Поисковые алгоритмы Яндекса
В этой статье вы найдете наиболее полную подборку информации обо всех алгоритмах поисковой системы Яндекс, а также ссылки на официальные источники этих данных.
Поисковый алгоритм — это определенная математическая формула, по которой поисковая система вычисляет, как именно должны ранжироваться сайты в поисковой выдаче. Как правило, большинство алгоритмов затрагивали либо ссылочные факторы, либо текстовый контент.
Непот фильтр — 2005 год
Вес внешних ссылок с сайтов, которые занимаются линкоторговлей, перестает учитываться.
Новая формула ранжирования — 2007 год
Теперь алгоритм зависим от запросов. Он по разному ранжирует однословные и многословные запросы. Это первый поисковый апдейт Яндекса, который был официально анонсирован Садовским на https://searchengines.guru/showthread.php?t=149644
Алгоритм Родео — 07.08.2007
Появление новой формулы ранжирования для запросов из одного слова. Теперь в выдаче по таким запросам преимущество отдается главным страницам.
Восьмерка SP 1
Снижение веса ссылок с главных страниц ресурсов. После этого апдейта вебмастера начинают покупать ссылки с внутренних страниц.
Гости из прошлого — 5 февраля 2008
Теперь ссылки с сайтов, которые находятся под Непот фильтром, получают минимальный вес, который стремится в нулю. Это означает, что теперь нельзя определять площадки, которые находятся под санкциями, с помощью меток в анкорах. Обсуждение этого фильтра началось с обсуждения на серче. https://searchengines.guru/showthread.php?t=201743
Крупный ссылочный апдейт — 18 марта 2008 года
Теперь ссылки с главных страниц полностью теряют свой вес. Большинство сайтов, которые держались в выдаче с помощью таких ссылок, полностью выпали из ТОП-10. Ссылки с внутренних страниц все еще работают.
Иноязычные документы — 4 апреля 2008 года
https://yandex.ru/blog/webmaster/535
Теперь в выдаче появляются иноязычные документы. Причина в том, что Яндекс теперь ведет поиск и по зарубежным сайтам.
Магадан — 16 мая 2008 года
https://yandex.ru/blog/webmaster/839
Первый именной поисковый алгоритм Яндекса. Теперь появилась выдача по информационным запросам. Также, Яндекс научился расшифровывать аббревиатуры и транслитерацию.
Магадан 2.0 — 2 июля 2008
https://yandex.ru/blog/webmaster/1062
С этим апдейтом Яндекс научился определять и ранжировать коммерческие запросы. Теперь очень важен фактор уникальности текстов, а возраст сайта уже не играет большой роли для ранжирования.
Изменения в алгоритме тИЦ — 28 августа 2008
https://yandex.ru/blog/webmaster/1439
Апдейт коснулся сайтов, которые накручивают тИЦ с помощью специальных алгоритмов. Их значение тИЦ резко снизилось до показателей от 0 до 10.
Находка — 11 сентября 2008
https://yandex.ru/blog/webmaster/1622
Зафиксировано значительное увеличение внутренних страниц. Теперь в выдаче по высокочастотным и среднечастотным запросам присутствуют не только главные страницы, но и внутренние. Морфологические изменения, в частотности, по запросам в единственном и множественном числе — разная выдача. В выдаче по коммерческим запросам можно встретить информационные страницы.
Арзамас (Анадырь) — 8 апреля 2009
https://yandex.ru/blog/webmaster/3255
Появление региональной выдачи. В Яндекс.Вебмастере появилась возможность привязки сайта к конкретному региону. При ранжировании запросов с неоднозначным значением в выдачу подмешиваются различные результаты.
Понижение страниц с popunder-баннерами — 30 апреля 2009
https://yandex.ru/blog/webmaster/3772
Яндекс объявил войну popunder рекламе из-за того, что она мешает пользователям, теперь такие сайты ранжируются ниже.
Арзамас 1.1 — 24 июня 2009
https://yandex.ru/blog/webmaster/4610
Улучшена формула регионального ранжирования для всех регионов, исключая Москву, Санкт-Петербург и Екатеринбург.
Страницы с clickunder ранжируются ниже — 11 августа 2009
https://yandex.ru/blog/webmaster/4967
Значительное понижение страниц с такой рекламой в поисковой выдаче.
Арзамас 1.2 — 20 августа 2009
https://yandex.ru/blog/webmaster/5055
Появление классификации геозависимости запросов. Теперь запросы делятся на геозависимые и геонезависимые.
АГС 17
https://www.searchengines.ru/008057.html
Фильтр, направленный на искоренение некачественного контента. Под него попадают сайты, которые содержат неуникальный, или мусорный контент. Симптомы — в индексе остается всего несколько страниц, а чаще всего только главная страница.
Снежинск — 17 ноября 2009
https://yandex.ru/blog/webmaster/5869
Первое применение алгоритма машинного обучения Матрикснет. В разы увеличено количество учитываемых при ранжировании параметров, благодаря чему качество поиска было серьезно улучшено.
АГС-30 — 18 декабря 2009
https://yandex.ru/blog/webmaster/6456
Улучшенная версия алгоритма АГС-17. Количество учитываемых в ранжировании параметров значительно увеличено, теперь учитывается около 100 факторов. Сайты с неактуальным контентом оказались под угрозой получения санкций.
Поиск Яндекса в каждом городе — 22 декабря 2009
https://yandex.ru/blog/webmaster/6895
Локальное ранжирование теперь работает не только для 19 крупнейших регионов, как это было ранее, а для 1250 городов по всей России.
21. Портяночный фильтр — 20 января 2010
Этот алгоритм является предшественником фильтра «Ты спамный». Накладывается за большие и длинные тексты, переспамленные ключевыми словами. Как правило, фильтр накладывался на страницу, содержащую «портянку» из текста.
Снежинск 1.1 — 10 марта 2010
https://yandex.ru/blog/webmaster/7465
Улучшена формула ранжирования по геонезависимым запросам для пользователей России.
Обнинск — 13 сентября 2010
https://yandex.ru/blog/webmaster/8403
Улучшено ранжирование по геозависимым запросам. Значительно увеличена формула ранжирования, почти в 2,5 раза. Такое внимание к ранжированию геозависимых запросов обусловлено тем, что они составляют почти 70% от всех запросов.
Улучшение определения авторства — 2 ноября 2010
https://yandex.ru/blog/webmaster/9118
Предпочтение в ранжировании теперь отдается авторским публикациям. Страницы с чужими текстами теперь ранжируются ниже.
Краснодар (Технология Спектр) — 15 декабря 2010
https://yandex.ru/blog/webmaster/9477
Алгоритм на основе пользовательской истории формирует нужные ответы на неоднозначные запросы. В основе этой технологии лежит статистика поисковых запросов по более чем 60-ти тематикам. Например, под поисковым запросом «Пушкин» может подразумеваться город или всем известный русский поэт. Алгоритм автоматически определяет, какой именно результат желает увидеть пользователь.
Более подробно про технологию вы сможете прочитать в статье нашего блога https://labrika.ru/blog/spektr
Обновление алгоритма ранжирования по геозависимым запросам — 17 декабря 2010
https://webmaster.yandex.ru/blog/9559
Преимущества в ранжировании по регионам получают местные сайты. Привязка сайта к конкретному региону становится более важна для продвижения по нему.
Фильтр за накрутку поведенческих факторов — 23 мая 2011
https://yandex.ru/blog/webmaster/10399
Яндекс объявляет войну программам накрутки, которые эмулируют действия пользователей на сайте. Позиции сайтов, на которых была замечена накрутка, были существенно понижены.
Рейкьявик — 17 августа 2011
https://yandex.ru/blog/company/38489
Каждый пользователь получает информацию в выдаче в соответствии со своими языковыми предпочтениями. В поиске по англоязычным запросам отображаются и страницы на русском языке, но если пользователь регулярно открывает англоязычные сайты, соответственно, они будут чаще отображаться в поиске. Алгоритм самообучаемый, поэтому, если меняются языковые предпочтения пользователя, то вместе с ними меняется и поисковая выдача.
Ты спамный — 13 сентября 2011
https://webmaster.yandex.ru/blog/11464
Обновление портяночного фильтра. Под угрозой оказались страницы с большим количеством текста, перенасыщенным ключевыми словами, также нежелательно, чтобы на странице было много выделений курсивом и жирным шрифтом. Тексты должны быть для людей, а не для роботов. Также, стали учитываться поведенческие факторы пользователей — под фильтр попадают только страницы с низким ПФ.
Яндекс начинает учитывать юзабилити сайтов — 5 октября 2011
https://yandex.ru/blog/webmaster/11888
Приоритет отдается сайтам с удобной структурой и навигацией. Сайты, которые неудобны для пользователей и имеют плохие поведенческие факторы, ранжируются ниже. Также, проблемы будут у сайтов, на которых рекламные баннеры мешают просмотру контента.
Новая формула ранжирования для коммерческих сайтов — 23 ноября 2011
https://yandex.ru/blog/webmaster/12443
При ранжировании сайтов учитываются дополнительные параметры, такие как наличие цен, разнообразие ассортимента продукции, различные возможности оплаты и доставки, доверие к компании и пользовательский интерфейс. Изначально, алгоритм применялся только к Московскому региону, но потом стал учитываться и в других регионах России.
Калининград (персональный поиск) — 12 декабря 2012
https://yandex.ru/company/press_releases/2012/1212/
Яндекс запускает персональный поиск, теперь при запросе пользователя учитывается история его предыдущих запросов, на основе которых формируются предполагаемые интересы пользователя. Например, при запросе «гарри поттер», пользователю, который любит читать, поисковая система, в первую очередь, покажет информацию о книге, а не о фильме или компьютерной игре.
Персональные подсказки для зарегистрированных пользователей — 7 февраля 2012
https://yandex.ru/blog/company/43447
При введении запроса в поисковую строку появляются не только популярные запросы, но и те запросы, которые пользователь уже вводил ранее.
Региональный поиск в Яндекс.Картинки — 16 февраля 2012
https://yandex.ru/blog/company/43792
Теперь по одному и тому же запросу пользователи из России, Беларуси, Украины и Казахстана могут видеть разные изображения, а именно, те, которые будут больше соответствовать их стране или региону.
Сайты с обманными pop-up элементами ранжируются ниже — 15 мая 2012
https://yandex.ru/blog/webmaster/13533
Ресурсы, которые содержат уведомления, обманывающие пользователей, теперь имеют меньший приоритет при ранжировании.
Дублин — 30 мая 2013
https://yandex.ru/company/press_releases/2013/0530/
https://yandex.ru/blog/company/66549
Теперь Яндекс учитывает не только персональные интересы пользователей, но и сиюминутные, и дает тот ответ, который хочет увидеть пользователь именно сейчас.
АГС-40 — 6 ноября 2013
https://yandex.ru/blog/webmaster/16272
Обновление всем известного алгоритма включило в себя дополнительные показатели, по которым поисковая машина определяет низкое качество сайта. Санкции, по-прежнему, накладываются автоматически.
Анонс алгоритма бессылочного ранжирования — 5 декабря 2013
https://yandex.ru/blog/webmaster/16843
Яндекс начинает вводить формулу ранжирования, которая не будет учитывать ссылки по коммерческим запросам.
Отмена учета ссылок в ранжировании коммерческих запросов — 12 марта 2014
https://yandex.ru/blog/webmaster/18092
Сначала алгоритм затронул только Московский регион и такие тематики как, например, недвижимость, туризм, электроника и бытовая техника.
Изменения в ранжировании страниц с шокирующей рекламой — 20 марта 2014
https://yandex.ru/blog/webmaster/18326
Страницы с отвлекающей рекламой (эротические баннеры, неприятные изображения и т. д.) стали ранжироваться ниже. Была отмечена положительная тенденция после внедрения изменений — количество страниц с шокирующей рекламой снизилось на 30%.
Изменения в работе алгоритма АГС — 15 апреля 2014
https://yandex.ru/blog/webmaster/18552
Очередное обновление алгоритма, задача которого бороться с некачественными сайтами. Теперь, вместо исключения страниц некачественного ресурса из поиска, у него будет обнуляться тИЦ .
Острова — 5 июня 2014
https://yandex.ru/blog/company/80704
Новый дизайн результатов поисковой выдачи. Позже Яндекс признал эксперимент неудачным и от данного нововведения пришлось отказаться.
Изменения в ранжировании страниц с назойливой рекламой — 22 сентября 2014
https://yandex.ru/blog/webmaster/19327
Очередное совершенствование алгоритма, направленного на борьбу с отвлекающей рекламой.
Пессимизация за накрутку поведенческих факторов — 1 декабря 2014
Под санкции попали сайты, которые накручивали переходы из поиска, а также ресурсы, которые использовали клики по покупным ссылкам, чтобы увеличить передаваемый ими вес.
Амстердам — 1 апреля 2015
В правой части результатов выдачи появляется информационный блок, в котором содержатся данные об объекте поиска.
Минусинск — 15 мая 2015
https://yandex.ru/blog/webmaster/20337
Сайты, которые используют для продвижения SEO-ссылки, теперь ранжируются ниже. Такие ограничения могут существенно снизить трафик из поисковых систем на несколько месяцев. Чтобы избежать неприятностей, Яндекс рекомендует полностью отказаться от SEO-ссылок и развивать web-ресурс.
https://yandex.ru/support/webmaster/yandex-indexing/algorithm-minusinsk.xml — все об алгоритме
Пессимизация за продажу ссылок с сайтов — 8 сентября 2015
https://yandex.ru/blog/webmaster/20960
Яндекс продолжает войну с методами продвижения, которые обманывают алгоритмы поисковой системы. Теперь за размещение SEO-ссылок на страницах сайт может попасть под пессимизацию — независимо от его качества. Как правило, ограничения в ранжировании сопровождаются обнулением тИЦ.
Многорукий бандит Яндекса — 14 сентября 2015
https://yandex.ru/blog/webmaster/20999
В ТОП-10 поисковой выдачи периодически подмешиваются новые страницы, которые еще не собрали нужного количества статистических данных для оценки поведенческих факторов. Это сделано для того, чтобы более молодые сайты могли конкурировать со старыми, надежно закрепившимися в поисковой выдаче. Возраст сайта уже не так важен для продвижения.
Опасные сайты — 2 октября 2015
https://yandex.ru/blog/webmaster/21119
https://yandex.ru/company/press_releases/2009/0526/ — об опасных сайтах. Теперь опасные сайты не только помечаются специальными предупреждениями в поисковой выдаче, но и ранжируются ниже.
Ссылки опять учитываются — 3 ноября 2015
На одной из лекций для вебмастеров от Яндекс сообщили, что ссылочное ранжирование опять работает для ряда тематик по Московскому региону.
Сайты с кликджекингом ранжируются ниже — 30 декабря 2015
https://yandex.ru/blog/webmaster/21745
Кликджекинг — это механизм обмана на сайтах, он связан с размещением на сайте невидимых элементов, с которыми пользователь взаимодействует, не подозревая об этом, при этом совершаются какие-либо действия. Такие сайты теперь ранжируются ниже.
Владивосток (Оптимизация для мобильных — теперь фактор ранжирования) — 2 февраля 2016
https://yandex.ru/blog/webmaster/optimizatsiya-dlya-mobilnykh-teper-faktor-ranzhirovaniya
Удобство использования сайта на мобильных устройствах становится фактором ранжирования. Теперь адаптивный дизайн или мобильная версия положительно учитываются при ранжировании ресурса.
Обновление алгоритма расчета тИЦ — 9 июня 2016
https://yandex.ru/blog/webmaster/obnovleniya-algoritma-rasch-ta-tits
Серьезным изменениям подверглись механизмы очистки ссылочного сигнала. Многие устаревшие показатели были исключены из алгоритма расчета.
Новый алгоритм Палех — 3 ноября 2016
https://yandex.ru/blog/webmaster/novyy-algoritm-palekh
https://habr.com/company/yandex/blog/314222/ — подробный разбор алгоритма.
Яндекс начал применять нейронные сети для поиска по смыслу. Новый алгоритм позволяет отвечать на сложные запросы, состоящие из большого количества слов и умеет находить документы не по словам, содержащимся в тексте, а по смыслу запроса и заголовка.
Алгоритм Баден-Баден 16 июня 2017
https://yandex.ru/blog/webmaster/baden-baden-novyy-algoritm-opredeleniya-pereoptimizirovannykh-tekstov
https://labrika.ru/blog/keis_po_vihodu_is_baden-baden — кейс по выводу сайта из-под фильтра Баден-Баден.
Обновление алгоритма, который определяет переоптимизированные тексты. Яндекс решил коренным образом бороться с SEO-текстами. Под этот фильтр массово начали попадать web-ресурсы, содержащие некачественные тексты с большим количеством ключевых слов. Попадание под фильтр сопровождается уведомлением в Яндекс.Вебмастер в разделе «Безопасность и нарушения». Сайты, попавшие в пессимизацию, резко теряют позиции в поисковой выдаче, а следовательно и трафик.
Алгоритм Королев — 22 августа 2017
https://yandex.ru/blog/webmaster/yandeks-predstavil-novyy-algoritm-korolev
Очень серьезное обновление поисковой системы. Мероприятие по запуску алгоритма было ярким и масштабным. Обновление в своей основе содержит алгоритм «Палех», но теперь нейронная сеть анализирует не только заголовок, но и всю страницу целиком. Это огромный шаг в сторону поиска по смыслу. Большое значение стала играть скрытая семантика — слова, которые относятся к одной и той же смысловой подгруппе и помогающие поисковой системе определить тематику страницы. Наше исследование на тему скрытой семантики вы можете прочитать — тут.
Запуск Турбо-страниц — 22 ноября 2017
https://yandex.ru/blog/webmaster/turbo-stranitsy-otkryty-dlya-vsekh
Появление в поисковой выдаче страниц, которые значительно ускоряют загрузку контента на мобильных устройствах. Пользователи моментально получают нужный контент и не уходят с ресурса из-за долгой загрузки. Создать турбо-страницы можно на любом сайте.
Фильтрация агрессивной рекламы — 5 февраля 2018
https://webmaster.yandex.ru/blog/s-5-fevralya-yandeks-brauzer-nachinaet-filtrovat-reklamu-razdrazhayuschikh-formatov
https://yandex.ru/support/webmaster/diagnosis/annoying-ads.html?utm_source=wmblog&utm_campaign=browser5
С первой недели февраля 2018 г. Яндекс прекращает использование на своих площадках раздражающих форматов рекламы, которые противоречат рекомендациям ассоциации IAB Russia. А также фильтрует такую рекламу в Яндекс Браузере. Проверить наличие на сайте раздражающей рекламы можно в разделе «Диагностика» Яндекс Вебмастера.
Борьба с некачественными турбо-страницами — 20 февраля 2018
https://webmaster.yandex.ru/blog/turbo-stranitsy-opyt-pervykh-trekh-mesyatsev
Яндекс объявляет о том, что с 5 марта 2018 г. некачественные турбо-страницы, содержимое которых не соответствует оригинальной версии, не будут появляться в Поиске, Дзене и Новостях. Их заменят оригинальными страницами сайта. Соответствующее предупреждение будет отображаться в Вебмастере.
Обновление алгоритма, определяющего влияние рекламы на удобство использования сайта — 24 апреля 2018
https://webmaster.yandex.ru/blog/o-reklame-kotoraya-vvodit-v-zabluzhdenie
Произошло обновление алгоритма, который используется для распознавания на сайте нарушения «Малополезный контент, некорректная реклама, спам». При наличии данного нарушения все страницы сайта могут ранжироваться ниже. Информация о нем отображается в Яндекс.Вебмастере в разделе «Диагностика» — «Безопасность и нарушения».
В результате обновления улучшилось определение страниц с рекламой, вводящей пользователей в заблуждение и мешающей навигации по сайту (например, маскирующейся под элементы интерфейса сайта).
Усиление внимания качеству ресурса — 1 июня 2018
https://webmaster.yandex.ru/blog/bolshe-vnimaniya-kachestvu
Яндекс заявил о внесении в основную метрику изменений с целью усиления учёта качества и оформления контента, удобства навигации по сайту, уместности и корректности рекламы.
Обновление алгоритма поиска в Яндекс.Картах — 3 августа 2018
https://webmaster.yandex.ru/blog/blyuda-v-poiske-po-kartam
Теперь посетители могут искать не только сами организации, но и товары из их прайс-листа. Обновление началось с поиска блюд из меню, загруженных в Яндекс.Справочник в формате XLSX.
Замена тИЦ на ИКС — 22 августа 2018
https://webmaster.yandex.ru/blog/yandeks-zamenyaet-tits-na-iks-novyy-pokazatel-kachestva-sayta
Яндекс перестает рассчитывать и отображать тематический индекс цитирования (тИЦ), определявший авторитетность ресурса по количеству и качеству ссылок на него. Его заменяет новый показатель — индекс качества сайта (ИКС). Под качеством сайта теперь в первую очередь понимается его востребованность аудиторией, способность удовлетворить запросы пользователей.
Усиление защиты пользователей от криптоджекинга — 21 сентября 2018
https://webmaster.yandex.ru/blog/yandeks-usilivaet-zaschitu-polzovateley-ot-kriptodzhekinga
Сайты, тайно использующие устройства пользователей для майнинга криптовалют, могут ранжироваться ниже в поисковой выдаче. При переходе на них пользователям будет выдаваться предупреждение. Владельцы сайтов, на которых будут обнаружены скрипты криптоджекинга, получат уведомление в сервисе Яндекс.Вебмастер в разделе «Безопасность и нарушения».
Обновленный поиск Андромеда — 19 ноября 2018
https://yandex.ru/blog/company/bolshoe-obnovlenie-poiska
Масштабное обновление поиска, содержащее более тысячи улучшений. Основные направления:
- увеличение количества быстрых ответов, которые можно получить прямо в выдаче;
- обновление формулы ранжирования — большее значение приобрели удобство для пользователей, наличие постоянной аудитории, полезного и ненавязчивого контента;
- возможность в один клик сохранять понравившиеся находки (ссылки, картинки, видео и т. д.) на сервисе Яндекс.Коллекции.
Обновление ИКС — 25 декабря 2018
https://webmaster.yandex.ru/blog/obnovlennyy-iks
Внесены коррективы в алгоритм расчета индекса качества сайта (ИКС) — в новой версии ИКС не присваивается сайтам, которые больше не содержат контента, а также при недостаточном количестве данных о сайте.
Защита пользователей от навязчивых оповещений — 10 января 2019
https://webmaster.yandex.ru/blog/zaschischaem-polzovateley-ot-navyazchivykh-opovescheniy
Сайты, которые вынуждают пользователя подписаться на рекламные оповещения, в результатах поиска ранжируются ниже и помечаются предупреждением об опасности.
HTTPS рассматривается как один из признаков качественного сайта — 21 февраля 2019
https://webmaster.yandex.ru/blog/https-kak-znak-kachestva-sayta
Яндекс объявляет использование защищенного протокола HTTPS одним из признаков безопасности сайта, который может быть учтен при ранжировании.
labrika.ru
Хронология алгоритмов Яндекса

Методика Яндекса по определению релевантности контента запросам пользователей претерпела многочисленные изменения со времени появления компании в 1997 году. Постоянно разрабатывались новые, усовершенствованные формулы ранжирования, но общественности эта внутренняя работа стала видна только с 2007 года. Тогда же алгоритмам стали присваиваться названия. Главные особенности каждого из них мы рассмотрим в краткой хронологии за последние десять лет.
«Версия 7» (02.07.07)
Обновлённый алгоритм с повышенным числом факторов был анонсирован только на специализированном форуме для вебмастеров.
«Версия 8» (20.12.07) и «Восьмерка SP1» (17.01.08)
Авторитетные сайты стали пользоваться преимуществом в ранжировании, появился фильтр для борьбы с накруткой ссылочных факторов.
«Магадан» (16.05.08) и «Магадан 2.0» (02.07.08)
Первые «именные» алгоритмы. Сначала увеличилось количество классификаторов веб-страниц и ссылок, модернизировалась база аббревиатур, в два раза возросло число факторов ранжирования, смягчилась фильтрация отбора документов, затем появились новые факторы для проверки уникальности контента и классификаторы коммерческих и геозапросов.
«Находка» (11.09.08)
Новый алгоритм стал учитывать стоп-слова в запросах. Также расширились словари Яндекса вследствие автообработки «оболочки» текста, модернизировалось машинное обучение.
«Арзамас»/«Анадырь» (10.04.09)
Самым важным нововведением стала зависимость характера выдачи от региона местонахождения пользователя, задавшего поисковый запрос. Также произошло снятие омонимии, улучшилась обработка многословных запросов. Впоследствии алгоритм получил несколько органических продолжений:
- «Арзамас 1.1» (24.06.09)– доработана формула для ряда регионов России;
- «Арзамас 1.2» (20.08.09)– стала учитываться геозависимость запросов;
- «Арзамас+16» (31.08.09) – дополнение 16-ю регионами для геозависимых запросов;
- «Арзамас 1.5» (23.09.09)– улучшенная общая формула для геонезависимых запросов и региональных запросов, где не применяется локализованный рейтинг;
- «Арзамас 1.5 SP1» (28.09.09)– заработала дополненная формула регионального поиска.
«Снежинск» (17.11.09)
Алгоритм был поставлен на платформу самообучающейся системы MatrixNet. Было добавлено несколько тысяч новых параметров ранжирования, проработана локальная выдача для девятнадцати российских регионов.
«Конаково» (22.12.09) и «Конаково 1.1» (10.03.10)
На 1250 российских городов расширилась база регионального ранжирования, затем обновилась формула для геонезависимых запросов. В выдаче хорошо поднялись некоммерческие информационные ресурсы.
«Обнинск» (13.09.10)
Алгоритм с перенастроенной формулой, повышенной производительностью, улучшенной обработкой геонезависимых запросов, ограниченным влиянием на рейтинг искусственных ссылок.
«Краснодар» (15.12.10)
В основу алгоритма была заложена поисковая технология «Спектр», которая помогла более чётко распознавать различные значения слов в запросах пользователей и разнообразить выдачу. Также улучшилась локализация геозависимых запросов.
«Рейкьявик» (17.08.11)
Алгоритм стал учитывать языковые предпочтения пользователей, выдавать два варианта ответов – с исправленной опечаткой в запросе и неизменный, и заложил основы персонализированной выдачи.
«Калининград» (12.12.12)
Произошла глобальная персонализация выдачи: возникли поисковые подсказки, избранные сайты стали выдаваться как наиболее релевантные. В продвижении сайтов стали комплексно учитываться множество факторов: качество контента и ссылочного профиля, юзабилити сайта, социальные сигналы и других.
«Дублин» (30.05.13)
Продолжалась и совершенствовалась персонализация поиска. Система стала подстраиваться под интересы пользователя прямо в процессе текущей поисковой сессии.
«Без ссылок» (12.03.14)
Было отменено несколько ссылочных факторов ранжирования по ряду коммерческих запросов в Москве (в сфере недвижимости, туризма, электроники и бытовой техники).
«Острова» (05.06.14)
Произошло обновление дизайна поисковой выдачи с помощью интерактивных ответов прямо на странице с результатами поиска. Позже этот эксперимент признали неудачным и свернули.
«Объектный ответ» (01.04.15)
Изменился внешний вид страницы с результатами поиска. Справа от результатов Яндекс стал показывать карточку запрашиваемого объекта с основной информацией, а также классифицировал в базу множество объектов поиска.
«Минусинск» (15.05.15)
Алгоритм понизил в рейтинге сайты с избытком искусственных ссылок в ссылочном профиле. В работах по продвижению Яндекс рекомендовал уделить внимание качеству контента и проработанности дизайна сайта.
«Многорукие бандиты Яндекса» (14.09.15 ± 3 месяца)
«Бандиты» рандомизировали поисковую выдачу, добавив в неё «молодые» ресурсы. Рандомизация проводилась для выявления дополнительных поведенческих особенностей.
«Владивосток» (02.02.16)
Алгоритм стал учитывать адаптированность сайта к мобильным устройствам. Более высокий рейтинг стали получать ресурсы, наиболее приспособленные для мобильного просмотра.
«Палех» (02.11.16)
С помощью нейронных сетей поиск стал производиться не формально по словам, а по смыслу запроса и Title, т.е. заголовку страницы. Целью этого алгоритма стал качественный поиск по редким запросам (например, заданный в естественном разговорном формате).
«Баден-Баден» (23.03.17)
Алгоритм с рядом дополнительных факторов, отвечающих за определение переоптимизированного контента и понижающий его ранжирование в выдаче.
«Королёв» (22.08.17)
Логическое продолжение «Палеха». С помощью технологии искусственного интеллекта алгоритм научился сопоставлять интенты на сайте и смысл запроса. В отличие от своего предшественника, «Королёв» анализировал не только Title, но и весь контент страницы.
«Андромеда» (19.11.18)
Новейший алгоритм с рядом нововведений, большая часть которых относится к отображению на странице выдачи различных колдунщиков и Яндекс-сервисов. Улучшены функции «быстрых ответов», появились метки на страницах («Популярный сайт», «Выбор пользователей» и т.п.). В основе «Андромеды» – новая метрика качества поиска Proxima. Она нацелена на максимально быстрый поиск релевантного ответа прямо в поисковой выдаче и учитывает множество аспектов: вероятность решения поставленной пользователем задачи на конкретной странице; лояльность пользователей; баланс релевантного и рекламного контента; индекс попарного сравнения сайта с аналогами. Proxima быстро обучается на основе разнообразных запросов, и качество ранжирования также растёт.
www.iseo.ru
Компания Яндекс — Принципы — Принципы ранжирования поиска Яндекса
Интернет состоит из миллионов сайтов и содержит экзабайты информации. Чтобы люди могли узнать о существовании этой информации и воспользоваться ей, существуют поисковые системы. Они реализуют право человека на доступ к информации — любой информации, которая нужна в данный момент. Поисковая система — это техническое средство, с помощью которого пользователь интернета может найти данные, уже размещенные в сети.
Пользователи ищут в интернете самые разные вещи — от научных работ до эротического контента. Мы считаем, что поисковая система в каждом случае должна показывать подходящие страницы — от статей по определенной теме до сайтов для взрослых. При этом она просто находит ту информацию, которая уже есть в интернете и открыта для всех.
Яндекс не является цензором и не отвечает за содержание других сайтов, которые попадают в поисковый индекс. Об этом было написано в одном из первых документов компании «Лицензия на использование поисковой системы Яндекса», созданном еще в 1997 году, в момент старта www.yandex.ru: «Яндекс индексирует сайты, созданные независимыми людьми и организациями. Мы не отвечаем за качество и содержание страниц, которые вы можете найти при помощи нашей поисковой машины. Нам тоже многое не нравится, однако Яндекс — зеркало Рунета, а не цензор».Информация, которая удаляется из интернета, удаляется и из поискового индекса. Поисковые роботы регулярно обходят уже проиндексированные сайты. Когда они обнаруживают, что какая-то страница больше не существует или закрыта для индексирования, она удаляется и из поиска. Для ускорения этого процесса можно воспользоваться формой «Удалить URL».В ответ на запрос, который пользователь ввел в поисковой строке, поисковая система показывает ссылки на известные ей страницы, в тексте которых (а также в метатегах или в ссылках на эти сайты) содержатся слова из запроса. В большинстве случаев таких страниц очень много — настолько, что пользователь не сможет просмотреть их все. Поэтому важно не просто найти их, но и упорядочить таким образом, чтобы сверху оказались те, которые лучше всего подходят для ответа на заданный запрос — то есть, наиболее релевантные запросу. Релевантность — это наилучшее соответствие интересам пользователей, ищущих информацию. Релевантность найденных страниц заданному запросу Яндекс определяет полностью автоматически — с помощью сложных формул, учитывающих тысячи свойств запроса и документа. Процесс упорядочивания найденных результатов по их релевантности называется ранжированием. Именно от ранжирования зависит качество поиска — то, насколько поисковая система умеет показать пользователю нужный и ожидаемый результат. Формулы ранжирования строятся также автоматически — с помощью машинного обучения — и постоянно совершенствуются.
Качество поиска — это самый важный аспект для любой поисковой системы. Если она будет плохо искать, люди просто перестанут ей пользоваться.
Поэтому мы не продаем места в результатах поиска.
Поэтому на результаты поиска никак не влияют политические, религиозные и любые другие взгляды сотрудников компании.
Пользователи просматривают страницу результатов поиска сверху вниз. Поэтому Яндекс показывает сверху, среди первых результатов, те документы, которые содержат наиболее подходящие пользователю ответы — то есть наиболее релевантные заданному запросу. Из всех возможных релевантных документов Яндекс всегда старается выбрать наилучший вариант.
С этим принципом связано несколько правил, которые Яндекс применяет к некоторым типам сайтов. Все эти правила работают полностью автоматически, их выполняют алгоритмы, а не люди.
1. Существуют страницы, которые явно ухудшают качество поиска. Они специально созданы с целью обмануть поисковую систему. Для этого, например, на странице размещают невидимый или бессмысленный текст. Или создают дорвеи — промежуточные страницы, которые перенаправляют посетителей на сторонние сайты. Некоторые сайты умеют замещать страницу, с которой перешел пользователь, на какую-нибудь другую. То есть когда пользователь переходит на такой сайт по ссылке из результатов поиска, а потом хочет снова вернуться к ним и посмотреть другие результаты, он видит какой-то другой ресурс.
Такие ресурсы не представляют интереса для пользователей и вводят их в заблуждение — и, соответственно, ухудшают качество поиска. Яндекс автоматически исключает их из поиска или понижает в ранжировании.
2. Бывает, что в том или ином документе есть полезная информация, но воспринимать ее сложно. Например, есть сайты, которые содержат popunder-баннеры (они перемещаются по экрану вслед за прокруткой страницы и закрывают ее содержание, а при попытке закрытия такого баннера открывается новое окно) и clickunder-рекламу (она неожиданно для пользователя открывает рекламную страницу при любом клике по сайту, в том числе — по ссылкам). С нашей точки зрения, оба этих вида рекламы мешают навигации по сайту и нормальному восприятию информации. Поэтому сайты с такой рекламой располагаются в поисковой выдаче ниже, чем сайты, на которых пользователь может найти ответ на свой вопрос без лишних проблем.
3. По запросам, которые не подразумевают явно потребность в эротическом контенте, Яндекс ранжирует сайты для взрослых ниже или вообще не показывает их в результатах поиска. Дело в том, что ресурсы с эротическим контентом часто используют достаточно агрессивные методы продвижения — в частности, они могут появляться в результатах поиска по самым разнообразным запросам. С точки зрения пользователя, который не искал эротики и порнографии, «взрослые» результаты поиска нерелевантны, и, к тому же, могут шокировать. Более подробно об этом принципе можно почитать здесь.4. Яндекс проверяет индексируемые веб-страницы на наличие вирусов. Если обнаружилось, что сайт заражен, в результатах поиска рядом с ним появляется предупреждающая пометка. При этом зараженные сайты не исключаются из поиска и не понижаются в результатах поиска — может быть, на таком ресурсе находится нужный пользователю ответ, и он все равно захочет туда перейти. Однако Яндекс считает важным предупредить его о возможном риске.
Основная метрика качества поиска Яндекса — это то, насколько пользователю пригодились найденные результаты. Иногда по запросам пользователей невозможно определить, какой ответ ему подойдет. Например, человек, задавший запрос [пушкин], возможно, ищет информацию о поэте, а возможно — о городе. Точно так же человек, который набрал запрос [iphone 4], может быть, хочет почитать отзывы и ищет форумы, а может быть, хочет купить и ищет магазины. Среди первых результатов поиска должны найтись ответы для всех случаев. Поэтому Яндекс старается сделать страницу результатов поиска разнообразной. Поиск Яндекса умеет определять многозначные запросы и показывает разнообразные ответы. Для этого используется технология «Спектр».yandex.ru
Яндекс Андромеда – что изменилось в поиске и как теперь продвигать сайт
19 ноября Яндекс объявил о запуске нового поискового алгоритма – Андромеда. Традиция называть алгоритмы в честь городов ушла в прошлое. Символично, что последним был г. Королев, неофициальная космическая столица России. Дальше только космос. Поехали!
Напомню, что последнее глобальное официальное обновление алгоритма было еще в августе 2017. За это время специалисты Яндекса добавили в поиск более 1000 изменений и улучшений. Все они постепенно запускались, тестировались. Внедренные изменения можно разделить на три направления: новый алгоритм ранжирования, быстрые ответы, коллекции.
Новый алгоритм ранжирования сайтов в Яндекс Proxima
Логичное развитие предыдущего алгоритма Палех. Теперь качество сайта напрямую влияет на его место в выдаче. Если раньше Яндекс для оценки использовал определенные категории людей – ассесоров, специалистов Толоки и продвинутых пользователей, взаимодействующих с результатами поиска, то теперь для обучения алгоритма берутся «явные знания людей, которые могут с помощью сервисов и алгоритмов компании помогать другим людям совершать выбор или получать информацию в «Поиске».» (из интервью руководителя Яндекс.Поиска Андрея Стыскина).
Еще один признак качественного сайта – лояльность. Яндекс учитывает постоянную аудиторию сайта, сколько людей возвращается после первого захода. Считает число переходов из внешних источников: социальных сетей, тематических форумов, справочников, Дзена. Используйте почтовую рассылку, публикуйте интересные статьи в ленте Дзен, держите пользователей в курсе об интересных акциях и предложениях через социальные сети. Чем популярнее сайт, тем он выше в органической выдаче.
Для таких сайтов теперь есть специальный значок:

Второй значок качественного сайта – Выбор пользователей:

Его может получить даже малопопулярный ресурс. Важно удержать костяк лояльной аудитории и работать над интересным контентом. Если после перехода пользователь надолго остался на сайте, а потом стал приходить вновь и вновь, такой сайт получает отметку «Выбор пользователей».
За прогрессом получения значков можно следить в Яндекс.Вебмастере, раздел – Показатели качества.
Третий признак качественного ресурса – отсутствие навязчивой рекламы. При переходе на сайт пользователь в первую очередь должен получить ответ на свой запрос, а не рекламный баннер во весь экран. Не следует использовать яркие, акцентирующие цвета, текст на странице должен быть легко читаем. Ничто не должно отвлекать внимание пользователя от просмотра контента.
Яндекс не запрещает размещать рекламу на сайте, просто не забывайте учитывать баланс полезного и навязчивого контента.
Еще один значок качественного сайта:

Доступен только для государственных сайтов, банков, внутренних сервисов Яндекс и официальных дилеров по данным портала Авто.ру.
Помогает защитить пользователя от мошенников, недобросовестных ресурсов и т.п. К примеру, если вам нужно получить загранпаспорт или подать заявление в ЗАГС, Яндекс подскажет ресурсы, где это можно сделать официально, без рисков отправить персональные данные шарлатанам.

Качество сайта – новый, важный фактор ранжирования. Учитывайте это при составлении стратегии продвижения на следующий год.
Быстрые ответы
Одно из самых заметных обновлений – быстрые ответы в поисковой выдаче. Яндекс уже давно выдавал ответ на некоторые запросы прямо на станице поиска. Курс валюты, почтовый индекс, высота Эвереста и т.д. В большинстве случаев это были запросы фактического характера, без дополнительной ценности, когда нет разницы, на каком сайте получить подобную информацию.
Сейчас список таких запросов значительно расширился. Теперь это не только интересные факты, но и решение ежедневных бытовых задач.
Где поужинать любимой китайской едой?

По запросу сразу же показывается карусель с подходящими ресторанами и кафе. Заведения можно отсортировать по нескольким параметрам.
Чтобы попасть в этот список организаций, необходимо полностью заполнить профиль компании в Яндекс.Справочнике. Указать время работы, добавить фотографии и дождаться отзывов от посетителей.
Еще пример быстрого ответа, рецепты:

«Колдунщики» Яндекс на базе микроразметки анализируют информацию на сайте, сравнивают между собой, и самые качественные показываются в быстрых ответах.
Быстрые ответы теперь подставляются и из сервиса Яндекс.Знатоки. 19 ноября он официально вышел из стадии бета-тестирования. Ответы дают как обычные пользователи, так и специально приглашенные эксперты – врачи, академики, учителя и студенты.

Компании также могут стать экспертами и отвечать на вопросы пользователей.

Никакой прямой рекламы продукта или услуги, только информационный ответ. Но в профиле можно указать подробное описание компании, оставить ссылку. Тут открываются большие возможности для крауд-маркетинга.
Яндекс.Коллекции
Теперь в один клик пользователи могут сохранять абсолютно все, что им понравилось в Сети. Книги, фильмы, рецепты, интерьеры и т.д. Все это попадает в сервис Яндекс.Коллекции.
Если коллекция общедоступна, она может попасть в выдачу по некоторым товарным запросам:

Сейчас сложно проследить четкую зависимость, как ранжируются коллекции в выдаче. На первых местах часто попадаются аккаунты с парой подписчиков и несколькими изображениями. Прямое вхождение ключевых слов важно, но оно не всегда играет решающую роль. К примеру, по запросу «красивые места Чечни» отображаются коллекции с названиями «Мечети Чечни», «Чечня», «Грозный», «Сердце Чечни» и т.д.

Алгоритм основывается на искусственном интеллекте и компьютерном зрении, он сам понимает, какие места относятся к Чечне, какие из них популярны и будут интересны пользователю. А дальше из публичных коллекций формируется ответ – наглядный пример работы нейросети Яндекс.
Андромеда – это новый подход Яндекса к обновлению поиска. Все фишки и изменения выкатываются постепенно, отследить, что именно влияет на проседание позиций сайта, становится все сложнее.
Качество сервиса в офлайне теперь напрямую влияет на позиции сайта в выдаче. Поведенческие факторы еще больше влияют на ранжирование, огромные баннеры во весь экран уходят в прошлое.
Главная задача Яндекс – дать пользователю быстрый и релевантный ответ из надежного источника. А задача вебмастеров сегодня – сделать сайт таким источником информации.
1ps.ru
Алгоритмы Яндекса — новые и старые, хронология за 2007-2017 года

Привет уважаемые читатели seoslim.ru! Тем, кто интересуется SEO и пытается развивать сайты правильно будет полезно узнать обо всех алгоритмах Яндекса, чтобы лучше понимать по каким критериям поисковая машина их ранжирует.
На протяжении всего времени Yandex постоянно вносит правки в работу алгоритмов: используются нейронные сети, устраняются ошибки, дорабатывается функционал, появляются новые фильтры и так далее.
Делается всё, чтобы выдача максимально точно отвечала на запросы пользователя.
По приведенным ссылкам вы узнаете о истории развитии компании, принципах работы поисковой машины и всех известных фильтрах.
В этой статье предлагаю всем освежить память и восстановить хронологию, дабы посмотреть, как происходила эволюция поисковых алгоритмов ранжирования Яндекса за период 2007 — 2017 годов.
Далее о каждом из них более подробно.
История алгоритмов Яндекса
«Безымянный или Версия 7» (июль 2007) — первый алгоритм, о котором было объявлено публике, цель которого улучшить релевантность выдачи.
Анонс на searchengines.guru
«8 SP1» (январь 2008) — после обновления в ТОП стали попадать старые авторитетные сайты, а ссылки стали товаром.
«Магадан» (май 2008) — запуск новой версии поиска, теперь поисковая программа могла решать ряд задач:
- Количество факторов ранжирования было удвоено.
- Алгоритмы могу быстро находить релевантные страницы, не дожидаясь обработки всех документов.
- Яндекс научился понимать слова, написанные транслитом и аббревиатуры.
- В выдаче стали отображаться сайты, не смотря на опечатки, которые исправляются автоматически.
- Расширение базы в несколько миллиардов страниц.
Анонс на yandex.ru/blog/
«Находка» (сентябрь 2008) — упор был сделан на изменения факторов ранжирования.
- Новый поход к машинному обучения.
- Учёт стоп-слов.
- Произошло расширение словарей Яндекса.
Анонс на yandex.ru/blog/
«Анадырь-Арзамас» (апрель 2009) — нововведения сильно пошатнули ТОП-выдачу.
Теперь молодым сайтам стало еще сложнее продвигаться, так как Яшка не могу определить их региональную принадлежность.
- Внедрение алгоритма «снятие омонимии», теперь Яндекс научился лучше понимать русский язык.
- Стал учитываться регион пользователя, и выдача менялась в зависимости от него.
- Был создан классификатор гео-зависимости запросов, когда в зависимости от запроса мог учитываться регион пользователя.
Релиз в yandex.ru/blog/
«Снежинск» (ноябрь 2009) — изменен подход к построению ранжирования, что позволило еще больше улучшить качество поиска.
- Появились фильтры АГС.
- Тестирование самообучающейся системы MatrixNet.
- Запуск дополнительных региональных факторов.
- Ухудшено ранжирование страниц с портянками текста.
- Первые места в выдаче отдаются первоисточнику, копипаст ранжируется хуже.
Анонс на yandex.ru/blog/webmaster/
«Конаково» (декабрь 2009) — был обновлением предыдущего алгоритма Снежинск.
- Появление новых операторов в поиске (*, / и др.).
- Расширение базы регионального ранжирования (добавлено 1250 городов России).
Релиз на yandex.ru/blog/webmaster/
«Обнинск» (сентябрь 2010) — запуск нового алгоритма, цель которого улучшить ранжирование по гео-независимым запросам.
- Снижено влияние seo-ссылок на поиск.
- Увеличен объем формулы ранжирования, который достиг 280 МБ.
- Расширение словаря транслитерации.
- Появилось понятие автор контента.
Подробнее в yandex.ru/blog/
«Краснодар» (декабрь 2010) — основой данного алгоритма стала технология «Спектр», которая могла отвечать на неточные запросы пользователей, благодаря разбавленным ответам из 60-ти категорий.
- Яндекс проиндексировал социальную сеть Вконтакте.
- Запросам стала присваиваться категория.
- Обновлено ранжирование по геозависимым запросам.
- Появились расширенные сниппеты.
Источник yandex.ru/blog/
«Рейкьявик» (август 2011) — теперь поиск стал персонализированным, то есть для каждого отображалась своя выдача.
- Появление колдунщиков, что позволило производить расчёты прямо в поиске.
- Обновлен алгоритм поисковых подсказок для новостных ресурсов.
- Тестирование программы «Оригинальные тексты».
Анонс запуска на yandex.ru/blog/company/
«Калининград» (декабрь 2012) — глобальная персонализация поисковой выдачи для запросов и подсказок.
- Обновление поисковых подсказок.
- Продвигать сайты теперь надо комплексно, теперь для Яндекса важны: ссылки, ключевые слова, дизайн, контент, юзабилити, соц. сигналы и другие факторы.
Источник yandex.ru/blog/
«Дублин» (май 2013) — следствие обновление предыдущего алгоритма Калининград.
Теперь персонализированный поиск мог реагировать на сиюминутные запросы пользователя.
Если раньше Яндекс обновлял данные об интересах пользователей раз в сутки, то теперь Яшка стал анализировать текущую поисковую сессию.
Подробнее на yandex.ru/company/
«Острова» (июль 2013) — запуск новой островной выдачи и сервисов.
Предполагалось, что пользователь будет решать свои вопросы прямо в выдаче без перехода на сайт с помощью интерактивных блоков, например, купить билет в кино или на самолёт, заказать столик в кафе и др.
Подробнее в yandex.ru/blog/company/
«Объектный ответ» (апрель 2015) — после запуска данной технологии в поиске справа, появилась карточка с общей информацией о предмете запроса. Подобное решение имеется и у Google.
Пример смотрите на yandex.ru/company/
«Минусинск» (май 2015) — цель этого алгоритма занижение позиций сайтов в выдаче, которые для продвижения используют SEO-ссылок в ссылочном профиле.
Яндекс рекомендуют вебмастерам больше уделять внимание улучшению сервисов на сайте, контенту и дизайну.
Подробнее yandex.ru/blog/webmaster/
«Владивосток» (февраль 2016) — новый алгоритм нацелен на учёт факторов мобилопригодности сайтов. Теперь в мобильном поиске будет большее значение отводиться сайтам, адаптированным под мобильный интернет.
Особенности алгоритма на yandex.ru/blog/
«Палех» (ноябрь 2016) — благодаря новому алгоритму Яндекс научился отвечать на сложные запросы пользователей.
Впервые в поиске стал использоваться искусственный интеллект, который с помощью нейронных сетей может понимать запросы пользователей не по словам, а по смыслу.
Подробно про работу алгоритма yandex.ru/blog/
«Баден-Баден» (март 2017) — алгоритм, который направлен на борьбу с переоптимизированными страницами. Если на сайте будут найдены подобные тексты, то позиции таких страниц или всего сайта в выдаче будут ухудшены.
Подобные нарушения отображаются в Яндекс.Вебмастере, раздел «Диагностика» — «Безопасность и нарушения».
Анонс алгоритма в yandex.ru/blog/webmaster/
«Королёв» (август 2017) — запуск новой версии поисковой выдачи или продолжение алгоритма Палех. Благодаря нейронной сети, Яндекс может наиболее точно давать ответы на сложные и многословные запросы.
Искусственный интеллект собирает данные на основе оценок пользователей, поисковой статистики, асессоров и толокеров.
Подробнее читайте на yandex.ru/blog/webmaster/
На этом все, с выходом нового алгоритма статья будет дополняться, так что добавьте ее в закладки, чтобы быть в курсе последний нововведений Яндекса.
seoslim.ru
Все алгоритмы ранжирования Яндекс 2007 — 2019
Привет, Друзья! В этой статье, я решил вспомнить былые годы и перечислить все алгоритмы ранжирования Яндекс начиная с 2007 года и заканчивая концом 2019-го. За это время много воды утекло и много сайтов попало под фильтры Яши, благодаря этим новым и старым алгоритмам. Итак, начинаем — АЛГОРИТМЫ ЯНДЕКС 2007 — 2019. Поехали!
Все алгоритмы ранжирования Яндекс 2007 — 2019

Второго июля 2007 года, Александр Садовский, объявил о появлении нового алгоритма в поисковой системе Яндекс.
Алгоритм Яндекс — «Версия 7»
Данный алгоритм был создан для улучшения ранжирования на различных дата центрах поисковой системы Yandex. Вот что написал в своем обращении по поводу данного алгоритма Александр Садовский:
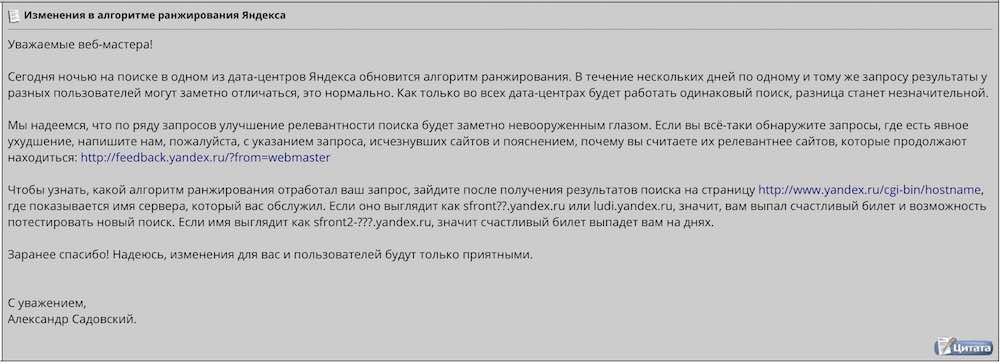
Следующий алгоритм Яндекса имел уже такое название:
Алгоритм Яндекс — «Версия 8» и «Восьмерка SP1»
За счет данного алгоритма, все авторитетные и трасстовые ресурсы, получили значительный прирост в поисковой выдаче. Внедрился фильтр «ПРОГОНОВ» двадцатого декабря 2007 года, для накрутки ссылочных факторов ранжирования.
Алгоритм Яндекс — Магадан
О появлении этого алгоритма, Яндекс заявил 16 мая 2008 года. Он был создан для ускорения подбора претендентов Fast Rank, а также для расширения базы аббревиатур, классификаторов документов и синонимов.
Алгоритм Яндекс — Находка
Алгоритм Находка появился 11 сентября 2008 года. Данный алгоритм Яндекса анализировал стоп слова в поисковых запросах и стал родоначальником нового подхода к машинному обучению Matrixnet.
Алгоритм Яндекс — Арзамас / Анадырь
Данный алгоритм появился 10 апреля 2009 года и работал с омонимами, учитывая региональность пользователей. В дальнейшем, несколько раз обновлялся, создав улучшенную формулу региональных запросов в Яндексе.
Алгоритм Яндекс — Снежинск
17 ноября 2009 в Яндексе состоялся официальный запуск алгоритма Снежинск. Он ознаменовал появление машинного обучения Matrixnet. С его появлением кратно увеличилось число факторов ранжирования, относительно крупнейших регионов России, что существенным образом отразилось на поисковой выдаче Yandex.
Алгоритм Яндекс — Конаково / Обнинск
22 декабря 2009 года Яндекс обзавелся еще одним алгоритмом, который изначально имел неофициальное название Конаково. С этим алгоритмом пришло изменение в ранжировании для геонезависимых запросов. В дальнейшем, 13 сентября 2010 года он поменял свое название на Обнинск.
Алгоритм Яндекс — Краснодар
Этот алгоритм, с «теплым» названием появился 15 декабря 2010 года. За счет технологии «СПЕКТР» и повышения разнообразия поисковой выдачи, алгоритм научился определять интент пользовательских запросов, проще говоря смысл, который пользователи закладывали в запрос. С появлением этой возможности повысилась локализация выдачи по геозависимым запросам для 1200 городов России.
Алгоритм Яндекс — Рейкьявик
17 августа 2011 появился данный алгоритм, который стал родоначальником такого понятия, как персонализация поисковой выдачи.
Алгоритм Яндекс — Калининград
Данный алгоритм компания Яндекс выпустила 12 декабря 2012 года на смену Рейкьявику. Была существенно улучшена персонализация и релевантность поисковой выдачи для пользователей.
Алгоритм Яндекс — Дублин
Вышел 30 мая 2013 года и тоже был направлен на улучшение персонализации данных для пользователей, с учетом их сиюминутных запросов, прямо во время ввода запроса в поисковую строку.
Алгоритм Яндекс — Началово
Алгоритм Началово появился 12 марта 2014 и ознаменовал начало борьбы со ссылками. Он так и назывался многими «БЕЗ ССЫЛОК», но только по Московскому региону.
Алгоритм Яндекс — Одесса
Алгоритм Одесса появился в Яндекс 5 июня 2014 и был создан для сервиса «Острова«. Началась эра островных дизайнов с внедрением быстрых интерактивных ответов. Но эта эра как быстро началась, также быстро и закончилась. Эксперимент с островами провалился.
Алгоритм Яндекс — Амстердам
Амстердам или «Объективный ответ» разработали и запустили 1 апреля 2015. Пользователям стала доступна дополнительная информация в правом столбце, о предмете своего запроса, с подробной классификацией, которую Яндекс стал собирать и хранить на своих серверах.
Алгоритм Яндекс — Минусинск
Алгоритм Минусинск появился 15 мая 2015 и наделал очень много шума. Он был создан для борьбы с покупкой и продажей ссылок и влиянием ссылок на поисковое ранжирование. Борьба была успешной и положила под фильтры Яндекс половину рунета, из под которых, многие сайты не вышли до сих пор.
Алгоритм Яндекс — Киров
Алгоритм Яндекса Киров или «Однорукий бандит Яндекса», вышел в свет 14 сентября 2015 года. Сервис начал рандомизировать и добавлять к числовому значению релевантности определенные документы с оценкой «REL+». Целью создания послужила необходимость для сбора дополнительной поведенческой информации, по Московскому региону. В дальнейшем рандомизация Яндекса была внедрена во всех регионах России.
Алгоритм Яндекс — Владивосток
Алгоритм Владивосток появился 2 февраля 2016 и был создан для учета адаптивности сайтов и их просматриваемости с мобильных устройств. С его приходом улучшилось ранжирование сайтов с адаптивным дизайном.
Алгоритм Яндекс — Палех
Алгоритм Палех стартовал 2 ноября 2016 и был направлен на определение соответствия поисковому запросу, в трехмерном пространстве семантического вектора и его связи с заголовком Title. Алгоритм определял соответствие пары ДОКУМЕНТ-ЗАПРОС на основании данных своей нейронной сети. Главная цель, которая преследовалась алгоритмом Палех, заключалась в улучшении качества поисковой выдачи для редких запросов пользователей.
Алгоритм Яндекс — Баден-Баден
Этот алгоритм тоже оставил за собой большой шлейф выжженной земли, состоящей из кучи забаненых сайтов. Он появился 23 марта 2017 с целью бороться с переоптимизацией сайтов ключевыми словами. Более подробно, о фильтре Баден-Баден я рассказал тут.
Алгоритм Яндекс — Королёв
22 августа 2017 года вышло логическое продолжение алгоритма Палех, с усовершенствованными возможностями определения семантических запросов пользователей. Алгоритм Королев выявлял смысл вводимого пользователями в поисковую строку запроса, сопоставлял его с интентами ожиданий этих пользователей и анализировал их не только с применением метатега Title, но и целиком всего текста на предлагаемых сайтах. Мощный алгоритм, который успешно работает до сих пор.
Алгоритм Яндекс — Андромеда
19 ноября 2018 года произошло глобальное обновление поисковой выдачи, с учетом появления нового алгоритма Андромеда. По сути, это улучшенная копия алгоритма Королев. Появились дополнительные значки качества для сайтов, улучшился сервис быстрых ответов и коллекций. Поисковая выдача стала управляться полностью за счет искусственной нейронной сети Яндекс. На сегодняшний день 14 ноября 2019 года это последний анонсированный Яндексом алгоритм.
Заключение
Итак, Друзья! Теперь вы знаете все алгоритмы ранжирования Яндекса, которые появлялись начиная с 2007 года по настоящий момент 2019 года. Перевод ранжирования на управление нейронной сетью, это действительно глобальный прорыв в развитии современного поиска. И неизвестно, что же будет дальше в сфере SEO продвижения, с учетом работы искусственного интеллекта.
hozyindachi.ru
Искусственный интеллект в поиске. Как Яндекс научился применять нейронные сети, чтобы искать по смыслу, а не по словам
Сегодня мы анонсировали новый поисковый алгоритм «Палех». Он включает в себя все те улучшения, над которыми мы работали последнее время.Например, поиск теперь впервые использует нейронные сети для того, чтобы находить документы не по словам, которые используются в запросе и в самом документе, а по смыслу запроса и заголовка.
Уже много десятилетий исследователи бьются над проблемой семантического поиска, в котором документы ранжируются, исходя из смыслового соответствия запросу. И теперь это становится реальностью.
В этом посте я постараюсь немного рассказать о том, как у нас это получилось и почему это не просто ещё один алгоритм машинного обучения, а важный шаг в будущее.
Искусственный интеллект или машинное обучение?
Почти все знают, что современные поисковые системы работают с помощью машинного обучения. Почему об использовании нейронных сетей для его задач надо говорить отдельно? И почему только сейчас, ведь хайп вокруг этой темы не стихает уже несколько лет? Попробую рассказать об истории вопроса.
Поиск в интернете — сложная система, которая появилась очень давно. Сначала это был просто поиск страничек, потом он превратился в решателя задач, и сейчас становится полноценным помощником. Чем больше интернет, и чем больше в нём людей, тем выше их требования, тем сложнее приходится становиться поиску.
Эпоха наивного поиска
Сначала был просто поиск слов — инвертированный индекс. Потом страниц стало слишком много, их стало нужно ранжировать. Начали учитываться разные усложнения — частота слов, tf-idf.
Эпоха ссылок
Потом страниц стало слишком много на любую тему, произошёл важный прорыв — начали учитывать ссылки, появился PageRank.
Эпоха машинного обучения
Интернет стал коммерчески важным, и появилось много жуликов, пытающихся обмануть простые алгоритмы, существовавшие в то время. Произошёл второй важный прорыв — поисковики начали использовать свои знания о поведении пользователей, чтобы понимать, какие страницы хорошие, а какие — нет.
Где-то на этом этапе человеческого разума перестало хватать на то, чтобы придумывать, как ранжировать документы. Произошёл следующий переход — поисковики стали активно использовать машинное обучение.
Один из лучших алгоритмов машинного обучения изобрели в Яндексе — Матрикснет. Можно сказать, что ранжированию помогает коллективный разум пользователей и «мудрость толпы». Информация о сайтах и поведении людей преобразуется во множество факторов, каждый из которых используется Матрикснетом для построения формулы ранжирования. Фактически, формулу ранжирования пишет машина (получалось около 300 мегабайт).
Но у «классического» машинного обучения есть предел: оно работает только там, где очень много данных. Небольшой пример. Миллионы пользователей вводят запрос [вконтакте], чтобы найти один и тот же сайт. В данном случае их поведение является настолько сильным сигналом, что поиск не заставляет людей смотреть на выдачу, а подсказывает адрес сразу при вводе запроса.
Но люди сложнее, и хотят от поиска всё больше. Сейчас уже до 40% всех запросов уникальны, то есть не повторяются хотя бы дважды в течение всего периода наблюдений. Это значит, что у поиска нет данных о поведении пользователей в достаточном количестве, и Матрикснет лишается ценных факторов. Такие запросы в Яндексе называют «длинным хвостом», поскольку все вместе они составляют существенную долю обращений к нашему поиску.
Эпоха искусственного интеллекта
И тут время рассказать о последнем прорыве: несколько лет назад компьютеры становятся достаточно быстрыми, а данных становится достаточно много, чтобы использовать нейронные сети. Основанные на них технологии ещё называют машинным интеллектом или искусственным интеллектом — потому что нейронные сети построены по образу нейронов в нашем мозге и пытаются эмулировать работу некоторых его частей.
Машинный интеллект гораздо лучше старых методов справляется с задачами, которые могут делать люди: например, распознаванием речи или образов на изображениях. Но как это поможет поиску?
Как правило, низкочастотные и уникальные запросы довольно сложны для поиска – найти хороший ответ по ним заметно труднее. Как это сделать? У нас нет подсказок от пользователей (какой документ лучше, а какой — хуже), поэтому для решения поисковой задачи нужно научиться лучше понимать смысловое соответствие между двумя текстами: запросом и документом.
Легко сказать
Строго говоря, искусственные нейросети – это один из методов машинного обучения. Совсем недавно им была посвящена лекция в рамках Малого ШАДа. Нейронные сети показывают впечатляющие результаты в области анализа естественной информации — звука и образов. Это происходит уже несколько лет. Но почему их до сих пор не так активно применяли в поиске?
Простой ответ — потому что говорить о смысле намного сложнее, чем об образе на картинке, или о том, как превратить звуки в расшифрованные слова. Тем не менее, в поиске смыслов искусственный интеллект действительно стал приходить из той области, где он уже давно король, — поиска по картинкам.
Несколько слов о том, как это работает в поиске по картинкам. Вы берёте изображение и с помощью нейронных сетей преобразуете его в вектор в N-мерном пространстве. Берете запрос (который может быть как в текстовом виде, так и в виде другой картинки) и делаете с ним то же самое. А потом сравниваете эти вектора. Чем ближе они друг к другу, тем больше картинка соответствует запросу.
Ок, если это работает в картинках, почему бы не применить эту же логику в web-поиске?
Дьявол в технологиях
Сформулируем задачу следующим образом. У нас на входе есть запрос пользователя и заголовок страницы. Нужно понять, насколько они соответствует друг другу по смыслу. Для этого необходимо представить текст запроса и текст заголовка в виде таких векторов, скалярное умножение которых было бы тем больше, чем релевантнее запросу документ с данным заголовком. Иначе говоря, мы хотим обучить нейронную сеть таким образом, чтобы для близких по смыслу текстов она генерировала похожие векторы, а для семантически несвязанных запросов и заголовков вектора должны различаться.
Сложность этой задачи заключается в подборе правильной архитектуры и метода обучения нейронной сети. Из научных публикаций известно довольно много подходов к решению проблемы. Вероятно, самым простым методом здесь является представление текстов в виде векторов с помощью алгоритма word2vec (к сожалению, практический опыт говорит о том, что для рассматриваемой задачи это довольно неудачное решение).
Дальше — о том, что мы пробовали, как добились успеха и как смогли обучить то, что получилось.
DSSM
В 2013 году исследователи из Microsoft Research описали свой подход, который получил название Deep Structured Semantic Model.
На вход модели подаются тексты запросов и заголовков. Для уменьшения размеров модели, над ними производится операция, которую авторы называют word hashing. К тексту добавляются маркеры начала и конца, после чего он разбивается на буквенные триграммы. Например, для запроса [палех] мы получим триграммы [па, але, лех, ех]. Поскольку количество разных триграмм ограничено, то мы можем представить текст запроса в виде вектора размером в несколько десятков тысяч элементов (размер нашего алфавита в 3 степени). Соответствующие триграммам запроса элементы вектора будут равны 1, остальные — 0. По сути, мы отмечаем таким образом вхождение триграмм из текста в словарь, состоящий из всех известных триграмм. Если сравнить такие вектора, то можно узнать только о наличии одинаковых триграмм в запросе и заголовке, что не представляет особого интереса. Поэтому теперь их надо преобразовать в другие вектора, которые уже будут иметь нужные нам свойства семантической близости.
После входного слоя, как и полагается в глубоких архитектурах, расположено несколько скрытых слоёв как для запроса, так и для заголовка. Последний слой размером в 128 элементов и служит вектором, который используется для сравнения. Выходом модели является результат скалярного умножения последних векторов заголовка и запроса (если быть совсем точным, то вычисляется косинус угла между векторами). Модель обучается таким образом, чтобы для положительны обучающих примеров выходное значение было большим, а для отрицательных — маленьким. Иначе говоря, сравнивая векторы последнего слоя, мы можем вычислить ошибку предсказания и модифицировать модель таким образом, чтобы ошибка уменьшилась.
Мы в Яндексе также активно исследуем модели на основе искусственных нейронных сетей, поэтому заинтересовались моделью DSSM. Дальше мы расскажем о своих экспериментах в этой области.
Теория и практика
Характерное свойство алгоритмов, описываемых в научной литературе, состоит в том, что они не всегда работают «из коробки». Дело в том, что «академический» исследователь и исследователь из индустрии находятся в существенно разных условиях. В качестве отправной точки (baseline), с которой автор научной публикации сравнивает своё решение, должен выступать какой-то общеизвестный алгоритм — так обеспечивается воспроизводимость результатов. Исследователи берут результаты ранее опубликованного подхода, и показывают, как их можно превзойти. Например, авторы оригинального DSSM сравнивают свою модель по метрике NDCG с алгоритмами BM25 и LSA. В случае же с прикладным исследователем, который занимается качеством поиска в реальной поисковой машине, отправной точкой служит не один конкретный алгоритм, а всё ранжирование в целом. Цель разработчика Яндекса состоит не в том, чтобы обогнать BM25, а в том, чтобы добиться улучшения на фоне всего множества ранее внедренных факторов и моделей. Таким образом, baseline для исследователя в Яндексе чрезвычайно высок, и многие алгоритмы, обладающие научной новизной и показывающие хорошие результаты при «академическом» подходе, оказываются бесполезны на практике, поскольку не позволяют реально улучшить качество поиска.
В случае с DSSM мы столкнулись с этой же проблемой. Как это часто бывает, в «боевых» условиях точная реализация модели из статьи показала довольно скромные результаты. Потребовался ряд существенных «доработок напильником», прежде чем мы смогли получить результаты, интересные с практической точки зрения. Здесь мы расскажем об основных модификациях оригинальной модели, которые позволили нам сделать её более мощной.
Большой входной слой
В оригинальной модели DSSM входной слой представляет собой множество буквенных триграмм. Его размер равен 30 000. У подхода на основе триграмм есть несколько преимуществ. Во-первых, их относительно мало, поэтому работа с ними не требует больших ресурсов. Во-вторых, их применение упрощает выявление опечаток и ошибок в словах. Однако, наши эксперименты показали, что представление текстов в виде «мешка» триграмм заметно снижает выразительную силу сети. Поэтому мы радикально увеличили размер входного слоя, включив в него, помимо буквенных триграмм, ещё около 2 миллионов слов и словосочетаний. Таким образом, мы представляем тексты запроса и заголовка в виде совместного «мешка» слов, словесных биграмм и буквенных триграмм.
Использование большого входного слоя приводит к увеличению размеров модели, длительности обучения и требует существенно больших вычислительных ресурсов.
Тяжело в обучении: как нейронная сеть боролась сама с собой и научилась на своих ошибках
Обучение исходного DSSM состоит в демонстрации сети большого количества положительных и отрицательных примеров. Эти примеры берутся из поисковой выдачи (судя по всему, для этого использовался поисковик Bing). Положительными примерами служат заголовки кликнутых документов выдачи, отрицательными — заголовки документов, по которым не было клика. У этого подхода есть определённые недостатки. Дело в том, что отсутствие клика далеко не всегда свидетельствует о том, что документ нерелевантен. Справедливо и обратное утверждение — наличие клика не гарантирует релевантности документа. По сути, обучаясь описанным в исходной статье образом, мы стремимся предсказывать аттрактивность заголовков при условии того, что они будут присутствовать в выдаче. Это, конечно, тоже неплохо, но имеет достаточно косвенное отношение к нашей главной цели — научиться понимать семантическую близость.
Во время своих экспериментов мы обнаружили, что результат можно заметно улучшить, если использовать другую стратегию выбора отрицательных примеров. Для достижения нашей цели хорошими отрицательными примерами являются такие документы, которые гарантированно нерелевантны запросу, но при этом помогают нейронной сети лучше понимать смыслы слов. Откуда их взять?
Первая попытка
Сначала в качестве отрицательного примера просто возьмём заголовок случайного документа. Например, для запроса [палехская роспись] случайным заголовком может быть «Правила дорожного движения 2016 РФ». Разумеется, полностью исключить то, что случайно выбранный из миллиардов документ будет релевантен запросу, нельзя, но вероятность этого настолько мала, что ей можно пренебречь. Таким образом мы можем очень легко получать большое количество отрицательных примеров. Казалось бы, теперь мы можем научить нашу сеть именно тому, чему хочется — отличать хорошие документы, которые интересуют пользователей, от документов, не имеющих к запросу никакого отношения. К сожалению, обученная на таких примерах модель оказалась довольно слабой. Нейронная сеть – штука умная, и всегда найдет способ упростить себе работу. В данном случае, она просто начала выискивать одинаковые слова в запросах и заголовках: есть — хорошая пара, нет — плохая. Но это мы и сами умеем делать. Для нас важно, чтобы сеть научилась различать неочевидные закономерности.
Ещё одна попытка
Следующий эксперимент состоял в том, чтобы добавлять в заголовки отрицательных примеров слова из запроса. Например, для запроса [палехская роспись] случайный заголовок выглядел как [Правила дорожного движения 2016 РФ роспись]. Нейронной сети пришлось чуть сложнее, но, тем не менее, она довольно быстро научилась хорошо отличать естественные пары от составленных вручную. Стало понятно, что такими методами мы успеха не добьемся.
Успех
Многие очевидные решения становятся очевидны только после их обнаружения. Так получилось и на этот раз: спустя некоторое время обнаружилось, что лучший способ генерации отрицательных примеров — это заставить сеть «воевать» против самой себя, учиться на собственных ошибках. Среди сотен случайных заголовков мы выбирали такой, который текущая нейросеть считала наилучшим. Но, так как этот заголовок всё равно случайный, с высокой вероятностью он не соответствует запросу. И именно такие заголовки мы стали использовать в качестве отрицательных примеров. Другими словами, можно показать сети лучшие из случайных заголовков, обучить её, найти новые лучшие случайные заголовки, снова показать сети и так далее. Раз за разом повторяя данную процедуру, мы видели, как заметно улучшается качество модели, и всё чаще лучшие из случайных пар становились похожи на настоящие положительные примеры. Проблема была решена.
Подобная схема обучения в научной литературе обычно называется hard negative mining. Также нельзя не отметить, что схожие по идее решения получили широкое распространение в научном сообществе для генерации реалистично выглядящих изображений, подобный класс моделей получил название Generative Adversarial Networks.
Разные цели
В качестве положительных примеров исследователи из Microsoft Research использовались клики по документам. Однако, как уже было сказано, это достаточно ненадежный сигнал о смысловом соответствии заголовка запросу. В конце концов, наша задача состоит не в том, чтобы поднять в поисковой выдаче самые посещаемые сайты, а в том, чтобы найти действительно полезную информацию. Поэтому мы пробовали в качестве цели обучения использовать другие характеристики поведения пользователя. Например, одна из моделей предсказывала, останется ли пользователь на сайте или уйдет. Другая – насколько долго он задержится на сайте. Как оказалось, можно заметно улучшить результаты, если оптимизировать такую целевую метрику, которая свидетельствует о том, что пользователь нашёл то, что ему было нужно.
Профит
Ок, что это нам дает на практике? Давайте сравним поведение нашей нейронной модели и простого текстового фактора, основанного на соответствии слов запроса и текста — BM25. Он пришёл к нам из тех времён, когда ранжирование было простым, и сейчас его удобно использовать за базовый уровень.
В качестве примера возьмем запрос [келлская книга] и посмотрим, какое значение принимают факторы на разных заголовках. Для контроля добавим в список заголовков явно нерелевантный результат.
| Заголовок страницы | BM25 | Нейронная модель |
|---|---|---|
| келлская книга википедия | 0.91 | 0.92 |
| ученые исследуют келлскую книгу вокруг света | 0.88 | 0.85 |
| book of kells wikipedia | 0 | 0.81 |
| ирландские иллюстрированные евангелия vii viii вв | 0 | 0.58 |
| икеа гипермаркеты товаров для дома и офиса ikea |
0 | 0.09 |
Все факторы в Яндексе нормируются в интервал [0;1]. Вполне ожидаемо, что BM25 имеет высокие значения для заголовков, которые содержат слова запроса. И вполне предсказуемо, что этот фактор получает нулевое значение на заголовках, не имеющих общих слов с запросом. Теперь обратите внимание на то, как ведет себя нейронная модель. Она одинаково хорошо распознаёт связь запроса как с русскоязычным заголовком релевантной страницы из Википедии, так и с заголовком статьи на английском языке! Кроме того, кажется, что модель «увидела» связь запроса с заголовком, в котором не упоминается келлская книга, но есть близкое по смыслу словосочетание («ирландские евангелия»). Значение же модели для нерелевантного заголовка существенно ниже.
Теперь давайте посмотрим, как будут себя вести наши факторы, если мы переформулируем запрос, не меняя его смысла: [евангелие из келлса].
| Заголовок страницы | BM25 | Нейронная модель |
|---|---|---|
| келлская книга википедия | 0 | 0.85 |
| ученые исследуют келлскую книгу вокруг света | 0 | 0.78 |
| book of kells wikipedia | 0 | 0.71 |
| ирландские иллюстрированные евангелия vii viii вв | 0.33 |
0.84 |
| икеа гипермаркеты товаров для дома и офиса ikea | 0 | 0.10 |
Для BM25 переформулировка запроса превратилась в настоящую катастрофу — фактор стал нулевым на релевантных заголовках. А наша модель демонстрирует отличную устойчивость к переформулировке: релевантные заголовки по-прежнему имеют высокое значение фактора, а нерелевантный заголовок — низкое. Кажется, что именно такое поведение мы и ожидали от штуки, которая претендует на способность «понимать» семантику текста.
Ещё пример. Запрос [рассказ в котором раздавили бабочку].
| Заголовок страницы | BM25 | Нейронная модель |
|---|---|---|
| фильм в котором раздавили бабочку | 0.79 | 0.82 |
| и грянул гром википедия | 0 | 0.43 |
| брэдбери рэй википедия | 0 | 0.27 |
| машина времени роман википедия | 0 | 0.24 |
| домашнее малиновое варенье рецепт заготовки на зиму | 0 | 0.06 |
Как видим, нейронная модель оказалась способна высоко оценить заголовок с правильным ответом, несмотря на полное отсутствие общих слов с запросом. Более того, хорошо видно, что заголовки, не отвечающие на запрос, но всё же связанные с ним по смыслу, получают достаточно высокое значение фактора. Как будто наша модель «прочитала» рассказ Брэдбери и «знает», что это именно о нём идёт речь в запросе!
А что дальше?
Мы находимся в самом начале большого и очень интересного пути. Судя по всему, нейронные сети имеют отличный потенциал для улучшения ранжирования. Уже понятны основные направления, которые нуждаются в активном развитии.
Например, очевидно, что заголовок содержит неполную информацию о документе, и хорошо бы научиться строить модель по полному тексту (как оказалось, это не совсем тривиальная задача). Далее, можно представить себе модели, имеющие существенно более сложную архитектуру, нежели DSSM — есть основания предполагать, что таким образом мы сможем лучше обрабатывать некоторые конструкции естественных языков. Свою долгосрочную цель мы видим в создании моделей, способных «понимать» семантическое соответствие запросов и документов на уровне, сравнимом с уровнем человека. На пути к этой цели будет много сложностей — тем интереснее будет его пройти. Мы обещаем рассказывать о своей работе в этой области. Cледите за следующими публикациями.
habr.com