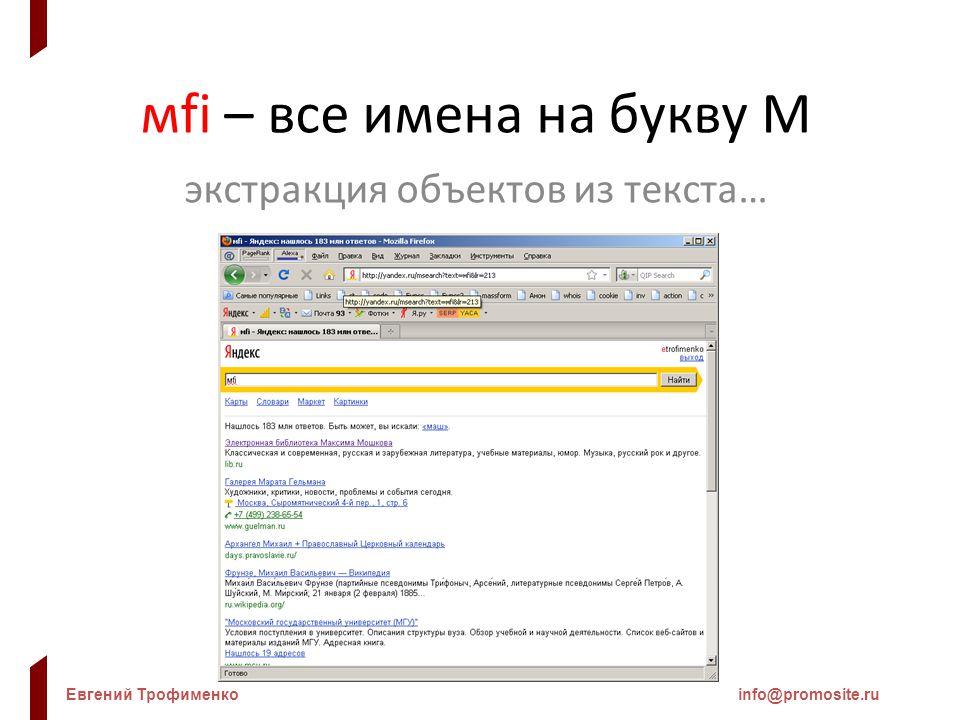
Алгоритмы Яндекс, хронология обновления поисковых алгоритмов до 2022 года
Поисковые алгоритмы Яндекса определяют, как система подходит к ранжированию сайтов. Логично, что за 25 лет существования поисковика, они менялись очень много раз. Если в самом начале алгоритмы могли анализировать всего несколько параметров, то сейчас поисковые системы потихоньку стремятся к тому, чтобы “понимать” тексты на страницах и выдавать пользователям самый релевантный и качественный ответ. Давайте посмотрим, как менялся подход к ранжированию ресурсов все эти годы, и какие нарушения могут привести к пессимизации.
Версия 7 — 2007 год
Первые 10 лет существования поисковика алгоритмы, конечно, менялись, но Яндекс не говорил об этом публично. В 2007 году это начало понемногу меняться. Первый шаг был в том, что один из руководителей поисковой системы просто предупредил SEO-специалистов на тематическом форуме о том, что грядут изменения. Пользователям пообещали, что изменится формула ранжирования, число параметров увеличится и в результате выдача станет более релевантной.
Родео — 2007 год
На этот раз разработчики сосредоточились на изменении алгоритмов ранжирования запросов, которые состоят из одного слова. Главный смысл в том, что по ним теперь чаще стали показываться главные страницы.
Версия 8 (SP1) — 2007 год
Самое большое изменение здесь — это то, что авторитетные ресурсы теперь стали чаще попадаться в топе выдачи. Также изменения коснулись ссылочного продвижения: теперь ссылки с главных страниц начали не так котироваться поисковиком, и веб-мастера стали закупать размещение на внутренних.
Магадан — 2008 год
В этой версии специалисты поработали с географическим фактором. Раньше, если человек хотел увидеть в выдаче только местные сайты, ему нужно было поставить галочку “Искать только в моём регионе”. Теперь же этого не требуется: поиск по умолчанию показывает только подходящие по географическому принципу ресурсы.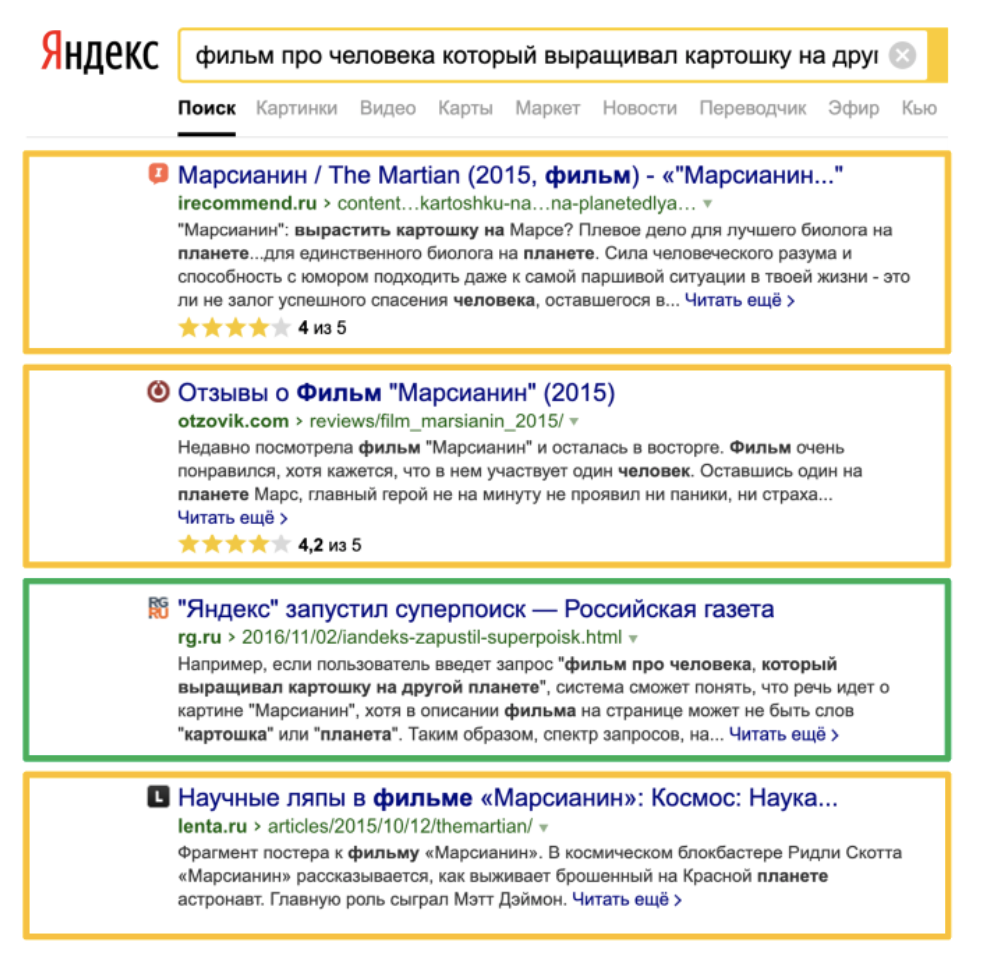 Конечно, всё это работало неидеально, и до нынешнего уровня выдачи было ещё далеко.
Конечно, всё это работало неидеально, и до нынешнего уровня выдачи было ещё далеко.
Также вдвое повысилось количество факторов ранжирования. Плюс, поиск научился распознавать транслитерацию, аббревиатуры и переводить слова. Это первый по хронологии алгоритм Яндекса, который называется именем города. В дальнейших обновлениях компания продолжит эту традицию.
Находка — 2008 год
Этим изменением Яндекс старается сделать выдачу максимально разнообразной. Даже в типично коммерческих тематиках начинают появляться информационные ресурсы. Поисковик пока не может точно угадать, что хотел увидеть пользователь, поэтому показывает ему сразу всё.
Эффективность внешних факторов ранжирования (например, ссылок) снизилась, и контент стал играть бОльшую роль. В результате совсем мусорные сайты, где просто накрутили ссылок, перестали так часто встречаться в топах.
Арзамас — 2009 год
Это обновление сконцентрировалось на изменениях в региональной выдаче.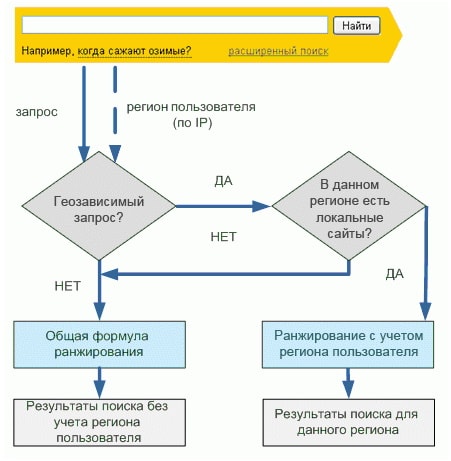 То есть оно практически не затронуло пользователей из Москвы и Петербурга. Теперь поисковик научился определять тип запроса: если для него важна привязка к региону, действует одна система ранжирования, если нет — другая. Также были разработаны разные формулы ранжирования для 19 регионов страны.
То есть оно практически не затронуло пользователей из Москвы и Петербурга. Теперь поисковик научился определять тип запроса: если для него важна привязка к региону, действует одна система ранжирования, если нет — другая. Также были разработаны разные формулы ранжирования для 19 регионов страны.
Снежинск — 2009 год
С внедрением этого алгоритма у Яндекса возросло доверие к взрослым сайтам и старым внешним ссылкам. То есть ссылка, которую получили месяц назад, будет давать меньший вес, чем та, что висит уже год. Плюс, стала важна схожая сфера сайтов: те, кто ссылается на вас, должны подходит вам по тематике, иначе это будет выглядеть неестественно, а значит подозрительно для поисковой системы. Также стал цениться выше уникальный контент. Поэтому сайтам, которые хотят оказаться на первых местах, важно создавать контент самим, а не копировать его у конкурентов.
Ещё в этом году Яндекс внедрил новый метод машинного обучения Матрикснет. Не будем углубляться в технические подробности этого подхода, а просто скажем, что с его помощью стало возможно учитывать ещё больше факторов ранжирования и их комбинаций.
Конаково — 2010 год
В алгоритме Арзамас мы говорили про формулы ранжирования для 19 регионов России. Теперь такой локальный подход работает в 1250 городах по всей стране. Других изменений тут не так много, поэтому название алгоритма неофициальное. В целом это немного обновлённая версия Снежинска.
Обнинск — 2010 год
Здесь разработчики сосредоточились на геонезависимых запросах, выдача по которым в целом не должна зависеть от местоположения человека. Таких запросов в поиске большинство, и для них были представлены новые факторы ранжирования.
Также после внедрения этого алгоритма дела у сайтов, которые продвигались в основном за счёт купленных ссылок, пошли не очень хорошо. Многие из них забанили, а кто-то просто потерял свои высокие позиции.
Краснодар — 2010 год
В этом алгоритме всерьёз взялись за поведенческие факторы ранжирования. Теперь стало важно, как пользователи ведут себя на конкретном ресурсе.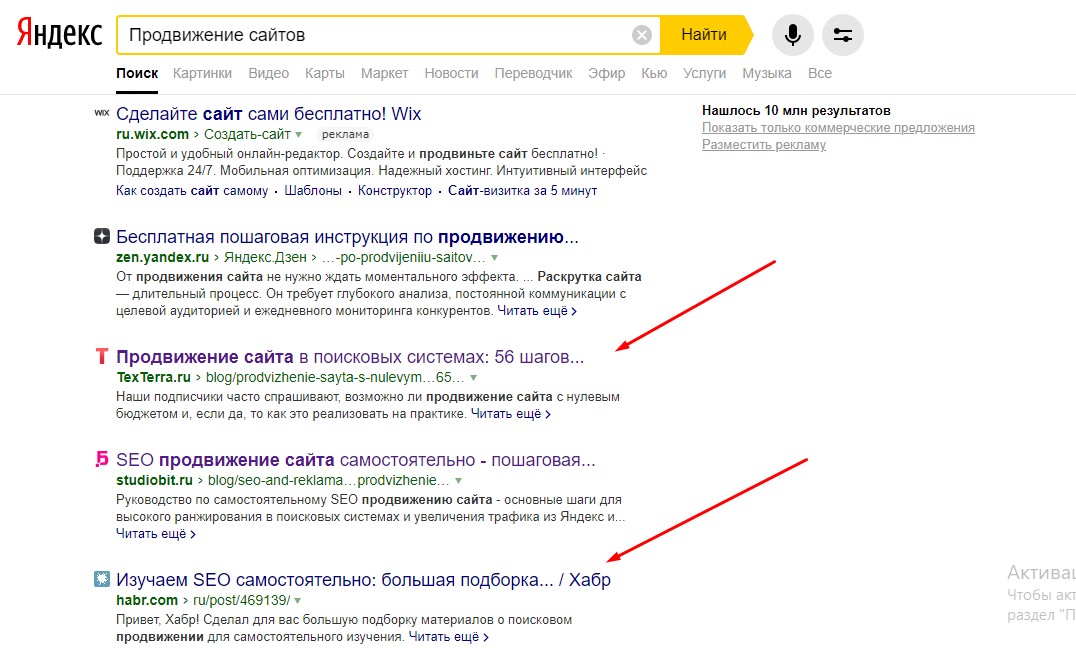 Особенно это касается кликов по сниппетам. Чем больше людей, которые ввели один и тот же запрос, перешли по одному сниппету, тем выше шанс, что для следующих пользователей Яндекс подвинет его на первое место. Также, конечно же, важно, чтобы человек не уходил слишком быстро. Иначе это сигнализирует о плохом качестве ресурса.
Особенно это касается кликов по сниппетам. Чем больше людей, которые ввели один и тот же запрос, перешли по одному сниппету, тем выше шанс, что для следующих пользователей Яндекс подвинет его на первое место. Также, конечно же, важно, чтобы человек не уходил слишком быстро. Иначе это сигнализирует о плохом качестве ресурса.
В этом же направлении оцениваются и внешние ссылки. Стало важно, чтобы они не просто существовали, но и были достаточно кликабельными. Ведь это значит, что они не просто размещены для поисковых роботов, а действительно интересны людям.
Рейкьявик — 2011 год
Этот алгоритм ранжирования стал первым шагом к персонализированной выдаче в Яндексе. С его внедрением поисковая система начала учитывать языковые предпочтения пользователей. То есть если человек больше переходил на англоязычные сайты или просто больше искал их, то они и будут чаще показываться ему в выдаче.
Калининград — 2012 год
В этом году Яндекс ещё плотнее занялся персонализацией поисковой выдачи. Результаты стали основываться на предыдущей истории поиска. То есть теперь появилось больше возможностей угадать, что именно имел в виду человек, используя тот или иной запрос. Например, если он часто ищет фильмы, то по запросу “Титаник” логично выдать ему ссылку на просмотр кино, а не историю парохода. Плюс, если пользователь часто посещает определённые сайты, то в его результатах выдачи они будут находиться выше, чем у других.
Результаты стали основываться на предыдущей истории поиска. То есть теперь появилось больше возможностей угадать, что именно имел в виду человек, используя тот или иной запрос. Например, если он часто ищет фильмы, то по запросу “Титаник” логично выдать ему ссылку на просмотр кино, а не историю парохода. Плюс, если пользователь часто посещает определённые сайты, то в его результатах выдачи они будут находиться выше, чем у других.
Дублин — 2013 год
И снова о персонализированной выдаче. Теперь поисковая система умеет учитывать не только долгосрочные интересы пользователя, но и текущие, которые актуальны в конкретный момент. Например, если только что человек искал информацию о женских именах, то по запросу “Роза” на первых местах ему вероятнее выпадут статьи о значении этого имени.
Началово — 2014 год
Этот алгоритм затронул только Московский регион и только коммерческую выдачу. Для ранжирования сайтов в этих тематиках перестала играть роль большая ссылочная масса и ряд других ссылочных факторов. Так Яндекс боролся с накрученными ссылками.
Так Яндекс боролся с накрученными ссылками.
Одесса — 2014 год
Обновление включало в себя изменения в дизайне результатов: теперь прямо в выдаче можно было слушать музыку, смотреть расписание самолетов, поездов и киносеансов, переводить одну валюту в другую и т.д. Для получения быстрых ответов людям больше не обязательно было переходить на сайты. Но это обновление очень быстро откатили назад, признав неуспешным. Хотя потом эксперименты в этом направлении продолжились, и сейчас мы также можем найти в выдаче быстрые ответы.
Амстердам — 2015 год
Теперь сбоку от основной выдачи пользователи начали видеть краткий ответ на свой запрос. В первую очередь это, конечно, коснулось информационных запросов. Информацию для таких ответов Яндекс стал собирать из самых авторитетных и релевантных источников. Эту технологию назвали “объективными ответами”, и она используется до сих пор.
Минусинск — 2015 год
После запуска этого алгоритма под раздачу попало большое количество сайтов, которые занимались массовой закупкой ссылок для продвижения. Санкции за слишком большое количество покупных ссылок накладывались либо на весь ресурс, либо на часть его страниц, куда ведут больше всего таких линков.
Санкции за слишком большое количество покупных ссылок накладывались либо на весь ресурс, либо на часть его страниц, куда ведут больше всего таких линков.
Киров — 2015 год
Этот алгоритм получил ещё одно название — “Многорукие бандиты”. Его суть в том, что в выдачу в случайном порядке добавлялись ресурсы, которые Яндекс считал наиболее релевантными в конкретной ситуации. Это могли быть даже новые сайты, которые ещё вчера находились на самой последней странице. После этого оценивалось поведение людей на ресурсе: если сайт им нравился и они проводили на нём много времени, значит он закреплял высокие позиции. Это стимулировали веб-мастеров работать над юзабилити и качеством контента.
Владивосток — 2016 год
С этого момента система начала учитывать адаптированность сайтов к мобильным устройствам. Ведь мобильный трафик быстро рос, поэтому людям было удобнее пользоваться ресурсами, которые нормально отображались на маленьких экранах.
Палех — 2016 год
Здесь в дело вступили нейронные сети. Их развитие позволило поисковой системе лучше определять смысл запроса. Палех в первую очередь отвечает за релевантность выдачи для запросов с длинным хвостом. Например: “фильм где у людей был рейтинг” или “яндекс найди пожалуйста серию маши и медведя про варенье”.
Такие запросы в принципе сложны для поисковиков, потому что практически всегда уникальны. Для них нет такой разнообразной статистики, по которой можно было бы понять, куда люди в таких случаях переходят чаще. Пока для понимания смысла страницы поисковик научился опираться только на её заголовок: он должен соотноситься с семантикой запроса.
Баден-Баден — 2017 год
Теперь Яндекс взялся за заспамленные тексты, в которых используется слишком много ключевых слов. Система и раньше не одобряла такое поведение, но это регулировалось только отдельными фильтрами. Теперь это стало встроено в алгоритм ранжирования.
С этого момента веб-мастеров призывают делать контент не для роботов, а для людей. Даже если на нескольких страницах будет замечена переоптимизация, позиции всего ресурса снизятся.
Королёв — 2017 год
Этот алгоритм поисковой системы Яндекса продолжает дело Палеха: его смысл так же в более релевантных ответах на сложные запросы с длинными хвостами. Теперь он опирается не только на заголовок, но и на весь текст страницы.
Понять на какой запрос может ответить текст помогают LSI-слова. Это не ключевые, но тоже очень важные слова, которые встречаются во многих текстах на одну тематику. Например, в статье про имя Роза будут содержаться слова: “значение”, “женщина”, “происхождение” и т.д. А в материале про цветок будут уже слова: “фото”, “сорт”, “шипы” и т.д. Также для того, чтобы выдать максимально подходящий ответ, алгоритм анализирует другие запросы, по которым конкретную страницу уже находили пользователи.
Андромеда — 2018 год
Вот основные нововведения, которые появились в поиске с внедрением нового алгоритма ранжирования Яндекса:
Быстрые ответы. Это ответы прямо на странице поиска. Чаще всего они помогают с простыми запросами. Например, “новогодние праздники 2019” или “на каком языке говорят в Бразилии”.
Это ответы прямо на странице поиска. Чаще всего они помогают с простыми запросами. Например, “новогодние праздники 2019” или “на каком языке говорят в Бразилии”.
Обновлены алгоритмы ранжирования страниц со сложными темами, на которые нельзя дать однозначный ответ. Стал учитываться размер лояльной аудитории, соотношение полезного и остального контента, индекс качества по сравнению с другими проектами. У авторитетных ресурсов появились значки “Популярный сайт” и “Выбор пользователей”.
Вега — 2019 год
Обновление поиска здесь затрагивает четыре основных момента:
- Продолжается дело Палеха и Королёва, но теперь нейросети научились объединять близкие по смыслу документы в кластеры. В итоге, когда пользователь вводит свой запрос, ответ на него ищется не по всей базе, а только по нескольким кластерам, которые максимально подходят ему по смыслу.
-
Появилась предварительная загрузка результатов поиска. Смысл в том, что система угадывает, каким будет полный запрос человека ещё до того, как он закончил вводить его.
 В результате время на загрузку результатов уменьшается.
В результате время на загрузку результатов уменьшается. - Оценки асессоров-экспертов получили больший вес среди других факторов ранжирования. Каждый такой специалист хорошо разбирается в конкретной теме и может сказать, достаточно ли качественный контент на той или иной странице. Также Яндекс запустил новый сервис — Кью. Это аналог Ответов Mail.ru, но его особенность в том, что отвечают на вопросы не только обычные люди, но и привлечённые к сотрудничеству эксперты.
- Более точная гео привязка. Учитывать географию запроса Яндекс научился давно. Теперь он умеет отслеживать ещё и район города, чтобы найти максимально близкие к человеку заведения.
YATI
В этом алгоритме опять же продолжается работа над глубинным пониманием смысла текста. Теперь запрос пользователя соотносится с его намерением и всем контентом страницы. В основе технологии совершенно новый подход к анализу текста, его называют аналогом BERT у Google. А если говорить про алгоритмы Яндекса, то YATI — продолжение Палеха и Королёва.
А если говорить про алгоритмы Яндекса, то YATI — продолжение Палеха и Королёва.
Также после обновления владельцы сайтов и SEO-специалисты заметили более строгие санкции за накрутку поведенческих факторов. Все ресурсы, поведение пользователей на которых кажется поисковой системе неестественным, пессимизируются в выдаче.
Y1 — 2021 год
Это самое свежее обновление, которое вышло в прошлом году. Помимо технологии YATI, в новом поиске задействована ещё и технология YALM. Она отвечает уже не за анализ текстов, а за их генерацию. То есть она обучается на терабайтах информации, а потом может создавать на её основе свои тексты. Например, так система может сформулировать максимально релевантный ответ, которого пока не дала ни одна страница из выдачи.
Также в обновлении появилось:
- Больше быстрых ответов. Теперь в выдаче сразу показываются короткие ответы на смежные темы, которые могут заинтересовать пользователя.

- Анализ видео. Оно включается сразу с того места, где есть ответ на нужный вопрос.
- Усиленный контроль безопасности. Помимо того, что совсем подозрительные площадки из поиска просто удаляются, на ресурсы теперь можно оставлять отзывы. Соотношение плохих и хороших отображается в выдаче.
- Умная камера. Например, у неё можно спросить, что за растение перед вами. Или с её помощью найти магазин, где продаётся конкретно этот диван.
Ещё подробнее о новом поиске мы рассказывали вот в этой статье.
Антиспам-алгоритмы Яндекса
Отдельно стоит поговорить про все антиспамные алгоритмы Яндекса. Они обновлялись параллельно с поисковыми алгоритмами и были направлены на разные составляющие сайтов.
В целом фильтры поисковых систем следят за тем, чтобы ресурсы не нарушали правила системы. В противном случае на них накладываются санкции. Здесь мы поговорим про отдельные фильтры, которые вводились не в рамках изменения глобальных алгоритмов.
Текстовый контент
Как мы уже говорили, алгоритмы не любят слишком заспамленного контента, который манипулирует системой и за счёт этого снижает свою ценность для аудитории. За борьбу с таким контентом отвечают фильтры:
- Ты последний. Появился в 2007 году. Налагается за неуникальный контент и затрагивает только отдельные страницы.
- Переспам. Работает с 2010 года. Наказывает сайты, где на страницах слишком много ключевых слов, они выделены жирным или в текстах просто много воды.
- Переоптимизация. Действует с 2011 года. Применяется за примерно такие же нарушения, что и прошлый фильтр. Но при его применении обычно проседают позиции по целой группе запросов.
Внешние ссылки
Общее правило для внешних ссылок — они должны быть естественными, а не рекламными. Это не значит, что платить за размещение ссылок вообще нельзя. Просто делать это стоит завуалированно. Вот какие фильтры контролируют нарушения в этой области:
Вот какие фильтры контролируют нарушения в этой области:
- Ссылочный взрыв. Отслеживает резкое увеличение количества ссылок. Особенно большая вероятность нарваться на него, если большинство сайтов-доноров некачественные.
- Внутренний и внешний Непот. Внешний Непот обычно применяется к ресурсам, которые массово размещают у себя чужие ссылки на платной основе. Внутренний — если на конкретном сайте есть перебор с перелинковкой.
Поведение пользователей
Чтобы подняться в выдаче выше, некоторые ресурсы манипулируют данными о поведении пользователей. Вот как Яндекс их наказывает:
- Накрутка поведенческих факторов. С помощью специальных программ владельцы сайтов могут имитировать действия пользователей. Конечно же, система накладывает за это санкции.
- Содействие имитации действий пользователей. Наказывает за то, что случайных посетителей вовлекают в накрутку ПФ.
-
Кликджекинг.
 Это фильтр против размещения на сайте скрытых элементов, с которыми пользователи взаимодействуют, сами того не ожидая.
Это фильтр против размещения на сайте скрытых элементов, с которыми пользователи взаимодействуют, сами того не ожидая. - Криптоджекинг. Фильтр направлен на сайты, которые используют вычислительные мощности устройств своих посетителей для майнинга.
Реклама
Реклама, которая есть на ресурсе, тоже должна отвечать определённым требованиям, чтобы не раздражать посетителей и не вредить им. В этой категории существуют такие фильтры:
- Назойливая реклама. Наказывает за перебор с попапами и другими всплывающими элементами.
- Обманная и избыточная реклама. Срабатывает, если на сайте слишком много рекламы и/или она содержит обманный контент.
- Обман мобильных посетителей. Для агрессивной мобильной рекламы существует отдельный фильтр. Также он действует, если посетителей при просмотре рекламы автоматически перенаправляют на другую страницу. Например, в магазин приложений.
-
Реклама, вводящая в заблуждение.
 Здесь можно словить нарушение, если реклама изображает из себя другой элемент сайта. Например, меню, кнопки и т.д.
Здесь можно словить нарушение, если реклама изображает из себя другой элемент сайта. Например, меню, кнопки и т.д.
Обман поисковой системы
Конечно же, поисковики не любят, когда обманывают не только пользователей, но и их систему. За это существуют фильтры:
- Бан. Фильтр, который применяется в крайних случаях, когда нарушения серьёзные. Например, это использование дорвеев, клоакинга, сайтов-клонов и т.д. Если ресурс попался на таком манипулировании системой, его полностью исключают из поиска.
- Сходство с популярным сайтом. Появился совсем недавно, в июле 2022 года. Наказывает за излишнюю схожесть с другим популярным ресурсом, ведь таким образом мошенники могут наживаться на чужой репутации.
- Псевдосайты. Этот фильтр по разным параметрам определяет ценность ресурсов для аудитории, а потом пессимизирует те, которые ей не обладают.
Нарушение закона
За нарушение любых законов страны сайты или ссылки на их конкретные страницы удаляются из поисковой выдачи. Иногда они всё-таки остаются, а поисковик при переходе на них просто выводит оповещение о том, что сайт нарушает закон, и поэтому он удалён.
Иногда они всё-таки остаются, а поисковик при переходе на них просто выводит оповещение о том, что сайт нарушает закон, и поэтому он удалён.
Качество сайта и всего бизнеса
Качество контролируют такие фильтры:
- АГС. Появился он в 2009 году и изначально наказывал за слишком большое количество исходящих ссылок. Теперь его функции изменились: он понижает в ранжировании любые сайты, которые предназначены не для пользователей. То есть у них бесполезный контент, скопированные с других ресурсов материалы, большое количество дублей страниц и т.д.
- Мобильный фильтр. В выдаче пессимизируются ресурсы, которые не адаптированы под мобильные.
- Некачественный бизнес. Фильтр довольно новый и запущен только в 2021 году. Сделан, чтобы защитить пользователей от мошенников, поэтому следит за репутацией компании, реальностью отзывов, адекватностью цен и т.д.
Взрослый контент
Здесь существует только один фильтр — Adult. Он следит за тем, чтобы по безобидным тематикам в выдачу не попали страницы с контентом для взрослых. Если не весь сайт, а только некоторые его разделы подходят под эту тематику, из поиска будут исключены именно они.
Он следит за тем, чтобы по безобидным тематикам в выдачу не попали страницы с контентом для взрослых. Если не весь сайт, а только некоторые его разделы подходят под эту тематику, из поиска будут исключены именно они.
Создание нескольких ресурсов с одной и той же целью
Иногда владельцы ресурсов считают, что если создать несколько площадок для своей компании, то можно занять больше мест в выдаче. Звучит логично, но не очень честно. Именно поэтому в Яндексе действует аффилиат-фильтр, который этому препятствует. Он оставляет в выдаче только один основной сайт, а все остальные просто скрывает.
Итог
Зачем обо всех этих обновлениях алгоритмов знать владельцам сайтов? Затем, чтобы успешно продвигать свой сайт в выдаче. Ведь если вы знаете, за что Яндекс может пессимизировать ваш ресурс, и каким правилам наоборот надо следовать, чтобы оказаться выше других, то можете действовать осознанно, а не вслепую.
Если вы хотите подробнее узнать обо всех санкциях, которые действуют в Google и Яндекс, почитайте ещё другую нашу статью на эту тему.
Алгоритмы ранжирования Яндекс: история развития
Игорь СеровSEO учебникseo информация, алгоритм поисковых систем, бан сайта, поисковой запрос, поисковый, ранжирование страниц сайта, яндексНа протяжении очень долгого времени алгоритмы ранжирования Яндекс оставались «секретом» для пользователей. Специалисты поисковой системы Яндекс предпочитали не информировать пользователей сети интернет об изменениях алгоритмов ранжирования.
12007 год
И только в 2007 году сотрудники компании Яндекс стали информировать своих пользователей о введении новшеств в поисковой алгоритм. Это немного облегчив продвижение сайтов для многих вебмастеров.
Стоит отметить, что алгоритмы ранжирования Яндекс постоянно изменяются. Благодаря этим изменениям добавляется более новый и совершенный функционал, который очень облегчает работу с данным поисковиком.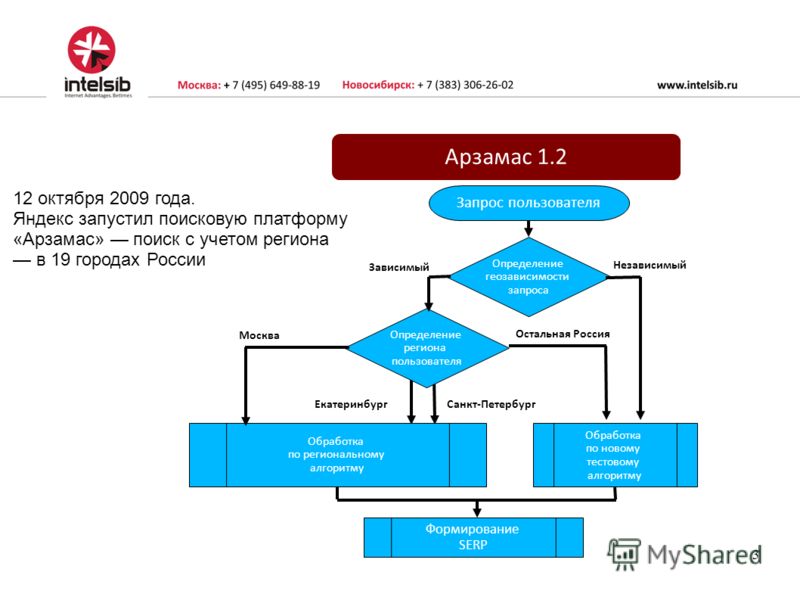 Также благодаря изменению алгоритмов ранжирования устраняются баги, происходит обновление фильтров и ограничителей, подгоняется более точная выдача информации, которая максимально соответствует первоначальному запросу.
Также благодаря изменению алгоритмов ранжирования устраняются баги, происходит обновление фильтров и ограничителей, подгоняется более точная выдача информации, которая максимально соответствует первоначальному запросу.
2май 2008 год
В мае 2008 года, специалистами компании Яндекс был выпущен новый алгоритм, который носит название “Магадан”.
Алгоритм Магадан
В данном алгоритме увеличено в два раза количество факторов ранжирования, значительно улучшен классификатор по местонахождению пользователя (геотаргетинг). Также в алгоритме “Магадан” присутствуют такие инновационные решения как добавление классификаторов для контента и ссылок. Значительно увеличена скорость поисковика по поиску информации по вводимым ключевым запросам (благодаря данному алгоритму поисковик способен выдавать информацию даже с текстами, которые имеют дореволюционную орфографию).
В июле того же года вышла новая версия алгоритма “Магадан”, в которой присутствовали дополнительные факторы ранжирования, например, такие как определение уникальности текста и информации, определение принадлежности контента к порнографическому и прочее.
3сентябрь 2008 год
Уже в сентябре 2008 года, компания Яндекс выпускает новый алгоритм, который носит название “Находка”.
Благодаря появлению данного алгоритма значительно улучшилась работа со словарями в поисковой системе Яндекс, значительно возросло качество ранжирования по запросам, в которых присутствовали стоп – слова (союзы и предлоги). Также в данном алгоритме был разработан абсолютно новый подход к машинальному обучению (машина стала различать разные запросы, и стала менять для разных запросов факторы ранжирования, в расчетной формуле поисковой выдачи).
4апрель 2009 год
Новый алгоритм под названием “Арзамас” или “Анадырь” был выложен в поисковой системе Яндекс в апреле 2009 года.
Алгоритм Арзамас
Благодаря введению этого алгоритма поисковая система Яндекс научилась более точно и значительно лучше понимать русский язык, что дало возможность более точно разрешать неоднозначные слова в запросах. Также данный алгоритм позволил учитывать, поисковой системой, регион, в котором находится пользователь. Благодаря чему пользователи стали получать более точную и более полезную информацию по запрашиваемому вопросу, которая имела максимальное отношения к региону, в котором находился пользователь.
Также данный алгоритм позволил учитывать, поисковой системой, регион, в котором находится пользователь. Благодаря чему пользователи стали получать более точную и более полезную информацию по запрашиваемому вопросу, которая имела максимальное отношения к региону, в котором находился пользователь.
При этом следует отметить, что в разных регионах выдаваемая информация тоже разная, несмотря на один и тот же вводимый пользователем запрос. Также в данном алгоритме поиска значительно улучшена формула, которая позволяет удобнее работать с многословными запросами. Были введены более жесткие фильтры для страниц с попандер-баннерами (Pop-Under баннер появляется на всех страницах сайта и не имеет отношение к тематике сайта), кликандер(Click-ander реклама, появляющаяся на странице при первом клике посетителя) и бодиклик (Bodyclic -сервис тизерной рекламы).
5ноябрь 2009 год
В ноябре 2009 года вышел новый алгоритм, который носит название “Снежинск”.

Алгоритм Снежинск
В этом алгоритме введены дополнительные функции и параметры ранжирования, которые позволяют применять несколько тысяч поисковых параметров для одного документа. Также в данном алгоритме присутствовали новые региональные параметры, были внедрены фильтры АГС (фильтры сайтов намерено пытающихся влиять на поисковую выдачу, проще, анти говно сайт), и значительно улучшился поиск оригиналов контента в сети интернет. Также в данном алгоритме присутствовала самообучающаяся система MatrixNet.
6декабрь 2009 год
В декабре 2009 года появился новый алгоритм под названием “Конаково”.
Этот алгоритм был всего лишь улучшенной версией алгоритма “Снежинск” и в нем было улучшено только локальное ранжирование. В сентябре 2010 года вышел новый алгоритм “Обнинск”. В этом алгоритме было улучшено ранжирование по территориально независимым запросам, было введено ограничение влияния искусственных ссылок на ранжирование. Также благодаря данному алгоритму значительно улучшилась процедура определения авторского текста, и был значительно расширен словарь транслитерации.
Также благодаря данному алгоритму значительно улучшилась процедура определения авторского текста, и был значительно расширен словарь транслитерации.
72010 год
В декабре 2010 года вышел новый алгоритм под названием “Краснодар”.
Для создания этого алгоритма была специально разработана новая технология, которая называется Спектр. Благодаря этому алгоритму поисковая система Яндекс стала классифицировать запросы и выделять из них объекты, присваивая запросам определенную категорию (товары, услуги и прочее).
82014 год
Очередной убойный выстрел Яндекс – Алгоритмы ранжирования Яндекс больше не будут учитывать ссылки при ранжировании. Согласно последним заявлениям, в начале 2014 года будет запущено ранжирование без ссылок. Из факторов ранжирования Яндекс уберут все ссылочные факторы. Это нововведение коснется только коммерческих запросов и сначала будет опробовано на Москве и Московской области. Авторы новшеств, создатели АГС Яндекс.
Авторы новшеств, создатели АГС Яндекс.
©SeoJus.ru
Другие уроки SEO учебника
Похожие записи:
Яндекс — История — История Яндекса
АлисаЯндекс запустил первого диалогового ИИ-помощника, не ограниченного набором заранее заданных сценариев. Названный Alice, он объединяет несколько сервисов, чтобы помочь пользователям эффективно выполнять самые разные задачи – среди прочего находить информацию в Интернете, планировать маршрут, воспроизводить музыку или получать прогноз погоды. Используя глубокие нейронные сети, обученные на массивных наборах данных, Алиса обеспечивает пользовательский опыт, очень похожий на взаимодействие с другим человеком. У него превосходные знания русского языка, ярко выраженная личность с чувством юмора и способность понимать незаконченные фразы и вопросы. | CatBoost Компания открыла исходный код CatBoost, новой библиотеки машинного обучения, основанной на повышении градиента. |
КоролевЯндекс разработал и внедрил новый алгоритм поиска Королев. Как и его предшественник Палех, он основан на нейронных сетях и ищет по смыслу, а не по ключевым словам. Но если Палех просматривал только заголовки, то Королев просматривает веб-страницы целиком. Также учитывается значение других запросов, которые привели пользователей на веб-страницу. Обновление улучшает работу Яндекса с нечастыми и сложными запросами и обеспечивает пользователям превосходные результаты поиска. | Беспилотный автомобиль Компания начала тестировать беспилотную автомобильную технологию. |
Сделка годаЯндекс.Такси и Uber договорились об объединении бизнеса в России, Азербайджане, Армении, Беларуси, Грузии и Казахстане. В рамках сделки Uber должен был инвестировать 225 миллионов долларов, а Яндекс инвестировал 100 миллионов долларов наличными в новую компанию при закрытии, оценивая ее в 3,725 миллиарда долларов после оплаты. | Услуги Яндекс.Переводчик добавил нейронную модель машинного перевода к статистическим моделям, которые он использовал ранее для реализации гибридной системы машинного перевода. Турбо-страницы стали доступны в Яндекс.Поиске, Яндекс.Дзен и Яндекс.Новостях, что ускорило загрузку сайта на мобильных устройствах. Компания также представила ряд новых услуг и продуктов для бизнеса, в том числе многофункциональное голосовое решение для подключенных автомобилей Яндекс.Авто и платформу для совместной работы на рабочем месте Яндекс.Коннект. |
 CatBoost является преемником алгоритма машинного обучения MatrixNet и имеет множество преимуществ по сравнению со своим предшественником: его прогнозы более точны, он более устойчив к переобучению и, что наиболее важно, поддерживает нечисловые признаки — например, породы собак или типы облаков. — то есть он может учиться на различных формах данных, которые не были предварительно обработаны и преобразованы в цифровую форму.
CatBoost является преемником алгоритма машинного обучения MatrixNet и имеет множество преимуществ по сравнению со своим предшественником: его прогнозы более точны, он более устойчив к переобучению и, что наиболее важно, поддерживает нечисловые признаки — например, породы собак или типы облаков. — то есть он может учиться на различных формах данных, которые не были предварительно обработаны и преобразованы в цифровую форму. Два прототипа автономных автомобилей, оснащенные датчиками, а также программным обеспечением, обрабатывающим информацию об окружающей обстановке и рассчитывающим траекторию движения автомобиля, успешно двигались по заданным маршрутам, распознавая и объезжая препятствия на пути.
Два прототипа автономных автомобилей, оснащенные датчиками, а также программным обеспечением, обрабатывающим информацию об окружающей обстановке и рассчитывающим траекторию движения автомобиля, успешно двигались по заданным маршрутам, распознавая и объезжая препятствия на пути. Яндекс.Погода добавила карты погоды, охватывающие весь мир.
Яндекс.Погода добавила карты погоды, охватывающие весь мир.Яндекс выпускает обновление алгоритма, Вега
Яндекс, крупнейшая поисковая система в России, объявила о своем новом обновлении алгоритма под названием «Вега», которое представило «1500 улучшений для поиска Яндекса». Самое существенное и самое примечательное изменение в этом обновлении, по мнению Яндекса, заключается в том, что организация добавляет в поиск больше человеческих элементов. Следующим изменением стала возможность удвоить размер своего поискового индекса, не влияя на скорость вывода запросов.
Андрей Стыскин, глава Поиска Яндекса, сказал об обновлении: «В Яндексе наша цель — помочь потребителям и компаниям лучше ориентироваться в онлайн и офлайн мире. Благодаря этому обновлению поиска пользователи Рунета помогают нам в этом».
Благодаря этому обновлению поиска пользователи Рунета помогают нам в этом».
Яндекс SEO
Прежде чем подробно рассмотреть Vega, давайте рассмотрим особенности Яндекс SEO. Несмотря на то, что между Google и Яндексом есть сходство, у российской поисковой системы есть свои правила и нюансы, которые следует учитывать при структурировании и создании вашего русскоязычного сайта:
- Получение индексации в Яндексе: Чтобы контент проиндексировался в Яндексе, необходимо отправить карту сайта через Яндекс.Вебмастер.
- JavaScript и CSS: Яндекс объявил в блоге для веб-мастеров, что они начали сканировать JavaScript и CSS, а в более поздней статье поддержки они рассказали, как Яндекс обрабатывает сайты AJAX в ноябре 201 года.
- Hreflang и XML Карты сайта: Реализация XML-карты сайта не будет работать в Яндексе, а разметка поддерживается Яндексом.
- Теги уровня страницы: Яндекс поддерживает метатеги ключевых слов как элемент HTML.
 Для определения релевантности страницы поисковым запросам можно использовать следующее:
Для определения релевантности страницы поисковым запросам можно использовать следующее: - Маскировка: Яндекс выпустил обновление своего алгоритма с Находкой в 2008 году с точка избегания и различения маскировки значительно более сильным способом.
- Всплывающие окна: Яндекс обновил свой основной алгоритм для обработки сайтов с навязчивыми всплывающими окнами в 2012 году. Позже, в 2014 году, он был обновлен, чтобы быть значительно более строгим к всплывающим окнам, которые мешают работе клиента и доступности контента. .
SEO на странице
- 8-SP1: В 2008 году был выпущен официально названный алгоритм 8-SPI1. За это время в истории Яндекса более авторитетные сайты позиционировались выше из-за своего возраста, и этот алгоритм попытался изменить это, чтобы дать более свежим страницам возможность занимать верхние позиции. Этот алгоритм также изменил способ взвешивания обратных ссылок как фактора ранжирования, так как уменьшил их емкость.

- Фильтр AGS: Это обновление алгоритма было представлено в сентябре 2008 г. и обновлено в 2009 г., 2013, 2014 и 2015. Первая итерация алгоритма работала с дублирующимся и некачественным контентом. Более поздние обновления подразумевали, что Яндекс может понизить рейтинг сайтов, нацеленных на привлечение трафика для показов рекламы на странице, и оштрафовать сайты, ориентированные на продажу и размещение ссылок.
- Рейкьявик и Калининград: Рейкьявик (2011 г.) и Калининград (2012 г.) были начальными этапами персонализации поиска. История поиска, файлы cookie и действия пользователей начали влиять на персонализированные результаты поиска.
- Тематический индекс цитирования (TIC): Яндекс использует показатель TIC, чтобы проанализировать очевидную известность сайта, его актуальность и авторитетность. Здесь вы можете сделать вывод о сходстве с PageRank.
Чтобы улучшить свой показатель TIC, убедитесь, что у вас есть:
- Отличные внутренние ссылки, которые повышают ценность для пользователя, а не произвольные ссылки на основные экземпляры каждого слова на странице и так далее.

- Создавайте высококачественный контент, отвечающий потребностям пользователей.
- Убедитесь, что содержимое значимо.
Выпуск обновления алгоритма Vega
Вот самое важное, что вам следует знать об обновлении Vega.
Добавление человеческих элементов в обучение алгоритма
Яндекс сообщил, что обновил алгоритм ранжирования с помощью нейронных систем, подготовленных на основе информации, предоставленной настоящими специалистами в нескольких областях, предоставляя пользователям лучшие результаты по их запросам. Похоже, у Яндекса есть специалисты, подкрепляющие расчеты ИИ сигналами о том, какими должны быть наилучшие результаты, и машины используют этот подлинный человеческий вклад для создания превосходного конечного продукта для проиндексированных списков. Как и Google, Яндекс дополнительно использует оценщиков качества — оценщиков — для проверки новых изменений в расчетах.
Как бы то ни было, российская поисковая система сделала все возможное, наняв специалистов для проверки работы оценщика для повышения точности. Таким образом, поскольку эти специалисты ручаются и проверяют обучающие данные Яндекса, они, вероятно, будут более точными.
Таким образом, поскольку эти специалисты ручаются и проверяют обучающие данные Яндекса, они, вероятно, будут более точными.
Поисковые запросы и предварительный рендеринг
Еще одно интересное и актуальное обновление Яндекса — использование алгоритмов для прогнозирования того, что спросит клиент, и «предварительного рендеринга» результатов для этого поискового вопроса. Хотя это было заявлено в отношении обновления Vega, оно было выполнено в марте 2019 года.. Одним из уникальных преимуществ этой конкретной функции является то, что она сокращает время, необходимое клиентам для поиска ответов на вопрос.
Яндекс также сообщил, что внедряет в поиск службу вопросов и ответов. Они, вероятно, связывают людей с ответами на их запросы от квалифицированных специалистов через свою новую систему вопросов и ответов, Яндекс.Q.
Поисковая индексация и кластеризация
Раньше Яндекс просматривал весь индекс в поисках ответа на запрос. Учитывая все обстоятельства, не больше. Яндекс представил исключительно увлекательный метод работы с тематически сопоставимыми страницами сайта. Вместо того, чтобы просматривать весь файл в поисках ответа, Яндекс сгруппировал страницы в тематические кластеры.
Яндекс представил исключительно увлекательный метод работы с тематически сопоставимыми страницами сайта. Вместо того, чтобы просматривать весь файл в поисках ответа, Яндекс сгруппировал страницы в тематические кластеры.
Технология кластеризации Яндекса позволила Яндексу удвоить свой индекс до 200 миллиардов страниц, не влияя на скорость выбора страницы сайта.
Это исключительно интересно, потому что кажется, что алгоритмы ранжирования, которые начинаются с начальных локалей, можно связать в качестве делегатов тем. Страницы сайта, на которые больше ссылок дальше, считаются менее важными. Страницы, которые находятся ближе к затравкам темы, считаются более уместными.
Краудсорсинг
Еще один яркий элемент обновления алгоритма Яндекса — краудсорсинговые рейтинги результатов поиска. Google использует временных подрядчиков, которые обучены правилам оценки качества Google, чтобы судить об их элементах поиска. Яндекс зависит от своей публичной платформы поддержки под названием Яндекс.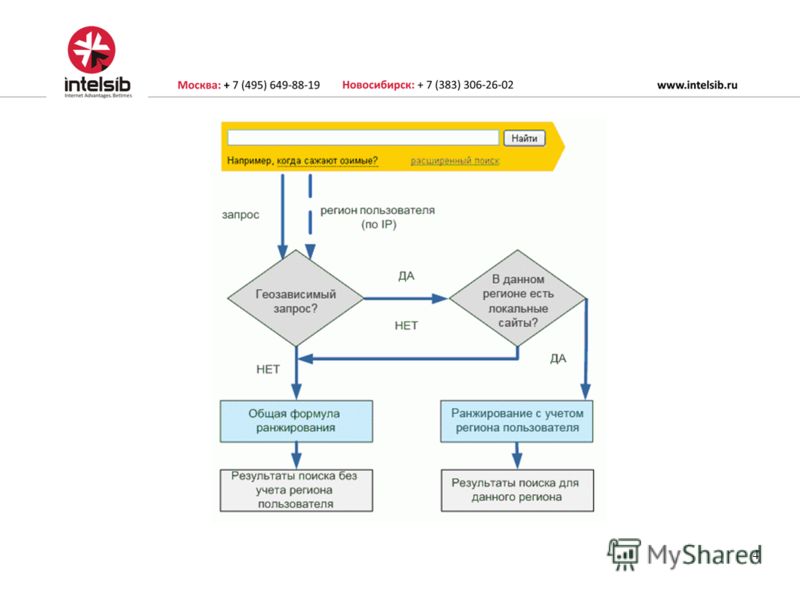 Толока. Хотя это может показаться несколько менее контролируемым, чем стратегия Google, Яндекс дает оценщикам правила для повышения точности оценок.
Толока. Хотя это может показаться несколько менее контролируемым, чем стратегия Google, Яндекс дает оценщикам правила для повышения точности оценок.
В отличие от стратегии Google, краудсорсинг Яндекса менее контролируем. Как бы то ни было, российская поисковая система дает правила рейтинга для повышения точности рейтинга.
Отдельные лица, или «оценщики», уже давно помогали обучать свои этапы ИИ через публично поддерживающий этап — Яндекс.Толоку. Используя наши правила оценки предметов, оценщики в Яндекс.Толоке выполняют действия, которые помогают им найти наиболее подходящие результаты для явных запросов.
Заключение
Яндекс — ведущая поисковая система в России, и из-за более поздних правовых изменений они дополнительно закрыли дыру на мобильных устройствах. С обновлением Vega Яндекс продолжает делать поиск самым точным и быстрым способом взаимодействия российских пользователей с наиболее актуальными данными в Интернете. Сопоставляя навыки искусственного интеллекта с информацией о настоящих специалистах, Яндекс объединяет лучшее из искусственного и человеческого понимания, чтобы связать людей с наиболее релевантными данными.