что это такое за система
АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ
ABCDEFGHIJKLMNOPQRSTUVWXYZ0-9
Ранжирование – это упорядочивание поисковой выдачи в зависимости от того, насколько результат подходит к запросу. Его используют поисковики, чтобы сделать результаты поиска по конкретной фразе релевантными, то есть отвечающими запросам пользователя. Релевантность (соответствие) оценивают по ряду параметров:
- подходит ли контент на странице под запрос, который ввел пользователь;
- насколько качественен сам сайт, нет ли на нем серьезных проблем или ошибок оптимизации, признаков использования черного SEO или сомнительных методов продвижения;
- сколько входящих ссылок ведет на ресурс, насколько они естественны и качественны.
В зависимости от того, насколько сайт соответствует требованиям качества поисковика, он сортируется в выдаче. Ресурсы, которые подходят под все критерии, оказываются в первых строчках, а те, которые им не отвечают, уходят на самое дно выдачи.
Как работает ранжирование
Когда пользователь вводит в поисковую строку какой-то запрос, алгоритмы просматривают базу сайтов и ищут там страницы с нужным ему содержанием. Найденные страницы выстраиваются в определенной последовательности: если поисковая система сочтет какой-то документ более подходящим под нужды посетителя, она разместит его выше, чем менее подходящий. Это и есть ранжирование. Оно позволяет сделать поиск удобнее и полезнее. Чтобы пользователи видели в выдаче преимущественно качественные сайты, учитываются еще и такие показатели, как авторитетность, возраст ресурса, его популярность и известность.
- Многозначные слова. Ранжирование включает в себя не только сортировку, но и, например, систему «Спектр»: так она называется в «Яндексе». Дело в том, что некоторые запросы могут быть неоднозначными. Например, человек вводит слово «горький». Непонятно, что он ищет: простое определение горького вкуса, город или писателя. Ранжирование позволяет добавить в выдачу страницы, содержащие все значения этого слова, чтобы пользователь мог найти вариант, который отвечает его нуждам.

- Алгоритмы. Выдача в «Яндексе», Google и других поисковиках различается даже по одному и тому же запросу, потому что алгоритмы ранжирования к каждой системы свои. Они по-разному учитывают факторы и их значимость, смотрят не только на конкретную страницу, но и на сайт в целом. По-разному считаются показатели региональности и многие другие.
Алгоритмы ранжирования поисковиков
У каждой поисковой системы свои алгоритмы, которые она не раскрывает. Они держатся в секрете от всех: от вебмастеров, владельцев сайтов, даже от самих сотрудников поисковиков. Есть версия, что в точности работу программ не сможет описать никто: поисковые системы активно применяют машинное обучение, алгоритмы достраивают сами себя и работают без управления со стороны людей. Это означает, что со временем они все сильнее превращаются в черный ящик, и программистам все сложнее понять, какими принципами руководствуются роботы.
- Факторы ранжирования. Некоторые критерии оценки сайтов известны.
 Они делятся на три большие группы:
Они делятся на три большие группы:
- внутренние. Сюда относится все, что определяет качество ресурса. Это количество страниц, вес и скорость загрузки, релевантность и качество текстового контента, наличие картинок и подписей к ним. Тексты должны быть уникальными и естественными, содержать ключевые слова, но без переспама и неестественных конструкций. Верстка должна быть удобной, адаптивной, сам сайт обязан отвечать современным стандартам качества. Имеет значение и возраст: слишком молодым ресурсам доверия меньше;
- внешние. Это количество и качество входящих ссылок и упоминаний ресурса на других площадках, а также авторитетность этих площадок;
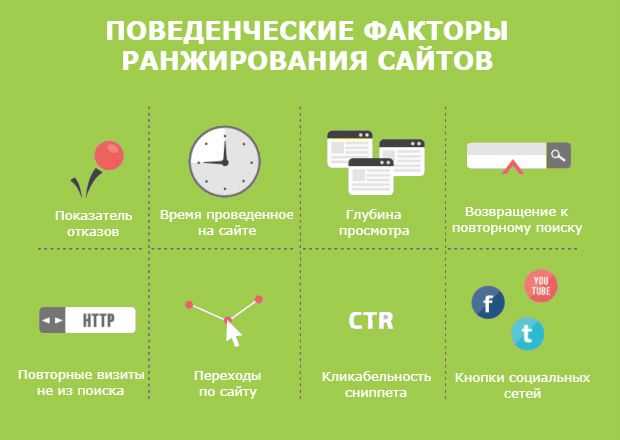
- поведенческие. Определение поведения пользователей на сайте играет важную роль в ранжировании. Как часто люди посещают страницы, что они на них делают, как много времени проводят на сайте и задерживаются ли на нем – это много значит для поисковика.
- «Яндекс». Российский поисковик называет свой алгоритм ранжирования «Матрикснет» и ввел его еще в 2009 году.

- Google. Зарубежная поисковая система рассказывает о своих технологиях реже. Большинство алгоритмов держится в секрете, как и у «Яндекса». Особенности ранжирования подмечают сами владельцы сайтов и специалисты по продвижению. Они подключают системы аналитики и проверяют, какие факторы особенно значимы. Выходит, что алгоритмы постоянно меняются, так что информация каждый год устаревает, но в целом Google уделяет больше внимания наличию длинного, подробного контента на странице и скорости загрузки сайта.

Другие термины на букву «Р»
Регистратор доменаРелевантностьРепутационный маркетингРерайтингРетаргетингРеферерРСЯ
Все термины SEO-Википедии
Теги термина
(Рейтинг: 5 |
Находи клиентов. Быстрее!
Работаем по будням с 9:30 до 18:30. Заявки, отправленные в выходные, обрабатываем в первый рабочий день до 10:30.
Приложи файл или ТЗ
Нажимая кнопку, ты разрешаешь обработку персональных данных и соглашаешься с политикой конфиденциальности.
Работаем по будням с 9:30 до 18:30. Заявки, отправленные в выходные, обрабатываем в первый рабочий день до 10:30.
Нажимая кнопку, ты разрешаешь обработку персональных данных и соглашаешься с политикой конфиденциальности.
Релевантность и оценка — Azure Cognitive Search
- Статья
- Чтение занимает 5 мин
В этой статье объясняется релевантность и алгоритмы оценки, используемые для вычисления оценок поиска в Когнитивный поиск Azure. Оценка релевантности вычисляется для каждого совпадения, найденного в полнотекстовом поиске, где наиболее сильные совпадения назначаются более высокие оценки поиска.

В Когнитивный поиск Azure можно настроить релевантность поиска и повысить оценки поиска с помощью следующих механизмов:
- Конфигурация алгоритма оценки
- Семантическое ранжирование (в предварительной версии, описанное в этой статье)
- Профили оценки
- Пользовательская логика оценки, включенная с помощью параметра
Примечание
Матчи оцениваются и ранжируются от высокого до низкого. Оценка возвращается как «@search.score». По умолчанию в ответе возвращаются первые 50 элементов, но можно использовать параметр $top, чтобы вернуть меньше или больше элементов (до 1000 в одном ответе) и параметр $skip, чтобы получить следующий набор результатов.
Оценка релевантности
Оценка релевантности относится к вычислению оценки поиска, которая служит индикатором релевантности элемента в контексте текущего запроса. Чем выше оценка, тем более релевантен элемент.
Оценка поиска вычисляется на основе статистических свойств входных данных строки и самого запроса. Когнитивный поиск Azure находит документы, соответствующие условиям поиска (некоторые или все в зависимости от searchMode), отдавая предпочтение документам, которые содержат несколько экземпляров условия поиска. Оценка поиска возрастает, если условие поиска редко встречается в индексе данных, но часто — внутри документа. Основу для такого подхода к вычислению релевантности называют TF-IDF или частотой условия — инверсная частота в документе.
Когнитивный поиск Azure находит документы, соответствующие условиям поиска (некоторые или все в зависимости от searchMode), отдавая предпочтение документам, которые содержат несколько экземпляров условия поиска. Оценка поиска возрастает, если условие поиска редко встречается в индексе данных, но часто — внутри документа. Основу для такого подхода к вычислению релевантности называют TF-IDF или частотой условия — инверсная частота в документе.
Оценки поиска могут повторяться во всем результирующем наборе. Если несколько попаданий имеют одинаковую оценку поиска, порядок одного и того же оцененного элемента не определен и не является стабильным. Выполните запрос еще раз, и, возможно, позиции элементов изменятся, особенно если вы используете бесплатную службу или оплачиваемую службу с несколькими репликами. Если есть два элемента с одинаковой оценкой, невозможно определить, какой из них отобразится первым.
Если вы хотите разорвать связь между повторяющимися оценками, вы можете добавить предложение $orderby, чтобы упорядочить элементы по оценке, а затем упорядочить по другому сортируемому полю (например, $orderby=search.). Дополнительные сведения см. в статье Синтаксис $orderby OData в Когнитивном поиске Azure. score() desc,Rating desc
score() desc,Rating desc
Примечание
@search.score = 1 указывает на результирующий набор без оценивания или без ранжирования. Оценка одинакова для всех результатов. Неоценок результатов возникает, когда форма запроса является нечетким поиском, подстановочными знаками или запросами регулярных выражений или пустым поиском (search=*иногда сопряжен с фильтрами, где фильтр является основным средством возврата совпадения).
Алгоритмы оценки в поиске
Когнитивный поиск Azure предоставляет алгоритм ранжированияBM25Similarity. В старых службах поиска вы можете использовать ClassicSimilarity.
Как BM25, так и классические — это функции извлечения, такие как TF-IDF, которые используют частоту терминов (TF) и обратную частоту документа (IDF) в качестве переменных для вычисления оценок релевантности для каждой пары запросов к документу, которая затем используется для ранжирования результатов.
BM25 предлагает расширенные параметры настройки, такие как разрешение пользователю решать, как масштабируется оценка релевантности с частотой совпадающих терминов. Дополнительные сведения см. в разделе «Настройка алгоритма оценки».
Примечание
Если вы используете службу поиска, созданную до июля 2020 года, алгоритм оценки, скорее всего, является предыдущим значением по умолчанию, ClassicSimilarityкоторый можно обновить на основе каждого индекса. Дополнительные сведения см. в разделе «Включение оценки BM25» в старых службах .
В следующем видео-фрагменте приводится краткое объяснение алгоритмов ранжирования, которые используются в Когнитивном поиске Azure. Дополнительные сведения можно получить, просмотрев полное видео.
Для обеспечения масштабируемости Когнитивный поиск Azure распределяет каждый индекс горизонтально через процесс сегментирования.
По умолчанию оценка документа вычисляется на основе статистических свойств данных в сегменте. Этот подход, как правило, не является проблемой для большого объема данных. Он обеспечивает лучшую производительность, чем вычисление оценки на основе информации по всем сегментам. Тем не менее, использование этой оптимизации производительности может привести к тому, что два очень похожих (или даже идентичных) документа будут иметь разные оценки релевантности, если они окажутся в разных сегментах.
Если вы предпочитаете вычислять оценку на основе статистических свойств всех сегментов, вы можете сделать это, добавив
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2020-06-30
{
"search": "<query string>",
"scoringStatistics": "global"
}
Использование scoringStatistics гарантирует, что все сегменты в одной реплике обеспечивают одинаковые результаты. Тем не менее, разные реплики могут немного отличаться друг от друга, так как они всегда обновляются с последними изменениями в индексе. В некоторых случаях вам может потребоваться, чтобы пользователи во время «сеанса запроса» получали более согласованные результаты. В таких случаях вы можете предоставить
Тем не менее, разные реплики могут немного отличаться друг от друга, так как они всегда обновляются с последними изменениями в индексе. В некоторых случаях вам может потребоваться, чтобы пользователи во время «сеанса запроса» получали более согласованные результаты. В таких случаях вы можете предоставить sessionId является уникальной строкой, которую вы создаете для ссылки на уникальный сеанс пользователя.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2020-06-30
{
"search": "<query string>",
"sessionId": "<string>"
}
Пока используется та же самая строка sessionId, будет предпринята максимальная попытка нацеливания на одну и ту же реплику, что повысит согласованность результатов, которые увидят пользователи.
Примечание
Повторное использование одних и тех же значений sessionId может повлиять на балансировку нагрузки запросов по репликам, а также негативно повлиять на производительность службы поиска. Значение, используемое в качестве sessionId, не может начинаться с символа «_».
Значение, используемое в качестве sessionId, не может начинаться с символа «_».
Профили оценки
Вы можете настроить способ ранжирования для разных полей, определив пользовательский профиль оценки. Профили оценки предоставляют критерии повышения оценки соответствия на основе характеристик контента. Например, может, вам нужно повысить приоритет совпадений на основе потенциального дохода, повысить уровень более новых элементов или, возможно, элементов, которые слишком долго находились на складе.
Профиль повышения — часть определения индекса, состоящая из взвешенных полей, функций и параметров. Дополнительные сведения о таком определении см. в статье Добавление профилей повышения в индекс службы Когнитивного поиска Azure.
Параметр featuresMode (предварительная версия)
В запросах поиска документов имеется новый параметр featuresMode, который может предоставить дополнительные сведения о релевантности на уровне полей. В то время как @searchScore вычисляется для всего документа (насколько этот документ является релевантным в контексте этого запроса), с помощью параметра featuresMode можно получать сведения об отдельных полях, как указано в структуре @search.. В этой структуре содержатся все поля, используемые в запросе (определенные поля используются с помощью конструкции searchFields из запроса или все поля с атрибутом доступные для поиска в индексе). Для каждого поля можно получить следующие значения: features
features
- Число уникальных токенов, найденных в поле
- Оценка подобия или мера того, насколько содержимое поля сходно с термином из запроса
- Частота термина или количество раз, когда термин из запроса был найден в поле
Для запроса, предназначенного для полей «description» (описание) и «title» (заголовок), ответ, который содержит @search.features, может выглядеть следующим образом:
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3. 0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
Вы можете использовать эти величины в пользовательских решениях оценки или применить эту информацию для отладки проблем, связанных с релевантностью поиска.
См. также раздел
- Профили оценки
- Справочник по REST API
- Поиск документов (REST API Когнитивного поиска Azure)
- Библиотеки службы «Поиск Azure» для .NET
Алгоритмы и типы ранжирования: концепции и примеры Алгоритмы ранжирования можно разделить на две категории: детерминированные и вероятностные. Алгоритмы ранжирования используются в поисковых системах для ранжирования веб-страниц в соответствии с их релевантностью поисковому запросу пользователя. В этой статье мы обсудим различные типы алгоритмов ранжирования и приведем примеры каждого типа.
Содержание
Что такое алгоритм ранжирования?
Алгоритм ранжирования — это процедура, которая ранжирует элементы в наборе данных в соответствии с некоторым критерием.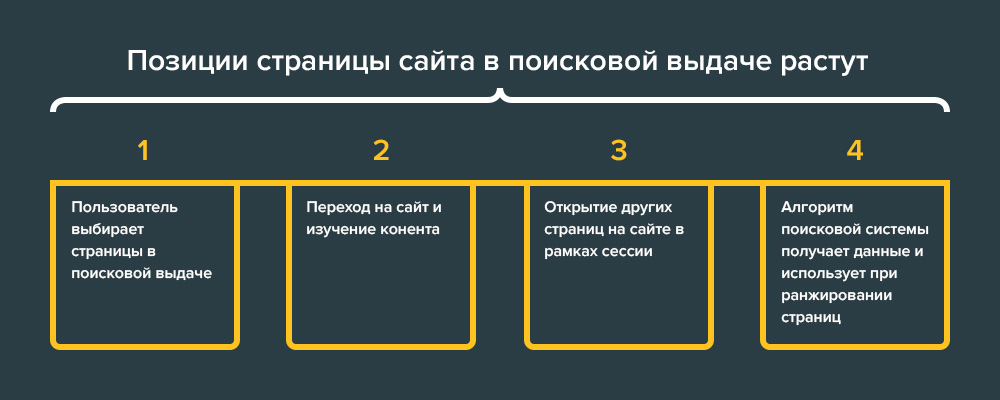 Алгоритмы ранжирования используются во многих различных приложениях, таких как веб-поиск, рекомендательные системы и машинное обучение.
Алгоритмы ранжирования используются во многих различных приложениях, таких как веб-поиск, рекомендательные системы и машинное обучение.
Алгоритм ранжирования — это процедура, используемая для ранжирования элементов в наборе данных в соответствии с некоторым критерием. Алгоритмы ранжирования можно разделить на две категории: детерминированные и вероятностные.
- Алгоритмы детерминированного ранжирования : Алгоритм детерминированного ранжирования — это алгоритм, в котором порядок элементов в ранжированном списке фиксирован и не изменяется независимо от входных данных. Примером детерминированного алгоритма ранжирования является алгоритм ранжирования по признаку. В этом алгоритме каждому элементу присваивается ранг на основе значения его признака. Элементу с наивысшим значением признака присваивается ранг 1, а элементу с наименьшим значением признака присваивается ранг N, где N — количество элементов в наборе данных. Одним из реальных приложений алгоритма детерминированного ранжирования является заказ товаров в продуктовом магазине.
 Товары в продуктовом магазине обычно упорядочены по отделам, таким как продукты, мясо, молочные продукты и т. д. Внутри каждого отдела товары обычно располагаются в алфавитном порядке. Этот тип организации является примером детерминированного алгоритма ранжирования. Алгоритмы сортировки используются в алгоритмах детерминированного ранжирования для упорядочения элементов в ранжированном списке. Существует множество различных типов алгоритмов сортировки, каждый из которых имеет свои преимущества и недостатки. Одними из наиболее распространенных алгоритмов сортировки являются сортировка вставками , сортировка слиянием и быстрая сортировка .
Товары в продуктовом магазине обычно упорядочены по отделам, таким как продукты, мясо, молочные продукты и т. д. Внутри каждого отдела товары обычно располагаются в алфавитном порядке. Этот тип организации является примером детерминированного алгоритма ранжирования. Алгоритмы сортировки используются в алгоритмах детерминированного ранжирования для упорядочения элементов в ранжированном списке. Существует множество различных типов алгоритмов сортировки, каждый из которых имеет свои преимущества и недостатки. Одними из наиболее распространенных алгоритмов сортировки являются сортировка вставками , сортировка слиянием и быстрая сортировка . - Алгоритмы вероятностного ранжирования : В алгоритме вероятностного ранжирования порядок элементов в ранжированном списке может варьироваться в зависимости от входных данных. Примером вероятностного алгоритма ранжирования является алгоритм ранжирования по достоверности. В этом алгоритме каждому элементу присваивается ранг на основе его значения достоверности.
 Элементу с наивысшим значением достоверности присваивается ранг 1, а элементу с наименьшим значением достоверности назначается ранг N, где N — количество элементов в наборе данных. Еще одним примером вероятностного алгоритма ранжирования является байесовский спам-фильтр. В этом алгоритме каждому электронному письму назначается вероятность того, что оно является спамом. Электронные письма с самой высокой вероятностью ранжируются первыми, а электронные письма с самой низкой вероятностью ранжируются последними. Алгоритмы вероятностного ранжирования могут использоваться в поисковых системах для ранжирования веб-страниц в соответствии с их релевантностью поисковому запросу пользователя. Алгоритм ранжирования использует входные данные, такие как количество ссылок на веб-страницу с других веб-сайтов и количество раз, когда ключевое слово появляется на странице, для расчета показателя релевантности страницы. Чем выше показатель релевантности, тем выше рейтинг страницы в результатах поиска. Алгоритмы вероятностного ранжирования также могут использоваться в алгоритмах машинного обучения для ранжирования элементов в наборе данных в соответствии с их вероятностью быть положительным примером.
Элементу с наивысшим значением достоверности присваивается ранг 1, а элементу с наименьшим значением достоверности назначается ранг N, где N — количество элементов в наборе данных. Еще одним примером вероятностного алгоритма ранжирования является байесовский спам-фильтр. В этом алгоритме каждому электронному письму назначается вероятность того, что оно является спамом. Электронные письма с самой высокой вероятностью ранжируются первыми, а электронные письма с самой низкой вероятностью ранжируются последними. Алгоритмы вероятностного ранжирования могут использоваться в поисковых системах для ранжирования веб-страниц в соответствии с их релевантностью поисковому запросу пользователя. Алгоритм ранжирования использует входные данные, такие как количество ссылок на веб-страницу с других веб-сайтов и количество раз, когда ключевое слово появляется на странице, для расчета показателя релевантности страницы. Чем выше показатель релевантности, тем выше рейтинг страницы в результатах поиска. Алгоритмы вероятностного ранжирования также могут использоваться в алгоритмах машинного обучения для ранжирования элементов в наборе данных в соответствии с их вероятностью быть положительным примером. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше вероятность того, что элемент является положительным примером. Существует множество различных типов алгоритмов вероятностного ранжирования, каждый из которых имеет свои преимущества и недостатки. Некоторые распространенные типы алгоритмов вероятностного ранжирования:
Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше вероятность того, что элемент является положительным примером. Существует множество различных типов алгоритмов вероятностного ранжирования, каждый из которых имеет свои преимущества и недостатки. Некоторые распространенные типы алгоритмов вероятностного ранжирования: - Байесовский алгоритм ранжирования : Байесовский алгоритм ранжирования — это вероятностный алгоритм ранжирования, который использует байесовскую сеть для расчета оценки релевантности элемента. Байесовская сеть — это графическая модель, представляющая набор случайных величин и их условных зависимостей. Алгоритм байесовского ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента.
 Чем выше показатель релевантности, тем больше вероятность того, что элемент является положительным примером.
Чем выше показатель релевантности, тем больше вероятность того, что элемент является положительным примером. - Алгоритм ранжирования лог-линейной модели : Алгоритм ранжирования лог-линейной модели представляет собой вероятностный алгоритм ранжирования, который использует лог-линейную модель для расчета оценки релевантности элемента. Логлинейная модель — это математическая модель, описывающая взаимосвязь между двумя или более переменными в терминах линейной комбинации логарифмов переменных.
Одним из наиболее распространенных применений алгоритмов ранжирования являются поисковые системы. Поисковые системы используют алгоритмы ранжирования, чтобы определить, какие веб-страницы наиболее релевантны поисковому запросу пользователя. Алгоритмы ранжирования также используются в рекомендательных системах, чтобы рекомендовать элементы, которые могут заинтересовать пользователя. Ниже приводится краткий обзор алгоритма ранжирования, используемого популярными поисковыми системами:
- Алгоритм ранжирования Google : Алгоритм ранжирования Google является секретом, но мы знаем, что это вероятностный алгоритм ранжирования.
 Google использует различные факторы для ранжирования веб-страниц, включая количество ссылок на страницу, PageRank страницы и релевантность поискового запроса для страницы. Алгоритм Google PageRank — это алгоритм вероятностного ранжирования, который использует количество ссылок на веб-страницу как меру ее важности. Чем выше PageRank веб-страницы, тем больше вероятность того, что она будет занимать более высокое место в результатах поиска.
Google использует различные факторы для ранжирования веб-страниц, включая количество ссылок на страницу, PageRank страницы и релевантность поискового запроса для страницы. Алгоритм Google PageRank — это алгоритм вероятностного ранжирования, который использует количество ссылок на веб-страницу как меру ее важности. Чем выше PageRank веб-страницы, тем больше вероятность того, что она будет занимать более высокое место в результатах поиска. - Алгоритм ранжирования Amazon : Алгоритм ранжирования Amazon также является алгоритмом вероятностного ранжирования. Amazon использует различные факторы для ранжирования товаров, в том числе количество отзывов о товаре, средний рейтинг товара и цену товара. Алгоритм Amazon предназначен для рекомендации товаров, которые соответствуют поисковому запросу пользователя и популярны среди других пользователей.
- Алгоритм ранжирования Facebook : Алгоритм ранжирования Facebook является секретом, но мы знаем, что это вероятностный алгоритм ранжирования.
 Facebook использует различные факторы для ранжирования новостей, в том числе количество лайков, репостов и комментариев к статье, PageRank истории и релевантность истории для новостной ленты пользователя. Алгоритм Facebook предназначен для того, чтобы показывать пользователям наиболее актуальные для них истории, о которых говорят их друзья.
Facebook использует различные факторы для ранжирования новостей, в том числе количество лайков, репостов и комментариев к статье, PageRank истории и релевантность истории для новостной ленты пользователя. Алгоритм Facebook предназначен для того, чтобы показывать пользователям наиболее актуальные для них истории, о которых говорят их друзья. - Алгоритм ранжирования Twitter : Алгоритм ранжирования Twitter также является алгоритмом вероятностного ранжирования. Твиттер использует различные факторы для ранжирования твитов, в том числе количество ретвитов, добавленных в избранное и ответов на твит, PageRank автора твита и релевантность твита на временной шкале пользователя. Алгоритм Twitter предназначен для показа пользователям твитов, которые наиболее актуальны для них и о которых говорят их друзья.
Типы алгоритмов ранжирования
Существует множество различных типов алгоритмов ранжирования, каждый из которых имеет свои преимущества и недостатки. Некоторые из наиболее распространенных типов алгоритмов ранжирования:
Некоторые из наиболее распространенных типов алгоритмов ранжирования:
- Алгоритмы двоичного ранжирования : Алгоритмы двоичного ранжирования являются простейшим типом алгоритма ранжирования. Алгоритм бинарного ранжирования ранжирует элементы в наборе данных в соответствии с их относительной важностью. Двумя наиболее распространенными типами алгоритмов бинарного ранжирования являются алгоритмы ранжирования по признакам и алгоритмы ранжирования по частоте. Алгоритмы ранжирования по признаку ранжируют элементы по количеству признаков, которые они имеют вместе с эталонным элементом. Эталонный элемент — это элемент, который используется для вычисления значения сходства для каждого из других элементов в наборе данных. Алгоритмы ранжирования по частоте ранжируют элементы по количеству раз, которое они встречаются в наборе данных. Алгоритмы ранжирования по признакам и частоте имеют свои преимущества и недостатки. Алгоритмы ранжирования по признаку более точны, чем алгоритмы ранжирования по частоте, но они также требуют больших вычислительных ресурсов.
 Алгоритмы ранжирования по частоте быстрее, чем алгоритмы ранжирования по признакам, но они менее точны.
Алгоритмы ранжирования по частоте быстрее, чем алгоритмы ранжирования по признакам, но они менее точны. - Ранжирование по сходству : Ранжирование по сходству — это тип алгоритма вероятностного ранжирования, который ранжирует элементы в наборе данных в соответствии с их сходством с эталонным элементом. Эталонный элемент — это элемент, который используется для вычисления значения сходства для каждого из других элементов в наборе данных. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше элемент похож на эталонный элемент. Существует множество различных типов ранжирования по алгоритмам сходства, каждый из которых имеет свои преимущества и недостатки. Некоторыми распространенными типами ранжирования по алгоритмам сходства являются алгоритм кластерного ранжирования, алгоритм ранжирования в векторном пространстве и т.
 д.
д. - Ранжирование по расстоянию : Алгоритмы ранжирования по расстоянию представляют собой тип вероятностного алгоритма ранжирования, который ранжирует элементы в наборе данных в соответствии с их расстоянием от эталонного элемента. Ссылочный элемент — это элемент, который используется для вычисления значения расстояния для каждого из других элементов в наборе данных. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем дальше элемент находится от эталонного элемента. Существует множество различных типов алгоритмов ранжирования по расстоянию, каждый из которых имеет свои преимущества и недостатки. Некоторыми распространенными типами алгоритмов ранжирования по расстоянию являются алгоритм Евклидова расстояния, алгоритм расстояния Махаланобиса и т. д.
- Ранжирование по предпочтениям : Алгоритмы предпочтительного ранжирования представляют собой тип алгоритма вероятностного ранжирования, который ранжирует элементы в наборе данных в соответствии с их предпочтением эталонного элемента.
 Эталонный элемент — это элемент, который используется для расчета значения предпочтения для каждого из других элементов в наборе данных. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем более предпочтительным является элемент для эталонного элемента.
Эталонный элемент — это элемент, который используется для расчета значения предпочтения для каждого из других элементов в наборе данных. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем более предпочтительным является элемент для эталонного элемента. - Ранжирование по вероятности : Ранжирование по вероятности — это тип вероятностного алгоритма ранжирования, который ранжирует элементы в наборе данных в соответствии с их вероятностью быть положительным примером. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше вероятность того, что элемент будет положительным примером. Ранжирование по вероятности отличается от других типов алгоритмов ранжирования, поскольку оно учитывает неопределенность данных.
 Это делает его более точным, чем другие типы алгоритмов ранжирования. Существует множество различных типов ранжирования по вероятностным алгоритмам, каждый из которых имеет свои преимущества и недостатки. Некоторыми распространенными типами ранжирования по вероятностным алгоритмам являются байесовский алгоритм ранжирования, алгоритм ранжирования AUC и т. д.
Это делает его более точным, чем другие типы алгоритмов ранжирования. Существует множество различных типов ранжирования по вероятностным алгоритмам, каждый из которых имеет свои преимущества и недостатки. Некоторыми распространенными типами ранжирования по вероятностным алгоритмам являются байесовский алгоритм ранжирования, алгоритм ранжирования AUC и т. д.
Заключение
Алгоритмы ранжирования используются для ранжирования элементов в наборе данных в соответствии с некоторым критерием. Существует множество различных типов алгоритмов ранжирования, каждый из которых имеет свои преимущества и недостатки. Ранжирование по сходству, расстоянию, предпочтению и вероятности являются наиболее распространенными типами алгоритмов ранжирования. Ранжирование по вероятности является наиболее точным типом алгоритма ранжирования, поскольку оно учитывает неопределенность данных. Если вы хотите узнать больше об алгоритмах ранжирования, оставьте комментарий ниже.
- Автор
- Последние сообщения
Аджитеш Кумар
Недавно я работал в области анализа данных, включая науку о данных и машинное обучение / глубокое обучение. Я также увлекаюсь различными технологиями, включая языки программирования, такие как Java/JEE, Javascript, Python, R, Julia и т. д., а также такие технологии, как блокчейн, мобильные вычисления, облачные технологии, безопасность приложений, платформы облачных вычислений, большие данные, и т. д. Чтобы быть в курсе последних обновлений и блогов, следите за нами в Twitter. Я хотел бы связаться с вами на Linkedin.
Я также увлекаюсь различными технологиями, включая языки программирования, такие как Java/JEE, Javascript, Python, R, Julia и т. д., а также такие технологии, как блокчейн, мобильные вычисления, облачные технологии, безопасность приложений, платформы облачных вычислений, большие данные, и т. д. Чтобы быть в курсе последних обновлений и блогов, следите за нами в Twitter. Я хотел бы связаться с вами на Linkedin.
Ознакомьтесь с моей последней книгой, озаглавленной «Основы мышления: создание успешных продуктов с использованием первых принципов».
Недавно я работал в области аналитики данных, включая науку о данных и машинное обучение/глубокое обучение. Я также увлекаюсь различными технологиями, включая языки программирования, такие как Java/JEE, Javascript, Python, R, Julia и т. д., а также такие технологии, как блокчейн, мобильные вычисления, облачные технологии, безопасность приложений, платформы облачных вычислений, большие данные, и т. д. Чтобы быть в курсе последних обновлений и блогов, следите за нами в Twitter. Я хотел бы связаться с вами на Linkedin.
Ознакомьтесь с моей последней книгой под названием «Мышление на основе первых принципов: создание успешных продуктов с использованием мышления на основе первых принципов».0003
Я хотел бы связаться с вами на Linkedin.
Ознакомьтесь с моей последней книгой под названием «Мышление на основе первых принципов: создание успешных продуктов с использованием мышления на основе первых принципов».0003
Опубликовано в Data Science. Помечены машинным обучением.
Азбука обучения рейтингу
Поиск нужной вещи во время покупок может быть утомительным. Вы можете часами просеивать похожие результаты только для того, чтобы сдаться в отчаянии. Может быть, поэтому 79% людей, которым не нравится то, что они находят, уходят с корабля и ищут другой сайт.
Должен быть лучший способ обслуживать клиентов с улучшенным поиском.
И есть. Обучение ранжированию — это метод машинного обучения, который помогает вам предоставлять результаты, которые не только релевантны, но и… подождите… ранжированы по этой релевантности.
Поисковые системы используют обучение для ранжирования почти два десятилетия, поэтому вам может быть интересно, почему вы ничего об этом не слышали.
Как и во многих предыдущих процессах машинного обучения, нам требовалось больше данных, и мы использовали лишь несколько функций для ранжирования, включая частоту терминов, обратную частоту документов и длину документа.
79 процентов людей, которым не нравится то, что они находят, уходят с корабля и ищут другой сайт.
Итак, люди настраивали вручную и повторяли снова и снова. Теперь измученными являются специалисты по данным, а не покупатели. Усталость кругом!
Сегодня у нас больше обучающих наборов и улучшены возможности машинного обучения.
Но все еще есть проблемы, особенно связанные с определением функций; преобразование данных поискового каталога в эффективные обучающие наборы; получение суждений о релевантности, включая как явные суждения людей, так и неявные суждения, основанные на журналах поиска; и принятие решения о том, какую целевую функцию оптимизировать для конкретных приложений.
Что такое научиться ранжировать?
Обучение ранжированию (LTR) — это класс алгоритмических методов, которые применяют контролируемое машинное обучение для решения проблем ранжирования в релевантности поиска. Другими словами, это то, что заказывает результаты запроса. Сделано хорошо, у вас есть счастливые сотрудники и клиенты; сделано плохо, в лучшем случае у вас будут разочарования, а что еще хуже, они никогда не вернутся.
Другими словами, это то, что заказывает результаты запроса. Сделано хорошо, у вас есть счастливые сотрудники и клиенты; сделано плохо, в лучшем случае у вас будут разочарования, а что еще хуже, они никогда не вернутся.
Для обучения ранжированию вам необходим доступ к обучающим данным, поведению пользователей, профилям пользователей и мощная поисковая система, такая как SOLR.
Данные обучения для модели обучения ранжированию состоят из списка результатов для запроса и рейтинг релевантности для каждого из этих результатов по отношению к запросу. Специалисты по данным создают эти обучающие данные, изучая результаты и принимая решение о включении или исключении каждого результата из набора данных.
Этот проверенный набор данных становится золотым стандартом, который модель использует для прогнозирования. Мы называем это исходной истиной и сравниваем с ней наши прогнозы.
Точечный, парный и списочный LTR-подходы
Три основных подхода к LTR известны как точечный, парный и списочный.
Точечный
Точечный подход рассматривает один документ за раз, используя классификацию или регрессию, чтобы найти наилучшее ранжирование для отдельных результатов.
Классификация означает помещение похожих документов в один и тот же класс — подумайте о сортировке фруктов на стопки по типам; клубника, ежевика и черника относятся к группе ягод (или классу), а персики, вишня и слива относятся к группе косточковых фруктов. (Видео: кластеризация и классификация)
Регрессия означает присвоение похожим документам аналогичного значения функции, чтобы мы могли назначать им аналогичные предпочтения во время процедуры ранжирования.
Во время этих процессов мы даем каждому документу баллы за то, насколько он подходит. Мы добавляем их и сортируем список результатов. Обратите внимание, что оценка каждого документа в списке результатов для запроса не зависит от оценки любого другого документа, т. е. каждый документ считается «баллом» для ранжирования, независимым от других «баллов»
Попарно
Попарно подходит для просмотра двух документов вместе. Они также используют классификацию или регрессию — чтобы решить, какая из пар занимает более высокое место.
Они также используют классификацию или регрессию — чтобы решить, какая из пар занимает более высокое место.
Мы сравниваем эту пару «выше-меньше» с реальной истиной (золотой стандарт ранжированных данных рук, который мы обсуждали ранее) и корректируем ранжирование, если оно не совпадает. Цель состоит в том, чтобы свести к минимуму количество случаев, когда пара результатов находится в неправильном порядке относительно основной истины (также называемой инверсией).
Listwise
Списковые подходы определяют оптимальное упорядочение всего списка документов. Идентифицируются наземные списки истинности, и машина использует эти данные для ранжирования своего списка. Списочные подходы используют вероятностные модели для минимизации ошибки порядка. Они могут быть довольно сложными по сравнению с точечными или парными подходами.
Рис. 1. Обучение (получению и) рангу — Интуитивно понятный обзор — Часть III0009
Прежде чем приступить к построению моделей, вам необходимо определиться с подходом, который вы хотите использовать.
При одних и тех же данных лучше обучать одну модель для всех или несколько моделей для разных наборов данных? Как известные модели обучения ранжированию справляются с этой задачей?
Вам также необходимо:
- Перед созданием обучающего набора данных определиться с признаками, которые вы хотите представить, и выбрать надежные суждения о релевантности.
- Выберите используемую модель и цель для оптимизации.
В частности, обученные модели должны иметь возможность обобщать:
- Ранее невиданные запросы, не входящие в обучающий набор, и
- Ранее не просмотренные документы должны быть ранжированы по запросам, обнаруженным в обучающем наборе.
Кроме того, увеличение доступных обучающих данных повышает качество модели, но высококачественные сигналы, как правило, разрежены, что приводит к компромиссу между количеством и качеством обучающих данных. Понимание этого компромисса имеет решающее значение для создания наборов обучающих данных.
Корпорация Майкрософт разрабатывает алгоритмы обучения ранжированию
Доступные варианты обучения алгоритмам ранжирования расширились за последние несколько лет, предоставив вам больше возможностей для принятия практических решений в отношении вашего проекта обучения ранжированию. Это довольно технические описания, поэтому, пожалуйста, не стесняйтесь обращаться с вопросами.
RankNet, LambdaRank и LambdaMART — популярные алгоритмы обучения ранжированию, разработанные исследователями Microsoft Research. Все используют попарное ранжирование.
RankNet вводит использование градиентного спуска (GD) для изучения функции обучения (обновления весов или параметров модели) для задачи LTR. Поскольку GD требует вычисления градиента, RankNet требует модели, для которой выход представляет собой дифференцируемую функцию , что означает, что ее производная всегда существует в каждой точке ее области (они используют нейронные сети, но это может быть любая другая модель с этим свойством).
Обучение ранжированию (LTR) — это класс алгоритмических методов, которые применяют контролируемое машинное обучение для решения проблем ранжирования в релевантности поиска. Другими словами, это то, что заказывает результаты запроса. Сделано хорошо, у вас есть счастливые сотрудники и клиенты; сделано плохо, в лучшем случае у вас будут разочарования, а что еще хуже, они никогда не вернутся.
RankNet представляет собой парный подход и использует GD для обновления параметров модели, чтобы минимизировать стоимость (RankNet был представлен с функцией стоимости Cross-Entropy). Это похоже на определение силы и направления для применения при обновлении позиций двух кандидатов (один занимает более высокое место в списке, а другой — более низкий, но с той же силой). В качестве окончательного решения по оптимизации они ускоряют весь процесс, используя мини-пакетный стохастический градиентный спуск (вычисление всех обновлений веса для данного запроса перед их фактическим применением).
LambdaRank основан на идее, что мы можем использовать одно и то же направление (градиент, оцененный по паре кандидатов, определяемой как лямбда) для замены, но масштабируя его изменением конечной метрики, такой как nDCG, на каждом шаге ( например, замена пары и немедленное вычисление дельты nDCG). Это очень удобный подход, поскольку он поддерживает любую модель (с дифференцируемым выходом) с метрикой ранжирования, которую мы хотим оптимизировать в нашем случае использования.
LambdaMART вдохновлен LambdaRank, но основан на семействе моделей под названием MART (Multiple Additive Regression Trees). Эти модели используют деревья с усилением градиента, которые представляют собой каскад деревьев, в которых градиенты вычисляются после каждого нового дерева, чтобы оценить направление, которое минимизирует функцию потерь (которая будет масштабироваться вкладом следующего дерева). Другими словами, каждое дерево вносит вклад в шаг градиента в направлении, которое минимизирует функцию потерь. Ансамбль этих деревьев является окончательной моделью (т. е. деревьями повышения градиента). LambdaMART использует этот ансамбль, но заменяет этот градиент лямбдой (градиент, вычисленный на основе пар кандидатов), представленным в LambdaRank.
Ансамбль этих деревьев является окончательной моделью (т. е. деревьями повышения градиента). LambdaMART использует этот ансамбль, но заменяет этот градиент лямбдой (градиент, вычисленный на основе пар кандидатов), представленным в LambdaRank.
Этот алгоритм часто считается попарным, так как лямбда рассматривает пары кандидатов, но на самом деле он должен знать весь ранжированный список (т. е. масштабирование градиента с коэффициентом метрики nDCG, который учитывает весь список) четкая характеристика подхода Listwise.
Обучение ранжированию приложений в промышленности
Wayfair
В сообщении в своем техническом блоге Wayfair рассказывает о том, как они использовали обучение ранжированию для целей поиска по ключевым словам. Wayfair — это публичная компания электронной коммерции, которая продает товары для дома. Таким образом, поиск имеет решающее значение для взаимодействия с клиентами. Wayfair решает эту проблему, используя LTR в сочетании с методами машинного обучения и обработки естественного языка (NLP), чтобы понять намерения клиента и предоставить соответствующие результаты.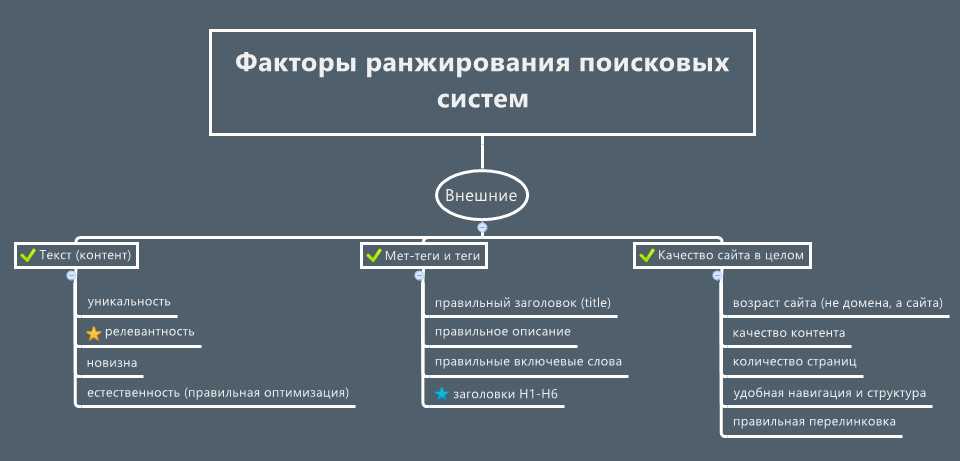
На приведенной ниже схеме показана поисковая система Wayfair. Они извлекают текстовую информацию из различных наборов данных, включая обзоры пользователей, каталог продуктов и историю посещений. Затем они используют различные методы НЛП для извлечения сущностей, анализа настроений и преобразования данных.
Затем Wayfair передает результаты в свой собственный модуль Query Intent Engine, чтобы определить намерения клиентов по большей части входящих запросов и направить многих пользователей прямо на нужную страницу с отфильтрованными результатами. Когда Intent Engine не может найти прямое соответствие, они используют модель поиска по ключевым словам. И тут на помощь приходит LTR.
Рисунок 2. Система поиска Wayfair
В своем подходе к поиску по ключевым словам Wayfair выполняет входящий поиск для получения результатов по всему каталогу продуктов. Под капотом они обучили модель LTR (используемую Solr) для присвоения оценки релевантности отдельным продуктам, возвращенным для входящего запроса. Затем Wayfair обучает свою модель LTR на данных о кликах и журналах поиска, чтобы предсказать оценку для каждого продукта. Эти оценки в конечном итоге будут определять позицию продукта в результатах поиска. Модель улучшается со временем, поскольку она получает обратную связь от новых данных, которые генерируются каждый день.
Затем Wayfair обучает свою модель LTR на данных о кликах и журналах поиска, чтобы предсказать оценку для каждого продукта. Эти оценки в конечном итоге будут определять позицию продукта в результатах поиска. Модель улучшается со временем, поскольку она получает обратную связь от новых данных, которые генерируются каждый день.
Результаты показывают, что эта модель улучшила коэффициент конверсии запросов клиентов Wayfair. В частности, они создали персонализированную сортировку по релевантности и поиск по разделам, называемым лучшими результатами, который представляет как персонализированные, так и недавние результаты в одном представлении. Обратите внимание, что поиск внутри Slack сильно отличается от обычного веб-поиска, потому что каждый пользователь Slack имеет доступ к уникальному набору документов, и то, что актуально в данный момент, часто меняется.
Slack предлагает две стратегии поиска: недавние и релевантные. Недавний поиск находит сообщения, соответствующие всем терминам, а затем представляет их в обратном хронологическом порядке. Релевантный поиск ослабляет ограничение по возрасту и учитывает, насколько документ соответствует условиям запроса.
Релевантный поиск ослабляет ограничение по возрасту и учитывает, насколько документ соответствует условиям запроса.
Сотрудники Slack заметили, что релевантный поиск работает немного хуже, чем недавний поиск, в соответствии с показателями качества поиска, такими как количество кликов на поиск и рейтинг кликов результатов поиска на нескольких верхних позициях.
Рисунок 3. Лучшие результаты по запросу «дорожная карта платформы»
Включение дополнительных функций, несомненно, улучшит ранжирование результатов релевантного поиска. Для этого команда Slack использует двухэтапный подход: (1) использование настраиваемой функции сортировки Solr для извлечения набора сообщений, ранжированных только по нескольким избранным функциям, которые Solr легко вычислить, и (2) повторное ранжирование. эти сообщения на прикладном уровне в соответствии с полным набором функций, взвешенных соответствующим образом. При построении модели для определения этих весов первой задачей было создание размеченного обучающего множества. Команда Slack использовала описанный ранее попарный метод, чтобы оценить относительную релевантность документов в рамках одного поиска с помощью кликов.
Команда Slack использовала описанный ранее попарный метод, чтобы оценить относительную релевантность документов в рамках одного поиска с помощью кликов.
Этот подход был включен в модуль лучших результатов Slack, который показывает значительное увеличение количества поисковых сеансов на пользователя, увеличение количества кликов на поиск и сокращение поисков на сеанс. Это указывает на то, что пользователи Slack могут быстрее находить то, что ищут.
Skyscanner
Skyscanner, приложение для путешествий, в котором пользователи ищут авиабилеты и бронируют идеальное путешествие, использует LTR для поиска маршрута полета.
Поиск сложен и включает в себя цены, доступное время, промежуточные рейсы, окна для путешествий и многое другое. Цель Skyscanner — помочь пользователям найти лучшие рейсы для их обстоятельств.
Команда Skyscanner переводит задачу ранжирования элементов в задачу бинарной регрессии. Они помечают свои данные об элементах, которые пользователи считают релевантными их запросам, как положительные примеры, а данные об элементах, которые пользователи считают не относящимися к их запросу, — как отрицательные примеры. Затем они используют эти данные для обучения модели машинного обучения для прогнозирования вероятности того, что пользователь найдет рейс, соответствующий поисковому запросу. В частности, термин релевантность определяется как переход по ссылке на веб-сайт авиакомпании и туристического агентства для его покупки, поскольку это требует от пользователя множества действий.
Затем они используют эти данные для обучения модели машинного обучения для прогнозирования вероятности того, что пользователь найдет рейс, соответствующий поисковому запросу. В частности, термин релевантность определяется как переход по ссылке на веб-сайт авиакомпании и туристического агентства для его покупки, поскольку это требует от пользователя множества действий.
Рисунок 4. Релевантность при поиске рейсов: результат поиска релевантен, если вы его купили
После применения LTR к данным они проводят как офлайн, так и онлайн эксперименты для проверки производительности модели. В частности, они сравнивают пользователей, которым дали рекомендации с помощью машинного обучения, пользователей, которым дали рекомендации с помощью эвристики, учитывающей только цену и продолжительность, и пользователей, которым вообще не давали рекомендаций. Результаты показывают, что модель LTR с машинным обучением приводит к лучшим показателям конверсии — как часто пользователи будут покупать рейс, рекомендованный моделью Skyscanner.