Алгоритм ссылочного ранжирования сайта — что это за фактор, его сила для поисковых систем Яндекс и Google
В комплексе эффективного SEO-продвижения рекомендуется использовать качественную ссылочную массу. Ссылочное ранжирование играет весомую роль при оценке релевантности и качества сайта. При покупке ссылок с проверенных сайтов-доноров и грамотной перелинковке можно добиться повышения рейтинга в ТОП поисковой выдачи, увеличить конверсию и рост продаж предлагаемых товаров или услуг. Перебор со ссылками, наоборот, может ухудшить позиции веб-ресурса и даже повлечь за собой штрафные санкции поисковых систем.
навигация по статье
- Что такое ссылочное ранжирование
- Особенности ссылочного ранжирования в поисковых системах
- Факторы ссылочного ранжирования
- Принцип работы ссылочного ранжирования
- Как качество ссылок влияет на ранжирование
- Платные и бесплатные ссылки
- Как получить естественные ссылки — советы
Что такое ссылочное ранжирование
Ссылочные факторы ранжирования до сих пор являются значимыми при формировании результатов выдачи поисковиков. Если на странице есть внешняя ссылка с анкором, в котором вписано ключевое слово или фраза, то поисковый робот выдаст ее в результатах органического поиска.
Если на странице есть внешняя ссылка с анкором, в котором вписано ключевое слово или фраза, то поисковый робот выдаст ее в результатах органического поиска.
Все внешние ссылки, которые размещены на других сайтах и ссылаются на ваш ресурс, относятся к ссылочной массе. Роботы учитывают вес ссылки, а также авторитетность и тематичность сайта-донора. То есть если проверенный надежный сайт ссылается на какой-то сторонний ресурс — значит, последний заслуживает доверия целевой аудитории. Оценка (ранг) веб-ресурса определяется исходя из количества качественных внешних ссылок: чем их больше, тем выше ранг (по данному алгоритму).
То есть на присваиваемый ранг влияют такие факторы:
- Показатель авторитетности ресурса и страницы, с которой идет ссылка.
- Релевантность запроса, введенного пользователем, тексту анкора. То есть если в тексте ссылки нет слов из ключевой фразы, этот показатель равен нулю. Если в анкоре встречается слово или полностью запрос — он принимает максимальное значение.

Тематичность сайта-донора. При покупке ссылочной массы нужно отбирать доноров с похожей или аналогичной тематикой. Донорами могут быть профильные справочники, каталоги, форумы и порталы с аналогичной или схожей тематикой.
Особенности ссылочного ранжирования в поисковых системах
Каждая поисковая система разрабатывает свои собственные алгоритмы анализа качества веб-сайтов, в которые входят и ссылочные факторы. Это сложная система оценки, которая состоит из сотни различных метрик. Такой подход позволяет выбрать наиболее релевантные (соответствующие запросу) результаты и отфильтровать те онлайн-ресурсы, которые продвигаются «черными», запрещенными методами раскрутки. В таблице 1 приведены особенности ссылочного ранжирования для основных поисковых систем.
Табл. 1. Особенности реализации ссылочного ранжирования для разных поисковых систем
| Поисковая система | Особенности и факторы ссылочного ранжирования |
Гугл учитывает до 8 первых слов текста ссылки (включая предлоги и междометия). Морфологию этот поисковик не учитывает. Google использует атрибут alt-тэга img в качестве текста для изображений. Если веб-мастер использует однопиксельные картинки с заполнением этих атрибутов (для повышения ранга ссылочной массы), такое действие будет расценено как спам и грозит баном. Морфологию этот поисковик не учитывает. Google использует атрибут alt-тэга img в качестве текста для изображений. Если веб-мастер использует однопиксельные картинки с заполнением этих атрибутов (для повышения ранга ссылочной массы), такое действие будет расценено как спам и грозит баном. | |
| Яндекс | Яндекс не ограничивает количество слов ссылки. Но этот поисковик применяет непот-фильтр, который в автоматическом режиме отфильтровывает страницы со ссылками, не соответствующими требованиям. Под фильтр могут попасть ссылки, ведущие на нетематический ресурс (когда деятельность сайта-донора и сайта-акцептора радикально отличается), цвет ссылки сливается с фоном или определяется некачественное текстовое окружение. Другой особенностью Яндекса является анализ соотношения релевантных ссылок (тех, которые соответствуют тематике ресурса) к общему количеству внешних ссылок. |
| Апорт | Учитывает не больше 1 ссылки с доменов второго уровня. Использует разные ссылки, в зависимости от ключевого запроса. Использует разные ссылки, в зависимости от ключевого запроса. |
Факторы ссылочного ранжирования
Поисковые системы анализируют ссылочные факторы по каждому конкретному сайту, поднимая или опуская его в рейтинге, что напрямую влияет на результат выдачи в ТОП-10. Роботы анализируют наращивание ссылочной массы, количество ссылок, а также оценивают качество и размещение линков, тематичность статей, в которые встроены ссылки, и тематику самого онлайн-ресурса.
Перечень основных факторов ранжирования сайта поисковыми системами:
- Возраст веб-сайта.
- Общее число ссылок с доменов верхнего уровня. Т.е. линк, размещенный на главной странице, имеет больший вес, чем ссылка с более низких уровней страниц.
- Число различных IP. Это количество уникальных адресов, которые цитируют продвигаемый ресурс. Такой показатель демонстрирует охват аудитории, рекомендующей веб-сайт.
- Скорость наращивания ссылочной массы. Резкое увеличение количества внешних ссылок может привести к резкому снижению рейтинга сайта или вообще удалению из индекса.

- ТИЦ. Тематичекий индекс цитирования — одна из метрик, которые учитывают поисковики. Яндекс включает ТИЦ в свои алгоритмы ранжирования, определяя авторитетность интернет-ресурса количеством ссылающихся проиндексированных сторонних веб-страниц.
- Разные виды ссылок. Веб-мастерам нужно использовать разные виды линков (с анкорами, без анкоров, в виде изображений и пр.). Наибольший вес имеют ссылки, вписанные в статью или другие тексты (их вес выше ссылок, размещенных в сайдбаре или футере веб-страницы). При этом чем выше ссылка находится в тексте, тем больший вес она имеет.
- Возраст линка. Чем дольше ссылка находится на ссылающемся тематическом ресурсе, тем выше она ценится при ранжировании сайта поисковыми системами.
Принцип работы ссылочного ранжирования
Качественными являются естественные ссылки, которыми пользователи делятся на своих страницах в социальных сетях, публикуют на своих веб-ресурсах. Например, на сайте, который продает мебель, опубликован текст с описанием, как ухаживать за обивкой, чем чистить те или другие материалы. Пользователь прочитал статью на странице сайта, она ему понравилась, и он опубликовал ее на своей странице в соцсети или на другом ресурсе. Там его видят другие пользователи, которые тоже делятся им. Такое распространение очень полезно для роста рейтинга первоначального источника. Чем больше естественных линков ведет на ваш ресурс, тем выше он будет подниматься в рейтинге поисковых систем по ссылочному фактору.
Пользователь прочитал статью на странице сайта, она ему понравилась, и он опубликовал ее на своей странице в соцсети или на другом ресурсе. Там его видят другие пользователи, которые тоже делятся им. Такое распространение очень полезно для роста рейтинга первоначального источника. Чем больше естественных линков ведет на ваш ресурс, тем выше он будет подниматься в рейтинге поисковых систем по ссылочному фактору.
Как качество ссылок влияет на ранжирование
Поисковые системы стали ужесточать требования к качеству ссылочной массы, чтобы минимизировать возможность использования накрутки и применения запрещенных способов продвижения сайтов.
По каким причинам поисковики стали учитывать качество ссылочной массы:
- Веб-мастера стали закупать много ссылок с сайтов без проверки ресурса на тематичность, возраст и уровень, на котором расположен линк.
- На страницах сайтов специалисты по раскрутке начали публиковать множество ссылок, которые ухудшали удобочитаемость.

- В первые позиции органической выдачи стали подниматься веб-сайты, которые зачастую не соответствовали запросам и интересам пользователей, а выходили на лидерские позиции только благодаря количеству внутренних и внешних линков.
Чтобы исключить недобросовестное продвижение только за счет закупки большого объема ссылочной массы, поисковые машины теперь применяют различные факторы оценки и фильтруют сайты, нерелевантные результатам поиска. Например, пользователи с сайта, где размещен текст о стройматериалах, перешли по ссылке на ресурс, продающий зоотовары, и пр.
Платные и бесплатные ссылки
Для того, чтобы поисковые роботы присвоили вашему сайту высокую оценку, нужно оптимизировать ссылочный профиль. Для этого веб-мастера наращивают линки, закупая или получая бесплатные ссылки.
Ссылочный профиль состоит из таких линков:
- естественных;
- платных;
- бесплатных.
Каждый из видов ссылок имеет свой вес и влияет на рейтинг веб-ресурса. В Табл. 2 приведены описания и влияние разных видов линков на раскрутку онлайн-ресурса.
В Табл. 2 приведены описания и влияние разных видов линков на раскрутку онлайн-ресурса.
Таблица 2. Особенности применения платных и бесплатных внешних ссылок
| Вид ссылки | Как работает | Как использовать |
| Естественные | При публикации полезного контента, экспертной статьи или инфографики пользователи делятся им на своих ресурсах. | Для создания релевантного контента нужно изучить интересы и проблемы целевой аудитории. При написании текстов давать короткие и понятные ответы на запросы ЦА. Тексты должны быть уникальными, полезными и грамотными, а фото и видео — выкладываться в хорошем разрешении. |
| Платные | Покупные ссылки, которые можно приобрести на специальных биржах. Наиболее популярные площадки для закупки ссылочной массы: Miralinks, GoGetLinks, Webartex, Sape, Blogun. Наиболее популярные площадки для закупки ссылочной массы: Miralinks, GoGetLinks, Webartex, Sape, Blogun. | На ссылочных биржах можно купить вечные (остаются на ресурсе постоянно) или временные (на месяц, другой установленный срок) ссылки. При выборе сайта-донора (ресурса, на котором будет размещена ссылка на ваш сайт) нужно обращать внимание на его возраст, тематичность, количество внешних ссылок (чем меньше, тем лучше). |
| Бесплатные | Размещение комментариев и статей со ссылками на сайт в различных блогах, формуах, каталогах. | Хотя такие ссылки почти не учитываются при ранжировании, их тоже можно использовать. Можно договориться о взаимном обмене ссылками с другим ресурсом. Писать полезные и уместные комментарии в тематических форумах со ссылкой на свой сайт. А также размещать линки на сайтах-отзовиках с отзывами о товарах и услугах. При выборе бесплатных каталогов нужно выбирать трастовые каталоги. |
Как получить естественные ссылки — советы
Для получения естественной ссылки, которая имеет наибольший вес у поисковиков, применяются такие инструменты:
- Проведение конкурсов. Участники должны опубликовать на своих страницах объявление о розыгрыше или другой акции со ссылкой на рекламируемый ресурс. Такой метод улучшает социальные факторы и дает возможность получить естественные ссылки.
- Публикация важного экспертного контента. Если текст содержит интересную уникальную информацию, подписчики и читатели будут делиться ей на своих веб-ресурсах.
- Участие в обсуждении профильных тем на специальных форумах. Если оставлять комментарии с рекомендациями или советами, то тексты со ссылками не будут удаляться модераторами.
- Линкбейтинг. Создание информационных поводов для перепостов. Можно взять интервью у известного эксперта или блогера и разместить у себя в социальной сети.
 Интересное или скандальное видео привлечет новых подписчиков, которые будут делиться контентом.
Интересное или скандальное видео привлечет новых подписчиков, которые будут делиться контентом. - Ведение аккаунта компании в соцсетях. Нужно публиковать актуальные новости, статьи по теме, вести обсуждения с подписчиками. Те, кого заинтересует ваша активность, будут переходить на сайт компании по ссылкам из социальных сетей.
Ссылочная масса влияет на рейтинг сайта при комплексном интернет-продвижении. Чтобы ссылки приносили вес и повышали позиции сайта в результатах органической выдачи, нужно покупать линки на проверенных площадках, стремиться к получению естественных репостов своего контента, размещать ссылки на бесплатных онлайн ресурсах.
что это такое за система
АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ
ABCDEFGHIJKLMNOPQRSTUVWXYZ0-9
Ранжирование – это упорядочивание поисковой выдачи в зависимости от того, насколько результат подходит к запросу. Его используют поисковики, чтобы сделать результаты поиска по конкретной фразе релевантными, то есть отвечающими запросам пользователя. Релевантность (соответствие) оценивают по ряду параметров:
Релевантность (соответствие) оценивают по ряду параметров:
- подходит ли контент на странице под запрос, который ввел пользователь;
- насколько качественен сам сайт, нет ли на нем серьезных проблем или ошибок оптимизации, признаков использования черного SEO или сомнительных методов продвижения;
- сколько входящих ссылок ведет на ресурс, насколько они естественны и качественны.
В зависимости от того, насколько сайт соответствует требованиям качества поисковика, он сортируется в выдаче. Ресурсы, которые подходят под все критерии, оказываются в первых строчках, а те, которые им не отвечают, уходят на самое дно выдачи.
Как работает ранжирование
Когда пользователь вводит в поисковую строку какой-то запрос, алгоритмы просматривают базу сайтов и ищут там страницы с нужным ему содержанием. Найденные страницы выстраиваются в определенной последовательности: если поисковая система сочтет какой-то документ более подходящим под нужды посетителя, она разместит его выше, чем менее подходящий. Это и есть ранжирование. Оно позволяет сделать поиск удобнее и полезнее. Чтобы пользователи видели в выдаче преимущественно качественные сайты, учитываются еще и такие показатели, как авторитетность, возраст ресурса, его популярность и известность.
Это и есть ранжирование. Оно позволяет сделать поиск удобнее и полезнее. Чтобы пользователи видели в выдаче преимущественно качественные сайты, учитываются еще и такие показатели, как авторитетность, возраст ресурса, его популярность и известность.
- Многозначные слова. Ранжирование включает в себя не только сортировку, но и, например, систему «Спектр»: так она называется в «Яндексе». Дело в том, что некоторые запросы могут быть неоднозначными. Например, человек вводит слово «горький». Непонятно, что он ищет: простое определение горького вкуса, город или писателя. Ранжирование позволяет добавить в выдачу страницы, содержащие все значения этого слова, чтобы пользователь мог найти вариант, который отвечает его нуждам.
- Алгоритмы. Выдача в «Яндексе», Google и других поисковиках различается даже по одному и тому же запросу, потому что алгоритмы ранжирования к каждой системы свои. Они по-разному учитывают факторы и их значимость, смотрят не только на конкретную страницу, но и на сайт в целом.
 По-разному считаются показатели региональности и многие другие.
По-разному считаются показатели региональности и многие другие.
Алгоритмы ранжирования поисковиков
У каждой поисковой системы свои алгоритмы, которые она не раскрывает. Они держатся в секрете от всех: от вебмастеров, владельцев сайтов, даже от самих сотрудников поисковиков. Есть версия, что в точности работу программ не сможет описать никто: поисковые системы активно применяют машинное обучение, алгоритмы достраивают сами себя и работают без управления со стороны людей. Это означает, что со временем они все сильнее превращаются в черный ящик, и программистам все сложнее понять, какими принципами руководствуются роботы.
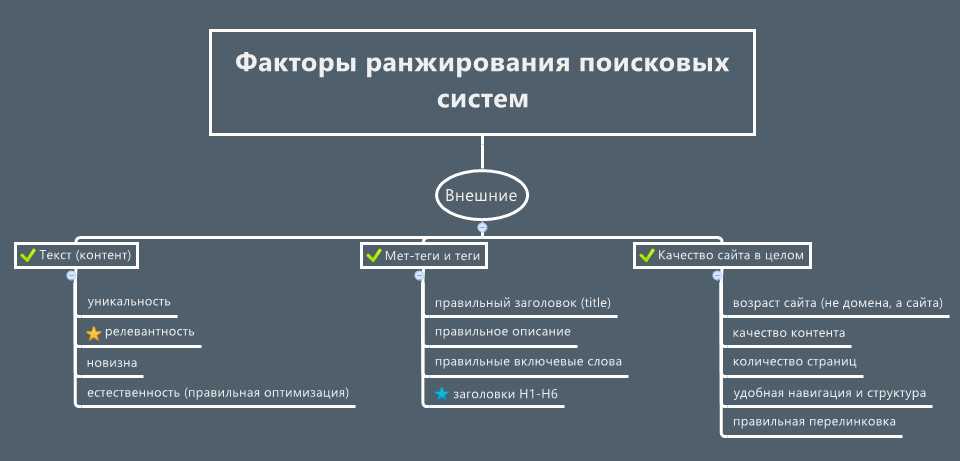
- Факторы ранжирования. Некоторые критерии оценки сайтов известны. Они делятся на три большие группы:
- внутренние. Сюда относится все, что определяет качество ресурса. Это количество страниц, вес и скорость загрузки, релевантность и качество текстового контента, наличие картинок и подписей к ним. Тексты должны быть уникальными и естественными, содержать ключевые слова, но без переспама и неестественных конструкций.

- внешние. Это количество и качество входящих ссылок и упоминаний ресурса на других площадках, а также авторитетность этих площадок;
- поведенческие. Определение поведения пользователей на сайте играет важную роль в ранжировании. Как часто люди посещают страницы, что они на них делают, как много времени проводят на сайте и задерживаются ли на нем – это много значит для поисковика.
- «Яндекс». Российский поисковик называет свой алгоритм ранжирования «Матрикснет» и ввел его еще в 2009 году. Специалисты уверяют, что у этого метода нет риска переобучения и построения ложных связей. Это позволяет создавать огромное количество факторов ранжирования, тонко их учитывать и настраивать. Скорость работы у «Матрикснета» огромная, система работает с сотнями тысяч сайтов, проверяет невероятное количество данных и получает результат в считанные секунды.

- Google. Зарубежная поисковая система рассказывает о своих технологиях реже. Большинство алгоритмов держится в секрете, как и у «Яндекса». Особенности ранжирования подмечают сами владельцы сайтов и специалисты по продвижению. Они подключают системы аналитики и проверяют, какие факторы особенно значимы. Выходит, что алгоритмы постоянно меняются, так что информация каждый год устаревает, но в целом Google уделяет больше внимания наличию длинного, подробного контента на странице и скорости загрузки сайта. А вот с определением регионов у него не так хорошо, как у «Яндекса», если речь идет о России и странах СНГ.
Другие термины на букву «Р»
AdSenseAJAXAllSubmitterAltApacheAPIBegunBlogunCAPTCHACMSCookieCopylancerCPACPCCPLCPMCPOCPSCPVCRMCS YazzleCSSCTR, CTB, CTI, VTRDescriptionDigital-агентствоDigital-маркетингDMOZDoS и DDoS атакиEmailFaviconFeedBurnerFTPGoGetLinksGoogle AdWordsGoogle AnalyticsGoogle ChromeGoogle MapsGoogle webmasters toolsGoogle Мой бизнесhCardhProducthRecipehreflanghtaccessHTTP-заголовкиHTTP-протоколHTTPS-протоколInternet ExplorerIP-адресJavaScriptJoomlaKeywordsKPILanding PageLiexLiveinternetLTVMash-upMiralinksMozilla FirefoxMSNNofollow и noindexOperaPageRank и тИЦPerformance MarketingPHPPinterestPPAPPCPush-уведомленияRobots.
Все термины SEO-Википедии
Теги термина
(Рейтинг: 5, Голосов: 7) |
Находи клиентов. Быстрее!
Работаем по будням с 9:30 до 18:30. Заявки, отправленные в выходные, обрабатываем в первый рабочий день до 10:30.
Приложи файл или ТЗ
Нажимая кнопку, ты разрешаешь обработку персональных данных и соглашаешься с политикой конфиденциальности.
Работаем по будням с 9:30 до 18:30. Заявки, отправленные в выходные, обрабатываем в первый рабочий день до 10:30.
Нажимая кнопку, ты разрешаешь обработку персональных данных и соглашаешься с политикой конфиденциальности.
наверх
Алгоритмы и типы ранжирования: концепции и примеры Алгоритмы ранжирования можно разделить на две категории: детерминированные и вероятностные. Алгоритмы ранжирования используются в поисковых системах для ранжирования веб-страниц в соответствии с их релевантностью поисковому запросу пользователя.
 В этой статье мы обсудим различные типы алгоритмов ранжирования и приведем примеры каждого типа.
В этой статье мы обсудим различные типы алгоритмов ранжирования и приведем примеры каждого типа.Содержание
Что такое алгоритм ранжирования?
Алгоритм ранжирования — это процедура, которая ранжирует элементы в наборе данных в соответствии с некоторым критерием. Алгоритмы ранжирования используются во многих различных приложениях, таких как веб-поиск, рекомендательные системы и машинное обучение.
Алгоритм ранжирования — это процедура, используемая для ранжирования элементов в наборе данных в соответствии с некоторым критерием. Алгоритмы ранжирования можно разделить на две категории: детерминированные и вероятностные.
- Алгоритмы детерминированного ранжирования : Алгоритм детерминированного ранжирования — это алгоритм, в котором порядок элементов в ранжированном списке фиксирован и не изменяется независимо от входных данных. Примером детерминированного алгоритма ранжирования является алгоритм ранжирования по признаку. В этом алгоритме каждому элементу присваивается ранг на основе значения его признака.
 Элементу с наивысшим значением признака присваивается ранг 1, а элементу с наименьшим значением признака присваивается ранг N, где N — количество элементов в наборе данных. Одним из реальных приложений алгоритма детерминированного ранжирования является заказ товаров в продуктовом магазине. Товары в продуктовом магазине обычно упорядочены по отделам, таким как продукты, мясо, молочные продукты и т. д. Внутри каждого отдела товары обычно располагаются в алфавитном порядке. Этот тип организации является примером детерминированного алгоритма ранжирования.
Элементу с наивысшим значением признака присваивается ранг 1, а элементу с наименьшим значением признака присваивается ранг N, где N — количество элементов в наборе данных. Одним из реальных приложений алгоритма детерминированного ранжирования является заказ товаров в продуктовом магазине. Товары в продуктовом магазине обычно упорядочены по отделам, таким как продукты, мясо, молочные продукты и т. д. Внутри каждого отдела товары обычно располагаются в алфавитном порядке. Этот тип организации является примером детерминированного алгоритма ранжирования. - Алгоритмы вероятностного ранжирования : В алгоритме вероятностного ранжирования порядок элементов в ранжированном списке может варьироваться в зависимости от входных данных.
 Примером вероятностного алгоритма ранжирования является алгоритм ранжирования по достоверности. В этом алгоритме каждому элементу присваивается ранг на основе его значения достоверности. Элементу с наивысшим значением достоверности присваивается ранг 1, а элементу с наименьшим значением достоверности назначается ранг N, где N — количество элементов в наборе данных. Еще одним примером вероятностного алгоритма ранжирования является байесовский спам-фильтр. В этом алгоритме каждому электронному письму назначается вероятность того, что оно является спамом. Электронные письма с самой высокой вероятностью ранжируются первыми, а электронные письма с самой низкой вероятностью ранжируются последними. Алгоритмы вероятностного ранжирования могут использоваться в поисковых системах для ранжирования веб-страниц в соответствии с их релевантностью поисковому запросу пользователя. Алгоритм ранжирования использует входные данные, такие как количество ссылок на веб-страницу с других веб-сайтов и количество раз, когда ключевое слово появляется на странице, для расчета показателя релевантности страницы.
Примером вероятностного алгоритма ранжирования является алгоритм ранжирования по достоверности. В этом алгоритме каждому элементу присваивается ранг на основе его значения достоверности. Элементу с наивысшим значением достоверности присваивается ранг 1, а элементу с наименьшим значением достоверности назначается ранг N, где N — количество элементов в наборе данных. Еще одним примером вероятностного алгоритма ранжирования является байесовский спам-фильтр. В этом алгоритме каждому электронному письму назначается вероятность того, что оно является спамом. Электронные письма с самой высокой вероятностью ранжируются первыми, а электронные письма с самой низкой вероятностью ранжируются последними. Алгоритмы вероятностного ранжирования могут использоваться в поисковых системах для ранжирования веб-страниц в соответствии с их релевантностью поисковому запросу пользователя. Алгоритм ранжирования использует входные данные, такие как количество ссылок на веб-страницу с других веб-сайтов и количество раз, когда ключевое слово появляется на странице, для расчета показателя релевантности страницы.
- Байесовский алгоритм ранжирования : Байесовский алгоритм ранжирования — это вероятностный алгоритм ранжирования, который использует байесовскую сеть для расчета оценки релевантности элемента.
 Байесовская сеть — это графическая модель, представляющая набор случайных величин и их условных зависимостей. Алгоритм байесовского ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше вероятность того, что элемент является положительным примером.
Байесовская сеть — это графическая модель, представляющая набор случайных величин и их условных зависимостей. Алгоритм байесовского ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше вероятность того, что элемент является положительным примером. - Алгоритм ранжирования лог-линейной модели : Алгоритм ранжирования лог-линейной модели представляет собой вероятностный алгоритм ранжирования, который использует лог-линейную модель для расчета оценки релевантности элемента. Логлинейная модель — это математическая модель, описывающая взаимосвязь между двумя или более переменными в терминах линейной комбинации логарифмов переменных.
Одним из наиболее распространенных применений алгоритмов ранжирования являются поисковые системы. Поисковые системы используют алгоритмы ранжирования, чтобы определить, какие веб-страницы наиболее релевантны поисковому запросу пользователя. Алгоритмы ранжирования также используются в рекомендательных системах, чтобы рекомендовать элементы, которые могут заинтересовать пользователя. Ниже приводится краткий обзор алгоритма ранжирования, используемого популярными поисковыми системами:
Алгоритмы ранжирования также используются в рекомендательных системах, чтобы рекомендовать элементы, которые могут заинтересовать пользователя. Ниже приводится краткий обзор алгоритма ранжирования, используемого популярными поисковыми системами:
- Алгоритм ранжирования Google : Алгоритм ранжирования Google является секретом, но мы знаем, что это вероятностный алгоритм ранжирования. Google использует различные факторы для ранжирования веб-страниц, включая количество ссылок на страницу, PageRank страницы и релевантность поискового запроса для страницы. Алгоритм Google PageRank — это алгоритм вероятностного ранжирования, который использует количество ссылок на веб-страницу как меру ее важности. Чем выше PageRank веб-страницы, тем больше вероятность того, что она будет занимать более высокое место в результатах поиска.
- Алгоритм ранжирования Amazon : Алгоритм ранжирования Amazon также является алгоритмом вероятностного ранжирования.
 Amazon использует различные факторы для ранжирования товаров, в том числе количество отзывов о товаре, средний рейтинг товара и цену товара. Алгоритм Amazon предназначен для рекомендации товаров, которые соответствуют поисковому запросу пользователя и популярны среди других пользователей.
Amazon использует различные факторы для ранжирования товаров, в том числе количество отзывов о товаре, средний рейтинг товара и цену товара. Алгоритм Amazon предназначен для рекомендации товаров, которые соответствуют поисковому запросу пользователя и популярны среди других пользователей. - Алгоритм ранжирования Facebook : Алгоритм ранжирования Facebook является секретом, но мы знаем, что это вероятностный алгоритм ранжирования. Facebook использует различные факторы для ранжирования новостей, в том числе количество лайков, репостов и комментариев к статье, PageRank истории и релевантность истории для новостной ленты пользователя. Алгоритм Facebook предназначен для того, чтобы показывать пользователям наиболее актуальные для них истории, о которых говорят их друзья.
- Алгоритм ранжирования Twitter : Алгоритм ранжирования Twitter также является алгоритмом вероятностного ранжирования. Твиттер использует различные факторы для ранжирования твитов, в том числе количество ретвитов, добавленных в избранное и ответов на твит, PageRank автора твита и релевантность твита на временной шкале пользователя.
 Алгоритм Twitter предназначен для показа пользователям твитов, которые наиболее актуальны для них и о которых говорят их друзья.
Алгоритм Twitter предназначен для показа пользователям твитов, которые наиболее актуальны для них и о которых говорят их друзья.
Типы алгоритмов ранжирования
Существует множество различных типов алгоритмов ранжирования, каждый из которых имеет свои преимущества и недостатки. Некоторые из наиболее распространенных типов алгоритмов ранжирования:
- Алгоритмы двоичного ранжирования : Алгоритмы двоичного ранжирования являются простейшим типом алгоритма ранжирования. Алгоритм бинарного ранжирования ранжирует элементы в наборе данных в соответствии с их относительной важностью. Двумя наиболее распространенными типами алгоритмов бинарного ранжирования являются алгоритмы ранжирования по признакам и алгоритмы ранжирования по частоте. Алгоритмы ранжирования по признаку ранжируют элементы по количеству признаков, которые они имеют вместе с эталонным элементом. Эталонный элемент — это элемент, который используется для вычисления значения сходства для каждого из других элементов в наборе данных.
 Алгоритмы ранжирования по частоте ранжируют элементы по количеству раз, которое они встречаются в наборе данных. Алгоритмы ранжирования по признакам и частоте имеют свои преимущества и недостатки. Алгоритмы ранжирования по признаку более точны, чем алгоритмы ранжирования по частоте, но они также требуют больших вычислительных ресурсов. Алгоритмы ранжирования по частоте быстрее, чем алгоритмы ранжирования по признакам, но они менее точны.
Алгоритмы ранжирования по частоте ранжируют элементы по количеству раз, которое они встречаются в наборе данных. Алгоритмы ранжирования по признакам и частоте имеют свои преимущества и недостатки. Алгоритмы ранжирования по признаку более точны, чем алгоритмы ранжирования по частоте, но они также требуют больших вычислительных ресурсов. Алгоритмы ранжирования по частоте быстрее, чем алгоритмы ранжирования по признакам, но они менее точны. - Ранжирование по сходству : Ранжирование по сходству — это тип алгоритма вероятностного ранжирования, который ранжирует элементы в наборе данных в соответствии с их сходством с эталонным элементом. Эталонный элемент — это элемент, который используется для вычисления значения сходства для каждого из других элементов в наборе данных. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше элемент похож на эталонный элемент.
 Существует множество различных типов ранжирования по алгоритмам сходства, каждый из которых имеет свои преимущества и недостатки. Некоторыми распространенными типами ранжирования по алгоритмам сходства являются алгоритм кластерного ранжирования, алгоритм ранжирования в векторном пространстве и т. д.
Существует множество различных типов ранжирования по алгоритмам сходства, каждый из которых имеет свои преимущества и недостатки. Некоторыми распространенными типами ранжирования по алгоритмам сходства являются алгоритм кластерного ранжирования, алгоритм ранжирования в векторном пространстве и т. д. - Ранжирование по расстоянию : Алгоритмы ранжирования по расстоянию представляют собой тип вероятностного алгоритма ранжирования, который ранжирует элементы в наборе данных в соответствии с их расстоянием от эталонного элемента. Ссылочный элемент — это элемент, который используется для вычисления значения расстояния для каждого из других элементов в наборе данных. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем дальше элемент находится от эталонного элемента. Существует множество различных типов алгоритмов ранжирования по расстоянию, каждый из которых имеет свои преимущества и недостатки.
 Некоторыми распространенными типами алгоритмов ранжирования по расстоянию являются алгоритм Евклидова расстояния, алгоритм расстояния Махаланобиса и т. д.
Некоторыми распространенными типами алгоритмов ранжирования по расстоянию являются алгоритм Евклидова расстояния, алгоритм расстояния Махаланобиса и т. д. - Ранжирование по предпочтениям : Алгоритмы предпочтительного ранжирования представляют собой тип вероятностного алгоритма ранжирования, который ранжирует элементы в наборе данных в соответствии с их предпочтением эталонного элемента. Эталонный элемент — это элемент, который используется для расчета значения предпочтения для каждого из других элементов в наборе данных. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем более предпочтительным является элемент для эталонного элемента.
- Ранжирование по вероятности : Ранжирование по вероятности — это тип вероятностного алгоритма ранжирования, который ранжирует элементы в наборе данных в соответствии с их вероятностью быть положительным примером.
 Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше вероятность того, что элемент будет положительным примером. Ранжирование по вероятности отличается от других типов алгоритмов ранжирования, поскольку оно учитывает неопределенность данных. Это делает его более точным, чем другие типы алгоритмов ранжирования. Существует множество различных типов ранжирования по вероятностным алгоритмам, каждый из которых имеет свои преимущества и недостатки. Некоторыми распространенными типами ранжирования по вероятностным алгоритмам являются байесовский алгоритм ранжирования, алгоритм ранжирования AUC и т. д.
Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше вероятность того, что элемент будет положительным примером. Ранжирование по вероятности отличается от других типов алгоритмов ранжирования, поскольку оно учитывает неопределенность данных. Это делает его более точным, чем другие типы алгоритмов ранжирования. Существует множество различных типов ранжирования по вероятностным алгоритмам, каждый из которых имеет свои преимущества и недостатки. Некоторыми распространенными типами ранжирования по вероятностным алгоритмам являются байесовский алгоритм ранжирования, алгоритм ранжирования AUC и т. д.
Заключение
Алгоритмы ранжирования используются для ранжирования элементов в наборе данных в соответствии с некоторым критерием. Существует множество различных типов алгоритмов ранжирования, каждый из которых имеет свои преимущества и недостатки. Ранжирование по сходству, расстоянию, предпочтению и вероятности являются наиболее распространенными типами алгоритмов ранжирования. Ранжирование по вероятности является наиболее точным типом алгоритма ранжирования, поскольку оно учитывает неопределенность данных. Если вы хотите узнать больше об алгоритмах ранжирования, оставьте комментарий ниже.
Ранжирование по сходству, расстоянию, предпочтению и вероятности являются наиболее распространенными типами алгоритмов ранжирования. Ранжирование по вероятности является наиболее точным типом алгоритма ранжирования, поскольку оно учитывает неопределенность данных. Если вы хотите узнать больше об алгоритмах ранжирования, оставьте комментарий ниже.
- Автор
- Последние сообщения
Аджитеш Кумар
Недавно я работал в области анализа данных, включая науку о данных и машинное обучение / глубокое обучение. Я также увлекаюсь различными технологиями, включая языки программирования, такие как Java/JEE, Javascript, Python, R, Julia и т. д., а также такие технологии, как блокчейн, мобильные вычисления, облачные технологии, безопасность приложений, платформы облачных вычислений, большие данные, и т. д. Чтобы быть в курсе последних обновлений и блогов, следите за нами в Twitter. Я хотел бы связаться с вами на Linkedin.
Ознакомьтесь с моей последней книгой под названием «Мышление на основе первых принципов: создание успешных продуктов с использованием мышления на основе первых принципов». Концепции, примеры — 27 апреля 2023 г.
Концепции, примеры — 27 апреля 2023 г.
Недавно я работал в области аналитики данных, включая науку о данных и машинное обучение/глубокое обучение. Я также увлекаюсь различными технологиями, включая языки программирования, такие как Java/JEE, Javascript, Python, R, Julia и т. д., а также такие технологии, как блокчейн, мобильные вычисления, облачные технологии, безопасность приложений, платформы облачных вычислений, большие данные, и т. д. Чтобы быть в курсе последних обновлений и блогов, следите за нами в Twitter. Я хотел бы связаться с вами на Linkedin. Ознакомьтесь с моей последней книгой под названием «Мышление на основе первых принципов: создание успешных продуктов с использованием мышления на основе первых принципов».0003
Опубликовано в Data Science. Помечены машинным обучением.
Алгоритмы ранжирования — знайте свои многокритериальные методы принятия решений! | Мохит Маянк
Давайте рассмотрим некоторые из основных алгоритмов для решения сложных задач принятия решений, зависящих от множества критериев.
 Мы обсудим, зачем нам нужны такие техники, и изучим доступные алгоритмы в крутом пакете skcriteria python Photo by Joshua Golde from Unsplash
Мы обсудим, зачем нам нужны такие техники, и изучим доступные алгоритмы в крутом пакете skcriteria python Photo by Joshua Golde from UnsplashОбновление — март 2022: Из-за изменений кода в последней версии scikit-criteria рекомендуется использовать v0.2.11 пакета для кода, обсуждаемого в статье. Репозиторий кода здесь.
Предположим, вам нужно принять решение — например, купить дом, машину или даже гитару. Вы не хотите выбирать случайным образом или быть предвзятым из-за чьего-то предложения, но хотите принять взвешенное решение. Для этого вы собрали некоторую информацию о объекте, который хотите купить (допустим, это автомобиль). Итак, у вас есть список из 9Автомобили 0125 N с информацией о ценах. Как обычно, мы не хотим тратить больше, мы можем просто отсортировать автомобили по их цене (в порядке возрастания) и выбрать лучший (с наименьшей ценой), и все готово! Это было принятие решения по одному критерию. Но увы, если жизнь так проста 🙂 Еще хотелось бы, чтобы у машины был хороший пробег, двигатель получше, разгон побыстрее (если хочется погонять) и еще кое-что. Здесь вы хотите выбрать автомобиль с наименьшей ценой, но с наибольшим пробегом и ускорением и так далее. Эта проблема не может быть так легко решена простой сортировкой. Введите многокритериальные алгоритмы принятия решений!
Здесь вы хотите выбрать автомобиль с наименьшей ценой, но с наибольшим пробегом и ускорением и так далее. Эта проблема не может быть так легко решена простой сортировкой. Введите многокритериальные алгоритмы принятия решений!
Давайте выберем один набор данных, чтобы было проще визуализировать результат, понять, что на самом деле происходит за кулисами и, наконец, развить интуицию. Для этого я выбираю набор данных cars. Для каждого автомобиля мы сосредоточимся на подмножестве атрибутов и выберем только 10 строк (уникальные автомобили), чтобы облегчить себе жизнь. Посмотрите на выбранные данные,
10 строк из набора данных о автомобилях.Объяснение некоторых атрибутов. .
 Цена играет в тысячах $, ускорение в десятках секунд и так далее.
Цена играет в тысячах $, ускорение в десятках секунд и так далее.2. Логика наилучшего для каждого атрибута также различается. Здесь мы хотим найти автомобиль с высокими значениями расхода топлива, объема и ускорения. При этом невысокие значения по весу и цене. Это понятие высокого и низкого можно вывести как максимизацию и минимизацию атрибутов соответственно.
3. Может быть дополнительное требование, когда мы не считаем каждый атрибут равным. Например, если я хочу машину для гонок и скажу, что меня спонсирует миллиардер, то меня не будут так сильно волновать расход на галлон и цена. Я хочу самую быструю и легкую машину. Но что, если я студент (отсюда, скорее всего, с ограниченным бюджетом) и много путешествую, то вдруг расход и цена становятся самым важным атрибутом, и мне наплевать на объем двигателя. Эти понятия важности атрибутов можно вывести как веса, присвоенные каждому атрибуту. Скажем, цена важна на 30%, а водоизмещение всего на 10% и так далее.
Разобравшись с требованиями, давайте попробуем посмотреть, как мы можем решить подобные проблемы.
Большинство основных многокритериальных решателей имеют общую методологию, которая пытается,
- Рассматривать один атрибут за раз и пытаться максимизировать или минимизировать его (согласно требованию) для получения оптимизированной оценки.
- Введите веса для каждого атрибута, чтобы получить оптимизированные взвешенные оценки.
- Объедините взвешенные баллы (каждого атрибута), чтобы получить окончательный балл для объекта (здесь автомобиля).
После этого мы преобразовали требования в один числовой атрибут (окончательная оценка), и, как и ранее, мы можем сортировать по нему, чтобы получить лучший автомобиль (на этот раз мы сортируем по убыванию, так как мы хотим выбрать автомобиль с максимальным счет). Давайте рассмотрим каждый шаг на примерах.
Увеличить и свернуть
Помните первый пункт из раздела набора данных, атрибуты имеют очень разные единицы и распределения, которые нам нужно обработать. Одним из возможных решений является нормализация каждого атрибута в пределах одного диапазона. И мы также хотим, чтобы направление добра было одинаковым (независимо от логики). Следовательно, после нормализации значения, близкие к максимальному диапазону (скажем, 1), должны означать, что автомобиль хорош по этому атрибуту, а более низкие значения (скажем, около 0) означают, что они плохие. Мы делаем это с помощью следующей формулы,
Одним из возможных решений является нормализация каждого атрибута в пределах одного диапазона. И мы также хотим, чтобы направление добра было одинаковым (независимо от логики). Следовательно, после нормализации значения, близкие к максимальному диапазону (скажем, 1), должны означать, что автомобиль хорош по этому атрибуту, а более низкие значения (скажем, около 0) означают, что они плохие. Мы делаем это с помощью следующей формулы,
Посмотрите на первое уравнение для максимизации, одним из примеров является обновление миль на галлон каждого автомобиля путем деления его на сумму миль на галлон всех автомобилей (сумма нормализации). Мы можем изменить логику, просто учитывая максимальное количество миль на галлон или другие формулы. Намерение состоит в том, что после применения этого к каждому атрибуту диапазон каждого атрибута будет одинаковым, и мы можем сделать вывод, что значение, близкое к 1, означает хорошее.
Формула для минимизации почти такая же, как и для максимизации, мы просто инвертируем ее (1 делим на максимизацию) или отражаем ее (путем вычитания из 1), чтобы фактически изменить направление добра (иначе 1 будет означать плохое, а 0 будет значит хорошо). Посмотрим, как это выглядит на практике,
Пример тепловой карты нормализации суммы исходных данных. Проверьте значение «миль на галлон» для «Форд Торино». Первоначально это 17, но после нормализации суммы должно быть 17/156 = 0,109. Точно так же «цена» равна 20k, после обратного преобразования она будет равна 1/(20k/287872) = 14,4Применение весов
Нам просто нужно наложить вес на оптимизированные оценки, что можно легко сделать, умножив веса оптимизированная оценка. Здесь также мы можем ввести различные типы нормализации,
- как есть : прямое умножение весов для получения оптимизированного результата
- сумма : нормализация весов по логике суммирования (обсуждалась выше), затем умножение.

- max : нормализовать по максимальной логике, затем умножить.
Объединить баллы
Наконец, мы объединим баллы, чтобы сделать их одним. Это можно сделать двумя разными способами:
- сумма : сложить все отдельные баллы вместе
- продукт : перемножьте все индивидуальные баллы вместе. Фактически, многие реализации добавляют логарифм значения вместо того, чтобы брать произведения, это делается для обработки очень меньшего результата при умножении небольших значений.
Существует очень хороший пакет Python с именем skcriteria, который предоставляет множество алгоритмов для решения проблемы принятия решений по нескольким критериям. На самом деле два алгоритма внутри модуля skcriteria.madm.simple :
-
WeightedSum— логика объединения индивидуальных оценок представляет собой сумму -
WeightedProduct— логика объединения индивидуальных оценок представляет собой произведение (сумма логарифма)
И оба эти метода принимают два параметра в качестве входных данных,
-
изация логика (минимизация всегда обратна той же логике максимизации).
-
wnorm— определить логику нормализации веса
Чтобы выполнить ранжирование наших данных, сначала нам нужно загрузить его как их0125 skcriteria.Data объект,
загрузка данных в объект данныхПосле загрузки данных все, что нам нужно сделать, это вызвать соответствующую функцию принятия решений с объектом данных и настройками параметров. В выходных данных есть один дополнительный столбец рангов, чтобы показать окончательный рейтинг с учетом всех упомянутых критериев.
пример логики weightedSum с нормализацией суммы значений Мы можем даже экспортировать окончательную оценку на dec.e_.points и ранги на дес.ранг_ .
Давайте сравним результат различных алгоритмов принятия решений (с разными параметрами) на нашем наборе данных. Для этого я использую реализации weightedSum и weightedProduct (один раз с max , а затем с нормализацией значения sum ). Я также реализовал функцию
Я также реализовал функцию normalize_data , которая по умолчанию выполняет нормализацию minmax и вычитания. Затем я применяю суммирование на выходе.
Наконец, я строю параллельные графики координат, где каждая ось (вертикальная линия) обозначает один тип решателя, а значения обозначают ранг автомобиля этим решателем. Каждая строка предназначена для одной машины и идет слева направо, она показывает путь — как меняется ранг машины, когда вы переключаетесь между разными решателями.
Путешествие автомобиля при переключении решателя решенийНесколько очков,
- Ford Torino занимает 1-е место (автомобиль с наивысшим баллом) для решателей 4/5. Minmax отдает предпочтение Chevrolet Malibu.
- Impala — универсальный низкоранговый 🙁
- Обе реализации
weightedProductприсваивают одинаковый рейтинг всем автомобилям. Здесь ничего интересного. МинМакс дает самые разнообразные рейтинги для лучших 4 парней.
Основная причина дисперсии результата при изменении нормализации (от суммы до максимума) связана с переводом исходных данных. Этот перевод изменяет диапазон данных (например, масштабирует все между x и y ), а в случае инверсии также изменяет линейность (скажем, равные шаги 1 в исходных данных не согласуются в преобразованных данных). Это станет более ясно из следующего результата:
. Здесь входные данные состоят из чисел от 1 до 9 (обратите внимание, разница между любыми двумя последовательными числами равна 1, т. е. шаг одинаков). Первый подход (minmax) переводит данные между 0 и 1, а шаг остается тем же. Теперь посмотрим на логику минимизации ( _inverse ) подхода 2 и 3. Здесь в начале (низкие исходные значения) шаг составляет почти половину последнего элемента, но ближе к концу (высокое исходное значение) шаг очень мал, хотя в исходном данные мы перемещаем с одинаковым шагом 1.
Из-за этого в случае минимизации очень высокий балл дается «хорошим» автомобилям (с низкими значениями) и даже небольшой примесной материи (при минимизации высокое значение = низкая оценка) и приводит к резкому снижению оценки. Мы как бы очень придираемся, либо ты лучший, либо получи половину балла 🙂 С другой стороны, для более высоких значений мелкие примеси не имеют значения. Если автомобиль уже плохой по этому атрибуту, то нам все равно, будет ли его значение 7, 8 или 9.и снижение балла гораздо меньше! Мы можем использовать это понимание, чтобы выбрать правильный решатель с правильным параметром в соответствии с нашими потребностями.
Эта статья только коснулась поверхности многокритериальной области принятия решений. Даже в пакете skcriteria есть гораздо больше алгоритмов, таких как TOPSIS и MOORA, у которых совершенно другая интуиция для решения этих проблем. Но даже тогда во многих из них используется понятие добра и идея обработки отдельных признаков, чтобы в конечном итоге соединить их все вместе.