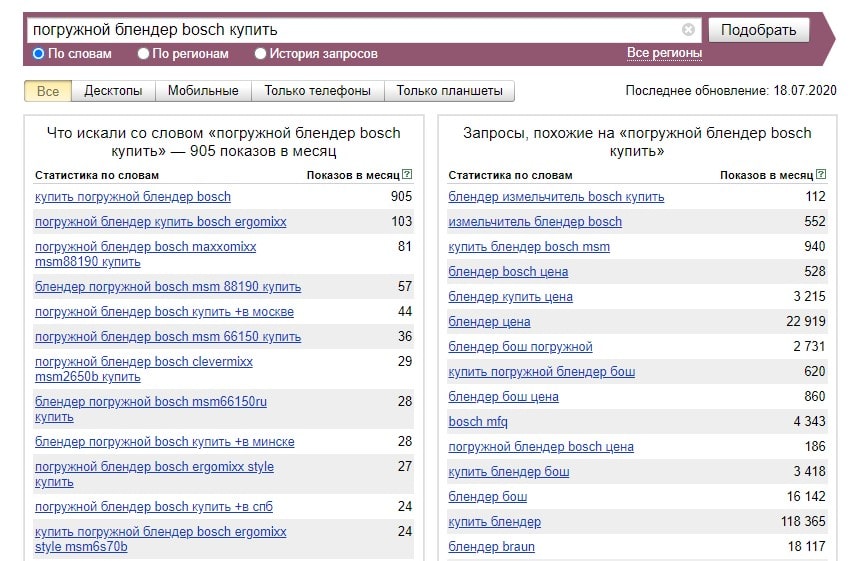 Он также ограничивает всплеск (то есть максимальный размер корзины) для всех API в AWS.
учетной записи для каждого региона. В шлюзе API предел пакета представляет собой целевое максимальное количество одновременных запросов.
отправки, которые API Gateway выполнит перед возвратом
Он также ограничивает всплеск (то есть максимальный размер корзины) для всех API в AWS.
учетной записи для каждого региона. В шлюзе API предел пакета представляет собой целевое максимальное количество одновременных запросов.
отправки, которые API Gateway выполнит перед возвратом 429 Too Many Requests ответы об ошибках. Для большего
информацию о квотах регулирования см. в разделе Квоты Amazon API Gateway и важные примечания.
Настройка регулирования уровня API и этапа цели в плане использования
В плане использования можно установить цель регулирования для каждого метода для всех методов на уровне API или этапа в разделе Создать план использования .
Настройка целей регулирования на уровне метода в использовании plan
Вы можете установить дополнительные цели регулирования на уровне метода в Планы использования , как показано на
Создайте план использования. В шлюзе API
консоль, они устанавливаются путем указания Resource= , Метод = в методе настройки Параметр регулирования . <метод>  Например, для зоомагазина
Например, вы можете указать
Например, для зоомагазина
Например, вы можете указать Resource=/pets , Method=GET .
Javascript отключен или недоступен в вашем браузере.
Чтобы использовать документацию Amazon Web Services, должен быть включен Javascript. Инструкции см. на страницах справки вашего браузера.
Условные обозначения документов
AWS WAF
Частные API-интерфейсы
Шаблон ограничения скорости — Центр архитектуры Azure
Многие службы используют шаблон регулирования для управления потребляемыми ими ресурсами, налагая ограничения на скорость, с которой другие приложения или службы могут получить доступ их. Вы можете использовать шаблон ограничения скорости, чтобы избежать или свести к минимуму ошибки регулирования, связанные с этими ограничениями регулирования, а также для более точного прогнозирования пропускной способности.
Шаблон ограничения скорости подходит для многих сценариев, но особенно полезен для крупномасштабных повторяющихся автоматизированных задач, таких как пакетная обработка.
Контекст и проблема
Выполнение большого количества операций с использованием регулируемой службы может привести к увеличению трафика и пропускной способности, поскольку вам потребуется отслеживать отклоненные запросы и затем повторять эти операции. По мере увеличения количества операций ограничение регулирования может потребовать нескольких проходов повторной отправки данных, что приведет к большему влиянию на производительность.
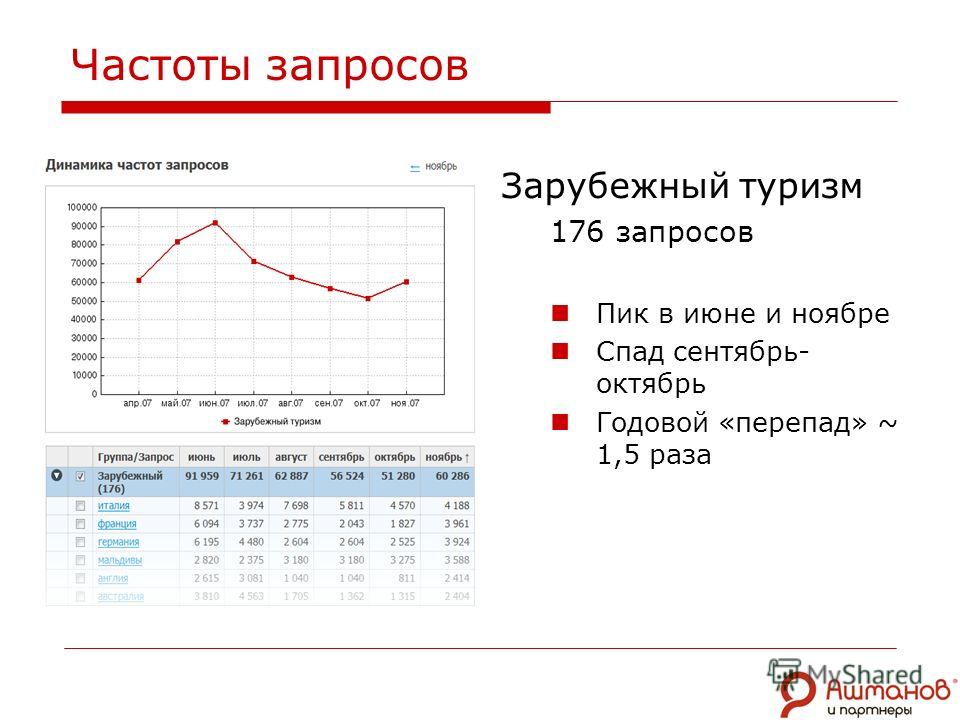
В качестве примера рассмотрим следующий простой процесс повторной попытки при ошибке для приема данных в Azure Cosmos DB:
- Вашему приложению необходимо принять 10 000 записей в Azure Cosmos DB. Каждая запись стоит 10 единиц запроса (ЕЗ) для загрузки, что в общей сложности требует 100 000 ЕЗ для выполнения задания.
- Для вашего экземпляра Azure Cosmos DB подготовлена емкость 20 000 RU.
- Вы отправляете все 10 000 записей в Azure Cosmos DB. 2000 записей успешно записаны и 8000 записей отклонены.
- Вы отправляете оставшиеся 8000 записей в Azure Cosmos DB.
 2000 записей успешно записаны и 6000 записей отклонены.
2000 записей успешно записаны и 6000 записей отклонены. - . Вы отправляете оставшиеся 6000 записей в Azure Cosmos DB. 2000 записей успешно записаны и 4000 записей отклонены.
- Вы отправляете оставшиеся 4000 записей в Azure Cosmos DB. 2000 записей успешно записаны и 2000 записей отклонены.
- . Вы отправляете оставшиеся 2000 записей в Azure Cosmos DB. Все пишется успешно.
Задание приема завершено успешно, но только после отправки 30 000 записей в Azure Cosmos DB, хотя весь набор данных состоял только из 10 000 записей.
В приведенном выше примере следует учитывать дополнительные факторы:
- Большое количество ошибок также может привести к дополнительной работе по регистрации этих ошибок и обработке полученных данных журнала. Этот наивный подход обработает 20 000 ошибок, и регистрация этих ошибок может привести к затратам на обработку, память или ресурсы хранения.
- Не зная пределов регулирования службы приема, наивный подход не позволяет установить ожидаемое время обработки данных.
 Ограничение скорости может позволить вам рассчитать время, необходимое для приема.
Ограничение скорости может позволить вам рассчитать время, необходимое для приема.
Решение
Ограничение скорости может сократить трафик и потенциально улучшить пропускную способность за счет уменьшения количества записей, отправляемых в службу за определенный период времени.
Служба может регулироваться на основе различных показателей с течением времени, например:
- Количество операций (например, 20 запросов в секунду).
- Объем данных (например, 2 ГиБ в минуту).
- Относительная стоимость операций (например, 20 000 ЕЗ в секунду).
Независимо от метрики, используемой для регулирования, реализация ограничения скорости будет включать в себя контроль количества и/или размера операций, отправляемых в службу за определенный период времени, оптимизацию использования службы, не превышая ее возможности регулирования.
В сценариях, где ваши API могут обрабатывать запросы быстрее, чем позволяют любые службы регулируемой загрузки, вам необходимо управлять тем, насколько быстро вы можете использовать службу. Однако рассматривать регулирование только как проблему несоответствия скорости передачи данных и просто буферизовать ваши запросы на прием до тех пор, пока регулируемая служба не сможет наверстать упущенное, рискованно. Если ваше приложение выйдет из строя в этом сценарии, вы рискуете потерять все эти буферизованные данные.
Однако рассматривать регулирование только как проблему несоответствия скорости передачи данных и просто буферизовать ваши запросы на прием до тех пор, пока регулируемая служба не сможет наверстать упущенное, рискованно. Если ваше приложение выйдет из строя в этом сценарии, вы рискуете потерять все эти буферизованные данные.
Чтобы избежать этого риска, рассмотрите возможность отправки ваших записей в надежную систему обмена сообщениями, которая может справиться с полной скоростью приема. (Такие службы, как концентраторы событий Azure, могут обрабатывать миллионы операций в секунду). Затем вы можете использовать один или несколько обработчиков заданий для чтения записей из системы обмена сообщениями с контролируемой скоростью, находящейся в пределах ограничений регулируемой службы. Отправка записей в систему обмена сообщениями может сэкономить внутреннюю память, позволяя удалять из очереди только те записи, которые могут быть обработаны в течение заданного интервала времени.
Azure предоставляет несколько надежных служб обмена сообщениями, которые можно использовать с этим шаблоном, в том числе:
- Служебная шина Azure
- Хранилище очередей Azure
- Центры событий Azure
Когда вы отправляете записи, период времени, который вы используете для выпуска записей, может быть более детализированным, чем период, на который служба регулирует. Системы часто устанавливают дроссели на основе временных промежутков, которые вы можете легко понять и с которыми можно работать. Однако для компьютера, на котором работает служба, эти временные рамки могут быть очень большими по сравнению с тем, насколько быстро он может обрабатывать информацию. Например, система может регулировать скорость в секунду или в минуту, но обычно код обрабатывает порядка наносекунд или миллисекунд.
Хотя это и не требуется, часто рекомендуется отправлять меньшее количество записей чаще для повышения пропускной способности. Таким образом, вместо того, чтобы пытаться группировать вещи для выпуска раз в секунду или раз в минуту, вы можете быть более гранулированными, чем это, чтобы поддерживать потребление ресурсов (память, ЦП, сеть и т.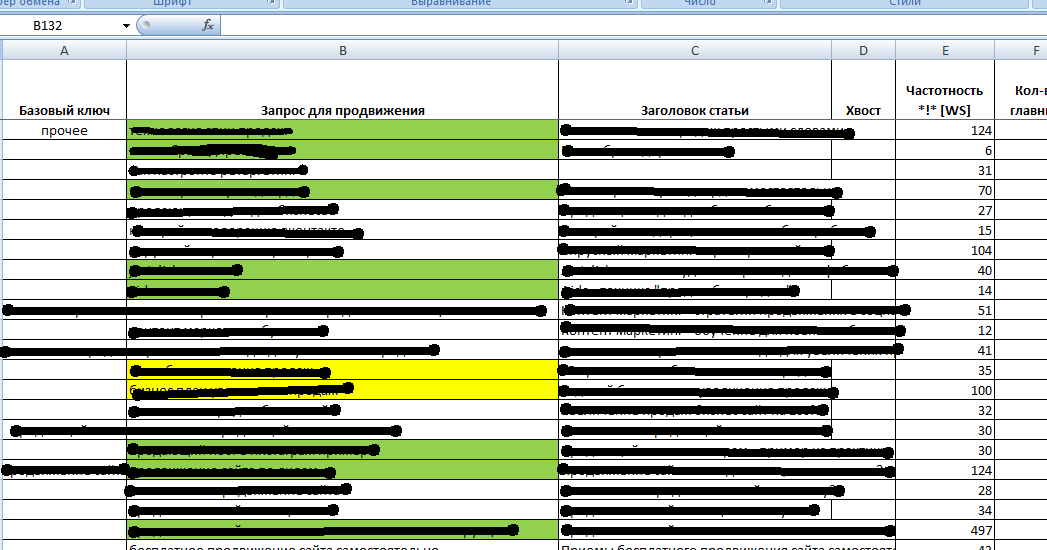 д.) с более равномерной скоростью, предотвращая потенциальное узкие места из-за внезапных всплесков запросов. Например, если служба допускает 100 операций в секунду, реализация ограничителя скорости может сгладить запросы, выпустив 20 операций каждые 200 миллисекунд, как показано на следующем графике.
д.) с более равномерной скоростью, предотвращая потенциальное узкие места из-за внезапных всплесков запросов. Например, если служба допускает 100 операций в секунду, реализация ограничителя скорости может сгладить запросы, выпустив 20 операций каждые 200 миллисекунд, как показано на следующем графике.
Кроме того, иногда необходимо, чтобы несколько нескоординированных процессов совместно использовали регулируемую службу. Чтобы реализовать ограничение скорости в этом сценарии, вы можете логически разделить емкость службы, а затем использовать распределенную систему взаимного исключения для управления эксклюзивными блокировками этих разделов. Затем нескоординированные процессы могут конкурировать за блокировки этих разделов всякий раз, когда им требуется емкость. Каждому разделу, заблокированному процессом, предоставляется определенная емкость.
Например, если регулируемая система допускает 500 запросов в секунду, вы можете создать 20 разделов по 25 запросов в секунду каждый.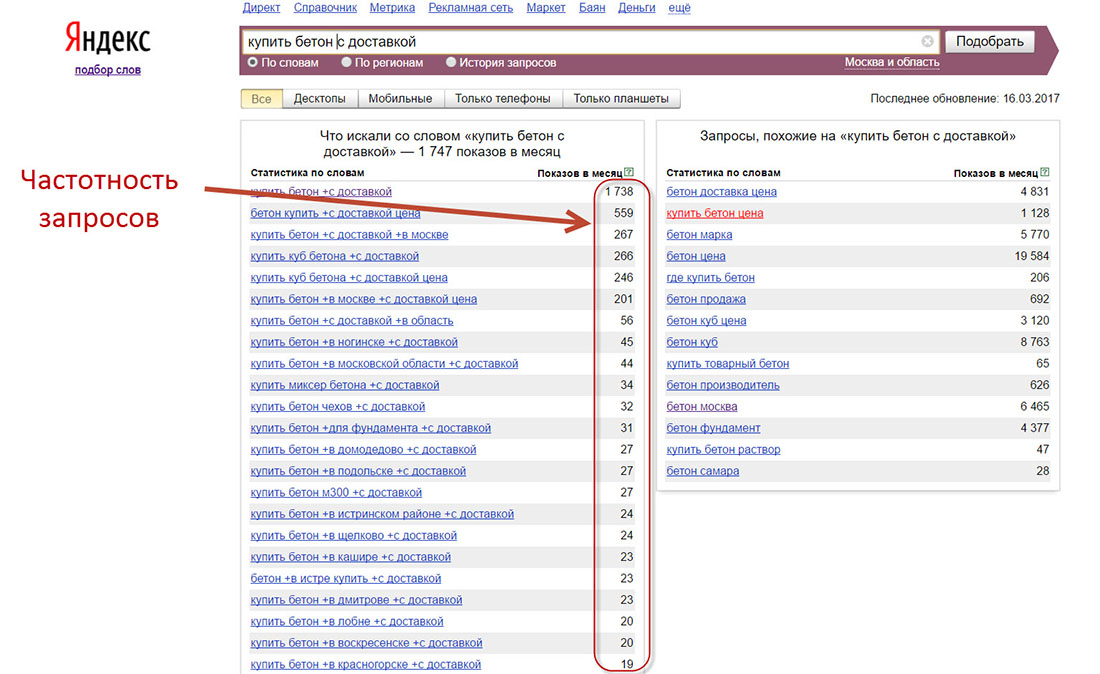 Если процессу необходимо выдать 100 запросов, он может запросить у распределенной системы взаимного исключения четыре раздела. Система может предоставить два раздела на 10 секунд. Затем процесс ограничит скорость до 50 запросов в секунду, завершит задачу за две секунды, а затем снимет блокировку.
Если процессу необходимо выдать 100 запросов, он может запросить у распределенной системы взаимного исключения четыре раздела. Система может предоставить два раздела на 10 секунд. Затем процесс ограничит скорость до 50 запросов в секунду, завершит задачу за две секунды, а затем снимет блокировку.
Одним из способов реализации этого шаблона является использование службы хранилища Azure. В этом сценарии вы создаете по одному большому двоичному объекту размером 0 байт на логический раздел в контейнере. Затем ваши приложения могут получать эксклюзивные права аренды непосредственно на эти большие двоичные объекты на короткий период времени (например, на 15 секунд). Для каждой аренды, предоставленной приложению, оно сможет использовать емкость этого раздела. Затем приложению необходимо отслеживать время аренды, чтобы, когда оно истечет, оно могло прекратить использовать предоставленную ему емкость. При реализации этого шаблона вы часто хотите, чтобы каждый процесс пытался арендовать случайный раздел, когда ему нужна емкость.
Чтобы еще больше уменьшить задержку, вы можете выделить небольшое количество монопольной емкости для каждого процесса. В этом случае процесс будет стремиться получить аренду совместно используемой емкости только в том случае, если ему необходимо превысить зарезервированную емкость.
В качестве альтернативы Azure Storage вы также можете внедрить такую систему управления арендой, используя такие технологии, как Zookeeper, Consul, etcd, Redis/Redsync и другие.
Вопросы и соображения
При принятии решения о реализации этого шаблона учитывайте следующее:
- Хотя шаблон ограничения скорости может уменьшить количество ошибок регулирования, ваше приложение по-прежнему должно должным образом обрабатывать любые ошибки регулирования, которые могут возникнуть.
- Если ваше приложение имеет несколько рабочих потоков, которые обращаются к одной и той же регулируемой службе, вам необходимо интегрировать их все в свою стратегию ограничения скорости.
 Например, вы можете поддерживать массовую загрузку записей в базу данных, а также запрашивать записи в той же базе данных. Вы можете управлять емкостью, гарантируя, что все рабочие потоки проходят через один и тот же механизм ограничения скорости. В качестве альтернативы вы можете зарезервировать отдельные пулы емкости для каждого рабочего потока.
Например, вы можете поддерживать массовую загрузку записей в базу данных, а также запрашивать записи в той же базе данных. Вы можете управлять емкостью, гарантируя, что все рабочие потоки проходят через один и тот же механизм ограничения скорости. В качестве альтернативы вы можете зарезервировать отдельные пулы емкости для каждого рабочего потока. - Регулируемая служба может использоваться в нескольких приложениях. В некоторых — но не во всех — случаях возможно координировать такое использование (как показано выше). Если вы начинаете видеть большее, чем ожидалось, количество ошибок регулирования, это может быть признаком конфликта между приложениями, обращающимися к службе. Если это так, вам, возможно, придется подумать о временном снижении пропускной способности, налагаемой вашим механизмом ограничения скорости, до тех пор, пока использование другими приложениями не снизится.
Когда использовать этот шаблон
Используйте этот шаблон, чтобы:
- Уменьшить ошибки регулирования, вызванные службой с ограничением регулирования.

- Сокращение трафика по сравнению с простым подходом повторной попытки при ошибке.
- Уменьшите потребление памяти, удаляя записи из очереди только тогда, когда есть возможность их обработать.
Пример
Следующий пример приложения позволяет пользователям отправлять записи различных типов в API. Для каждого типа записи существует уникальный обработчик заданий, который выполняет следующие действия:
- Валидация
- Обогащение
- Вставка записи в базу данных
Все компоненты приложения (API, процессор заданий A и процессор заданий B) являются отдельными процессами, которые можно масштабировать независимо. Процессы не взаимодействуют друг с другом напрямую.
Эта диаграмма включает следующий рабочий процесс:
- Пользователь отправляет в API 10 000 записей типа A.
- API помещает эти 10 000 записей в очередь A.
- Пользователь отправляет в API 5000 записей типа B.
- API помещает эти 5000 записей в очередь B.
- Обработчик заданий A видит, что в очереди A есть записи, и пытается получить эксклюзивную аренду большого двоичного объекта 2.
- Обработчик заданий B видит, что в очереди B есть записи, и пытается получить эксклюзивную аренду большого двоичного объекта 2.
- Рабочий процессор А не может получить аренду.
- Рабочий процессор B получает аренду большого двоичного объекта 2 на 15 секунд. Теперь он может ограничивать запросы к базе данных со скоростью 100 запросов в секунду.
- Рабочий процессор B удаляет 100 записей из очереди B и записывает их.
- Проходит одна секунда.
- Обработчик заданий A видит, что в очереди A больше записей, и пытается получить эксклюзивную аренду большого двоичного объекта 6.
- Обработчик заданий B видит, что в очереди B больше записей, и пытается получить эксклюзивную аренду большого двоичного объекта 3.
- Рабочий процессор A получает аренду большого двоичного объекта 6 на 15 секунд.
 Теперь он может ограничивать запросы к базе данных со скоростью 100 запросов в секунду.
Теперь он может ограничивать запросы к базе данных со скоростью 100 запросов в секунду. - Рабочий процессор B получает аренду большого двоичного объекта 3 на 15 секунд. Теперь он может ограничивать запросы к базе данных со скоростью 200 запросов в секунду. (Он также владеет арендой для большого двоичного объекта 2.)
- Рабочий процессор A удаляет 100 записей из очереди A и записывает их.
- Рабочий процессор B удаляет 200 записей из очереди B и записывает их.
- Проходит одна секунда.
- Обработчик заданий A видит, что в очереди A больше записей, и пытается получить эксклюзивную аренду большого двоичного объекта 0.
- Обработчик заданий B видит, что в очереди B больше записей, и пытается получить эксклюзивную аренду большого двоичного объекта 1.
- Рабочий процессор A получает аренду большого двоичного объекта 0 на 15 секунд. Теперь он может ограничивать запросы к базе данных со скоростью 200 запросов в секунду. (Он также владеет арендой для большого двоичного объекта 6.
 )
) - Рабочий процессор B получает аренду большого двоичного объекта 1 на 15 секунд. Теперь он может ограничивать запросы к базе данных со скоростью 300 запросов в секунду. (Он также владеет арендой больших двоичных объектов 2 и 3.)
- Рабочий процессор A удаляет 200 записей из очереди A и записывает их.
- Рабочий процессор B удаляет 300 записей из очереди B и записывает их.
- И так далее…
Через 15 секунд одно или оба задания не будут завершены. По истечении срока аренды процессор также должен уменьшить количество запросов, которые он удаляет из очереди и записывает.
Реализация этого шаблона, реализованная в Go, доступна на GitHub.
Следующие шаблоны и рекомендации также могут быть полезны при реализации этого шаблона:
- Регулирование. Обсуждаемый здесь шаблон ограничения скорости обычно реализуется в ответ на регулируемую службу.
- Повторить попытку. Когда запросы к регулируемой службе приводят к ошибкам регулирования, обычно целесообразно повторить их через соответствующий интервал.